整理并翻译自DeepLearning.AI×LangChain的官方课程:Question Answer(源代码可见)
本节介绍使用LangChian构建文档上的问答系统,可以实现给定一个PDF文档,询问关于文档上出现过的某个信息点,LLM可以给出关于该信息点的详情信息。这种使用方式比较灵活,因为并没有使用PDF上的文本对模型进行训练就可以实现文档上的信息点问答。本节介绍的Chain也比较常用,它涉及到了嵌入(embedding)和向量存储(vector store)。
(笔者注:embedding指的是将一个实体映射到高维空间,以高维向量的形式存储,以最大限度地capture其信息,自然语言处理使用embedding方式表示单词,即词向量。自然语言处理语境下,embedding都指的是word embedding词嵌入)
首先是一个简单的例子:

下面解释了一下底层原理:
LLM‘s on Documents 文档上的大语言模型

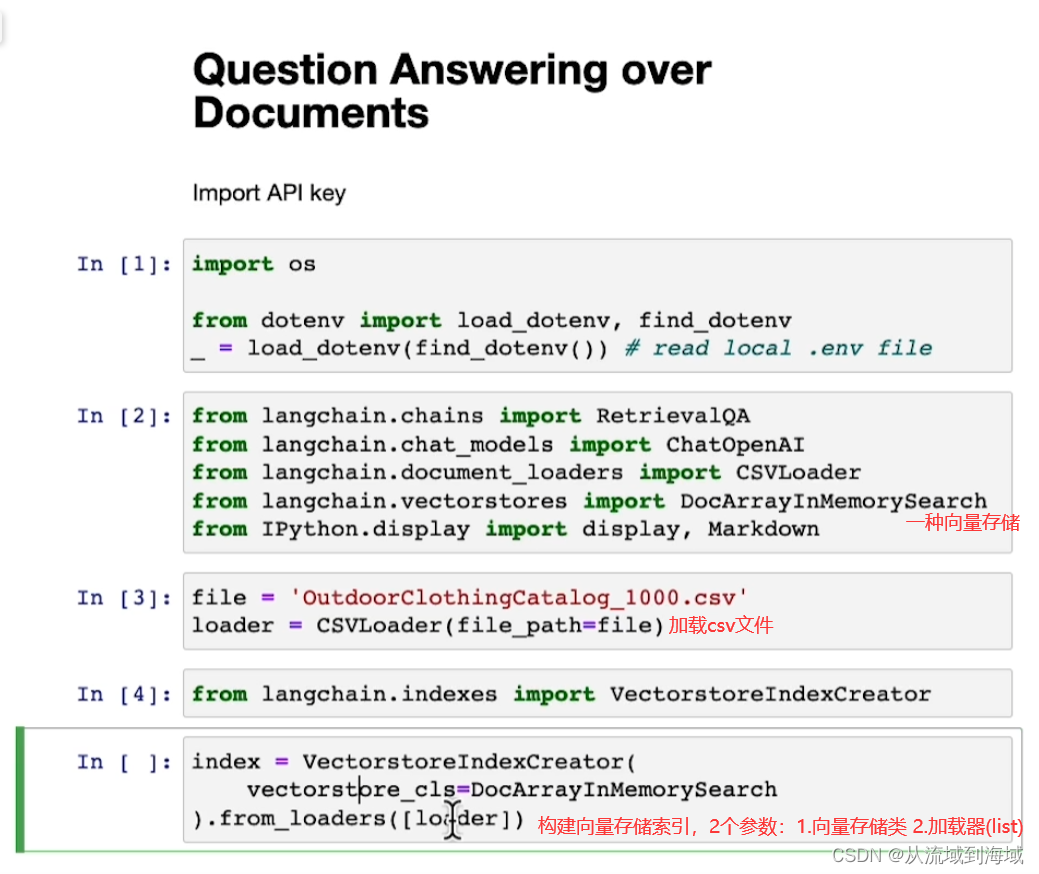
由于最大token数限制,LLM最多只能一次性处理几千个token。因而如果有一个文档级别的信息(远大于几千token),LLM没办法直接处理,因而引入词嵌入(embedding)和向量存储(vector store)来解决这个问题
Embedding 词嵌入
- 嵌入向量捕捉上下文/含义
- 相似(指语义相似)内容地文本对应相似的向量
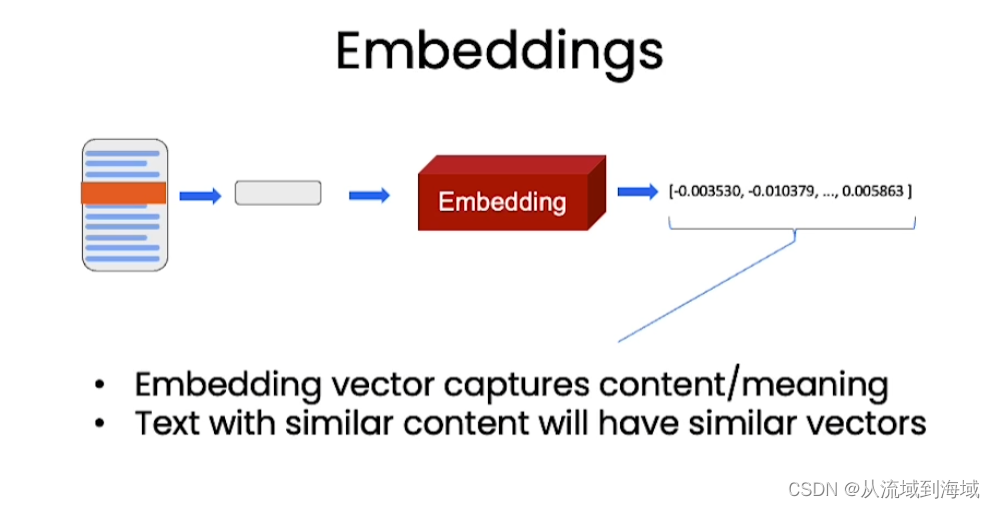
如下图:句子1)和2)语义相似,因而它们的表示向量也相似。

因而我们可以使用表示向量的相似程度来判定两句话的相似程度,在回答文档上的问题时,先找出和提问相似的信息,作为输入喂给LLM,期望LLM能根据相似信息做出解答。
(笔者注:事实上,LLM内部就是将文本转化为词向量(tokenizer)来处理的,直接以向量形式存储节省了文本到向量的转化步骤。)
Vecotor Database 向量数据库
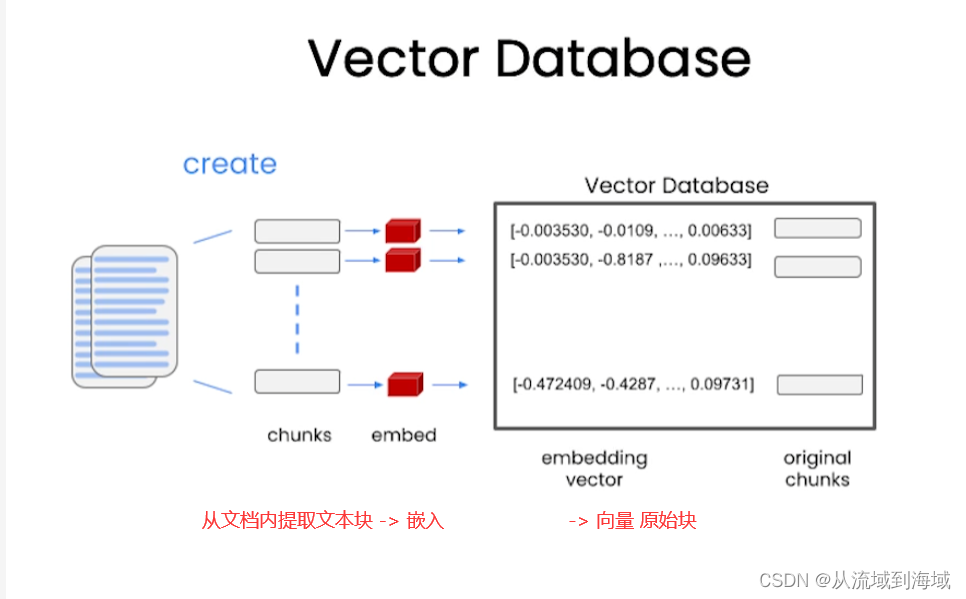
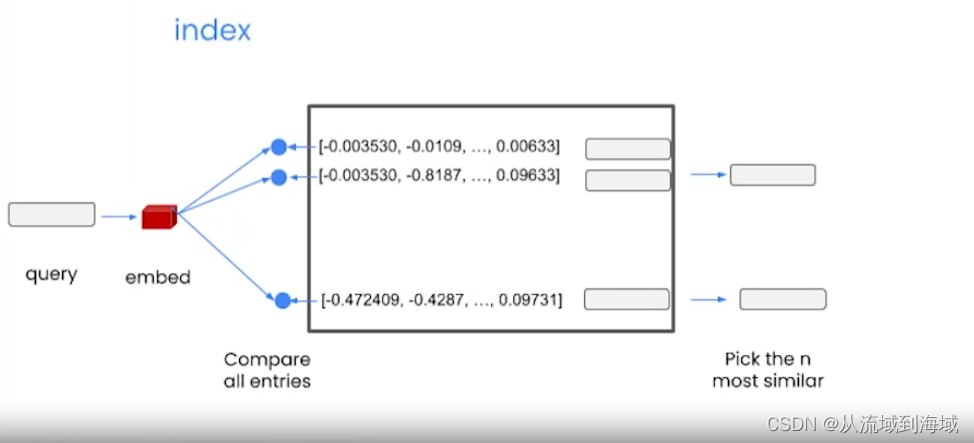
当一个查询输入时,先将其向量化,然后跟向量数据库里面的所有项对比,找出最相似的n项。
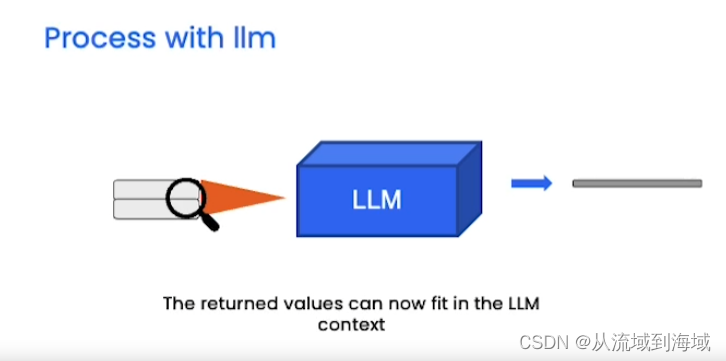
查询结果放入输入的上下文中喂给LLM,得到回复。
下面分步解释过程:

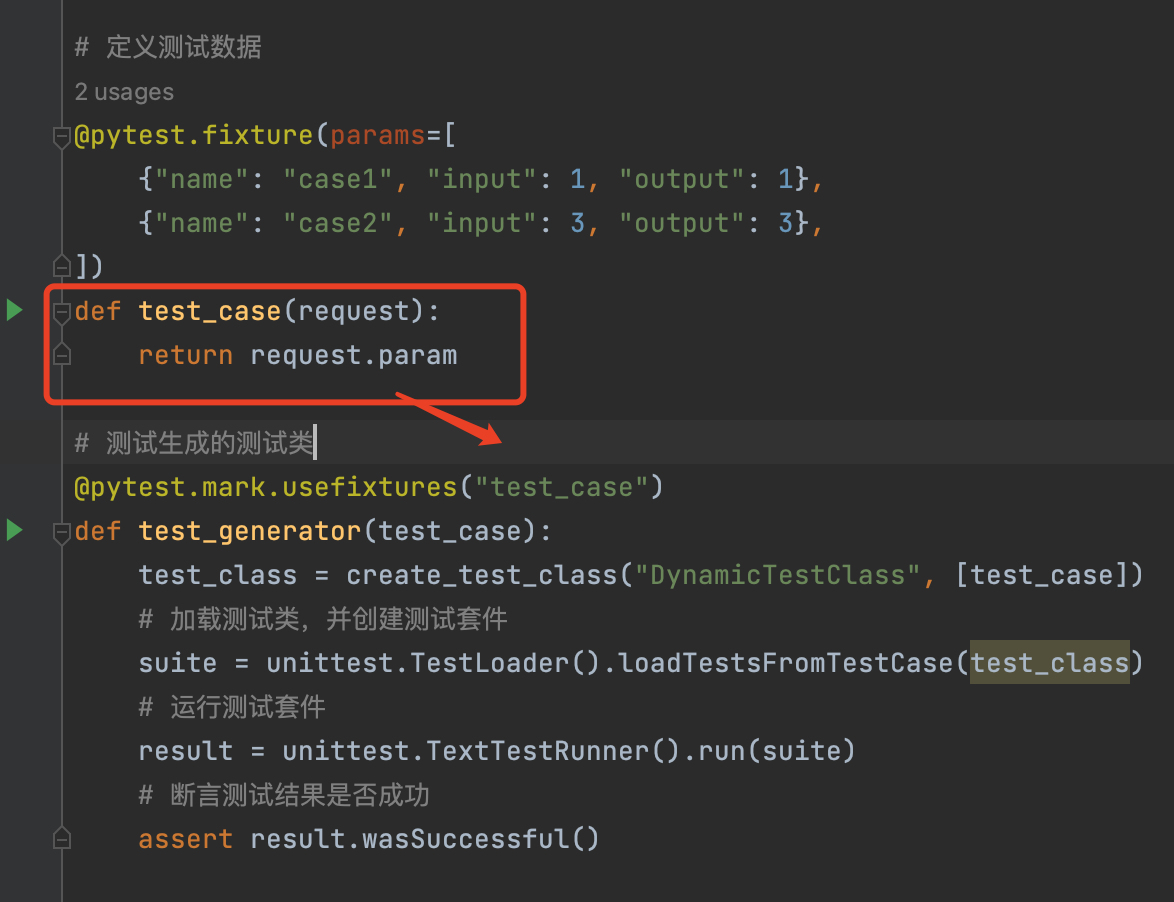
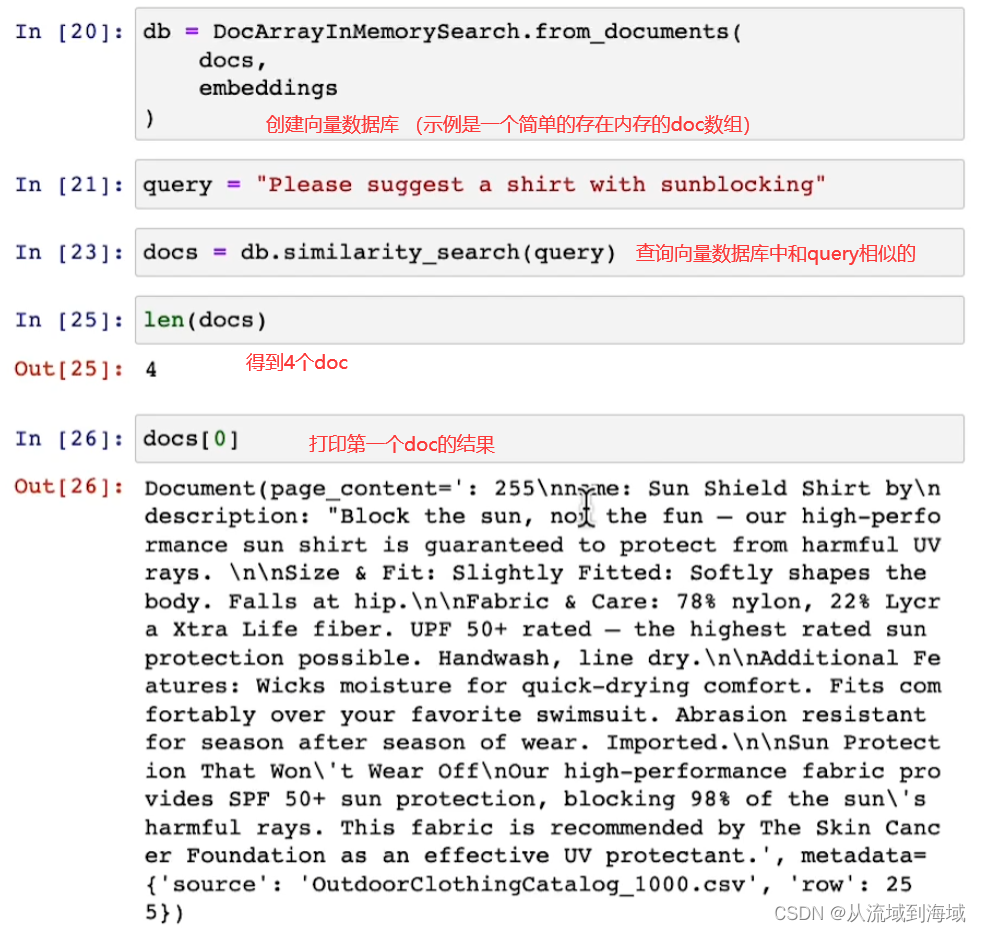
使用CSVLoader对象loader加载一个csv文件,里面存放了户外服装相关信息,打印第一行信息如上图。
因为文本量比较少,不需要分块,因而可以直接创建embedding,查看一个embedding(其实是一组词向量):

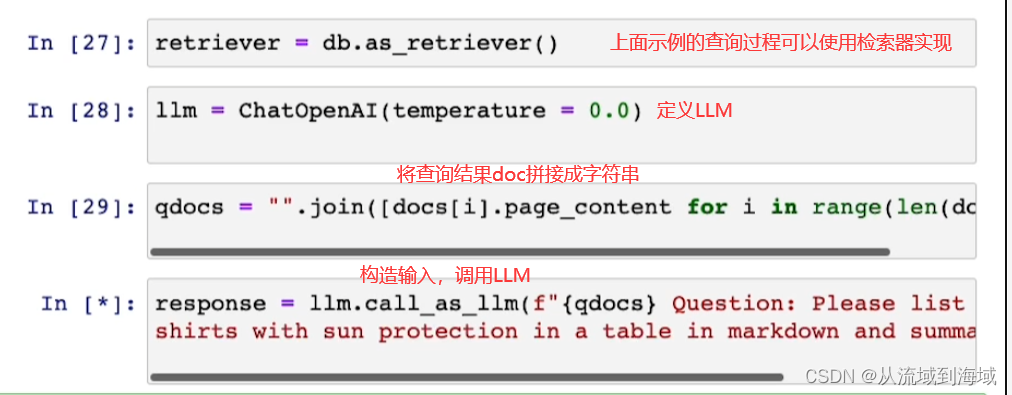

上述过程可以使用RetrievalQA chain轻松实现:


Stuff method 原材料方法

原材料是最简单的方法,只需要将所有的原始数据放到prompt中作为上下文喂给语言模型。
优点:只需调用一次LLM。LLM可以一次性访问所有数据。
缺点:LLM有上下文长度,对于大型文档或者多个文档超过上下文长度时无法生效。
additional methods 额外方法
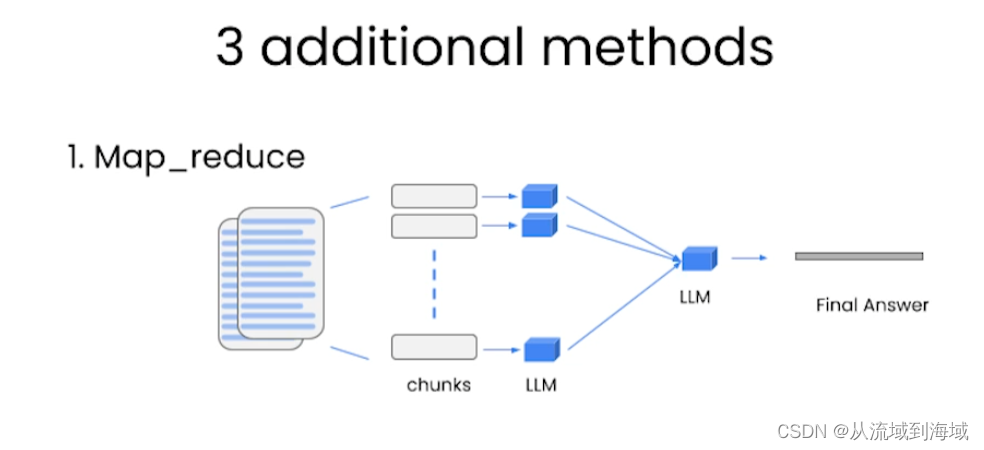
Map_reduce:将文档每一个块和提问一起输入一个LLM中,汇总所有LLM结果,再使用一个LLM处理拿到最终答案。
(很有效,可以处理任意数量的文档,还可以并行,但很贵,且独立对待每一个文档,即忽略了文档之间的关联性)

Refine:从一个块和LLM中得到回复之后,再把结果作为下一轮的输出,不断优化到最后一个块,得到最终结果。
(好处时考虑了文档之间的关联性,和map_reduce代价相同)
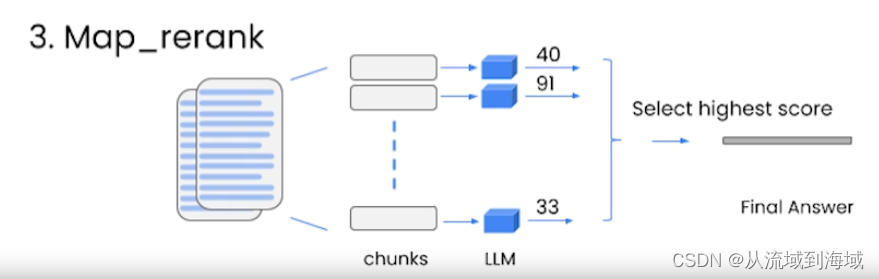
Map_rank:处理所有块,给每一个块和LLM的结果打分,选一个分最高的作为最终结果。
(需要LLM有能力给结果打分,和map_reduce代价相同,也没有考虑文档之间的关联性)

![任我行CRM系统存在 SQL注入漏洞[2023-HW]](https://img-blog.csdnimg.cn/2e763e24b0a04745bb1d7beb0e092d8e.png)