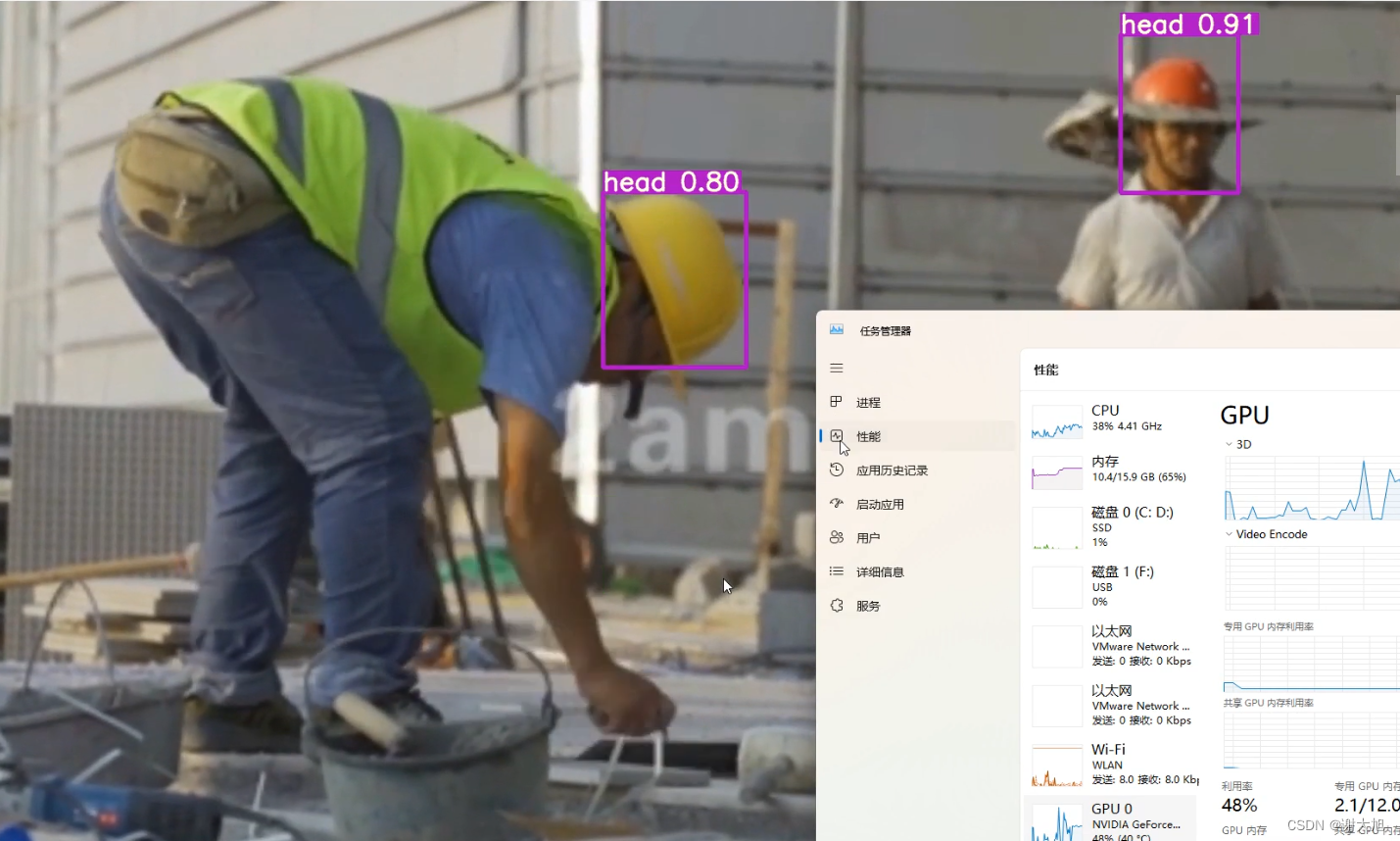
事务的ACID
-
A 原子性(Atomicity)
多步骤操作,只能是两种状态,要么所有的步骤都成功执行,要么所有的步骤都不执行,举例说明就是小明向小红转账30元的场景,拆分成两个步骤,步骤1:小明减30元。步骤2:小红加30元。步骤1和2必须同时执行成功或失败,不能只执行其中的一个步骤。 -
C 一致性(Consistency)
其实和原子性一样 -
I 隔离性(Isolation)
多个事务执行时,不能受并发的事务的影响,后面会详细的说隔离级别 -
D 持久性(Durability)
事务一旦提交落盘后,数据不会因为程序异常或断电丢失数据
隔离性
- 读未提交(Read uncommitted)
- 读已提交(Read committed)
- 可重复读(Repeatable read)
- 序列化(Serializable )
从上到下,四个级别的隔离性依次变强,性能依次变差
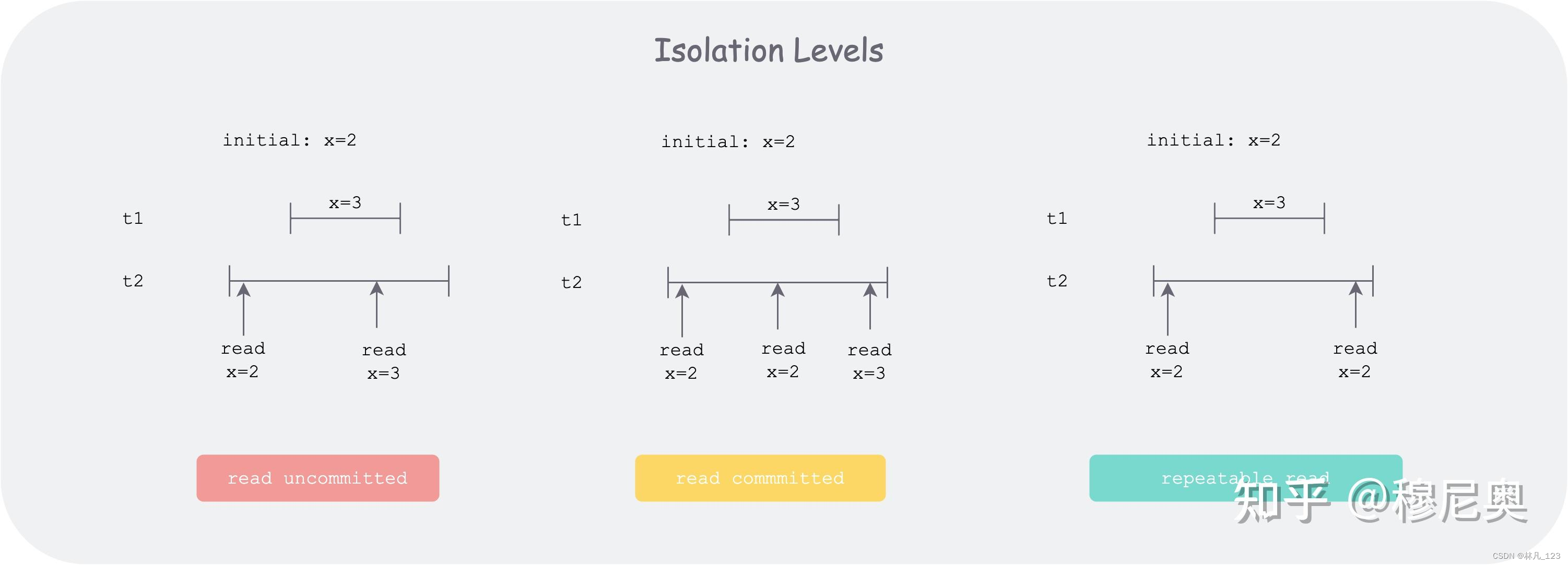
读未提交 :对应脏读,在本事务的线段内,会读到其他线段的中间状态。
读已提交:对应不可重复读,比上个好一些。该级别下不能读到其他事务的未提交状态。但如上图,如果事务 t2 在执行时,多次读某个记录 x 的状态,在事务 t1 未启动前,发现 x = 2,在事务 t1 提交后,发现 x = 3,这便出现了不一致。
可重复读:如上图,事务 t2 在整个执行期间,多次读取数据库 x 的状态,无论他事务(如 t1)是否改变 x 状态并提交,事务 t2 都不会感觉到。但是会存在幻读的风险。怎么理解呢?最关键的原因在于写并发。因为读不到,不代表其他事务的影响不存在。比如事务 t2 开始时,通过查询发现 id = “qtmuniao” 的记录为空,于是创建了 id=“qtmuniao” 的记录,然而在提交时,发现报错说该 id 已经存在。这可能是因为有一个开始的比较晚的事务 t2,也创建了一个 id=“qtmuniao” 的记录,但是先提交了。于是用户就郁闷了,明明你说没有,但我写又报错,难道我出现幻觉了?这就太扯淡了,但是此级别就只能做到这样了。反而,因为兼顾了性能和隔离性,他是大多数据库的默认级别。
序列化:最简单的实现办法就是一把锁来串行化所有的事务boltdb就是这么做的。badgerdb在此基础上如果能提高并发,做很多优化。
badger 的序列化SSI
badgerdb 的事务主要依靠多个tnx结构体和全局的一个oracle结构体来维护
type Txn struct {readTs uint64commitTs uint64
}type oracle struct {nextTxnTs uint64
}每一个txn都有readTs和commitTs ,其中全局的o.nextTxnTs只有获得提交时间戳的时候才加1,如果多个事务并发,任何一个事务都还没有提交的时候,这些事务获得的readTs 是一样的
var readTs uint64o.Lock()readTs = o.nextTxnTs - 1//txn 的readTso.readMark.Begin(readTs)o.Unlock()ts = o.nextTxnTso.nextTxnTs++//事务获得了提交时间后,再把nextTxnTs+1o.txnMark.Begin(ts)创建一个事务的时候,要进行授时txn.readTs = db.orc.readTs(),这个时间是一个递增的序列,接下来主要来分析一下db.orc.readTs()这个函数,获得readTs后会等待readTs这个时间戳提交的事务彻底写入LSM tree后才返回,保证了不会脏读,不会读到其他未提交的事务,和不可重复读
func (o *oracle) readTs() uint64 {if o.isManaged {panic("ReadTs should not be retrieved for managed DB")}var readTs uint64o.Lock()readTs = o.nextTxnTs - 1o.readMark.Begin(readTs)o.Unlock()// Wait for all txns which have no conflicts, have been assigned a commit// timestamp and are going through the write to value log and LSM tree// process. Not waiting here could mean that some txns which have been// committed would not be read.y.Check(o.txnMark.WaitForMark(context.Background(), readTs))return readTs
}badgerdb 解决幻读
在上文描述的可重复读,出现的幻读,badgerdb解决幻读和不可重复读的方法就是事务t2放弃提交,给用户层返回ErrConflict错误,让用户层稍后再试。
先找到代码中报ErrConflict的地方,是获取CommitTs的时候报的错误
func (txn *Txn) commitAndSend() (func() error, error) {orc := txn.db.orc// Ensure that the order in which we get the commit timestamp is the same as// the order in which we push these updates to the write channel. So, we// acquire a writeChLock before getting a commit timestamp, and only release// it after pushing the entries to it.orc.writeChLock.Lock()defer orc.writeChLock.Unlock()commitTs, conflict := orc.newCommitTs(txn)if conflict {return nil, ErrConflict}
}
进去看orc.newCommitTs(txn)
func (o *oracle) newCommitTs(txn *Txn) (uint64, bool) {o.Lock()defer o.Unlock()if o.hasConflict(txn) {return 0, true}
}
再看o.hasConflict(txn);
txn.reads 是被txn.addReadKey进行修改的;
committedTxn.conflictKeys 是txn.modify() 修改的,txn.modify()是txn.Set或txn.Detele调用的;
总结下来就是:当前事务如果读过的key,在当前事务的readTs后有在其他的事务对这些读到过的key做过修改,那么本次事务就是有冲突的
// hasConflict must be called while having a lock.
func (o *oracle) hasConflict(txn *Txn) bool {if len(txn.reads) == 0 {return false}for _, committedTxn := range o.committedTxns {// If the committedTxn.ts is less than txn.readTs that implies that the// committedTxn finished before the current transaction started.// We don't need to check for conflict in that case.// This change assumes linearizability. Lack of linearizability could// cause the read ts of a new txn to be lower than the commit ts of// a txn before it (@mrjn).if committedTxn.ts <= txn.readTs {continue}for _, ro := range txn.reads {if _, has := committedTxn.conflictKeys[ro]; has {return true}}}return false
}
https://zhuanlan.zhihu.com/p/395229054