参考项目
cGitHub - PeterH0323/Smart_Construction: Base on YOLOv5 Head Person Helmet Detection on Construction Sites,基于目标检测工地安全帽和禁入危险区域识别系统,🚀😆附 YOLOv5 训练自己的数据集超详细教程🚀😆2021.3新增可视化界面❗❗
注意:我习惯先把pytorch安装了,这样能减少很多问题,哈哈
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
================================分界线=================================
目录
一、常见错误
1、梯度爆炸问题
2、gpu内存不足
3、张量计算使用设备不一致问题(一)
二、项目运行
1、图片识别
2、视频流识别
一、常见错误
跑YOLOv5遇到的问题_runtimeerror: a view of a leaf variable that requi_Pysonmi的博客-CSDN博客
python train.py --img 640 --batch 16 --epochs 10 --data ./data/custom_data.yaml --cfg ./models/custom_yolov5.yaml --weights ./weights/yolov5s.pt
1、梯度爆炸问题

报错原因
这个错误是由于在执行in-place操作时,使用了一个需要梯度的叶节点变量视图(view)。在PyTorch中,如果一个变量需要梯度,那么它的视图也会继承这个属性。而in-place操作是对变量进行原地操作,即直接修改变量的值,这样会导致梯度信息的丢失或不一致。
解决方法
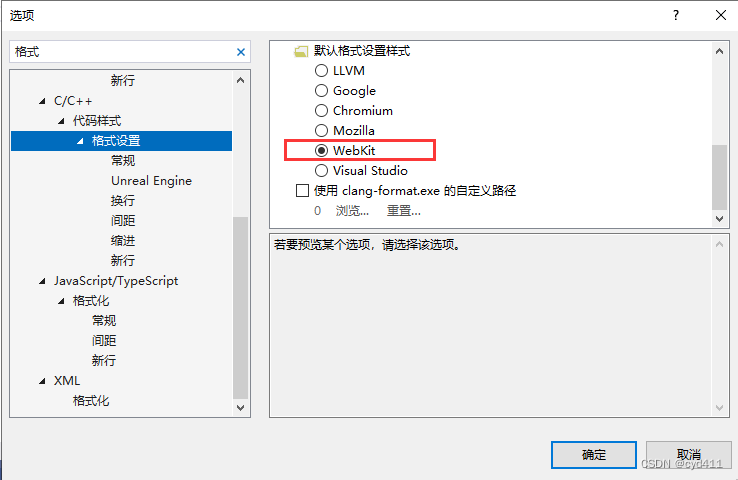
最简单粗暴的方法是找到models文件夹下的yolo.py文件,在第149下面添加with torch.no_grad(): 如下图:

2、gpu内存不足

解决办法:

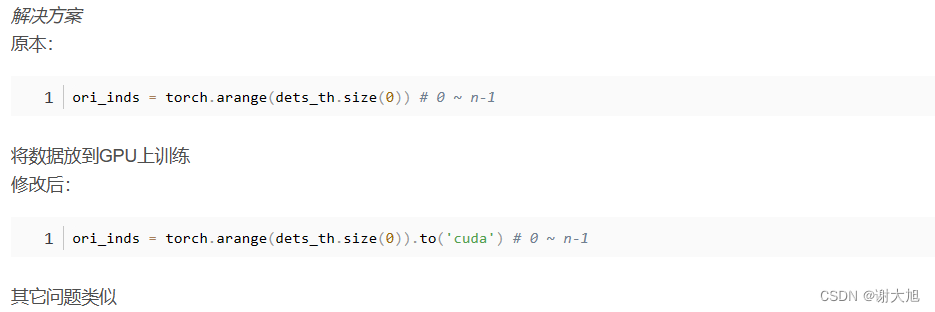
3、张量计算使用设备不一致问题(一)
模型和数据都分别放入了GPU中,将数据和模型打印出来也在GPU上、运行时GPU的显存确实有被占但依然报这个错误。

解决办法:

无意在这里看到的,刚好解决了,真是随便解决了,感谢cctv,感谢csdn,感谢这位大佬

来源:
yolov5_obb报错合集_while-L的博客-CSDN博客
4、张量计算使用设备不一致问题(二)
can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
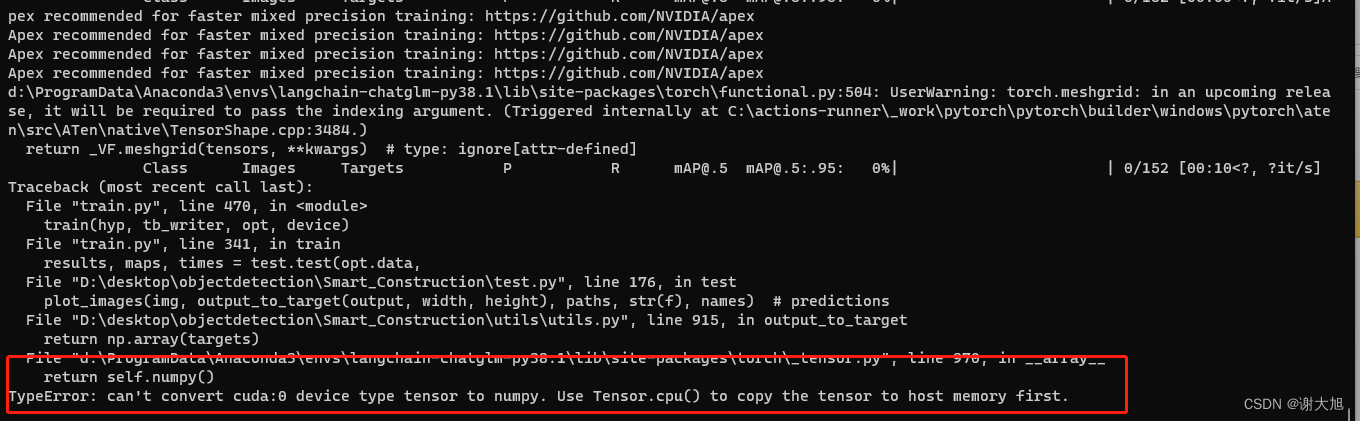
解决办法:

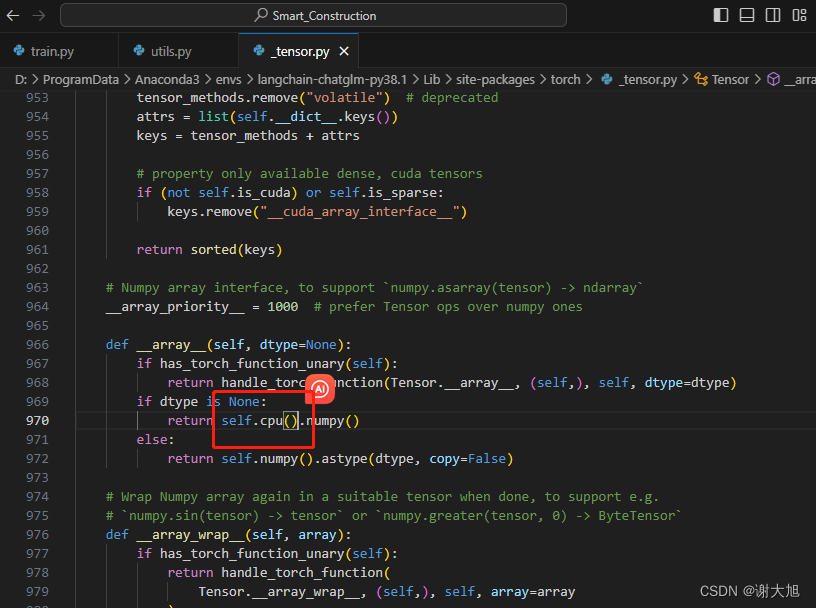
nice
二、项目运行
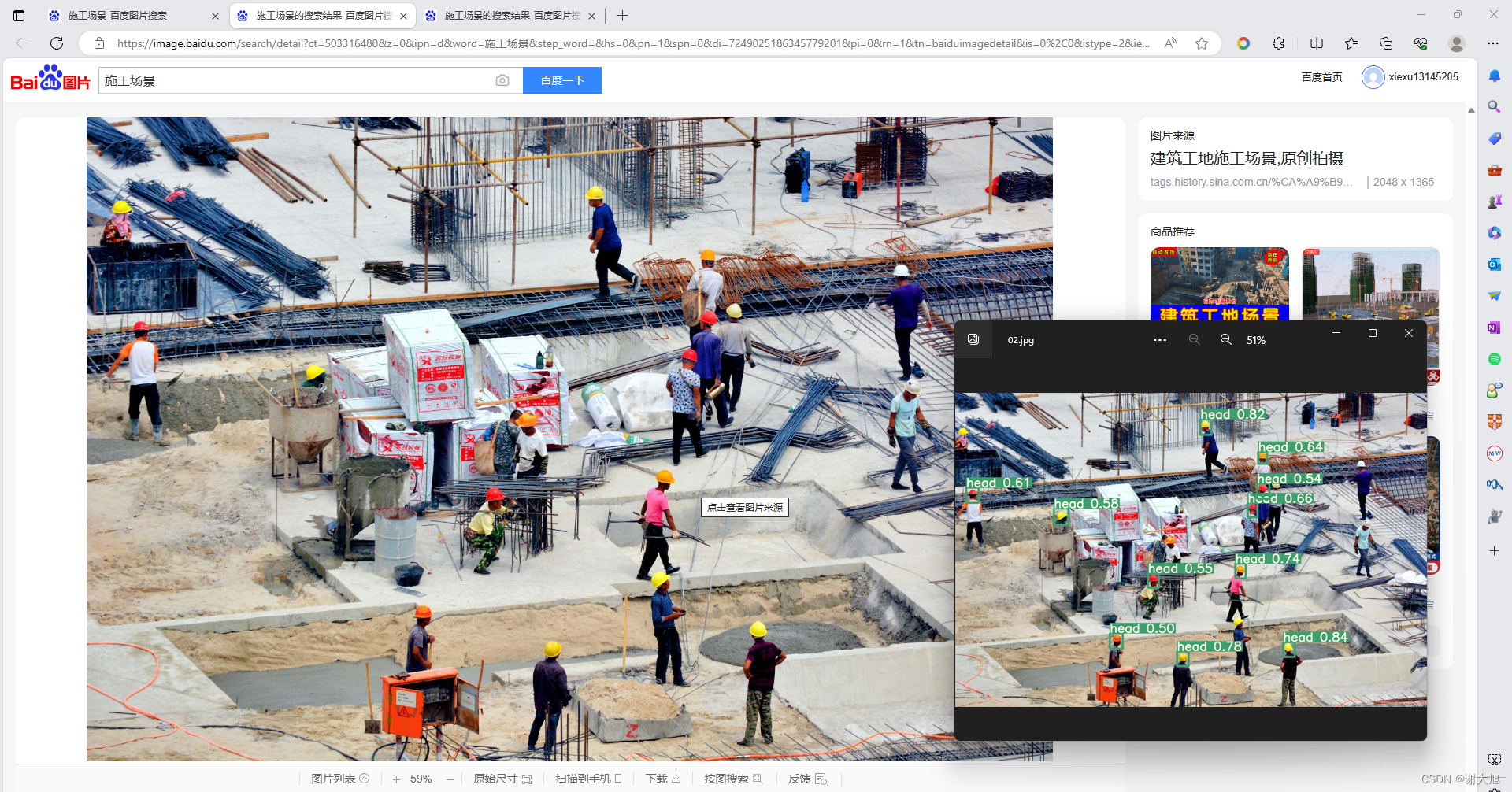
1、图片识别
python detect.py --source ./inference/test/02.jpg --weight ./weights/helmet_head_person_s.pt
2、视频流识别
python detect.py --source rtsp://127.0.0.1:8554/stream --weights ./weights/helmet_head_person_s.pt
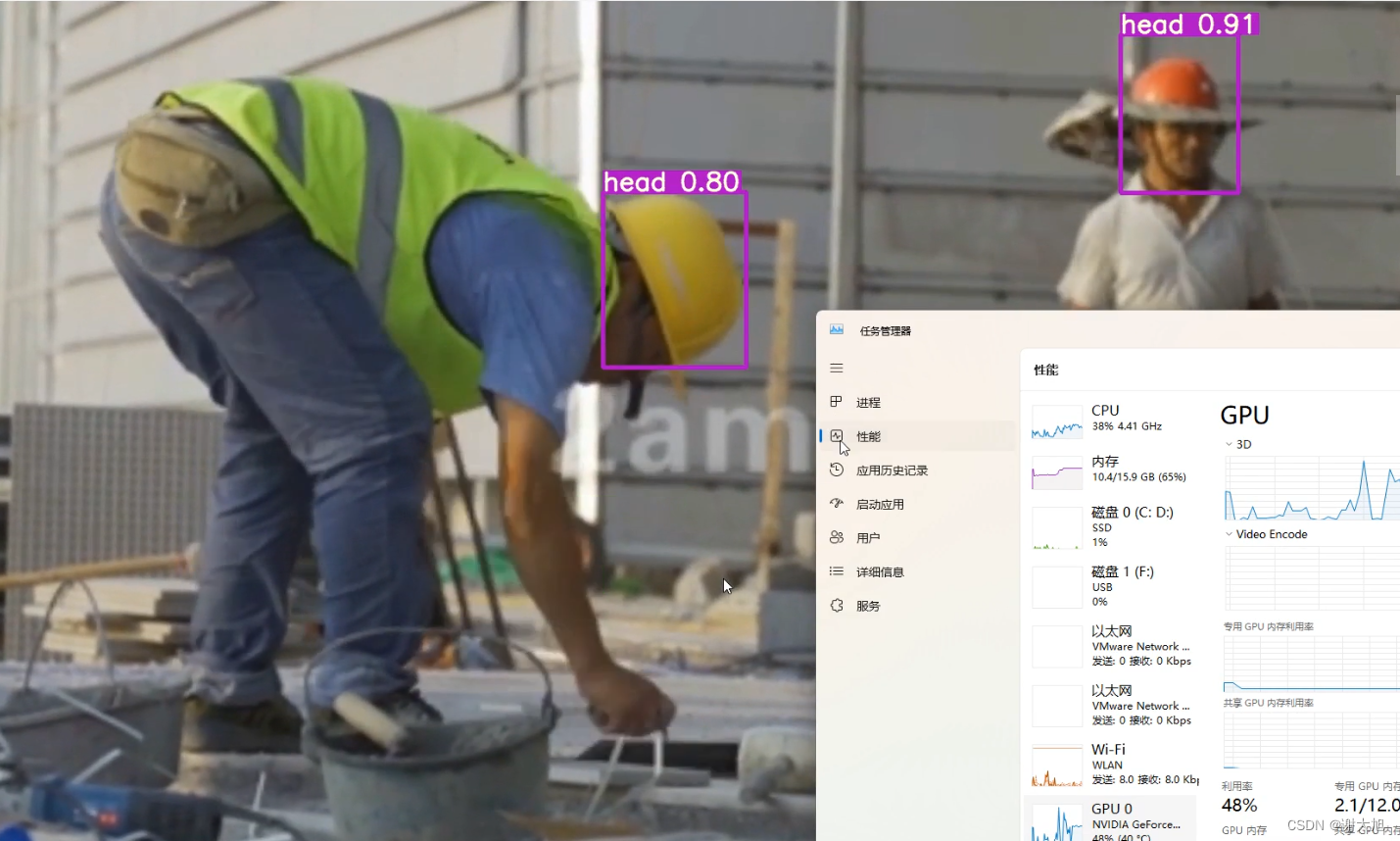
使用5s模型进行训练,内存占用2G,3060显卡性能去到20%,CPG占20%左右。

![[ MySQL ] — 常见函数的使用](https://img-blog.csdnimg.cn/8039b9ae158b43a7a34ff8a79088bf00.png)
![C国演义 [第十二章]](https://img-blog.csdnimg.cn/ef799b9f95114cb197c9eb1e1143b2e6.png)