目录
1、增加
insert into 表 (字段1, 字段3, 字段5) values(value1, value2, value3)
insert into 表 [(字段1, 字段2, 字段3....)] values(value1, value2,value3.....)[,(value1, value2, value3....) .....]
insert into 表 values(value1, value2,value3.....),(value4, value5,value6.....)....
查看表数据:
2、删除
1)删除表数据
delete from +表名 where +限定的条件;
2)删除表所有数据
truncate +表名;
3)删除表所有数据和表结构
drop table +表名;
3、修改
update语句
update+表名+set+字段对应值 where +指定位置
replace语句
replace into 表名 [(字段列表)] values (值列表)
replace [into] 目标表名[(字段列表1) select (字段列表2) from 源表 where 条件表达式
replace [into] 表名 set 字段1=值1, 字段2=值2
4、查询
select * from +表名:查询表所有的数据(*代表所有)
1、增加
insert into 插入数据
方式一:
insert into 表 (字段1, 字段3, 字段5) values(value1, value2, value3)
insert into student(socre,name,age,gender,address,co_id,time,notes) values(80,'zhangsan',18,'M','hunan',001,'2020-9-1',null);方式二:
insert into 表 [(字段1, 字段2, 字段3....)] values(value1, value2,value3.....)[,(value1, value2, value3....) .....]
insert into student values(2,81,'lisi',19,'M',12345678946,'hubei',2,'2020-9-1','1');方式三:
insert into 表 values(value1, value2,value3.....),(value4, value5,value6.....)....
insert into student (id,socre,name,age,gender,phone,address,co_id,time,notes) values(null,82,'wangwu',20,'M',12345678936,'hubei',3,'2020-9-1','2');详细知识点在另一篇文章(想仔细了解可移至):MySQL插入数据库 insert into 语句 用法总结_周湘zx的博客-CSDN博客
MySQL插入数据库 insert into 语句 用法总结_周湘zx的博客-CSDN博客insert into 表 [(字段1, 字段2, 字段3....)] values(value1, value2,value3.....)[,(value1, value2, value3....) .....]命令格式:insert into 表 values(value1, value2,value3.....),(value4, value5,value6.....)....命令格式:insert into 表 values(value1, value2, value3....)https://blog.csdn.net/weixin_68256171/article/details/132150692
注意:0不等于null ,null指的是一个空属性,0是一个值
查看表数据:
select *from student;
2、删除
1)删除表数据
delete from +表名 where +限定的条件;
如:删除student表中name等于lisi的数据
delete from student where name='lisi';2)删除表所有数据
truncate +表名;
如:truncate student;
(删除表所有数据,表结构还在)
3)删除表所有数据和表结构
drop table +表名;
如:drop table dcs;
(删除表所有数据和表结构,直接把表删除)
3、修改
update语句
update+表名+set+字段对应值 where +指定位置
1)修改student表中的id=2的age的值为22
update student set age=22 where id=2;2)修改student表中name以zhang开头的gender的值为F
update student set gender='F' where name like 'zhang%';(%号代表通配符,%放在后面就是以什么开头,%放在前面就是以什么结尾,前后都有%就是包含)
3)修改student表中 co_id为1 且 phone为12345678912 的address的值为beijing
update student set address='beijing' where co_id=1 and phone=12345678912;4)修改student表中age在16到20之间的notes的值为'beizhu'
update student set notes='beizhu' where age between 16 and 20;replace语句
语法格式有三种语法格式:
语法格式1:
replace into 表名 [(字段列表)] values (值列表)
语法格式2:
replace [into] 目标表名[(字段列表1) select (字段列表2) from 源表 where 条件表达式
语法格式3:
replace [into] 表名 set 字段1=值1, 字段2=值2
4、查询
select * from +表名:查询表所有的数据(*代表所有)
查询对应字段的数据
select name,address from student;查询性别不等于0的所有数据
select *from student where gender!=0;
select *from student where gender<>0;查询age在18到19之间的所有数据
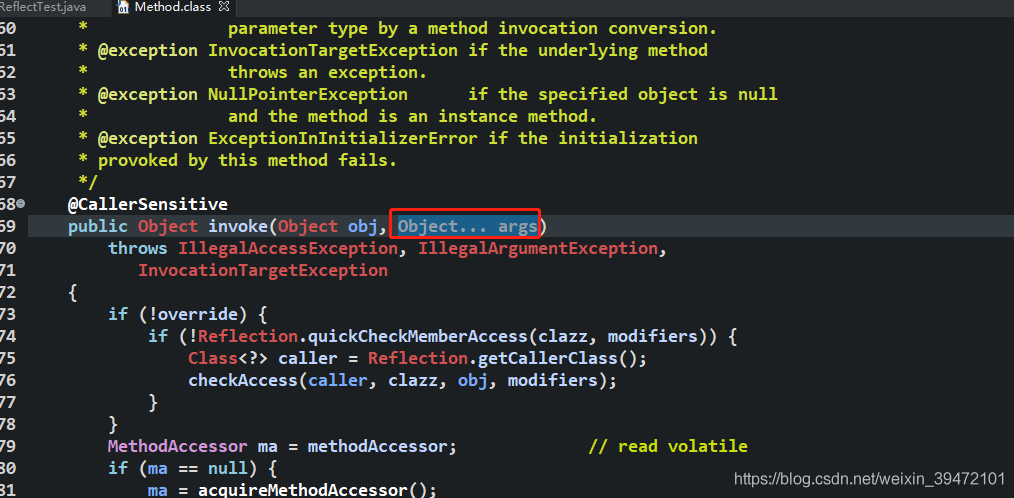
select *from student where age between 18 and 19;
select *from student where age>=18 and age<=19;查询notes字段为null的数据(null是属性不能用等于)
select *from student where notes is null;查询表中前三行数据
select *from student limit 3;查询表中2到4行数据
select *from student limit 1,3;查询表中2到5行数据
select *from student limit 1,4;查询name以wang开头的所有数据
select *from student where name like 'wang%';查询name包含zh的所有数据
select *from student where name like '%zh%';对age进行降序排序
select *from student order by age desc;对age进行升序排序
select *from student order by age asc;查询出表中age为前三个的name的值
select name from student order by age desc limit 3;根据gender进行分组,然后求出不同性别的人数
(对某个分组,select后面查询字段必须是分组的字段或者聚合函数,不能接其他字段)
select gender,count(*) from student group by gender;统计age为18的人数
select count(*) from student where age=18;
select count(age) from student where age=18;求出男生的年龄总和
select sum(age) from student where gender='M';求出男生的平均年龄
select avg(age) from student where gender='M';求出男生的最高年龄
select max(age) from student where gender='M';求出男生的最低年龄
select min(age) from student where gender='M';把表中的phone字段的值去重
select distinct(phone) from student;取别名
select name as 名字 from student;求出总成绩大于150的班级
select co_id from student group by co_id having sum(socre)>150;常用的聚合函数: sum(): 求和 count(): 统计 avg(): 求平均数 max():最大值 min():最小值 distinct():去重 (group by也有去重功能)
重点: 1.分组函数group by只能和聚合函数、分组的字段一起使用 2.where 后面可以接group by,但是group by 后面不能接where条件 3.group by前面加where条件是为了先过滤再分组,group by后面接条件用having 加条件(一般接聚合函数)
文章参考:MySQL语句总和