推荐阅读列表:
LLM本地知识库问答系统(一):使用LangChain和LlamaIndex从零构建PDF聊天机器人指南
上一篇文章我们介绍了使用LlamaIndex构建PDF聊天机器人,本文将介绍一下LlamaIndex的基本概念和原理。
LlamaIndex简介
LlamaIndex(也称为GPT Index)是一个用户友好的界面,可将外部数据连接到大型语言模型(LLM)。它提供了一系列工具来简化流程,包括可以与各种现有数据源和格式(如API、PDF、文档和SQL)集成的数据连接器。此外,LlamaIndex为结构化和非结构化数据提供索引,可以轻松地与LLM一起使用。
本文将讨论LlamaIndex提供的不同类型的索引以及如何使用它们。LlamaIndex索引包括列表索引、矢量存储索引、树索引和关键字表索引,当然也包括一些特殊索引,比如图索引、Pandas索引、SQL索引和文档摘要索引。
有了ChatGPT这么强大的LLM,搭建PDF聊天机器人不够吗?为什么还需要LlamaIndex?其实,如果想搭建企业级的聊天机器人,那么ChatGPT的上下文是不够的,常见LLM上下文大致如下:
- GPT-3:约2000个tokens
- GPT-3.5:约4000个tokens
- GPT-4:最多32.000个tokens
Note:1000个tokens大约有750个words

LlamaIndex将文档分解为多个Node对象,Node表示源文档的“块”,这些源文档可以是文本块、图像或者其他内容。它们还包含元数据以及与其他节点和索引结构的关系信息。创建索引,其实就是创建这些Node,也可以手动为文档定义Node。
使用LlamaIndex构建索引
下面我们看一下如何创建这些索引:
安装LlamaIndex相关库
pip install llama-indexpip install openai
设置OpenAI API Key
import osos.environ['OPENAI_API_KEY'] = '<YOUR_OPENAI_API_KEY>'import loggingimport sys## showing logslogging.basicConfig(stream=sys.stdout, level=logging.INFO)logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))## load the PDFfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom llama_index import download_loader# define loaderUnstructuredReader = download_loader('UnstructuredReader', refresh_cache=True)loader = UnstructuredReader()# load the datadocuments = loader.load_data('../notebooks/documents/Apple-Financial-Report-Q1-2022.pdf',split_documents=False)
列表索引(List Index)
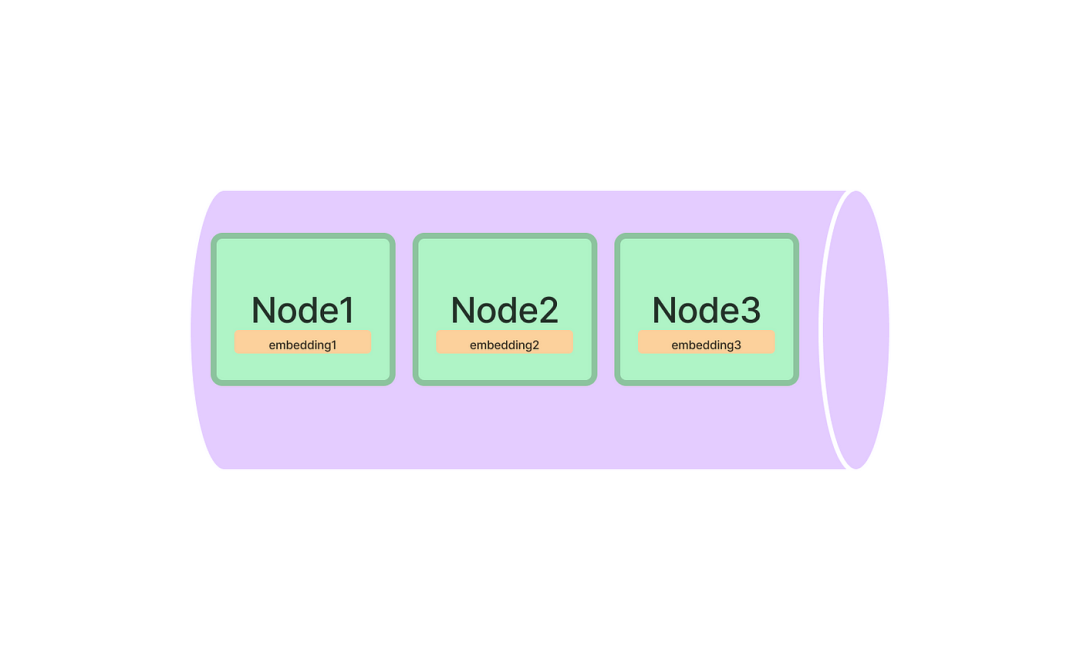
列表索引是一个简单的数据结构,其中Node存储在一个序列中。文档文本被分块,转换为节点,并在索引构建过程中存储在列表中。如下图所示:

在查询期间,如果没有指定其他查询参数,LlamaIndex只需将列表中的所有节点加载到Response Synthesis模块中。

列表索引提供了多种查询列表索引方式,比如通过embedding查询最相关的top-k块,或者使用关键字过滤,如下所示:

LlamaIndex为列表索引提供embedding支持。每个节点存储文本之外还可以选择存储embedding。在查询期间,我们可以使用embedding对节点进行最大相似度检索,然后调用LLM来生成答案。由于使用embedding的相似性查找(例如,使用余弦相似性)不需要LLM调用,因此embedding是一种代价更低的查询机制,而不需要遍历LLM节点。这意味着在索引构建过程中,LlamaIndex不会调用LLM来生成embedding,而是在查询时生成embedding。这种设计避免了在索引构建期间为所有文本块生成embedding,这对于大数据来说可能代价高昂。
下面是一个具体的使用案例:
from llama_index import GPTKeywordTableIndex, SimpleDirectoryReaderfrom IPython.display import Markdown, displayfrom langchain.chat_models import ChatOpenAI## by default, LlamaIndex uses text-davinci-003 to synthesise response# and text-davinci-002 for embedding, we can change to# gpt-3.5-turbo for Chat modelindex = GPTListIndex.from_documents(documents)query_engine = index.as_query_engine()response = query_engine.query("What is net operating income?")display(Markdown(f"<b>{response}</b>"))## Check the logs to see the different between th## if you wish to not build the index during the index construction# then need to add retriever_mode=embedding to query engine# query with embed_model specifiedquery_engine = new_index.as_query_engine(retriever_mode="embedding",verbose=True)response = query_engine.query("What is net operating income?")display(Markdown(f"<b>{response}</b>"))
向量存储索引(Vector Store Index)
向量存储索引是最常见且使用简单的,允许在大量数据中回答查询。
默认情况下,GPTVectorStoreIndex使用内存中的SimpleVectorStore。与List Index不同,Vector Store Index在构建索引过程中就生成了embedding,这意味着在构建索引以生成embedding数据期间就调用了LLM。
查询Vector Store Index前k个最相似的节点,并将它们传递到我们的Response Synthesis模块中。

from llama_index import GPTVectorStoreIndexindex = GPTVectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()response = query_engine.query("What did the author do growing up?")response
树索引(Tree Index)
树索引是一个树结构索引,其中每个节点都是子节点的摘要。在索引构建过程中,树是以自下而上的方式构建的,直到我们最终得到一组根节点。树索引从一组节点(成为该树中的叶节点)构建一个层次树。
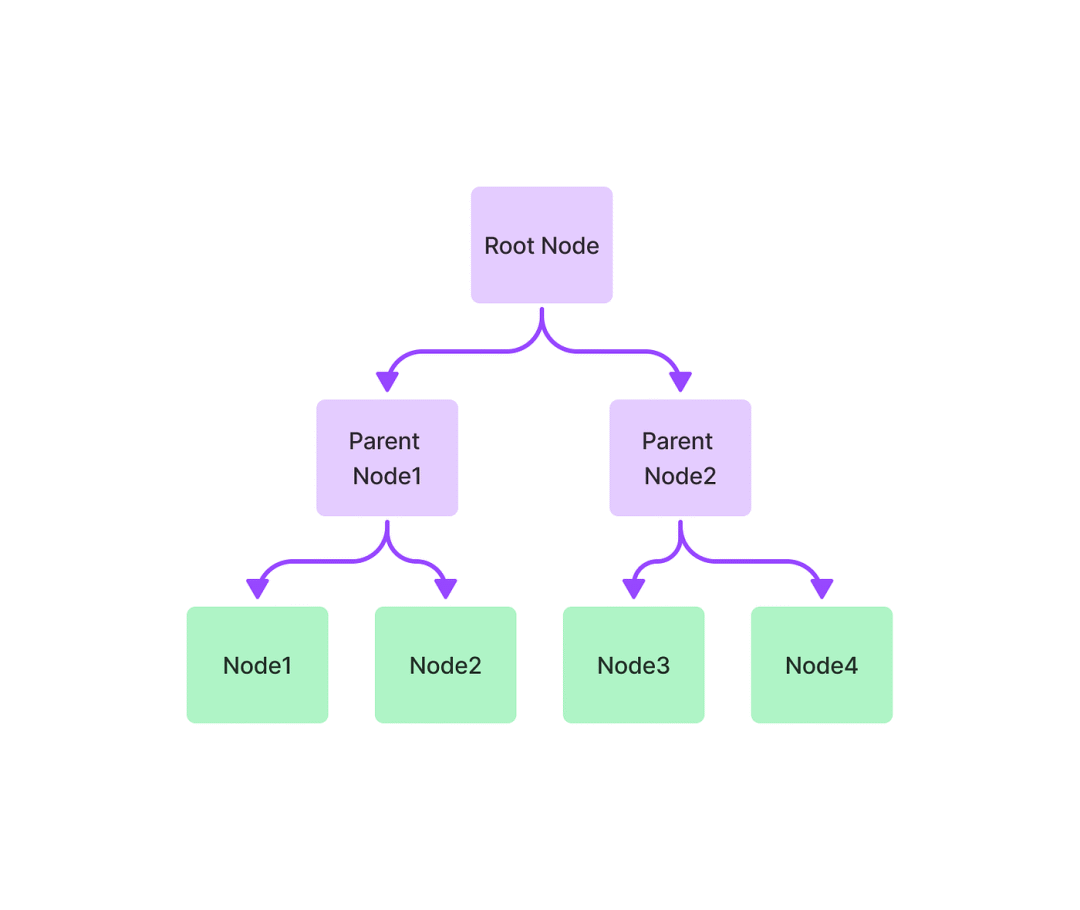
查询树索引涉及从根节点向下遍历到叶节点。默认情况下,(child_branch_factor=1),查询在给定父节点的情况下选择一个子节点。如果child_branch_factor=2,则查询会在每个级别选择两个子节点。

与Vector Index不同,Tree Index是在查询时生成embedding,当然如果在查询时指定retriever_mode=“embedding”,那么embedding会延迟生成并被缓存起来。
from llama_index import GPTTreeIndexnew_index = GPTTreeIndex.from_documents(documents)response = query_engine.query("What is net operating income?")display(Markdown(f"<b>{response}</b>"))## if you want to have more content from the answer,# you can add the parameters child_branch_factor# let's try using branching factor 2query_engine = new_index.as_query_engine(child_branch_factor=2)response = query_engine.query("What is net operating income?")display(Markdown(f"<b>{response}</b>"))
要在查询期间构建Tree Index,我们需要向查询引擎添加retrier_mode和response_mode,并将GPTTreeIndex中的build_Tree参数设置为False。
index_light = GPTTreeIndex.from_documents(documents, build_tree=False)query_engine = index_light.as_query_engine(retriever_mode="all_leaf",response_mode='tree_summarize',)query_engine.query("What is net operating income?")
关键词表索引(Keyword Table Index)
关键字表索引从每个节点提取关键字,并构建从每个关键字到该关键字的相应节点的映射。

在查询期间,我们从查询中提取相关关键字,并将这些关键字与预先提取的Node关键字进行匹配,以获取相应的Node。提取的节点被传递到我们的Response Synthesis模块。

对于GPTKeywordTableIndex,一般情况是使用LLM从每个文档中提取关键字,这意味着它在构建时确实需要LLM调用。但是,如果使用GPTSimpleKeywordTableIndex(使用正则表达式关键字提取器从每个文档中提取关键字),则在构建时不会调用LLM。
from llama_index import GPTKeywordTableIndexindex = GPTKeywordTableIndex.from_documents(documents)query_engine = index.as_query_engine()response = query_engine.query("What is net operating income?")
可组合性图索引(Composability Graph Index)
LlamaIndex通过在现有Index的基础上composite indices,此功能能够高效地索引完整的文档层次结构,并为GPT提供量身定制的知识。通过利用可组合性,您可以在多个级别定义索引,例如单个文档的较低级别索引和文档组的较高级别索引。考虑以下示例:
- 可以为每个文档中的文本创建一个树索引。
- 生成一个列表索引,该索引覆盖整个文档集合的所有树索引。
下面通过一个实例来说明一下可组合性图索引的能力:
-
从多个文档创建树索引
-
从树索引生成摘要。如前所述,树索引对于汇总文档集合非常有用。
-
接下来,我们将创建一个Graph,它在3个树索引之上有一个列表索引。为什么?因为列表索引适合于合成组合多个数据源上的信息的答案。
-
最后查询图形。
我们加载了苹果从Q1–2022和Q1–2023 两个季度10k的金融数据,并进行问答,代码如下:
## reyears = ['Q1-2023', 'Q2-2023']UnstructuredReader = download_loader('UnstructuredReader', refresh_cache=True)loader = UnstructuredReader()doc_set = {}all_docs = []for year in years:year_docs = loader.load_data(f'../notebooks/documents/Apple-Financial-Report-{year}.pdf', split_documents=False)for d in year_docs:d.extra_info = {"quarter": year.split("-")[0],"year": year.split("-")[1],"q":year.split("-")[0]}doc_set[year] = year_docsall_docs.extend(year_docs)
为每个季度数据创建索引
## setting up vector indicies for each year#---# initialize simple vector indices + global vector index# this will use OpenAI embedding as default with text-davinci-002service_context = ServiceContext.from_defaults(chunk_size_limit=512)index_set = {}for year in years:storage_context = StorageContext.from_defaults()cur_index = GPTVectorStoreIndex.from_documents(documents=doc_set[year],service_context=service_context,storage_context=storage_context)index_set[year] = cur_index# store index in the local env, so you don't need to do it over againstorage_context.persist(f'./storage_index/apple-10k/{year}')
从树索引生成摘要。如前所述,树索引对于汇总文档集合非常有用。
# describe summary for each index to help traversal of composed graphindex_summary = [index_set[year].as_query_engine().query("Summary this document in 100 words").response for year in years]
接下来,我们将在3个树索引之上创建一个包括列表索引Graph。
### Composing a Graph to Synthesize Answersfrom llama_index.indices.composability import ComposableGraphfrom langchain.chat_models import ChatOpenAIfrom llama_index import LLMPredictor# define an LLMPredictor set number of output tokensllm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, max_tokens=512, model_name='gpt-3.5-turbo'))service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)storage_context = StorageContext.from_defaults()\## define a list index over the vector indicies## allow us to synthesize information across each indexgraph = ComposableGraph.from_indices(GPTListIndex,[index_set[y] for y in years],index_summaries=index_summary,service_context=service_context,storage_context=storage_context)root_id = graph.root_id#save to diskstorage_context.persist(f'./storage_index/apple-10k/root')## querying graphcustom_query_engines = {index_set[year].index_id: index_set[year].as_query_engine() for year in years}query_engine = graph.as_query_engine(custom_query_engines=custom_query_engines)response = query_engine.query("Outline the financial statement of Q2 2023")response.response
Pandas Index and SQL Index
这个相对比较好理解一些,我们直接展示一下实例代码:
Pandas Index:
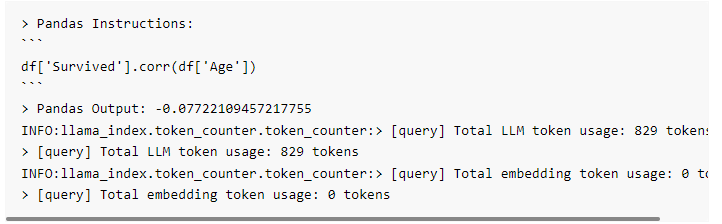
from llama_index.indices.struct_store import GPTPandasIndeximport pandas as pddf = pd.read_csv("titanic_train.csv")index = GPTPandasIndex(df=df)query_engine = index.as_query_engine(verbose=True)response = query_engine.query("What is the correlation between survival and age?",)response
SQL Index:
可以使用LLM去访问传统数据库了,对于传统行业是不有些激动呢?下面展示一个例子,更多例子可以参考(https://gpt-index.readthedocs.io/en/latest/examples/index_structs/struct_indices/SQLIndexDemo.html)
# install wikipedia python package!pip install wikipediafrom llama_index import SimpleDirectoryReader, WikipediaReaderfrom sqlalchemy import create_engine, MetaData, Table, Column, String, Integer, select, columnwiki_docs = WikipediaReader().load_data(pages=['Toronto', 'Berlin', 'Tokyo'])engine = create_engine("sqlite:///:memory:")metadata_obj = MetaData()# create city SQL tabletable_name = "city_stats"city_stats_table = Table(table_name,metadata_obj,Column("city_name", String(16), primary_key=True),Column("population", Integer),Column("country", String(16), nullable=False),)metadata_obj.create_all(engine)from llama_index import GPTSQLStructStoreIndex, SQLDatabase, ServiceContextfrom langchain import OpenAIfrom llama_index import LLMPredictorllm_predictor = LLMPredictor(llm=LLMPredictor(llm=ChatOpenAI(temperature=0, max_tokens=512, model_name='gpt-3.5-turbo')))service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)sql_database = SQLDatabase(engine, include_tables=["city_stats"])sql_database.table_info# NOTE: the table_name specified here is the table that you# want to extract into from unstructured documents.index = GPTSQLStructStoreIndex.from_documents(wiki_docs,sql_database=sql_database,table_name="city_stats",service_context=service_context)# view current table to verify the answer laterstmt = select(city_stats_table.c["city_name", "population", "country"]).select_from(city_stats_table)with engine.connect() as connection:results = connection.execute(stmt).fetchall()print(results)query_engine = index.as_query_engine(query_mode="nl")response = query_engine.query("Which city has the highest population?")

文档摘要索引(Document Summary Index)
Document Summary Index是LlamaIndex全新的数据结构,非常适合QA系统开发的。到目前为止,我们已经研究了单个索引,我们可以通过使用单个索引或将多个索引组合在一起来构建LLM QA应用程序。
一般来说,强大的LLM-QA系统通常由以下方式开发:
-
获取源文档并将其划分为文本块;
-
然后将文本块存储在矢量数据库中;
-
在查询时间期间,通过利用用于嵌入的相似性和/或关键字过滤器来检索文本块;
-
执行Response synthesis;
然而,这种方法有几个限制,会影响检索性能。
当前方法的缺点:
-
文本块没有完整的全局上下文,这通常会限制问答过程的有效性。
-
需要仔细调整top-k/相似性得分阈值,因为太小的值可能导致错过相关上下文,而太大的值可能会增加不相关上下文的成本和延迟。
-
embedding可能并不总是为问题选择最合适的上下文,因为这个过程本质上是分别确定文本和上下文的。
为了增强检索结果,添加了关键字过滤器。然而,这种方法有其自身的一系列挑战,例如通过手动工作或使用NLP关键字提取/主题标记模型来为每个文档识别适当的关键字,以及从查询中推断正确的关键字。

这就是LlamaIndex引入文档摘要索引的地方,该索引可以为每个文档提取和索引非结构化文本摘要,从而提高了现有方法之外的检索性能。这个索引比单个文本块包含更多的信息,并且比关键字标签具有更多的语义。它还允许灵活的检索,包括LLM和基于embedding的方法。
在构建期间,该索引加载文档,并使用LLM从每个文档中提取摘要。在查询期间,它根据摘要检索要查询的相关文档,方法如下:
- 基于LLM的检索:获取文档摘要集合,并请求LLM识别相关文档+相关性得分
- 基于embedding的检索:利用摘要嵌入相似性来检索相关文档,并对检索结果的数量施加top-k限制。
注意:Document Summary Index的检索类检索任何选定文档的所有节点,而不是在节点级别返回相关块。
下面来看一个例子:
import nest_asyncionest_asyncio.apply()from llama_index import (SimpleDirectoryReader,LLMPredictor,ServiceContext,ResponseSynthesizer)from llama_index.indices.document_summary import GPTDocumentSummaryIndexfrom langchain.chat_models import ChatOpenAIwiki_titles = ["Toronto", "Seattle", "Chicago", "Boston", "Houston"]from pathlib import Pathimport requestsfor title in wiki_titles:response = requests.get('https://en.wikipedia.org/w/api.php',params={'action': 'query','format': 'json','titles': title,'prop': 'extracts',# 'exintro': True,'explaintext': True,}).json()page = next(iter(response['query']['pages'].values()))wiki_text = page['extract']data_path = Path('data')if not data_path.exists():Path.mkdir(data_path)with open(data_path / f"{title}.txt", 'w') as fp:fp.write(wiki_text)# Load all wiki documentscity_docs = []for wiki_title in wiki_titles:docs = SimpleDirectoryReader(input_files=[f"data/{wiki_title}.txt"]).load_data()docs[0].doc_id = wiki_titlecity_docs.extend(docs)# # LLM Predictor (gpt-3.5-turbo)llm_predictor_chatgpt = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor_chatgpt, chunk_size_limit=1024)# default mode of building the indexresponse_synthesizer = ResponseSynthesizer.from_args(response_mode="tree_summarize", use_async=True)doc_summary_index = GPTDocumentSummaryIndex.from_documents(city_docs,service_context=service_context,response_synthesizer=response_synthesizer)doc_summary_index.get_document_summary("Boston")
知识图谱索引(Knowledge Graph Index)
它通过在一组文档上提取形式为(主语、谓语、宾语)的知识三元组来构建索引,了解知识图谱的读者不陌生。
在查询期间,它可以只使用知识图作为上下文进行查询,也可以利用每个实体的底层文本作为上下文。通过利用底层文本,我们可以针对文档的内容提出更复杂的查询。
把一个图想象成相互连接的边和顶点。

更多例子,可以参考(https://gpt-index.readthedocs.io/en/latest/examples/index_structs/knowledge_graph/KnowledgeGraphDemo.html)
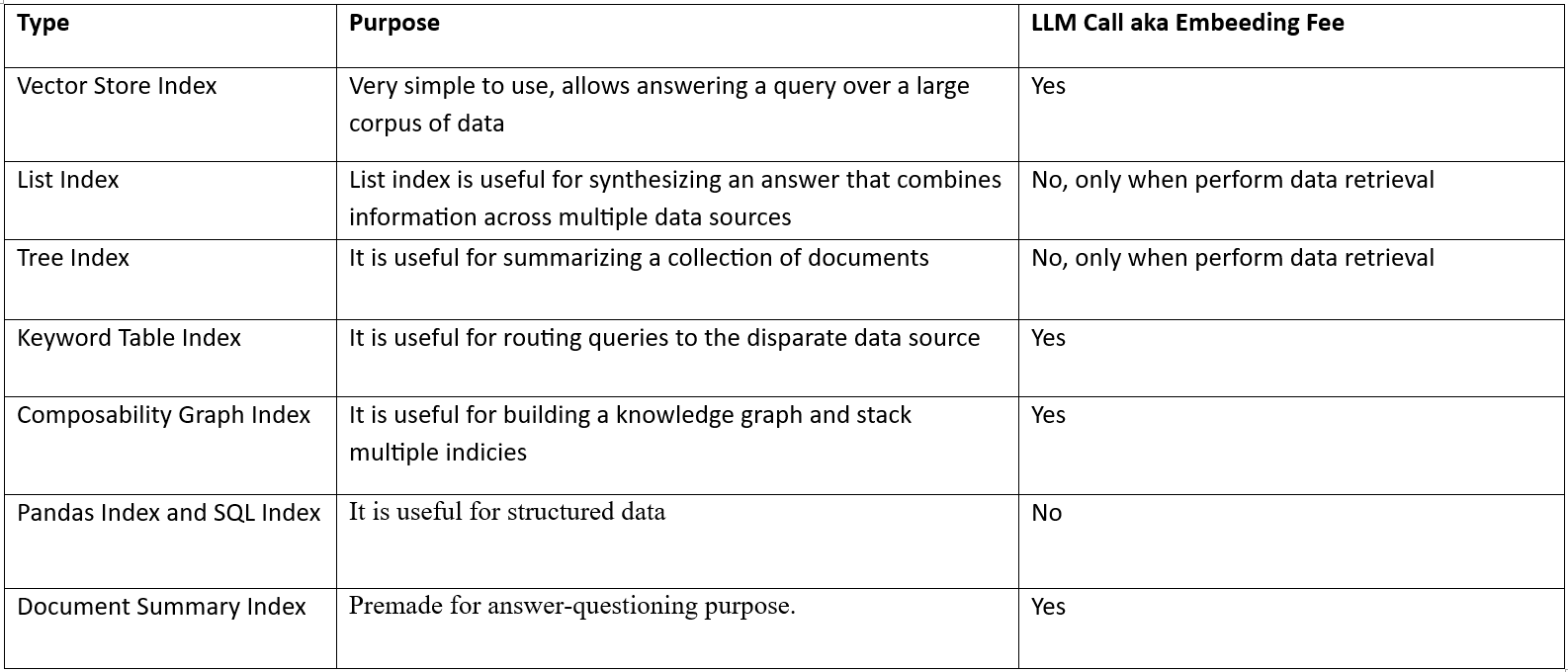
各种Index对比

![[JDK8下的HashMap类应用及源码分析] 数据结构、哈希碰撞、链表变红黑树](https://img-blog.csdnimg.cn/c02ef767a9e743068b4ff6034a46cb21.png)