redo log
redo log叫做重做日志.用于解决数据库事物提交 还未刷入磁盘,服务器down机导致的数据丢失的问题。
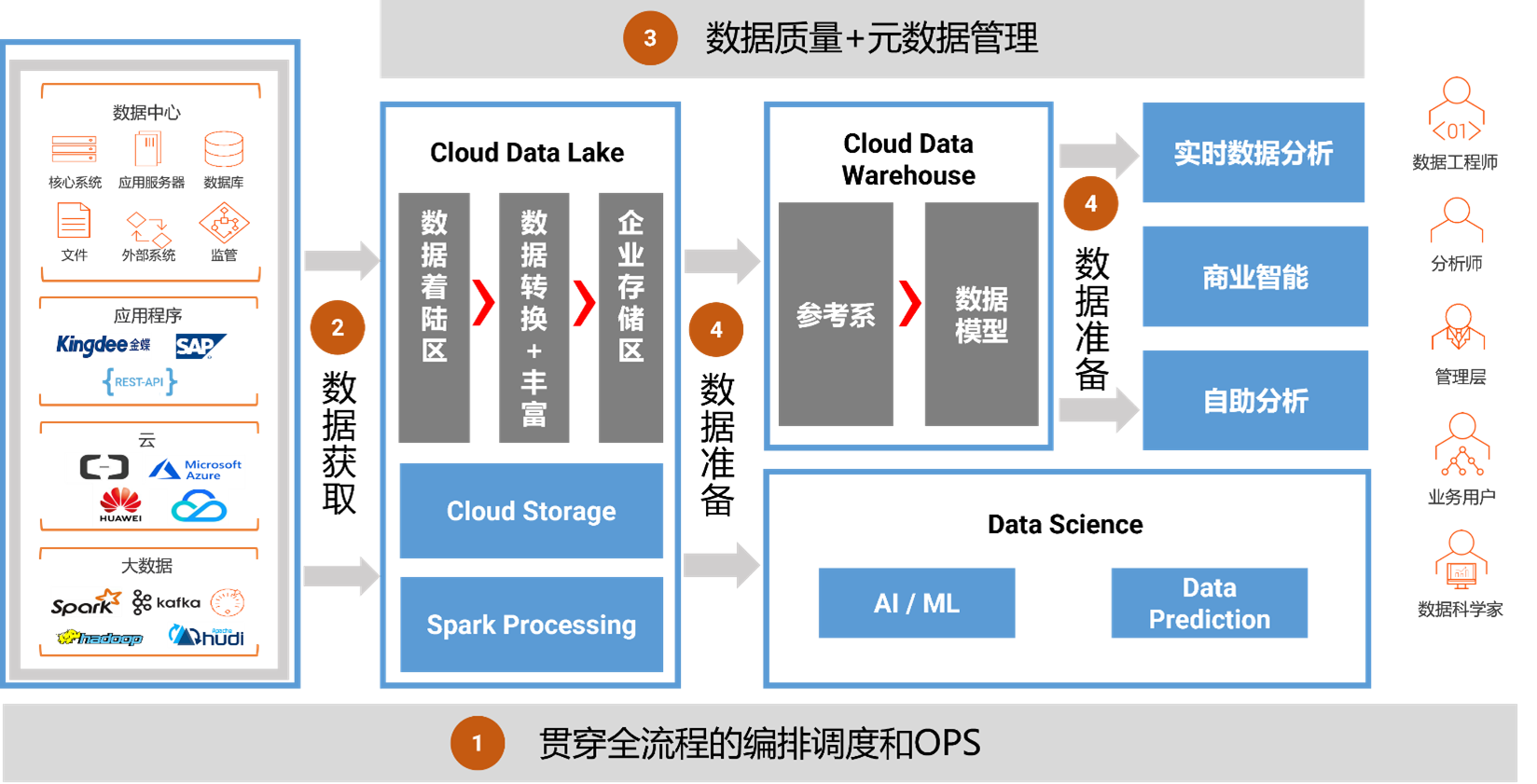
InnoDB作为MySQL的存储引擎,数据存储在磁盘中,如果每次读写数据都要操作磁盘IO效率会很低,为此InnoDB提供了缓存(Buffer Pool),Buffer Pool中包含了磁盘中部分数据页的映射,作为访问数据库的缓冲:当从数据库读取数据时,会首先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool;当向数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中(刷脏)
Buffer Pool的使用大大提高了读写数据的效率,但是也带了新的问题:如果MySQL宕机,而此时Buffer Pool中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。
于是,redo log被引入来解决这个问题:当数据修改时,除了修改Buffer Pool中的数据,还会在redo log记录这次操作;当事务提交时,会调用fsync接口对redo log进行刷盘。如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool,保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。
既然redo log也需要在事务提交时将日志写入磁盘,为什么它比直接将Buffer Pool中修改的数据写入磁盘(即刷脏)要快呢?主要有以下两方面的原因:
(1)刷脏是随机IO,因为每次修改的数据位置随机,但写redo log是追加操作,属于顺序IO。
(2)刷脏是以数据页(Page)为单位的,MySQL默认页大小是16KB,一个Page上一个小修改都要整页写入;而redo log中只包含真正需要写入的部分,无效IO大大减少。

undo log
undo log的2个主要作用是实现MVCC和事物回滚
当 delete 一条记录时,undo log 中会记录一条对应的 insert 记录,反之亦然,当 update 一条记录时,它记录一条对应相反的 update 记录,如果 update 的是主键,则是对先删除后插入的两个事件的反向逻辑操作的记录。

在事物回滚时就会反向读取相应内容进行回滚,也可以根据undo log读取到被修改后数据的原值

喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!