使用zip批量压缩文件
前文的代码示例了使用gzip对单个文件进行压缩。本文示例使用更通用的zipfile来批量压缩文件。zipfile也是python内置的库,使用起来非常方便。废话不说,直接上代码示例。
import dbm
import glob
import zipfile# 保存压缩计划的库名
dbname = 'plan'def writeplan():# 设置要压缩的文件名后缀以及目录名with dbm.open(dbname,'n') as db:db[r'd:\dev\gotoolkits\markdown'] = '*.md'db[r'd:\dev\gotoolkits\python'] = '*.py'def genzipfile(zipfilename):"""将要压缩的文件保存在一个zipfile中。Args:zipfilename (string): 压缩文件名"""zipcontainer = zipfile.ZipFile(zipfilename, 'w', zipfile.ZIP_DEFLATED )# 获得目录与后缀名with dbm.open(dbname,'r') as db:for startdir in db.keys():filefilter = db[startdir]# 在指定目录下进行文件过滤regstr = f"{startdir.decode('utf-8')}\\{filefilter.decode('utf-8')}"files = glob.iglob(regstr)for file in files:# 将文件放入压缩文件中zipcontainer.write(file)# 详细输出print(zipcontainer.infolist())zipcontainer.close()print('done')writeplan()
genzipfile(r'd:\dev\demo.zip')
上述示例代码中,再次引入一个python内置的轻量级数据库dbm。与shelve类似,也是key-value数据库。它的特殊性在于无论是键还是值,都必须是字符串,但使用起来非常方便。虽然在示例代码中对此数据库是先写后读,但在实际批量压缩备份的应用场景中,应该是一次性配置好后,后续就是定期调用genzipfile不断的生成压缩文件。
在genzipfile函数中,使用了glob.iglob来搜索特定后缀的文件。这个函数无法搜索子目录,但对指定目录下的文件搜索有效,类似于命令中的“ls *.py”。
zipfile.infolist()能够详细的输出压缩文件中的所有文件信息。在此基础上做GUI界面时,可以依托此信息生成目录树。
生成的zip文件,其它工具类软件也能够使用,以下使用Bandizip这个windows工具软件打开,显示效果如下: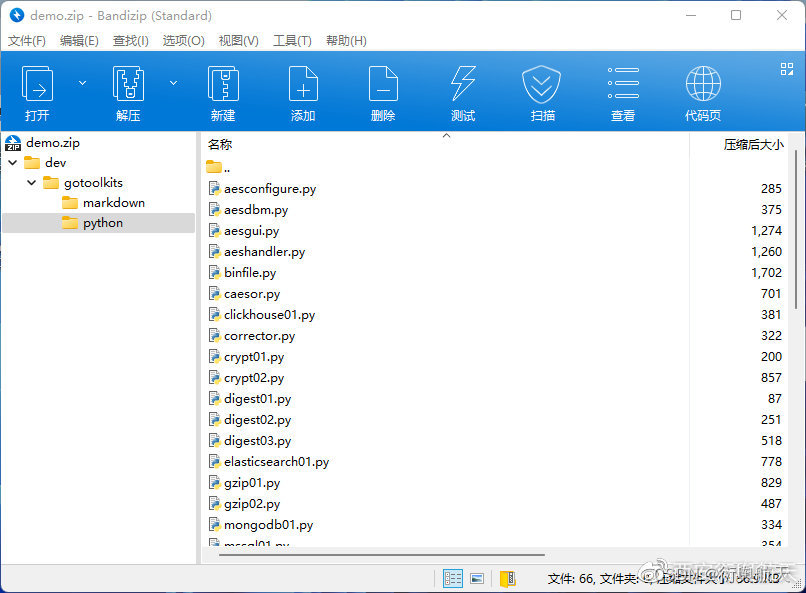

需要注意的是:
一、zipfile当前不支持创建一个加密的zip文件
二、zipfile能够解开加密的文件,但非常慢