一、说明
卡塔尔世界杯充满了惊喜!从沙特阿拉伯通过击败阿根廷震惊世界到摩洛哥历史性地进入半决赛,你必须听到或见证那些足球热潮中的时刻。在这篇文章中,我将使用 BERTopic 来分析 2022 年世界杯期间发布的推文。让我们看看与世界杯相关的最受欢迎的话题是什么,以及我们是否可以理解这些话题。
二、准备数据
,我们需要从社交媒体中检索数据。这一次,我将使用从Twitter检索到的文本数据作为我们的研究对象。为了抓取推文,我们将使用snscrape,这是Facebook,Twitter和Reddit等社交网络服务的抓取工具。要安装开发版本,请执行以下操作:
pip install git+https://github.com/JustAnotherArchivist/snscrape.git使用此抓取工具,我们可以从 Twitter 获取属性用户、用户个人资料、主题标签、搜索(实时推文、热门推文和用户)、推文(单个或周围线程)、列表帖子、社区和趋势。要启动嗅探:
# Get tweets using SNSCRAPE
import snscrape.modules.twitter as sntwitter
import pandas as pd然后,让我们获取一些用英语写的推文,其中包含搜索词:世界杯,从 20 年 18 月 2022 日到 2022 月 12 日。注意:由于我们只想要推文而不是回复,因此我们会过滤掉回复。在这里,我们需要更加小心时间框架。应使用以下方法设置时间段:直到:19–00–00_00:2022:11_AST 自:20–00–00_00:2022:12_AST。因为 till 子句中的时间会被排除在外,我们应该将其设置为 19-0-<> <> 点钟。AST 表示 阿拉伯标准时间。如果我们没有在 AST 中指定时间,时间将自动以 UTC 格式设置。
# Get 10,000 tweets containing search term: world cup within a certain period of time
query = "(world cup) lang:en until:2022-12-19_00:00:00_AST since:2022-11-20_00:00:00_AST -filter:replies"
tweets = []
limit = 10000for tweet in sntwitter.TwitterSearchScraper(query).get_items():if len(tweets) == limit:breakelse:tweets.append([tweet.date, tweet.id, tweet.username, tweet.content])# Store tweets under a data frame
df = pd.DataFrame(tweets, columns=['Date', 'Id', 'User', 'Tweet'])三、预处理数据
当我们处理非结构化文本数据时,在运行任何分析之前我们需要做的一件事是预处理数据。在这里,我们将删除推文中的所有 URL、表情符号和换行符。我建议在每一轮数据清理后打印出一些样本,看看我们是否以我们想要的方式操作文本。另外,当您完成所有数据清理后,我建议使用pickle保存最终版本。如果我们需要使用数据集执行不同的任务,我们可以简单地加载腌制的数据,而不是再次从头开始抓取。
# Round1: Remove URL
df['Tweet']=df['Tweet'].str.replace('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', ' ')
# df.head()# Round2: Remove emoji
df['Tweet']=df['Tweet'].str.replace('[^\w\s#@/:%.,_-]', '', flags=re.UNICODE)
# df.head()# Round3: Remove newlines:\n
df['Tweet_processed'] = df['Tweet'].replace('\n','', regex=True)
# df.head()# Store the filtered tweets in a new data frame
df_new=df.drop('Tweet',axis=1)
# df_new.head()df_new.to_pickle('world_cup_tweets.pkl')四、使用 BERTopic
BERTopic 是一种主题建模技术,它利用转换器和基于自定义类的 TF-IDF 来创建密集的集群,允许易于解释的主题,同时在主题描述中保留重要单词。要安装 BERTopic:
pip install bertopic然后我们将推文存储在列表中,并使用以下代码实例化 BERTopic。请耐心等待,因为此过程可能需要一段时间,具体取决于您正在抓取的推文数量以及您使用的是 CPU(较慢)还是 GPU(较快)。
texts=df_new['Tweet_processed']# Set the language to English. There is other language models as well.
from bertopic import BERTopic
topic_model = BERTopic(language="english", calculate_probabilities=True, verbose=True)
topics, probs = topic_model.fit_transform(texts)五、提取主题
拟合模型后,我们可以看到一些结果。首先,我们可以检查 10 个最常见的主题:
freq = topic_model.get_topic_info(); freq.head(11)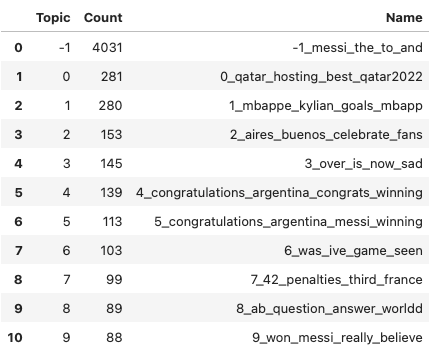
-1 表示所有异常值,应忽略。接下来,让我们看一下生成的一个常见主题:
topic_model.get_topic(0) # Select the most frequent topic, which is topic 0# Result
[('qatar', 0.03543929861004061),('hosting', 0.01386799885558573),('best', 0.012979749598061752),('qatar2022', 0.011693988492318397),('thank', 0.01145218957158738),('ever', 0.011044699651033682),('tournament', 0.008304478567760317),('hosted', 0.007997848070012806),('you', 0.007665018845225487),('the', 0.007350426929036396)]正如我们所看到的,这个话题指的是足球迷对东道国卡塔尔表示感谢。尽管卡塔尔世界杯从头到尾都有争议,但最终球迷们还是赞赏东道主为这项赛事所做的努力。我们也可以看看主题0下的三条有代表性的推文:
topic_model.get_representative_docs(0)# Result
['Critics sceptical of Qatars carbon neutrality claim at #WorldCup ','Apart from Messi being the highlight of the WC, this tournament has been a huge success for Qatar itself. From the stunning venues to the welcoming and hospitable atmosphere, the tournament has truly shone, making this World Cup truly one to remember. Congratulations Qatar ','With the World Cup over, that means no more Tracey Holmes doing Qatar propaganda']六、可视化前 10 个主题
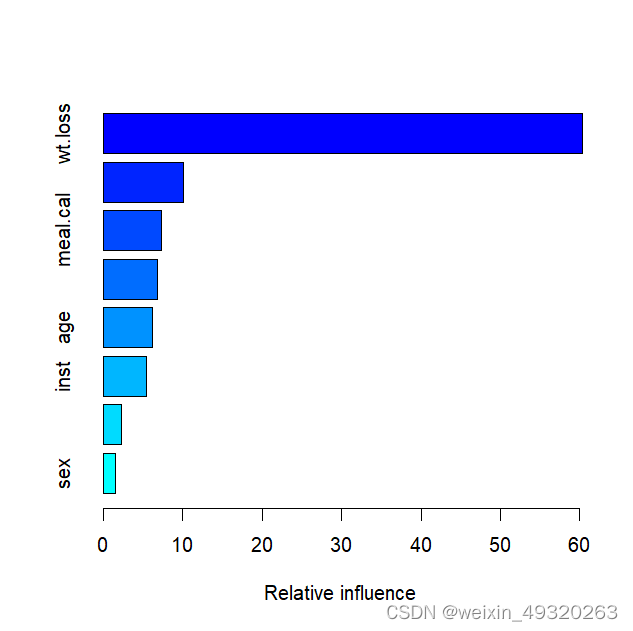
我们可以使用以下方法更清楚地了解最常见的 10 个主题:
topic_model.visualize_barchart(top_n_topics=10)
七、加载数据
在第 1 部分教程中,我将数据保存在名为“world_cup_tweets.pkl”下。现在我们可以解腌它,使用:
import pandas as pd
import pickle
with open('world_cup_tweets.pkl', 'rb') as f:data = pickle.load(f)八、动态主题建模
“动态主题建模(DTM)是一组技术,旨在分析主题随时间的变化。这些方法可以让你了解一个主题在不同时间是如何表示的。
为了表示不同的时间段,我们可以创建一个推文列表及其相应的发布时间。然后我们需要创建和训练一个 BERTopic 模型,就像我们在第 1 部分中所做的那样:
timestamps = data.Date.to_list()
tweets = data.Tweet_processed.to_list()from bertopic import BERTopic
topic_model = BERTopic(language="english", calculate_probabilities=True, verbose=True)
topics, probs = topic_model.fit_transform(tweets)现在我们应该打电话给topics_over_time并传递推文和时间戳。请注意,箱表示用于对图表中的值进行分组的连续值的单个范围。如果一个箱宽太大,我们将得不到足够的区分;如果太小,则无法正确分组数据。在这里,我们将箱的数量设置为 20。并可视化前 10 个主题。
topics_over_time = topic_model.topics_over_time(tweets, timestamps, nr_bins=20)
topic_model.visualize_topics_over_time(topics_over_time, top_n_topics=10)九、结果:
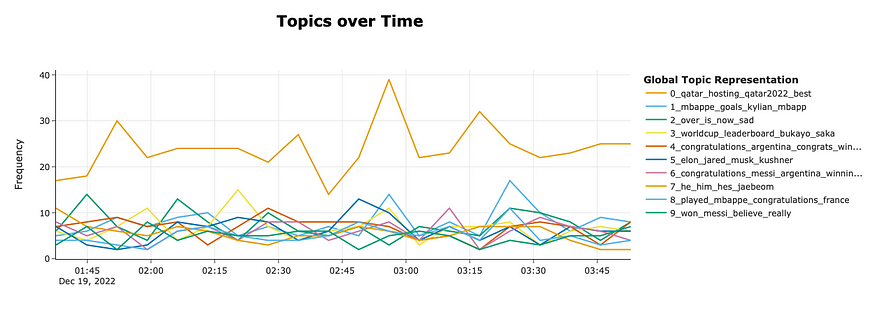
从这张图中,我们可以很容易地掌握不同主题如何随着时间的推移而出现。这不是很方便吗!
十、总结
在这篇文章中,我们学习了如何使用snscrape抓取推文,以及如何使用BERTopic通过卡塔尔世界杯案例研究对主题进行建模。结果显示,球迷们普遍认可卡塔尔所做的努力,并对阿根廷和法国之间激动人心的决赛感到惊讶。
BERTopic具有更多惊人的功能,例如动态主题建模(DTM)。我将很快向您展示如何实现它。暂时再见,敬请期待!