前提:
单机的Redis存在四大问题:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0Ire1laS-1691852468090)(assets/image-20210725144240631.png)]](https://img-blog.csdnimg.cn/d5fc6494cf204b0e846b194ec07907b3.png)
解决办法:基于Redis集群解决单机Redis存在的问题
1、Redis持久化
Redis 具有持久化功能,其会按照设置以 快照 或 操作日志 的形式将数据持久化到磁盘。
Redis有两种持久化方案:
- RDB持久化
- AOF持久化
注意:
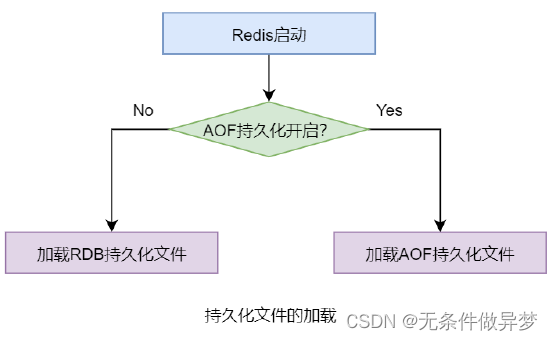
RDB 是默认持久化方式,但 Redis 允许 RDB 与 AOF 两种持久化技术同时开启,此时系统会使用 AOF 方式做持久化,即 AOF 持久化技术的优先级要更高。
同样的道理,两种技术同时开启 状态下 系统 启动时若两种持久化文件同时存在,则优先加载 AOF持久化文件。
1.1 RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中(将内存中某一时刻的数据快照 全量 写入到指定的 rdb 文件的持久化技术。)。
当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB 文件,默认是保存在当前运行目录。
当 Redis 启动时会自动读取 RDB 快照文件,将数据从硬盘载入到内存, 以恢复 Redis 关机前的数据库状态。
1.1.1 执行时机
RDB持久化在四种情况下会执行:
- 执行save命令
- 执行bgsave命令
- Redis停机时
- 触发RDB条件时
1)save命令
执行下面的命令,可以立即执行一次RDB:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1EXhmBVX-1691852602646)(assets/image-20210725144536958.png)]](https://img-blog.csdnimg.cn/52e75fa76dd2497d83147e7b0be02cbd.png)
save命令会导致主进程执行RDB,这个过程中其它所有命令都会被阻塞。只有在数据迁移时可能用到。
阻塞 redis-server 进程,直至持久化过程完毕。而在redis-server 进程阻塞期间, Redis不能处理任何读写请求,无法对外提供服务。
2)bgsave命令
下面的命令可以异步执行RDB:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dVs393is-1691852602647)(assets/image-20210725144725943.png)]](https://img-blog.csdnimg.cn/815626322c4246f0bf16819e635621ad.png)
这个命令执行后会开启独立进程完成RDB,主进程可以持续处理用户请求,不受影响。
background save ,后台运行 save
bgsave 命令会使服务器进程 redis-server 生成一个子进程,由该子进程负责完成保存过程 。在子进程进行保存过程中,不会阻塞 redis-server 进程对客户端读写请求的处理。
3)停机时
Redis停机时会执行一次save命令,实现RDB持久化。
4)触发RDB条件
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1 # 在 900 秒 内发生 1 次写操作
save 300 10
save 60 10000
RDB的其它配置也可以在redis.conf文件中设置:
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes# RDB文件名称 默认为 dump.rdb
dbfilename dump.rdb # 文件保存的路径目录
dir ./
1.1.2 RDB原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1D6BOrJX-1691852602647)(assets/image-20210725151319695.png)]](https://img-blog.csdnimg.cn/626fdbf3e39b4eb886a70d458924b47f.png)
1.1.3 小结
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
RDB会在什么时候执行?save 60 1000代表什么含义?
- 默认是服务停止时
- 代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
1.2 AOF持久化
1.2.1 AOF原理
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
指 Redis 将每一次的写操作都以日志的形式记录到一个 AOF文件中的持久化技术。当需要恢复内存数据时,将这些写操作重新执行一次,便会恢复到之前的内存数据状态。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eX61jeir-1691852602648)(assets/image-20210725151543640.png)]](https://img-blog.csdnimg.cn/868ccc1577f84b2695e959400ac202fa.png)
1.2.2 AOF配置
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no
appendonly yes# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配:
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always # 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec # 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
三种策略对比:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dTei06Dl-1691852602648)(assets/image-20210725151654046.png)]](https://img-blog.csdnimg.cn/5408aa82256d4fe7a6151d66881f6e49.png)
1.2.3 AOF文件重写
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能(Rewrite 机制),用最少的命令达到相同效果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V8jHsUqu-1691852602649)(assets/image-20210725151729118.png)]](https://img-blog.csdnimg.cn/5fc4188c8735460ea21b083505b9d0e6.png)
如图,AOF原本有三个命令,但是set num 123 和 set num 666都是对num的操作,第二次会覆盖第一次的值,因此第一个命令记录下来没有意义。
所以重写命令后,AOF文件内容就是:mset name jack num 666
Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb

1.2.4 AOF 文件格式
AOF文件包含三类文件:基本文件、增量文件与清单文件。其中基本文件一般为 rdb 格式。
1) RDB文件结构
RDB持久化文件 dump.rdb 整体上有五部分构成:
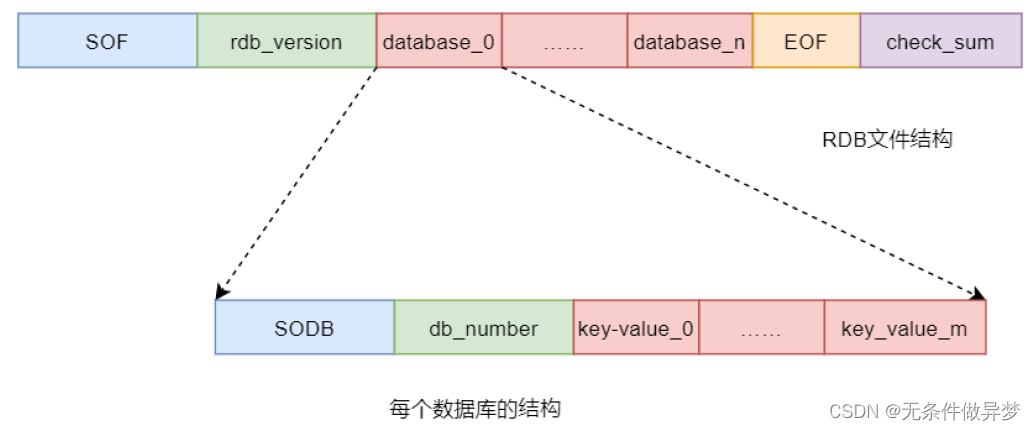
2) Redis 协议
增量文件扩展名为.aof ,采用 AOF 格式。 AOF 格式其实就是 Redis 通讯协议格式, AOF持久化文件的 本质 就 是基于 Redis 通讯协议 的文本 ,将命令以纯文本的方式写入到文件中。
Redis 协议规定, Redis 文本 是以行来划分,每行以 \r \n 行结束。每一行都有一个消息头
以表示消息类型。 消息头 由六种不同的符号表示,其意义如下:
- (+) 表示一个正确的状态 信息
- ((–) 表示一个错误信息
- (*) 表示消息体总共有多少行,不包括当前行
- ($) 表示下一行 消息 数据 的 长度,不包括换行符长度 r n
- (空) 表示一个消息数据
- ( : ) 表示返回一个数值
3) AOF 文件内容
打开 appendonly.aof.1.incr.aof 文件,可以看到如下格式内容:
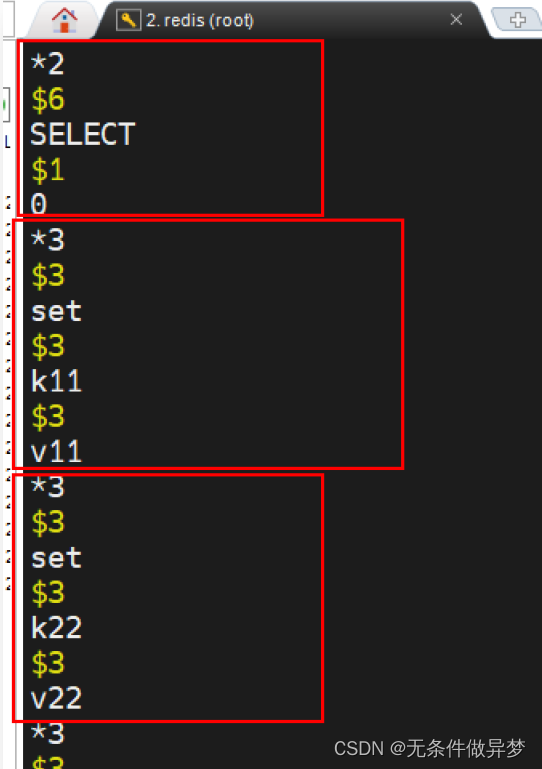
以上内容中框起来的是三条命令。一条数据库切换命令 SELECT 0 ,两条 set 命令。它们的意义如下:

4)清单文件
打开清单文件 appendonly.aof.manifest ,查看其内容如下:

该文件首先会按照 seq 序号列举出所有基本文件,基本文件 type 类型为 b ,然后再按照seq 序号再列举出所有增量文件,增量文件 type 类型为 i 。
对于Redis 启动时的数据恢复,也会按照该文件由上到下依次加载它们中的数据。
1.3 RDB与AOF对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
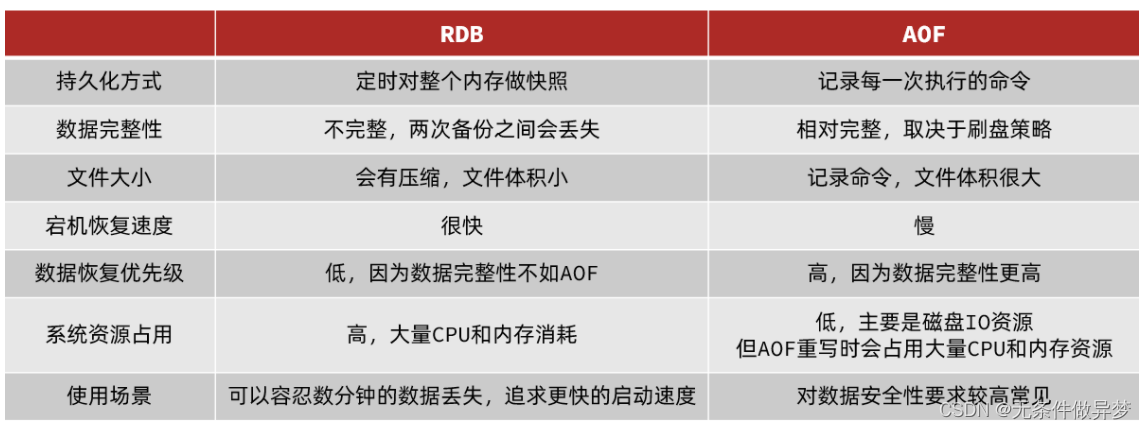
2、Redis主从
2.1 搭建主从架构
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gP8rMhPi-1691852602650)(assets/image-20210725152037611.png)]](https://img-blog.csdnimg.cn/f91443df2f604899bfda412cd56ccdad.png)
2.1.1 伪集群搭建与配置
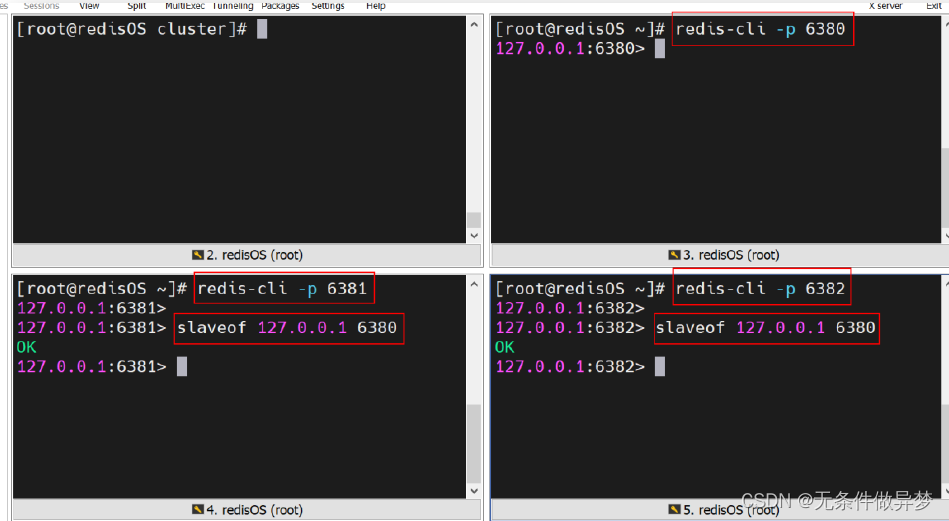
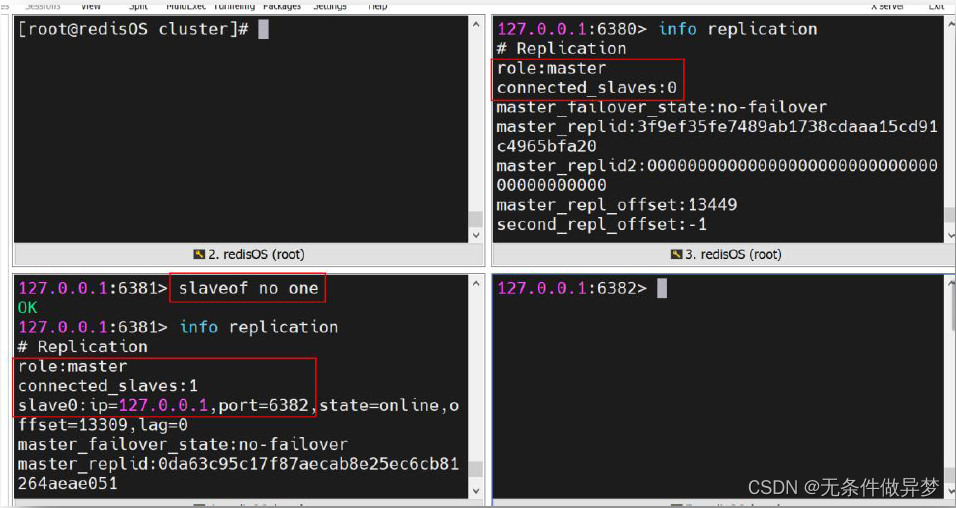
搭建的读写分离伪集群包含一个 Master 与两个 Slave 。 它们的端口号分别是: 6380 、6381 、 6382
步骤:
1) 复制 redis.conf
在redis 安装目录中 mkdir 一个目录,名称随意。这里命名为 cluster 。然后将 redis.conf 文件复制到 cluster 目录中。该文件后面会被其它配置文件包含,所以该文件中需要设置每个 Redis 节点相同的公共的属性。

2)修改 redis.conf
2-a) masterauth

因为我们要搭建主从集群,且每个主机都有可能会是Master ,所以最好不要设置密码验证属性 requirepass 。如果真需要设置,一定要每个主机的密码都设置为相同的(相同的属性: requirepass 与 masterauth)。
2-b) repl-disable-tcp-nodelay
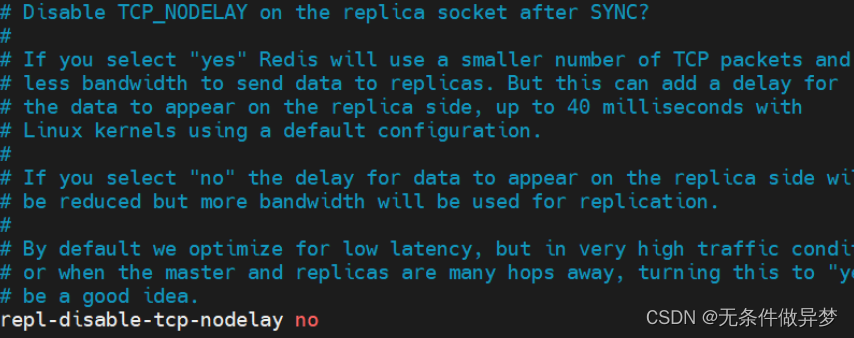
该属性用于设置是否禁用 TCP 特性 tcp-nodelay 。设置为 yes 则禁用 tcp-nodelay ,此时master 与 slave 间的通信会产生延迟,但使用的 TCP 包数量会较少,占用的网络带宽会较小。相反,如果设置为 no ,则网络延迟会变小,但使用的 TCP 包数量会较多,相应占用的网络带宽会大。
tcp-nodelay 则是 TCP 协议中 Nagle 算法的开头。
3) 新建 redis 6380.conf
新建一个redis 配置文件 redis6380.conf ,该配置文件中的 Redis 端口号为 6380 。
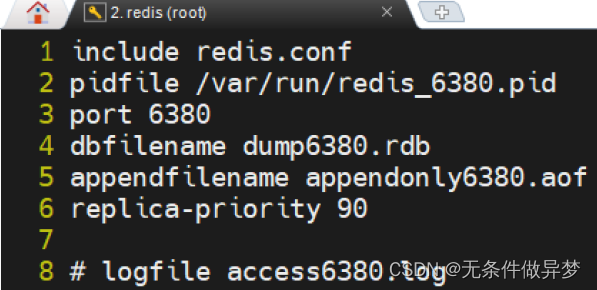
4) 再复制出两个 conf 文件
再使用redis6380.conf 复制出两个 conf 文件: redis6381.conf 与 redis6382.conf 。然后修改其中的内容。

修改内容:
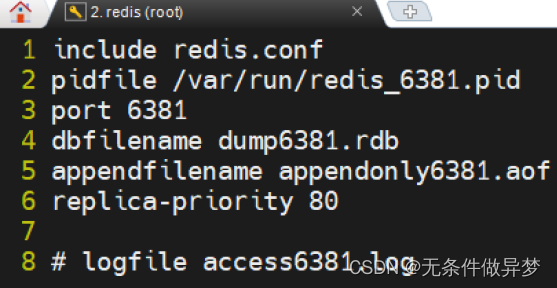
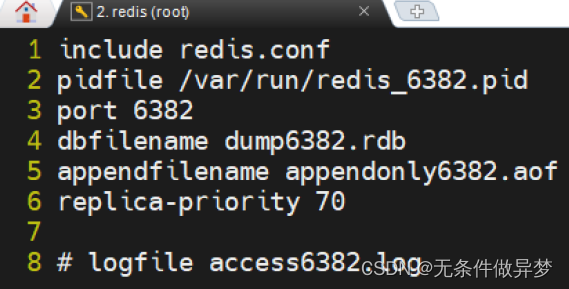
5) 启动三台 Redis
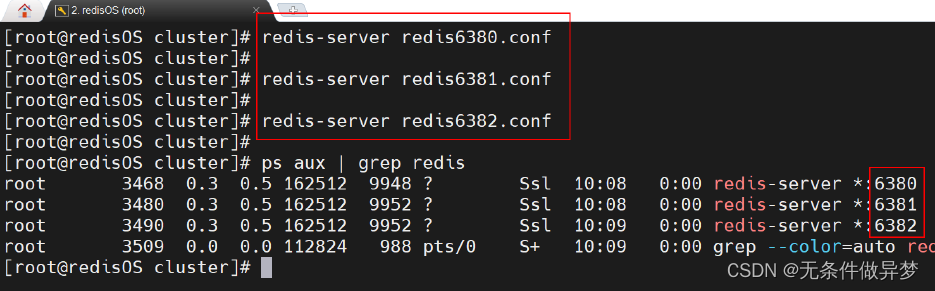
6) 设置主从关系
打开三个会话框,分别使用客户端连接三台Redis 。 然后通过 slaveof 命令,指定 6380的 Redis 为 Master 。
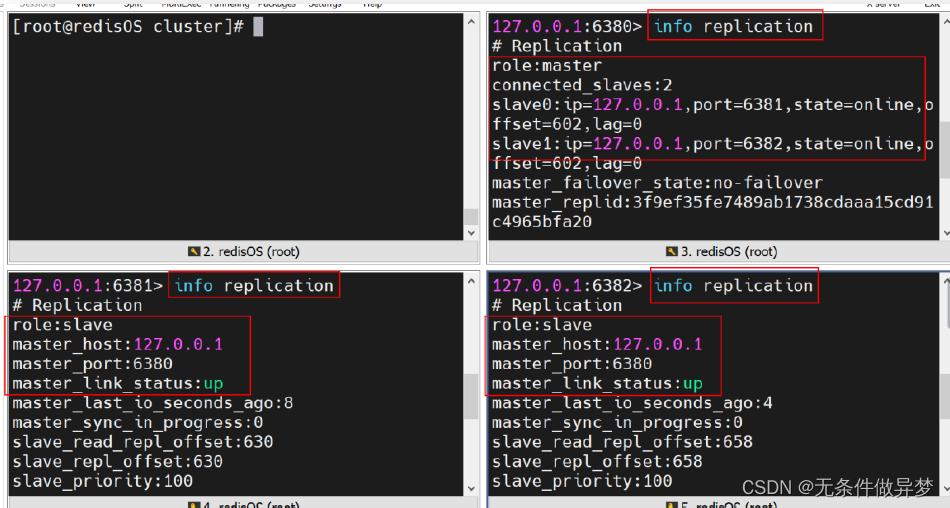
7) 查看状态信息
通过 info replication 命令可查看当前连接的 Redis 的状态信息。
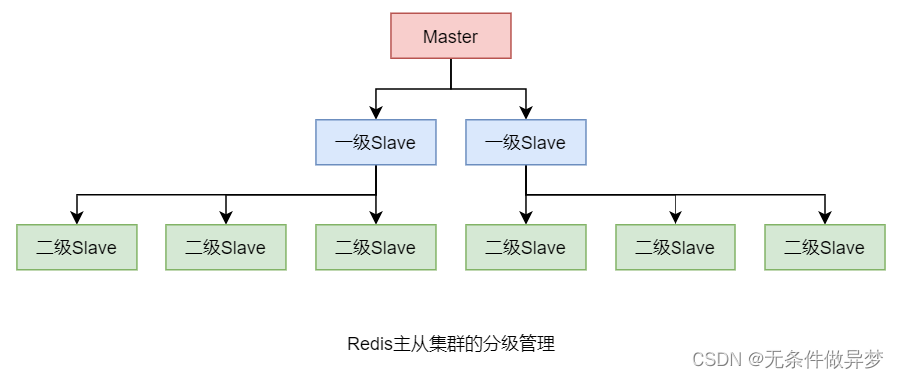
2.1.2 分级管理
若Redis 主从集群中的 Slave 较多时,它们的数据同步过程会对 Master 形成较大的性能压力。此时可以对这些 Slave 进行分级管理。(详细看[4、Redis分片集群])
实现:
例如,指定 6382 主机为 6381 主机的 Slave ,而 6381 主机仍为真正的 Master 的 Slave 。
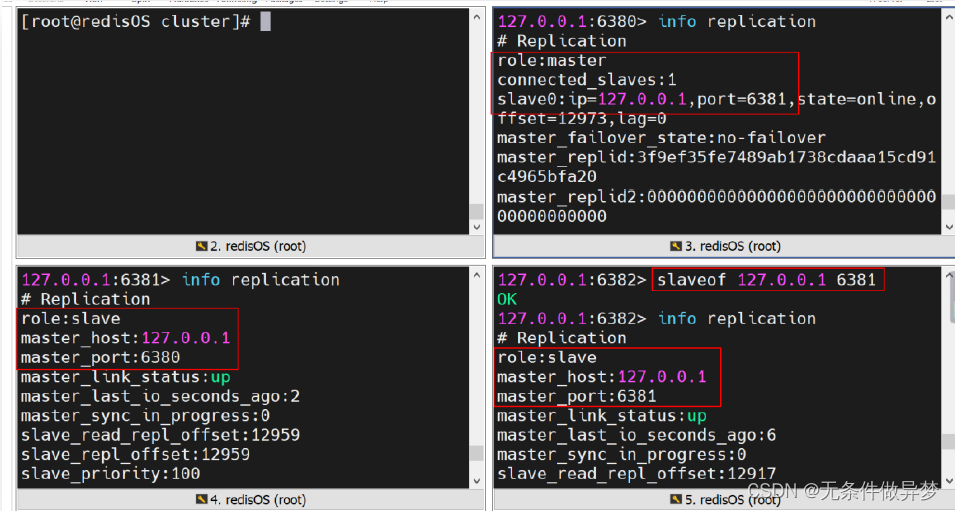
Master 的 Slave 只有 6381 一个主机。
2.1.3 容灾冷处理
在Master/Slave 的 Redis 集群中,若 Master 出现宕机怎么办呢?
有 两种处理方式,一种是通过手工角色调整,使 Slave 晋升为 Master 的冷处理;一种是使用哨兵模式,实现 Redis集群的高可用 HA ,即热处理。
2.2 主从数据同步原理
2.2.1 全量同步
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点,流程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KpD9Wttr-1691852602651)(assets/image-20210725152222497.png)]](https://img-blog.csdnimg.cn/6724715dc8ea42abb85956bccb772b0e.png)
master如何得知salve是第一次来连接呢??
有几个概念,可以作为判断依据:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
因为slave原本也是一个master,有自己的replid和offset,当第一次变成slave,与master建立连接时,发送的replid和offset是自己的replid和offset。
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。
如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f8Abh86Z-1691852602651)(assets/image-20210725152700914.png)]](https://img-blog.csdnimg.cn/490978b71db94dc183e70a46b3a014fd.png)
完整流程描述:
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
2.2.2 增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。
什么是增量同步?就是只更新slave与master存在差异的部分数据。如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bpCzCPiP-1691852602652)(assets/image-20210725153201086.png)]](https://img-blog.csdnimg.cn/e2647665fe754996b94b1198bc7deb76.png)
那么master怎么知道slave与自己的数据差异在哪里呢?
2.2.3 repl_backlog原理
master怎么知道slave与自己的数据差异在哪里呢?
这就要说到全量同步时的repl_baklog文件了。
这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aHjWB3kR-1691852602653)(assets/image-20210725153359022.png)]](https://img-blog.csdnimg.cn/822b21e1c9114b95991538292e1e70f0.png)
slave与master的offset之间的差异,就是salve需要增量拷贝的数据了。
随着不断有数据写入,master的offset逐渐变大,slave也不断的拷贝,追赶master的offset:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vVvV6LEG-1691852602653)(assets/image-20210725153524190.png)]](https://img-blog.csdnimg.cn/3429ec4a599e4abebc968808c702c5d2.png)
直到数组被填满:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z1g2tHhA-1691852602654)(assets/image-20210725153715910.png)]](https://img-blog.csdnimg.cn/53f3c212a1fd4f62b5e1afcb4ac36ca5.png)
此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分。
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dgURvUVn-1691852602654)(assets/image-20210725153937031.png)]](https://img-blog.csdnimg.cn/657e15bad1a44a3fb6689beac733c094.png)
如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VTL8aQ5D-1691852602655)(assets/image-20210725154155984.png)]](https://img-blog.csdnimg.cn/22251050664d40c886dd74c3966ce7a2.png)
棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v9nAMIDJ-1691852602655)(assets/image-20210725154216392.png)]](https://img-blog.csdnimg.cn/dad73c6d6adb4e3dab42827607c4baed.png)
2.3 主从同步优化
主从同步可以保证主从数据的一致性,非常重要。
可以从以下几个方面来优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
主从从架构图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6MMHh2oc-1691852602656)(assets/image-20210725154405899.png)]](https://img-blog.csdnimg.cn/66890ab3e2eb4912876a87ec49eb5d4d.png)
2.4 小结
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
3、Redis哨兵
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。
3.1 哨兵原理
3.1.1 集群结构和作用
哨兵的结构如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BRs3NwqU-1691852602656)(assets/image-20210725154528072.png)]](https://img-blog.csdnimg.cn/b4abf0cc6bc64bbfb234fa0c62099364.png)
哨兵的作用如下:
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
3.1.2 集群监控原理
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
•主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
•客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-06nNB4WR-1691852602656)(assets/image-20210725154632354.png)]](https://img-blog.csdnimg.cn/b0263e5c24c84c3aaa8155d3ed38f0b2.png)
3.1.3 集群故障恢复原理
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。
当选出一个新的master后,该如何实现切换呢?
流程如下:
- sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
- sentinel给所有其它slave发送slaveof 192.168.150.101 7002 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rW3qczTq-1691852602657)(assets/image-20210725154816841.png)]](https://img-blog.csdnimg.cn/b03a4027285649bdaac94a5d5b63dc0e.png)
3.1.4 小结
Sentinel的三个作用是什么?
- 监控
- 故障转移
- 通知
Sentinel如何判断一个redis实例是否健康?
- 每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线
- 如果大多数sentinel都认为实例主观下线,则判定服务下线
故障转移步骤有哪些?
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有节点都执行slaveof 新master
- 修改故障节点配置,添加slaveof 新master
3.2 搭建哨兵集群
3.3 RedisTemplate
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
下面,我们通过一个测试来实现RedisTemplate集成哨兵机制。
3.3.1 导入Demo工程
3.3.2 引入依赖
在项目的pom文件中引入依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
3.3.3 配置Redis地址
然后在配置文件application.yml中指定redis的sentinel相关信息:
spring:redis:sentinel:master: mymasternodes:- 192.168.150.101:27001- 192.168.150.101:27002- 192.168.150.101:27003
3.3.4 配置读写分离
在项目的启动类中,添加一个新的bean:
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
这个bean中配置的就是读写策略,包括四种:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
4、Redis分片集群
4.1 搭建分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
-
海量数据存储问题
-
高并发写的问题
使用分片集群可以解决上述问题,如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cyGa6z8p-1691852602659)(assets/image-20210725155747294.png)]](https://img-blog.csdnimg.cn/42813a3b009f443e8c4770aa5983f301.png)
分片集群特征:
-
集群中有多个master,每个master保存不同数据
-
每个master都可以有多个slave节点
-
master之间通过ping监测彼此健康状态
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
4.2 散列插槽
4.2.1 插槽原理
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4twreoTa-1691852602660)(assets/image-20210725155820320.png)]](https://img-blog.csdnimg.cn/0e2f238a4cf44db6a9864eb640dee9e1.png)
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FcAvoShh-1691852602660)(assets/image-20210725155850200.png)]](https://img-blog.csdnimg.cn/03b0d9ad173f4e01abc04549802a72c2.png)
如图,在7001这个节点执行set a 1时,对a做hash运算,对16384取余,得到的结果是15495,因此要存储到103节点。
到了7003后,执行get num时,对num做hash运算,对16384取余,得到的结果是2765,因此需要切换到7001节点
4.2.1 小结
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
4.3 集群伸缩
redis-cli --cluster提供了很多操作集群的命令,可以通过下面方式查看:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6lsmK2hz-1691852602661)(assets/image-20210725160138290.png)]](https://img-blog.csdnimg.cn/8d29d0b5902441da85dd3af2795ee9fb.png)
比如,添加节点的命令:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JqRvNlMQ-1691852602661)(assets/image-20210725160448139.png)]](https://img-blog.csdnimg.cn/9d2d4638892b4314b45ede9e2c5add50.png)
4.3.1 需求分析
需求:向集群中添加一个新的master节点,并向其中存储 num = 10
- 启动一个新的redis实例,端口为7004
- 添加7004到之前的集群,并作为一个master节点
- 给7004节点分配插槽,使得num这个key可以存储到7004实例
这里需要两个新的功能:
- 添加一个节点到集群中
- 将部分插槽分配到新插槽
4.3.2 创建新的redis实例
创建一个文件夹:
mkdir 7004
拷贝配置文件:
cp redis.conf /7004
修改配置文件:
sed /s/6379/7004/g 7004/redis.conf
启动
redis-server 7004/redis.conf
4.3.3 添加新节点到redis
添加节点的语法如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dSt3J3Xo-1691852602662)(assets/image-20210725160448139.png)]](https://img-blog.csdnimg.cn/9f29c01dc4ed42a99983930b7d7d4663.png)
执行命令:
redis-cli --cluster add-node 192.168.150.101:7004 192.168.150.101:7001
通过命令查看集群状态:
redis-cli -p 7001 cluster nodes
如图,7004加入了集群,并且默认是一个master节点:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Dq7yJww-1691852602662)(assets/image-20210725161007099.png)]](https://img-blog.csdnimg.cn/f056f3b9296146afa8d5d6b97fde33b0.png)
但是,可以看到7004节点的插槽数量为0,因此没有任何数据可以存储到7004上
4.3.4 转移插槽
我们要将num存储到7004节点,因此需要先看看num的插槽是多少:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hcnawKj3-1691852602663)(assets/image-20210725161241793.png)]](https://img-blog.csdnimg.cn/19cab20074ad480796f10c9a3f6d1f71.png)
如上图所示,num的插槽为2765.
我们可以将0~3000的插槽从7001转移到7004,命令格式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hBN6pXDd-1691852602663)(assets/image-20210725161401925.png)]](https://img-blog.csdnimg.cn/866b76ac2b24468d9b1e88e94853c69b.png)
具体命令如下:
建立连接:

得到下面的反馈:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7uW92zsR-1691852602664)(assets/image-20210725161540841.png)]](https://img-blog.csdnimg.cn/549abc953a474f518e377fd0590d0a40.png)
询问要移动多少个插槽,我们计划是3000个:
新的问题来了:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nFPG9HF6-1691852602666)(assets/image-20210725161637152.png)]](https://img-blog.csdnimg.cn/7a55dd68bedf40a787c75595c8fa469d.png)
那个node来接收这些插槽??
显然是7004,那么7004节点的id是多少呢?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TCpq2or3-1691852602666)(assets/image-20210725161731738.png)]](https://img-blog.csdnimg.cn/20618fda8abf4e088a9360d997e16fd6.png)
复制这个id,然后拷贝到刚才的控制台后:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SaLWQMBB-1691852602667)(assets/image-20210725161817642.png)]](https://img-blog.csdnimg.cn/1d8a695117cb486b946632ccde69de1a.png)
这里询问,你的插槽是从哪里移动过来的?
- all:代表全部,也就是三个节点各转移一部分
- 具体的id:目标节点的id
- done:没有了
这里我们要从7001获取,因此填写7001的id:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0WMY1yOX-1691852602667)(assets/image-20210725162030478.png)]](https://img-blog.csdnimg.cn/08a658b515cd4c5ba233ffcd653259bf.png)
填完后,点击done,这样插槽转移就准备好了:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oCE1XSNu-1691852602668)(assets/image-20210725162101228.png)]](https://img-blog.csdnimg.cn/a55189f80780484e9053db2e8e127059.png)
确认要转移吗?输入yes:
然后,通过命令查看结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MCWiUqQ3-1691852602668)(assets/image-20210725162145497.png)]](https://img-blog.csdnimg.cn/5d3388957789434ea17ae54c09a4b2ac.png)
可以看到:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oxTms0sV-1691852602668)(assets/image-20210725162224058.png)]](https://img-blog.csdnimg.cn/0198ba3bac154167a0869b5f57cec24c.png)
目的达成。
4.4 故障转移
集群初识状态是这样的:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2GnkYKWB-1691852602669)(assets/image-20210727161152065.png)]](https://img-blog.csdnimg.cn/aba20f27296543cfa3fd3c0941d0fa08.png)
其中7001、7002、7003都是master,我们计划让7002宕机。
4.4.1.自动故障转移
当集群中有一个master宕机会发生什么呢?
直接停止一个redis实例,例如7002:
redis-cli -p 7002 shutdown
1)首先是该实例与其它实例失去连接
2)然后是疑似宕机:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rg0hT3W1-1691852602669)(assets/image-20210725162319490.png)]](https://img-blog.csdnimg.cn/9d47ea38439d4e6d8bf37560a0d993b2.png)
3)最后是确定下线,自动提升一个slave为新的master:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4A0yTwzR-1691852602670)(assets/image-20210725162408979.png)]](https://img-blog.csdnimg.cn/b4a0fa7e9c3046eda0d5b6ef8b0f24b5.png)
4)当7002再次启动,就会变为一个slave节点了:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4p13TWs0-1691852602670)(assets/image-20210727160803386.png)]](https://img-blog.csdnimg.cn/c202a6c9c8d64a37bed75173a4c72f3a.png)
4.4.2 手动故障转移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。其流程如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7ZivJH5K-1691852602670)(assets/image-20210725162441407.png)]](https://img-blog.csdnimg.cn/3fe21d002eec47a584774997703eb413.png)
这种failover命令可以指定三种模式:
- 缺省:默认的流程,如图1~6歩
- force:省略了对offset的一致性校验
- takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见
案例需求:在7002这个slave节点执行手动故障转移,重新夺回master地位
步骤如下:
1)利用redis-cli连接7002这个节点
2)执行cluster failover命令
如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DqxQs1Ah-1691852602671)(assets/image-20210727160037766.png)]](https://img-blog.csdnimg.cn/9a0023e3a8fb469ba252d94b258c5bc5.png)
效果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1MOqbAJc-1691852602671)(assets/image-20210727161152065.png)]](https://img-blog.csdnimg.cn/76917910eb1e4a8c94105b7208dc4585.png)
4.5 RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
1)引入redis的starter依赖
2)配置分片集群地址
3)配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:redis:cluster:nodes:- 192.168.150.101:7001-