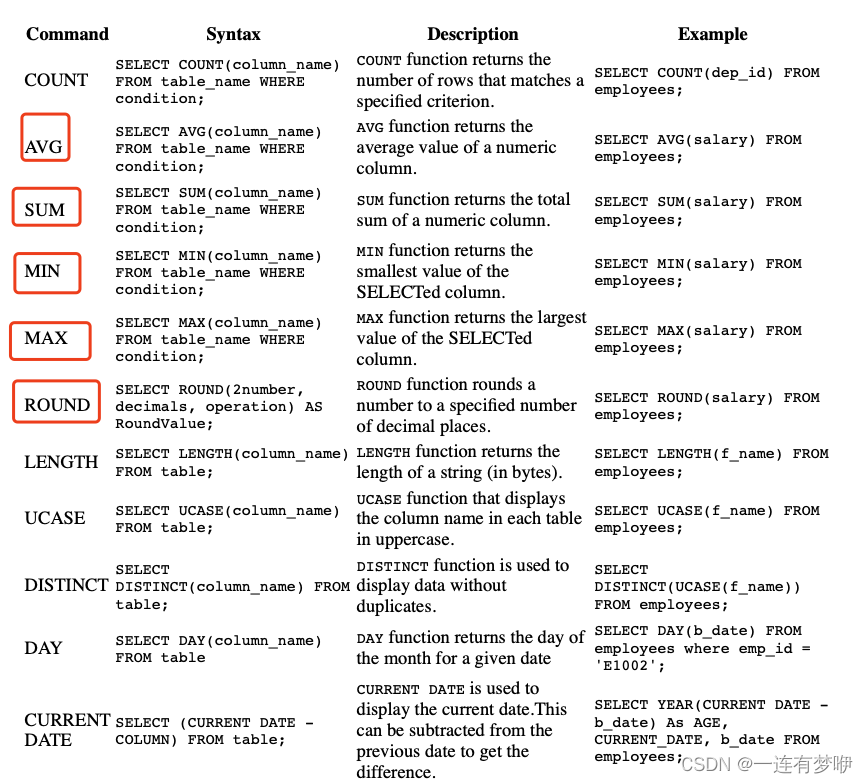
一、什么是自定义类型
C语言提供了丰富的内置类型,常见的有int, char, float, double, 以及各种指针。
除此之外,我们还能自己创建一些类型,这些类型称为自定义类型,如数组,结构体,枚举类型和联合体类型。
二、数组
把一组相同类型的元素放到一起,就是数组。数组按照结构分为一维数组,二维数组等等,按照存储元素类型又可以分为整型数组,浮点型数组等等。
2.1 定义
假设一个数组能存储5个元素,每个元素是int类型的,可以如下定义:
int arr[5];上面是一个常见的一维数组。如果我们想定义一个二维数组呢?比如一个3行5列的数组,每个元素是char*类型,应该如下定义:
char* ch[3][5];2.2 初始化
对于一维数组,可以用大括号把要初始化的数据括起来,用来初始化这个数组。如:
int arr[5] = {1,2,3,4,5};对于上面这行代码,可以这么用语言表述:有一个一维数组,数组名叫做arr,数组存储了5个元素,每个元素的类型是int,在定义这个数组的同时我们对它进行了初始化,使得它存储的元素分别是1~5。
以上写法非常基础,还有一些进阶的写法。比如,当数组定义的同时对其初始化,可以省略元素个数。如:
int arr[] = {1,2,3,4,5};此时编译器会根据大括号里有5个元素,来确定数组的元素个数是5。
如果我们只想初始化一部分元素呢?
int arr[5] = {1,2,3};数组一共有5个元素,但我们只初始化了3个。当初始化的元素个数小于数组的元素个数时,剩余的元素会被默认初始化成0。如以上的代码的意思是:我们把数组的前3个元素初始化成1,2,3,剩下的2个元素都初始化成0。这种初始化方式被称为不完全初始化。
思考:如何创建一个数组,数组名叫ch,能存储10个元素,存储的元素类型是char,并把所有元素都初始化成'\0'(ASCII码值是0)?
char ch[10] = {0};以上是一维数组的初始化。如果是二维数组呢?假设有一个三行五列的数组,总共有15个数,分别是:
第一行:1,2,3,4,5
第二行:6,7,8,9,10
第三行:11,12,13,14,15
我们可以把每一行当成一个一维数组,用大括号括起来,并且在最外面再加上一个大括号。
int arr[3][5] = {{1,2,3,4,5}, {6,7,8,9,10}, {11,12,13,14,15}};对于二维数组,如果能确定行数,可以把行数省略。注意:列数无论如何都不能省略!
int arr[][5] = {{1,2,3,4,5}, {6,7,8,9,10}, {11,12,13,14,15}};以上代码中,编译器会自动识别数组一共有3行。
如果确定数组元素的顺序,内层的大括号可以省略。如:
int arr[3][5] = {1,2,3,4,5, 6,7,8,9,10, 11,12,13,14,15};以上代码效果是一样的。编译器会自动用1,2,3,4,5初始化第一行,6,7,8,9,10初始化第二行,依此类推。
如果是不完全初始化,没有初始化的元素会被默认初始化成0。
int arr[3][5] = {1,2,3,4,5, 6,7,8,9,10};以上代码中,第三行会被默认初始化成0。
注意:如果只定义,不初始化,并且数组是局部的(在大括号内部),则所有的元素都是随机值。
int arr[5];此时数组存储的是5个随机值。
2.3 访问
数组的元素是有下标的,每个元素都对应一个下标。第一个元素的下标是0,后面元素的下标依次递增。如假设一个一维数组有5个元素,则元素的下标分别是0~4。数组的元素可以用下标访问。如:
arr[3] = 30;就把数组arr中下标为3的元素改成了30。
对于二维数组,每个元素有2个下标。行标和列标都是从0开始的。假设有一个3行5列的数组,则第一行的行标为0,第二行的行标为1,第三行的行标为2。列标同理,第一列到第五列的下标分别是0~4。每个元素都要写明白行标和列标,如:
arr[2][3] = 100;就表示把数组的行标为2,列标为3的元素改成了100。
2.4 内存分布
对于一维数组,随着下标的增长,地址是连续的,由低到高变化的!
char ch[5];
for (int i = 0; i < 5; ++i)
{printf("&ch[%d] = %p\n", i, &ch[i]);
}打印出来的地址信息是:

可以发现地址是连续增长的,由于一个char类型的数据是1个字节,相邻元素的地址也相差1个字节。
那二维数组呢?
char ch[3][5];
for (int i = 0; i < 3; ++i)
{for (int j = 0; j < 5; ++j){printf("&ch[%d][%d] = %p\n", i, j, &ch[i][j]);}
}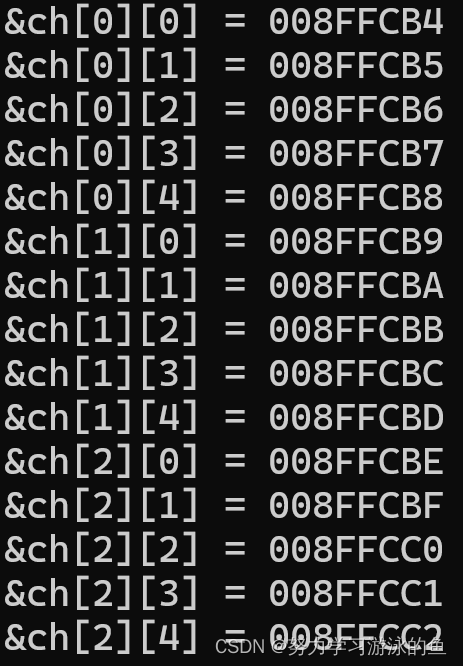
可以看到相同行中,随着列标的增长,地址是由低到高连续增长的。并且每一行的最后一个元素和下一行的第一个元素是无缝对接的。
三、结构体类型
3.1 定义
数组是把相同类型的元素放到一块去。如果是把不同的元素放到一块去呢?比如说,要想描述清楚一个学生,我们需要知道他的姓名,学号和成绩。姓名和学号是字符数组,成绩是浮点型。我们就可以声明一个结构体类型:
struct Stu
{char name[20];char id[20];float score;
};其中,struct Stu是一种结构体类型,name,id,score就是这个结构体类型创建出来的结构体变量的成员变量。
这样,我们就可以定义一个结构体,用来描述某个学生。
struct Stu s;我们可以在声明的同时定义。如:
struct Stu
{char name[20];char id[20];float score;
}s;3.2 初始化
如果我们想在定义的同时对这个结构体初始化,可以用大括号把初始化的数据括起来。
struct Stu s = {"Zhang San", "12345xyz", 95.0f};我们可以在声明的同时初始化:
struct Stu
{char name[20];char id[20];float score;
}s = {"Zhang San", "12345xyz", 95.0f};3.3 访问
如何把张三的成绩改成59.5f呢?我们可以使用结构成员访问操作符。具体使用方式是:
结构体变量名.成员变量名如:
s.score = 59.5f;假设我们使用了一个指针ps来保存s的地址。
struct Stu* ps = &s;那么访问时就需要先解引用。
(*ps).score = 59.5f;但这样写太麻烦了,有一种写法和上面这种写法是等价的。
ps->score = 59.5f;这里的->就等价于先解引用再访问结构体成员变量。
3.4 内存分布
划重点!结构体在内存中的存储需要遵循内存对齐规则。
先介绍几个概念:
-
针对某一个地址ptr1,我们定义另一个地址ptr2的偏移量为((int)ptr2-(int)ptr1)。简单来说,某一个地址相对于另一个地址的偏移量就是把这两个地址当成整数后的差。
-
每个编译器会根据环境,有一个默认对齐数。这个默认对齐数取决于编译器,但我们是可以修改的。修改方法如下:
#pragma pack(4)就把默认对齐数设置成4。如果省略括号里的数,就会重置默认对齐数为默认值。
#pragma pack()内存对齐的规则如下:
-
结构体变量的第一个成员变量存储在偏移量为0的地址处。注意:此处的偏移量是针对某一个地址的偏移量,对于同一个结构体变量,我们讨论偏移量都是针对同一个地址的偏移量。
-
从第二个成员变量开始,存储位置的偏移量是(自身大小和默认对齐数的较小值)的整数倍。我们把括号括起来的部分称之为这个成员变量的对齐数。把这个结构体变量的所有对齐数的最大值称之为这个结构体变量的最大对齐数。
-
结构体变量的总大小是这个结构体变量的最大对齐数的整数倍。
-
以上三点是针对没有嵌套结构体的情况,也就是说,结构体的成员变量中不存在结构体。对于嵌套的结构体的对齐数的计算也满足规则2,结构体的总大小是所有对齐数(包括嵌套结构体的对齐数)的整数倍。
举个例子:以下程序会输出多少?
#include <stdio.h>#pragma pack(8)
struct A
{double d1;char c1;int i;double d2;char c2;
}a;
#pragma pack()int main()
{printf("%d\n", sizeof(a));return 0;
}根据规则1,d1的起始偏移量为0,而d1的大小是8,故d1的偏移量是0~7。
根据规则2,c1的起始偏移量至少为8,且是其对齐数的整数倍。c1的对齐数为min(sizeof(c1), 8)=1,8是1的整数倍。又因为c1的大小是1,故c1的偏移量是8。
根据规则2,i的起始偏移量至少是9,且是其对齐数的整数倍。i的对齐数为min(sizeof(i), 8)=4。9不是4的整数倍,同理10,11都不是。故i的起始偏移量是12。又因为i的大小是4,故i的偏移量是12~15。
根据规则2,d2的起始偏移量至少是16,且是其对齐数的整数倍。d2的对齐数为min(sizeof(d2), 8)=8。16是8的倍数,故d2的起始偏移量是16。又因为d2的大小是8,故d2的偏移量是16~23。
根据规则2,c2的起始偏移量至少是24,且是其对齐数的整数倍。c2的对齐数为min(sizeof(c2), 8)=1。24是1的倍数,故c2的起始偏移量是24。又因为c2的大小是1,故c2的偏移量是24。
根据规则3,a的总大小至少是25(偏移量0~24),且是其最大对齐数的整数倍。最大对齐数是以上算出来的对齐数的最大值,即8。而25不是8的倍数。比25大的整数中,最小的8的倍数是32,故a的总大小是32个字节。
对于有嵌套结构体的情况同理。朋友们可以自行验证。
四、枚举类型
4.1 定义
枚举,即一一列举。比如三原色,就是红绿蓝。我们就声明一个枚举类型。
enum Color
{RED,GREEN,BLUE
};从而定义枚举变量。
enum Color c;和结构体类似,也可以在声明时定义。
enum Color
{RED,GREEN,BLUE
}c;4.2 初始化
可以使用枚举常量来初始化枚举变量。如:
enum Color c = GREEN;注意:枚举常量,默认从0开始,从上到下依次递增。如对于enum Color类型,RED的值是0,GREEN的值是1,BLUE的值是2。
五、联合体类型
5.1 定义
联合体类型的成员变量公用同一块空间,并且遵守内存对齐规则。如:
union U
{int i;char c;
};这个类型大小是4个字节,其中i占满全部的4个字节,而c只占第一个字节,它们共用同一块空间,所以联合体又叫做共用体。
5.2 访问
访问方式和结构体类似。如:
union U u;
u.i = 10;


![[PyTorch][chapter 54][Variational Auto-Encoder 实战]](https://img-blog.csdnimg.cn/c27f973ceff14d1e95b4aac79292b719.png)