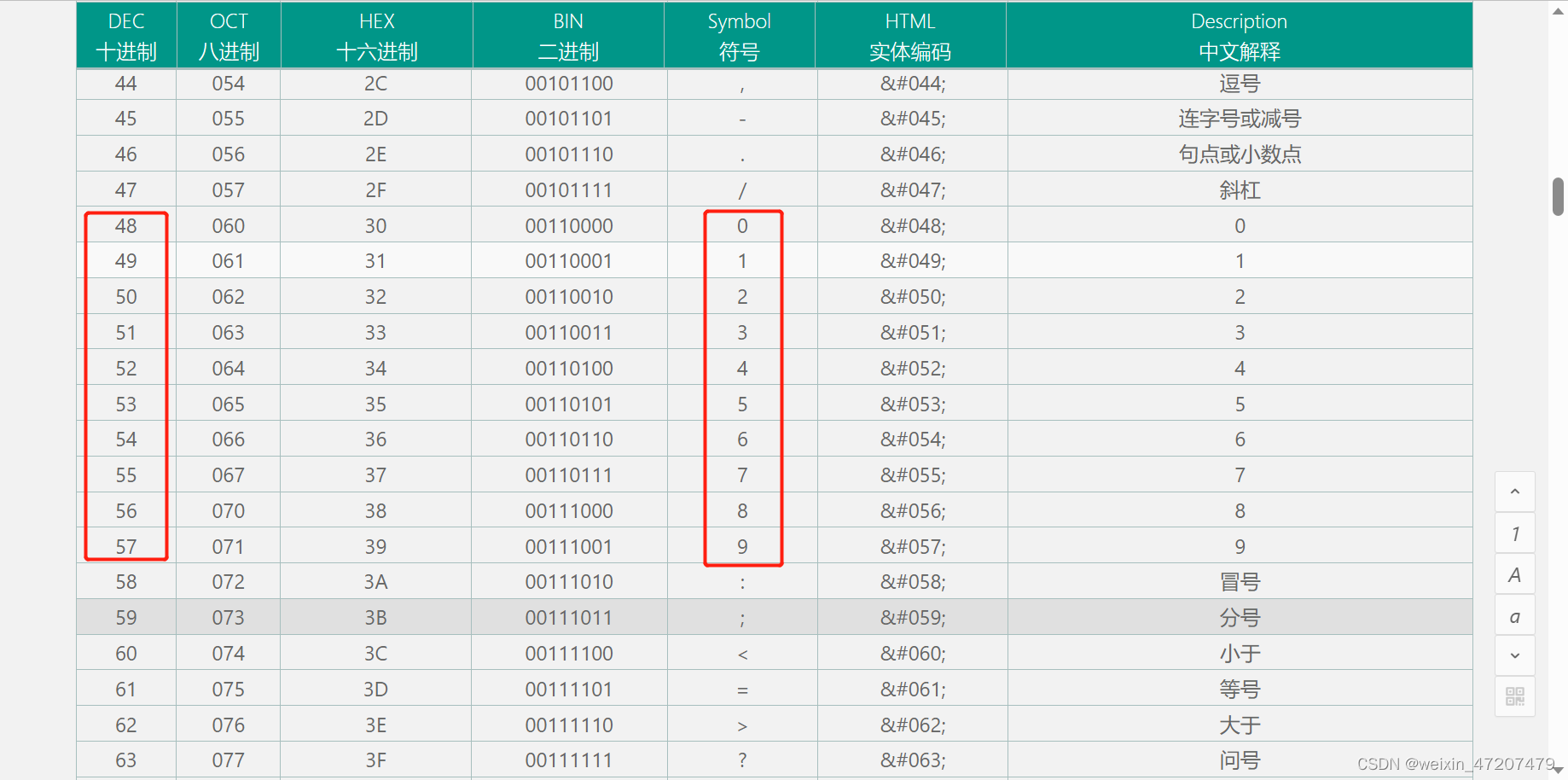
项目场景:
在分布式微服务架构中,远程通信是最基本的需求。 常见的远程通信方式,有基于 REST 架构的 HTTP协议、RPC 框架。
下面,从三个维度了解一下 RPC。
1、什么是远程调用
2、什么是 RPC
3、RPC 的运用场景和优
什么是远程调用?
有的小伙伴误以为,远程调用,是指跨域物理距离的远。 实际上,远程调用是指跨进程的功能调用, 跨进程可以理解成一个计算机节点的多个进程, 或者多个计算机节点的多个进程。 有的小伙伴误认为,远程就是距离远。 其实,远程并不是指距离上的远程,而是指由于进程和进程之间彼跨越进程的。
什么是 RPC?
RPC 的概念与技术其实是比较早的,40 年前,也就是 1981 年由 Nelson 提出。1984 年,Birrell 和把它用于分布式系统间的通讯。Java 在 1.1 版本提供了 Java 版本的 RPC 框架(RMI)。
全称为 Remote Procedure Call,翻译过来就是远程过程调用, 它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议, 凡是符合该协议的框架,我们都可以称它为 RPC 框架。
关于 RPC 协议,通俗来讲就是,A 计算机提供一个服务,B 计算机可以像调用本地服 务那样调用 A 计算机的服务。
要实现 RPC,需要通过网络传输数据,并对调用的过程进行封装。 现在比较流行的 RPC 框架,都会采用 TCP 作为底层传输协议。
RPC 强调的是过程调用,调用的过程对用户而言是是透明的,用户不需要关心调用的细 节,可以像调用本地服务一样调用远程服务。
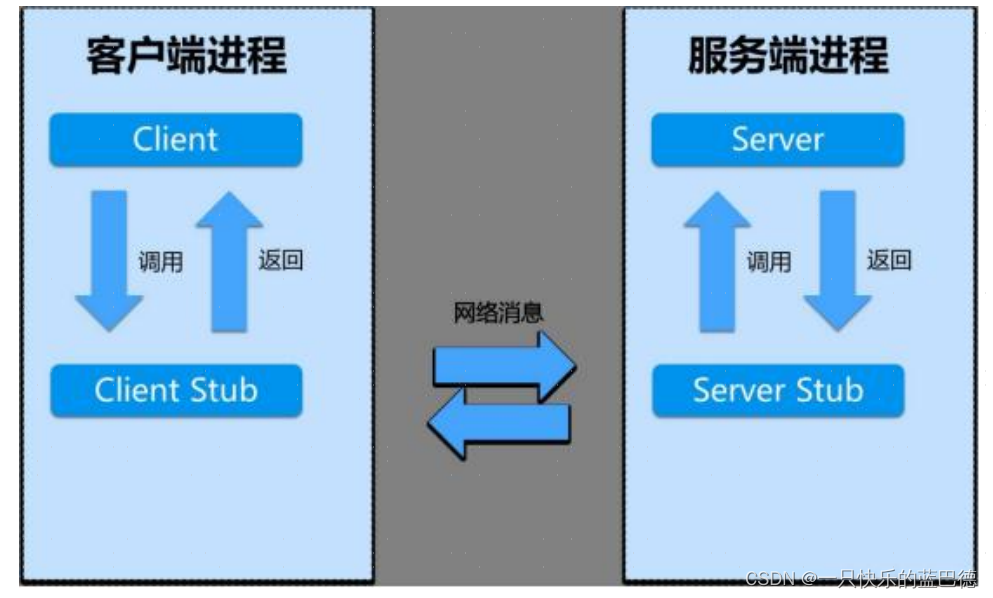
如图所示,一个完整的 RPC 架构里面包含了四个核心的组件,分别是:
1) 客户端(Client),服务的调用方。
2) 服务端(Server),真正的服务提供者。
3) 客户端存根(Client Stub),存放服务端的地址消息,再将客户端的请求参数打包成 网络消息,然后通过网络远程发送给服务方。
4)服务端存根(Server Stub),接收客户端发送过来的消息,将消息解包,并调用本地 的方法。
目前比较流行的开源 RPC 框架有 Google 的 gRPC,Facebook 的 Thrift,阿里巴巴的 Dubbo。
RPC 的运用场景和优势
在开发电商系统时,随着业务越来越复杂,走分布式架构这个方向是绝大部分互联网企 业必然的选择。
分布式架构落地的里程碑,应该是阿里的去 IOE 运动的成功,它让互联网企业看到了, 如何利用更少的软硬件成本来支撑海量的用户。
分布式架构的核心,就是利用多个普通计算机节点,组成一个庞大而复杂的计算网络, 提供高性能以及高并发的能力支撑。
在分布式架构中,原本的单体应用被拆分成多个独立部署的服务分部在计算及网络上, 这些服务必然需要通过网络进行数据交互。 而 RPC 框架就是解决在分布式架构中的各个业务服务彼此的网络通信问题。 一般来说,RPC 服务主要是针对大型的企业,也就说当我们业务复杂度以及用户量都比较高时,需要解耦服务,扩展性强、部署灵活。
一般市面上开源的 PRC 框架,除了提供基础的远程通信功能以外,还会在性能消耗、 传输效率、服务治理等方面做很多的设计,比如阿里开源的 RPC 框架 Dubbo。
补充:
何谓 IOE ?
所谓 IOE 是个简称。是指以 IBM 、Oracle、EMC 为代表的小型机、集中式数据库和高端存储的技术架构。其中 I 指 IBM p 系列小型机,操作系统是 AIX,IBM 专有的 Unix 系统;O 指 Oracle 数据库(RDBMS);E 指 EMC 中高端 SAN 存储,曾经一度是 IT 企业很喜欢采用的技术架构。IOE 这个说法怎么来的? 据我所知应是来自阿里技术团队内部的称谓,然后才在整个业界流传开来。如果你去问国外技术专家什么是 IOE,对方肯定一头雾水。当然,随着国内案例逐渐被介绍到国外,或许某一天这个术语能输出价值观也说不定。
在小型机领域,只有 IBM 这一家,独步武林;HP 当初把宝押在安腾上,算是早早退出这个市场;Sun 日薄西山,SPARC 机器…那就更不必说了。另外,需要说明的是,IBM 也生产存储产品,但 IBM 的存储产品早期其实挺山寨,竞争不过 EMC ,而且有些用户会忌讳把所有的东西困在一家公司身上,尾大不掉。 起码在国内,EMC 的占有率应该更高。中高端存储这个领域,还有一家 HDS,不过曾经一度在阿里也栽过跟头。数据库软件方面,在当初几乎没的选择,只有 Oracle 这一家,IBM 的 DB2 实在是不行,虽然号称市场占有率不错。国内用 Oracle 数据库支撑互联网应用的话,一般是采用 Data Guard 这个架构方案。
为何要「去 IOE」?
说起「去 IOE」,跟阿里的王坚博士有直接关系。我无从得知他当时为什么要做出这个决定。但根据我的推断,当时淘宝、支付宝等公司每家技术体系各有特色,技术团队也各是一套,只有去「去 IOE」,才有可能将淘宝、支付宝等公司的网站核心体系架构迁移到云上,体现阿里云的价值,某些管理者才有可能从集团公司层面对整个技术团队有更好的控制力。否则,阿里云师出无名。注意,这个说法只是我个人臆测,肯定不是事实,只是逻辑上是说得通的。实际上,阿里云当时自己的活儿做的很垃圾,也幸亏这个「去 IOE」运动进行并不那么快。当然这是后话了。
或许有人认为「去 IOE」会节约企业成本,实际上,当时的 Oracle 和 EMC 等软件成本已经足够低,硬件上,硬件上的每年的成本也是可控的,如果考虑迁移后总体成本,新硬件成本、开发人员成本、运维成本、时间成本等等,通通算下来,未必能节约多少。这个不是我拍脑袋给出来的,而是跟不少技术人事后复盘,结论基本一致。
客观的说,当时「去 IOE」有一种公司政治的倾向,或者成为一个一窝蜂的运动,这很令人讨厌,或者说这事情出发点未必如何好,但令人意外的是,最后在阿里诸多优秀技术人才的努力下,却取得了一个令人惊讶的很好的结果,那么,就别管出发点如何了。
为何「去 IOE」是必要的?
从另外一个角度考虑,尤其从运维 DBA 的角度去审视,「去 IOE」 实际上是必须要进行的,或者说去「O」是必须的,因为当时存在的问题是,Oracle 数据库对用户 (DBA) 来说已经不够灵活,常用的 Data Guard 模式无法适应互联网公司快速增长,最基本的一点,读写分离就做不到,只能向上扩展(Scale Up),拼硬件能力,几乎无法做到横向扩展。或许有人说,不是有 RAC 么? 但 Oracle RAC 是无法对付高并发下的 OLTP 应用的 – 一直到现在很多人都认识不到这一点,RAC 跑跑数据仓库什么的倒是不错。
注:有人会说 Orale RDBMS 11g 的 Data Guard 可以读写分离呀,这个所谓的读写分离可靠性其实是不够的,而且出现的时间也太晚了,此外,不够灵活。还会有人争论 Oracle RAC 怎么就不能应付 OLTP 呢? 别争论了,你非要说可以应付,没问题,但是在阿里体系的公司里,还真没人敢这么玩儿,为什么? 是做不到? 还是他们掉进坑过?
如果要动「O」,那么 「I」 和「E」就必须要动 – 相信不会有人在小型机上跑 MySQL 的,而且,只换掉「O」也没有意义,换汤不换药不会有成效。
随着中国电子商务的快速发展,整个阿里系其实已经在面对全世界增长最快最复杂的业务系统之一,这是机遇,也是挑战。旧有的技术架构已经不足以支撑更大的梦想。从这个意义上来说,去「IOE」是相当必要的。或许,这也是王坚博士以及一些人的初衷。
为何「去 IOE」成功了?
阿里几家子公司这么复杂的技术体系,「去 IOE」这事情堪比高速公路上给飞驰的汽车换轮胎,最后成功是相当不容易的。
成功的因素有哪些呢?
1.功不可没的当然是一群出色的技术人才,很了不起。我想这是无需多说的,面对这么复杂的业务环境,这个任务如果没有一批优秀的工程师是绝对做不到的,没有阿里 B2B 技术团队、淘宝团队、支付宝技术团队的先后投入以及合作实践也是绝对做不到的。要强调一下的是,阿里在在分布式事务上的处理能力和解决方案,这应该是独门绝技。在业界各种会议上也经常能看到这一群牛人出来分享,同行应该能感受到。
2.开源软件的快速成熟。举个例子,这两年 MySQL 体系的软件进步相当惊人,各种经验证的解决方案如雨后春笋般涌现出来。这得益于不少知名互联网公司(比如 Facebook、淘宝)在使用 MySQL 的同时也将其技术改进回馈给技术社区,把技术方案分享给业界,业界在吸收这些技术的同时再次回馈给技术社区,形成正向的反馈,极大地提升了开源软件在商业领域的竞争力。
3.硬件革命。硬件的进步给技术体系的变迁做好了铺垫。最主要的关键词:「SSD」。如果没有「SSD」的技术成熟以及在商业应用上被普遍接受,「去 IOE」几乎是不可能做到的。要知道物理机械硬盘存储的性能数十年几乎没得到什么大的改进 – 当然每年提升一点是有的。但 SSD 相比机械硬盘来说,则是质的飞跃。我记忆深刻的是,每年做 I/O 容量规划的时候都会发愁,因为即使已经使用上了很高端的 EMC 存储设备,但实际上只要应用层 I/O 没有命中到存储内存,直接打到后面的磁盘上,几乎没什么抵抗能力。比如当时一个硬盘极限能撑 100 多个 I/O,100 块硬盘也不过是万把个 I/O 就不行了。 但这样的 I/O 「打击」对 SSD 来说,则不是什么大问题。SSD 给解决「IOE」体系最大的瓶颈 – I/O 能力提供了硬件先决条件。
4.摩尔定律。这一点最初我不想提及,但不提及,就会有别人说,所以还是补充一下。提到摩尔定律,重点要说的 X86 芯片的计算能力不断进步,而 IBM 的 Power 芯片虽然也在不断进步,但正式商用的节奏明显在控制。这就给 Intel 体系带来了机会和空间。
国内对「去 IOE」的反应
在出现阿里这个成功案例之后,技术圈很是震动,曾经一度讨论热烈,随后则是国内产业界对此出现了一些跟风的倾向,不少公司则打着「国产」软件的旗号出来蒙人,这是值得警惕的。去掉 Oracle 不意味着就要采用国产的垃圾数据库,因为 MySQL 以及衍生的各种分支数据库才是最佳选择。同样,不用 IBM 的小型机也不意味着国产服务器就迎来新机会,在用户那里,适合的解决方案才是最重要的。「去 IOE」不应该成为一个噱头。任何时候,「国产」都不应该是一个互联网企业选型所要优先考虑的因素。在全球化的今天,我们应该忘掉「国产」,才有可能早点做出来更牛的软件来。
更好笑的,还搞出来一个什么「去 SOA」的组织,我觉得这是不太正常的,实际需求为前提,不能本末倒置,难道是为了「去」而「去」么?
2014 以后会有更多公司「去 IOE」
从目前的种种趋势来看,在今后几年,国内一些互联网公司以及 IT 企业会逐渐的「去 IOE」化。相比几年前,现在的「去 IOE」的主要原因则是:旧的「三件套」已经的确不适合互联网应用了。开源数据库更为可靠成熟,SSD 可靠性也得到验证,技术人才甚至都不需要从头开始进行储备 – 类似「沃趣科技」这样的团队已经能够提供足够好的技术支持服务,新的技术体系毫无疑问会让企业更有竞争力,总体成本更低。
如果要找「去 IOE」技术顾问,似乎他们是独一份(这里不是广告)。相比之下,IBM、Oracle、EMC 等公司近些年来,实际上对国内那些快速发展的互联网公司已经提供不了有力的技术支持了,IBM 拿苏宁电商练手更成为业内笑柄。或许这也是 IOE 们被抛弃的一个原因,也可能是一些创业团队的新机会。
关于 IOPS 的数据补充:
机械硬盘现在最高号称能跑到 400 IOPS,但应该 200 左右(走 SAS 接口)也就是极限了; 单块 SSD(走 PCIe 接口)的最高记录是九百多万,用不了多久突破千万 IOPS 是没问题的,相当了不起, 即使百万量级也足够吓人了。