在这篇文章中,我们将一起探讨Python爬虫异常处理实践,特别关注处理被封禁和网站升级问题。让我们一起来看看如何解决这些问题,提高我们爬虫程序的稳定性和可靠性。
首先,我们要了解为什么会遇到这些问题。网站封禁爬虫的原因主要是为了防止恶意爬取和保护网站数据。而网站升级可能会导致页面结构发生变化,从而影响爬虫程序的正常运行。
接下来,我们将分享一些实用的解决方案,帮助你应对这些问题:
1.处理被封禁问题:
a.使用代理IP:通过使用代理IP,我们可以隐藏爬虫的真实IP地址,降低被封禁的风险。Python中有许多库可以帮助我们实现代理功能,例如requests库。
b.设置请求头:模拟浏览器行为,伪装成正常用户。在请求头中添加User-Agent字段,可以让爬虫更像一个真实的浏览器。
c.限制爬取速度:通过设置爬虫的延迟时间,避免对目标网站造成过大的访问压力。
2.处理网站升级问题:
a.代码解耦:将爬虫程序中负责解析网页的部分与其他功能分离,这样在网站升级时,只需修改解析部分的代码,降低维护成本。
b.使用可靠的选择器:优先使用网页中较为稳定的元素作为选择器,例如元素的ID或特定的类名。
c.异常处理:为爬虫程序添加异常处理机制,当遇到网站结构变化导致的解析错误时,可以及时捕获异常并进行相应处理。
下面是一个简单的代码示例,展示了如何在Python爬虫中使用requests库设置代理IP和请求头:
python import requests url="https://example.com" proxies={ "http":"http://proxy.example.com:8080", "https":"https://proxy.example.com:8080", } headers={ "User-Agent":"Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/58.0.3029.110 Safari/537.36" } response=requests.get(url,proxies=proxies,headers=headers)
通过以上方法,我们可以提高爬虫程序的稳定性和可靠性。希望这些解决方案对你在实际操作中有所帮助,让你的Python爬虫项目更加强大!
Python爬虫异常处理实践:处理被封禁和网站升级问题
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/110061.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

广州华锐互动:VR垃圾分类虚拟科普系统让学习过程更加丰富有趣
在我们的日常生活中,垃圾分类已成为一项重要的公民责任。然而,由于缺乏对垃圾分类的深入理解和相关知识,许多人在实践中往往感到困惑和挫败。为了解决这个问题,一种创新的解决方案应运而生:垃圾分类VR虚拟仿真教学系统…

【校招VIP】前端算法考察之排序
考点介绍: 不同的场景中,不同的排序算法执行效率不同。 稳定:冒泡、插入、归并 不稳定:选择、快速、堆排序、希尔排序
『前端算法考察之排序』相关题目及解析内容可点击文章末尾链接查看!
一、考点题目
1、使用js实…
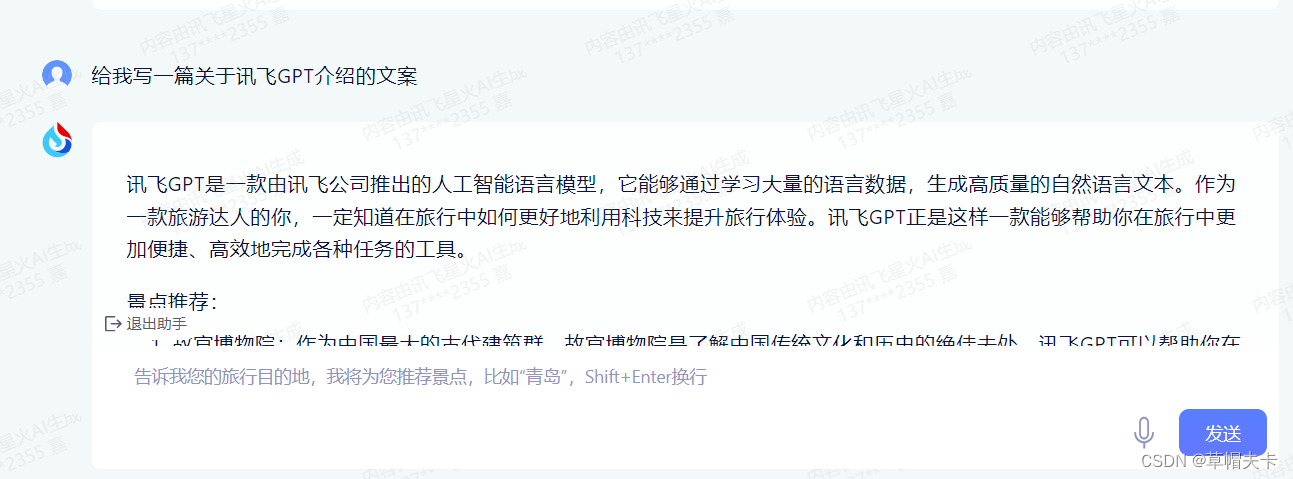
科大讯飞永久免费GPT入口来了!!!
讯飞GPT永久免费使用入口注册链接:讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞。 登录讯飞账号后,点击进入体验。 进入体验页面后,选择景点推荐。 笔者让其写一篇关于讯飞GPT介绍的文案。 讯飞GPT是一款由讯飞公司推出的人工智能语…

【算法专题突破】双指针 - 盛最多水的容器(4)
目录
1. 题目解析
2. 算法原理
3. 代码编写
写在最后: 1. 题目解析
题目链接:11. 盛最多水的容器 - 力扣(Leetcode) 这道题目也不难理解,
两边的柱子的盛水量是根据短的那边的柱子决定的,
而盛水量…

MySQL项目迁移华为GaussDB PG模式指南
文章目录 0. 前言1. 数据库模式选择(B/PG)2.驱动选择2.1. 使用postgresql驱动2.1. 使用opengaussjdbc驱动 3. 其他考虑因素4. PG模式4.1 MySQL和OpenGauss不兼容的语法处理建议4.2 语法差异 6. 高斯数据库 PG模式JDBC 使用示例验证6. 参考资料 本章节主要…
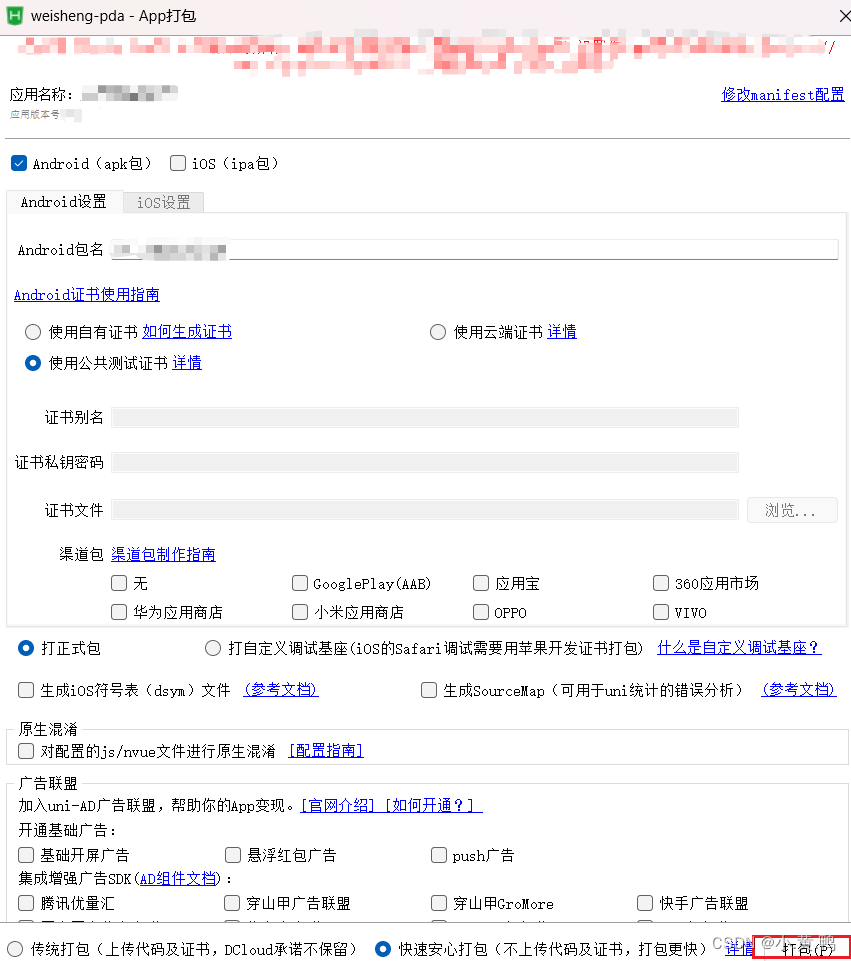
配置uniapp调试环境
目录 uni-app介绍
uni-app开发工具HBuilderX
创建项目前提条件
uni-app项目结构
配置mumu模拟器
uni-app生命周期
1.应用生命周期 小程序规范
2.页面生命周期-小程序规范
3.组件生命周期 vue规范
uni-app登录按钮方法
uni-app发布安卓app uni-app介绍
uni-app 是一个…

JavaScript设计模式(二)——简单工厂模式、抽象工厂模式
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…
ASUS华硕天选4笔记本电脑FA507XV原厂Windows11系统22H2
天选四FA507X原装系统自带所有驱动、出厂主题壁纸LOGO、Office办公软件
华硕电脑管家、奥创控制中心等预装程序,恢复出厂状态W11
链接:https://pan.baidu.com/s/1SPoFW7wR5KawGu-yMckNzg?pwdayxd 提取码:ayxd

开源与可持续发展:环境友好的技术选择
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…
【数据结构大全】你想要的都有,数组、链表、堆栈、二叉树、红黑树、B树、图......
目录
1.概述
2.线性结构
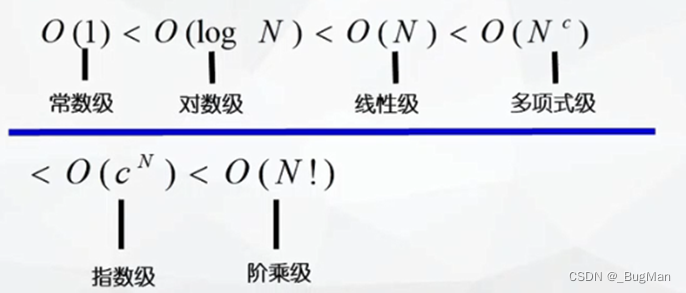
3.时间复杂度
4.查找算法
5.树
6.图 1.概述
博主之前写过一个完整的关于数据结构的系列文章,一共十三篇,内容包含,数组、链表、堆栈、队列、时间复杂度、顺序查找、二分查找、二叉树、二叉搜索树、平衡二叉树、…
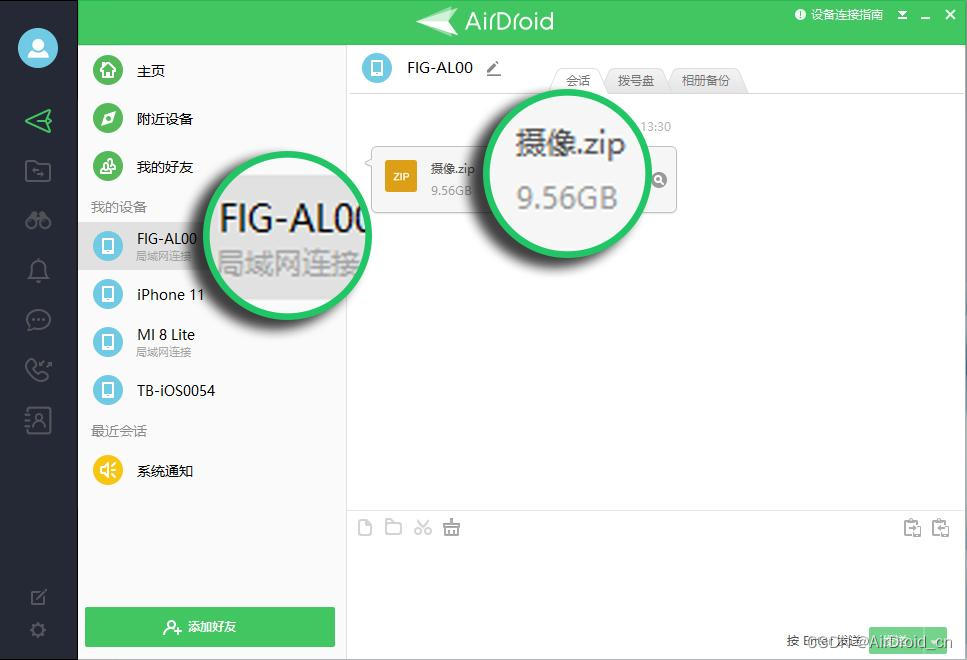
电脑不安装软件,怎么将手机文件传输到电脑?
很多人都知道,AirDroid有网页版(web.airdroid.com)。
想要文件传输,却不想在电脑安装软件时,AirDroid的网页版其实也可以传输文件。
然而,要将文件从手机传输文件到网页端所在的电脑时,如果按…


LInux之chrony服务器
目录 场景
重要性
LInux的两个时钟
硬件时钟
系统时钟
NTP协议
Chrony介绍
定义
组成 --- chronyd和chronyc
安装与配置
安装 Chrony配置文件分析
同步时间服务器
chronyc命令
chronyc sources输出分析
其它命令
查看时间服务器的状态
查看时间服务器是否在线 …
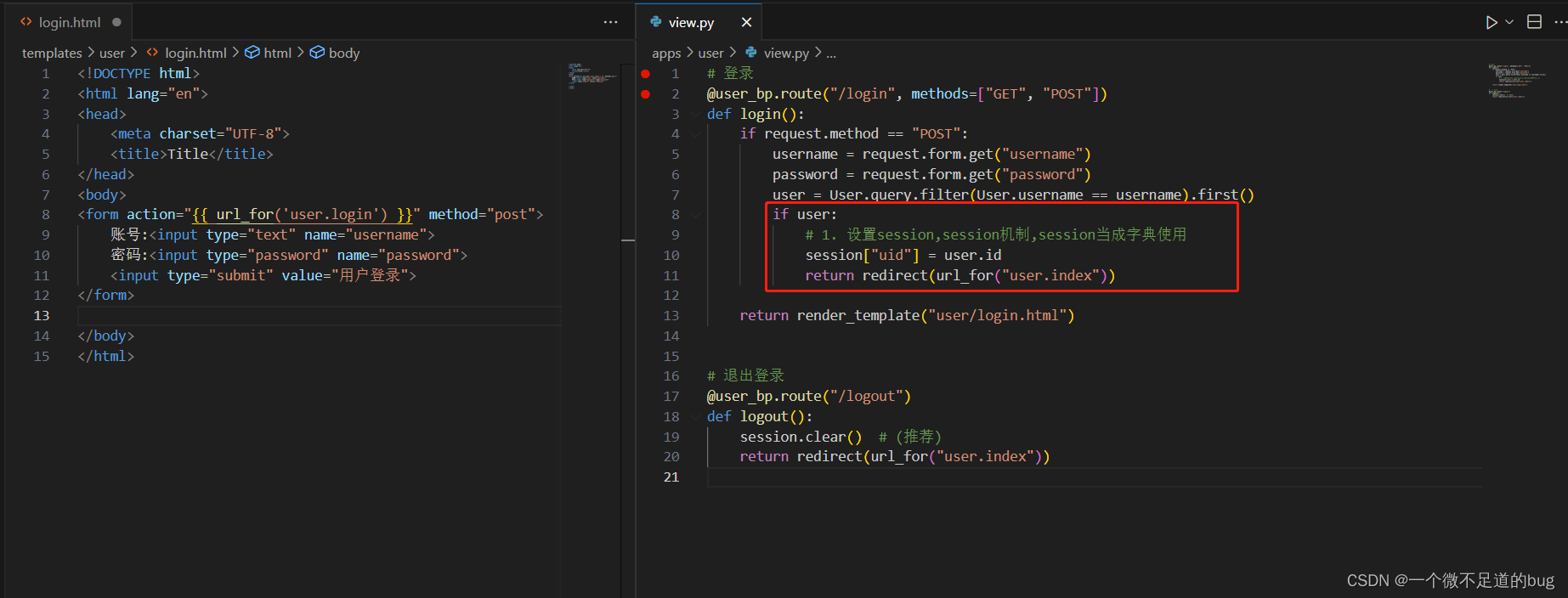
18-使用钩子函数判断用户登录权限-登录前缀
钩子函数的两种应用: (1). 应用在app上
before_first_request
before_request
after_request
teardown_request (2). 应用在蓝图上
before_app_first_request #只会在第一次请求执行,往后就不执行, (待定,此属性没调试通过)
before_app_request # 每次请求都会执行一次(重点…

服务网格实施周期缩短 50%,丽迅物流基于阿里云 ACK 和 ASM 的云原生应用管理实践
作者:王夕宁、 刘强、 华相
公司介绍
丽迅物流是百丽旗下专注于时尚产业、为企业提供专业物流及供应链解决方案的服务商。其产品服务主要包括城市落地配、仓配一体、干线运输及定制化解决方案。通过自研智能化物流管理平台,全面助力企业合作集约化发展…
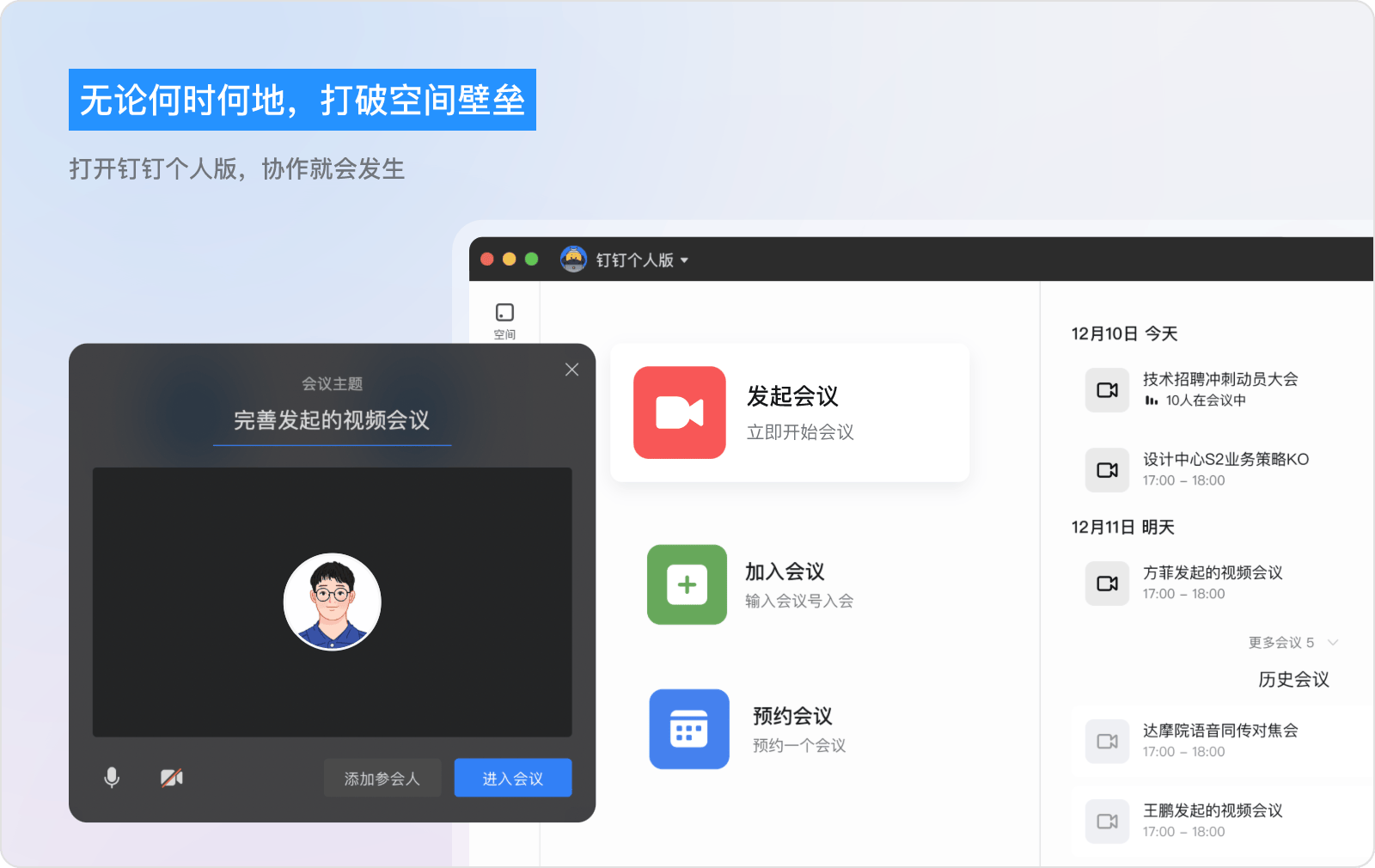
玩转软件|钉钉个人版内测启动:AI探索未来的工作方式
目录 前言
正文
AI为核心,个人效率为王!
指令中心,解锁AI技巧!
灵感Store,探索更多可能!
未来的AI,即将问世!
个人内测体验 前言
重磅消息:钉钉个人版在8月16日正…

Android实现监听APP启动、前台和后台
Android 实时监听APP进入前台或后台
前言 在我们开发的过程中,经常会遇到需要我们判断app进入后台,或者切换到前台的情况。比如我们想判断app切换到前台时,显示一个解锁界面,要求用户输入解锁密码才能继续进行操作;我…
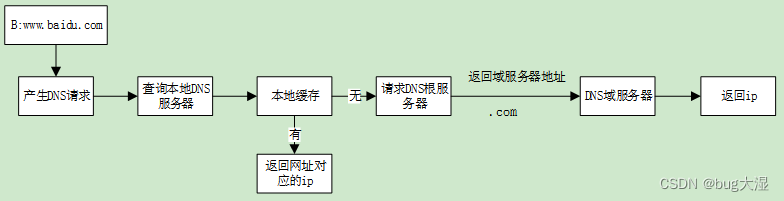
不同子网络中的通信过程
从输入www.baidu.com经历了什么
一、DNS(网址->IP) 二、ARP(IP->MAC)
A->B:有数据发送,数据封装ip之后发现没有主机B的mac地址。然后ARP在本网段广播:检查目标地址和源地址是否在同一…
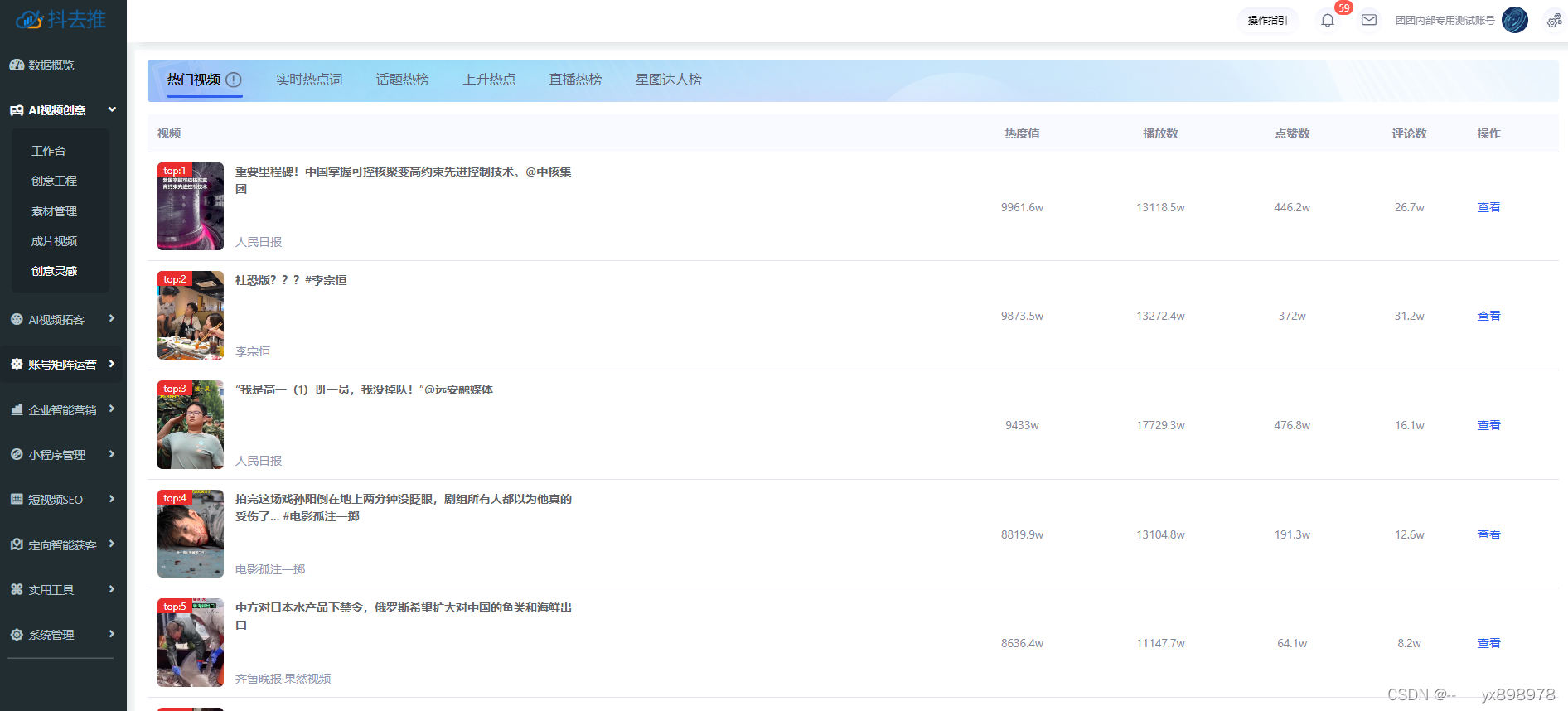
抖音矩阵,矩阵账号开发,抖音矩阵源码搭建
抖音矩阵,矩阵账号开发,抖音矩阵源码搭建:
1、账号矩阵系统搭建首先需要注意的是支持多平台,多账号,可以实现流量互通,账号矩阵多个账号联动形成账号矩阵形式分发开发。
2、账号矩阵系统需要可以查看分发…
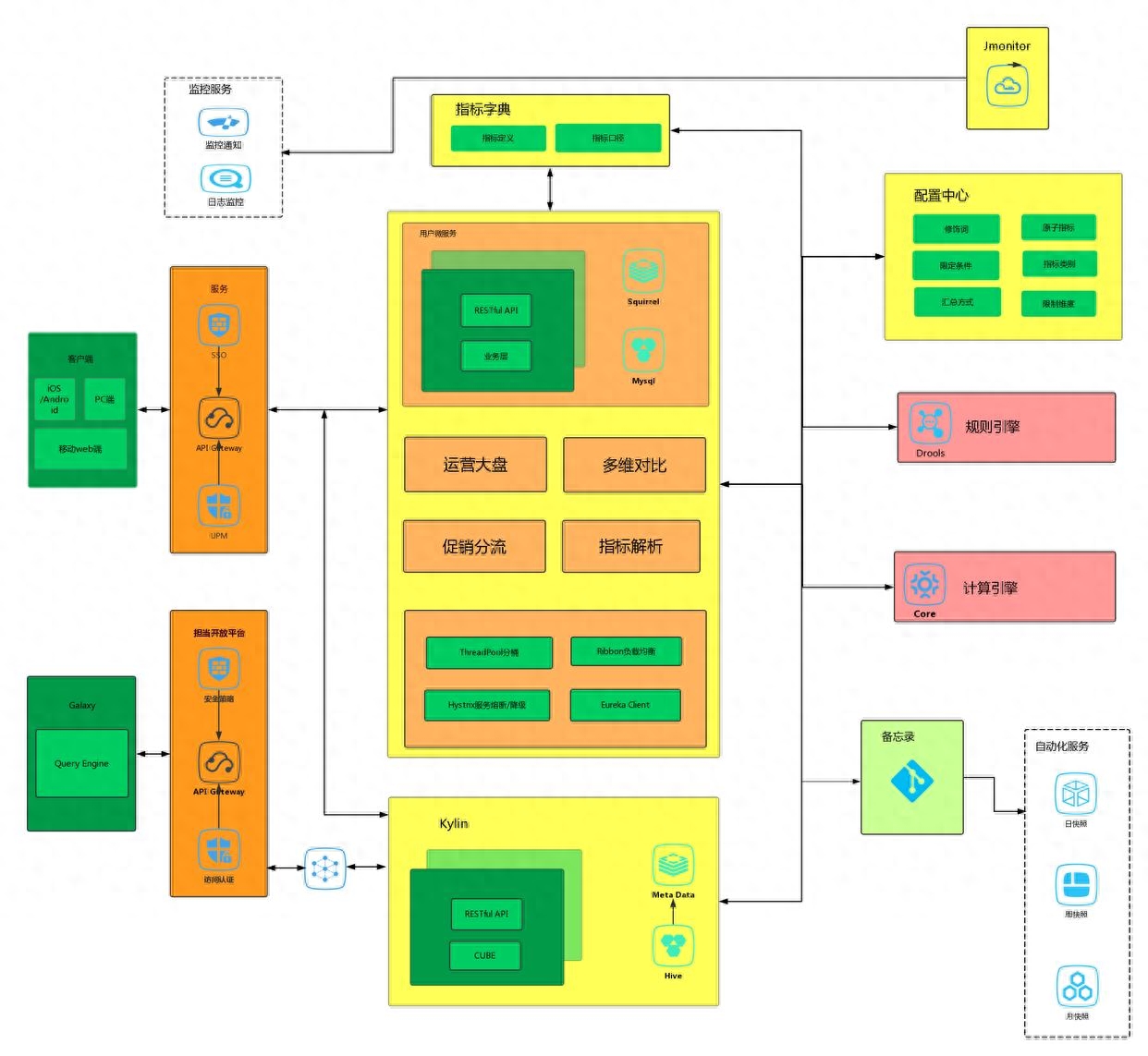
Node与Express后端架构:高性能的Web应用服务
在现代Web应用开发中,后端架构的性能和可扩展性至关重要。Node.js作为一个基于事件驱动、非阻塞I/O的平台,以及Express作为一个流行的Node.js框架,共同构建了高性能的Web应用服务。 在本文中,我们将深入探讨Node与Express后端架构…
推荐文章
- 【已解决】npm install卡主不动的情况
- 7.1 项目1 学生通讯录管理:文本文件增删改查(C++版本)(自顶向下设计+断点调试) (A)
- 使用ChatGPT时,当你给的指令越精确,它的回答会越到位正在上传…
- 字节一面
- #LinuxC高级 笔记一
- (1)图像识别yolov5—安装教程
- (BUUCTF)ycb_2020_easy_heap (glibc2.31的off-by-null + orw)
- (Chatgpt辅助)C语言移植Code128B条形码算法到LVGL8.3【附跑通代码】
- (delphi11最新学习资料) Object Pascal 学习笔记---第14章泛型第3节(特定类约束)
- (第23天)Oracle 数据泵用户导出导入
- (附源码)spring boot流浪动物救助系统 毕业设计180920
- (七)for循环控制