哈希函数
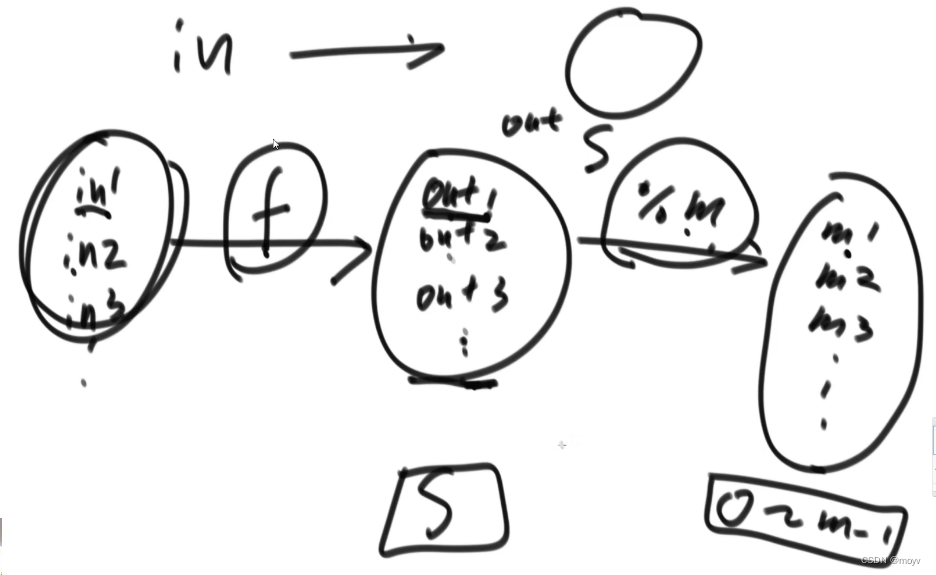
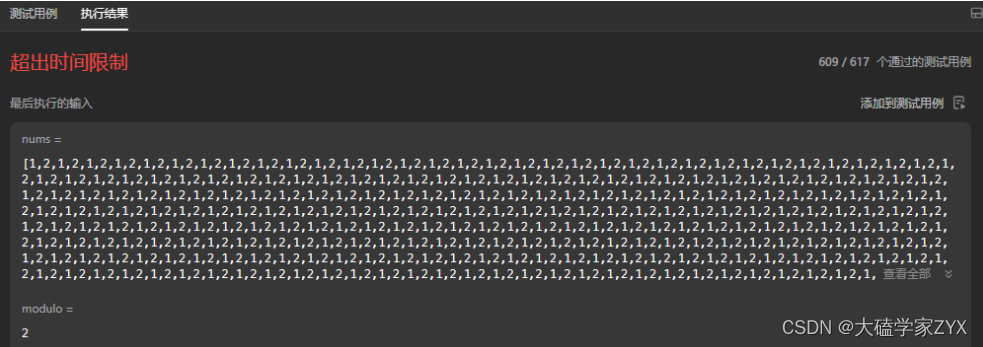
出现次数最多的
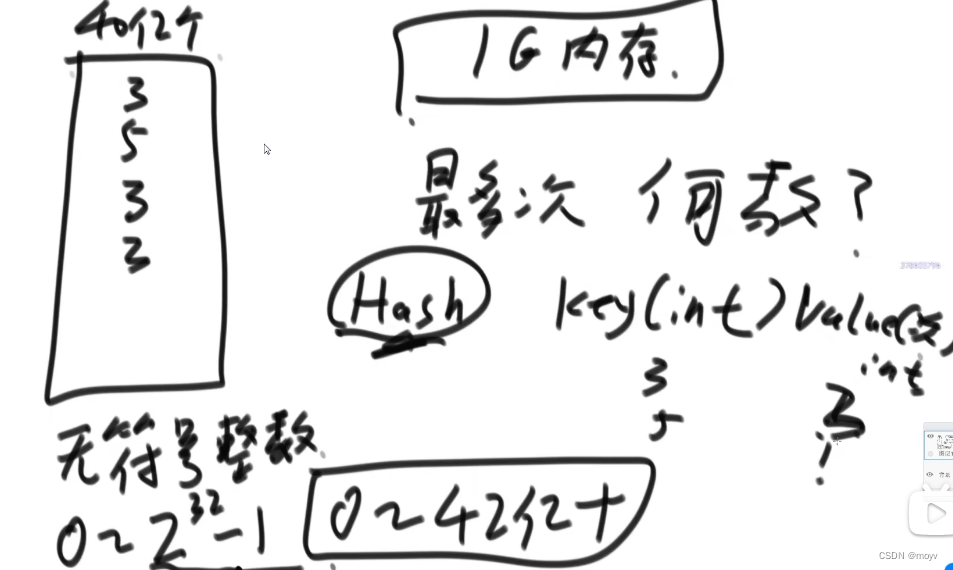
32G
小文件方法:利用哈希函数在种类上均分
设计RandomPool结构
设计一种结构,在该结构中有如下三个功能:
insert(key):将某个key加入到该结构,做到不重复加入
delete(key):将原本在结构中的某个key移除
getRandom(): 等概率随机返回结构中的任何一个key。
【要求】
Insert、delete和getRandom方法的时间复杂度都是O(1)
准备两张表
如果总size是26,那么利用random可以等概率随即返回
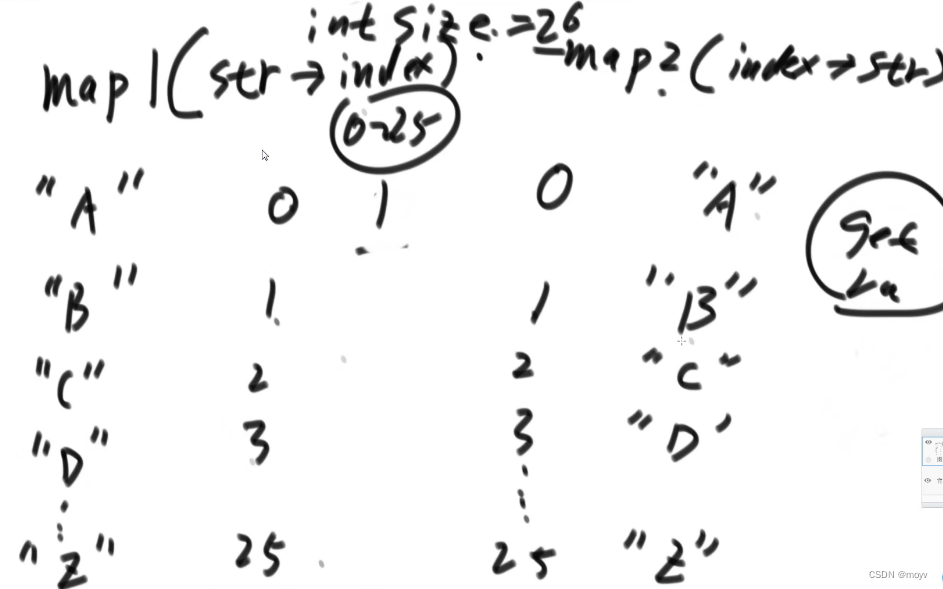
不可以直接删除,要拿最后一条记录填洞,然后index区域上都是连续的,仍然可以random

package tisheng.class01;import java.util.HashMap;public class Code02_RandomPool {public static class Pool<K> {private HashMap<K, Integer> keyIndexMap;private HashMap<Integer, K> indexKeyMap;private int size;public Pool() {this.keyIndexMap = new HashMap<K, Integer>();this.indexKeyMap = new HashMap<Integer, K>();this.size = 0;}public void insert(K key) {if (!this.keyIndexMap.containsKey(key)) {this.keyIndexMap.put(key, this.size);this.indexKeyMap.put(this.size++, key);}}public void delete(K key) {if (this.keyIndexMap.containsKey(key)) {int deleteIndex = this.keyIndexMap.get(key);int lastIndex = --this.size;K lastKey = this.indexKeyMap.get(lastIndex);this.keyIndexMap.put(lastKey, deleteIndex);this.indexKeyMap.put(deleteIndex, lastKey);this.keyIndexMap.remove(key);this.indexKeyMap.remove(lastIndex);}}public K getRandom() {if (this.size == 0) {return null;}int randomIndex = (int) (Math.random() * this.size); // 0 ~ size -1return this.indexKeyMap.get(randomIndex);}}public static void main(String[] args) {Pool<String> pool = new Pool<String>();pool.insert("zuo");pool.insert("cheng");pool.insert("yun");System.out.println(pool.getRandom());System.out.println(pool.getRandom());System.out.println(pool.getRandom());System.out.println(pool.getRandom());System.out.println(pool.getRandom());System.out.println(pool.getRandom());}}布隆过滤器
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,它用来检测一个元素是否在一个集合中。布隆过滤器的基本原理是,它使用一个位数组以及几个不同的随机映射函数来存储元素。当需要查询一个元素是否在集合中时,布隆过滤器通过这些映射函数快速地检查位数组中的几个位置。如果元素在集合中,这些位置的位应该都为1;如果元素不在集合中,这些位置的位可能为0或1。 放在内存中,允许一定的失误率(不会出现在黑名单中却没有找出),但是可以通过设计使失误率很低。
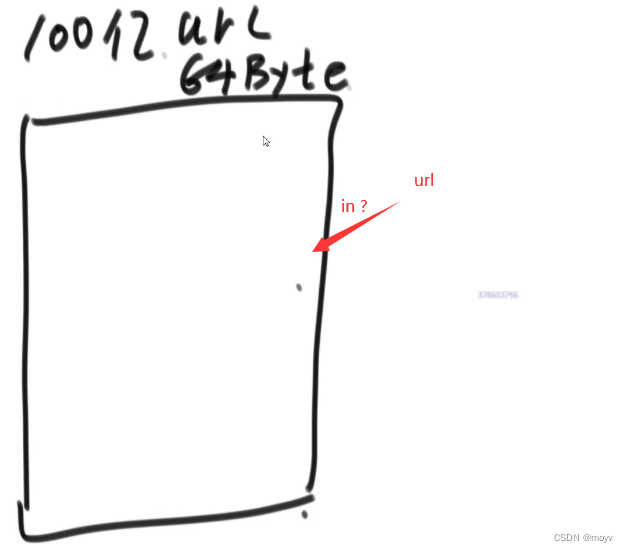
6400亿,开销太大,放在硬盘查询时间又太长
位图
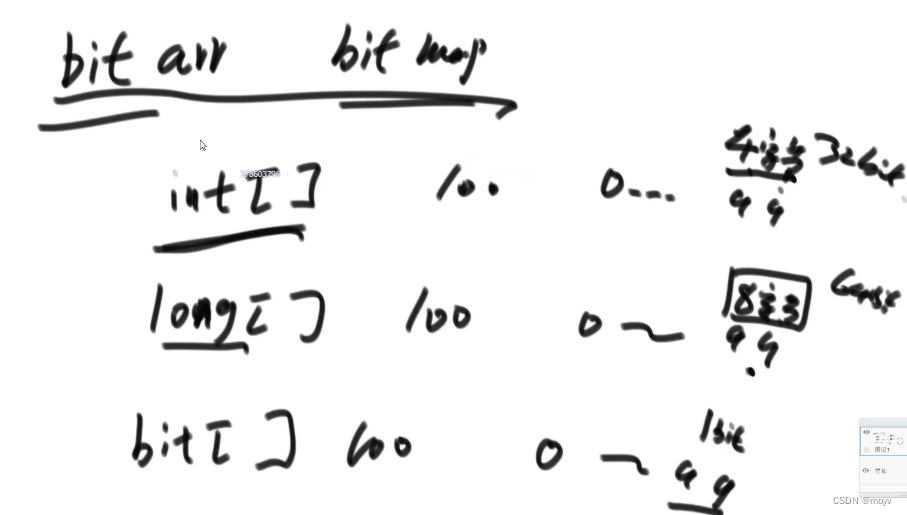
用基础类型拼
package tisheng.class01;public class Code05_BitMap {public static void main(String[] args) {int a = 0;//a 32 bitint[] arr = new int[10];//32bit * 10 -> 320bits的信息//arr[0] int 0 ~ 31//arr[1] int 32 ~ 63//arr[2] int 64 ~ 95int i = 178;//想取得178个bit的状态int numIndex = 178/32;int bitIndex = 178%32;//拿到178位状态int s = (arr[numIndex]>>(bitIndex) & 1);//把178位状态改成1arr[numIndex] = arr[numIndex] | (1<<(bitIndex));//把178位状态改成0arr[numIndex] = arr[numIndex] & (~(1<<(bitIndex)));}
}u1通过多个哈希函数计算,在不同区域记录
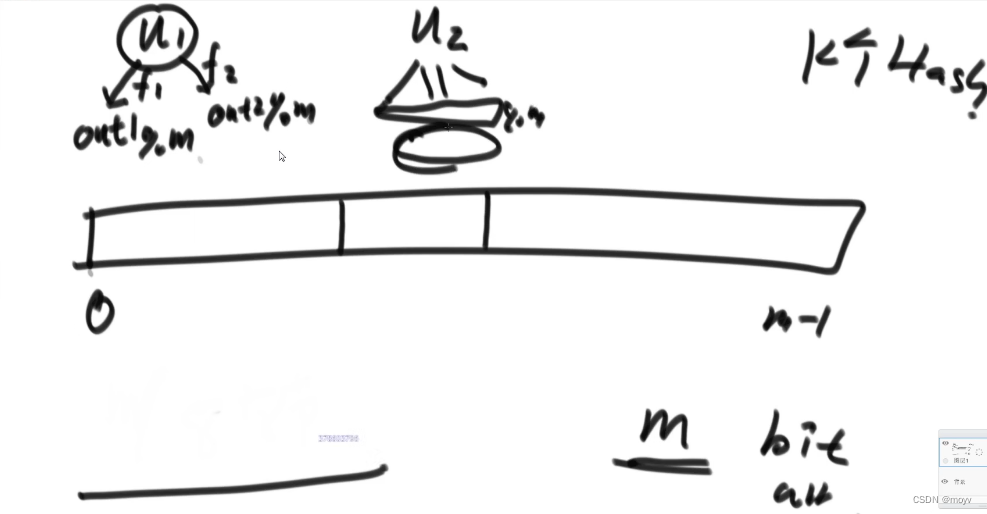
要数据的时候,查询每一个,全是1才认为有记录

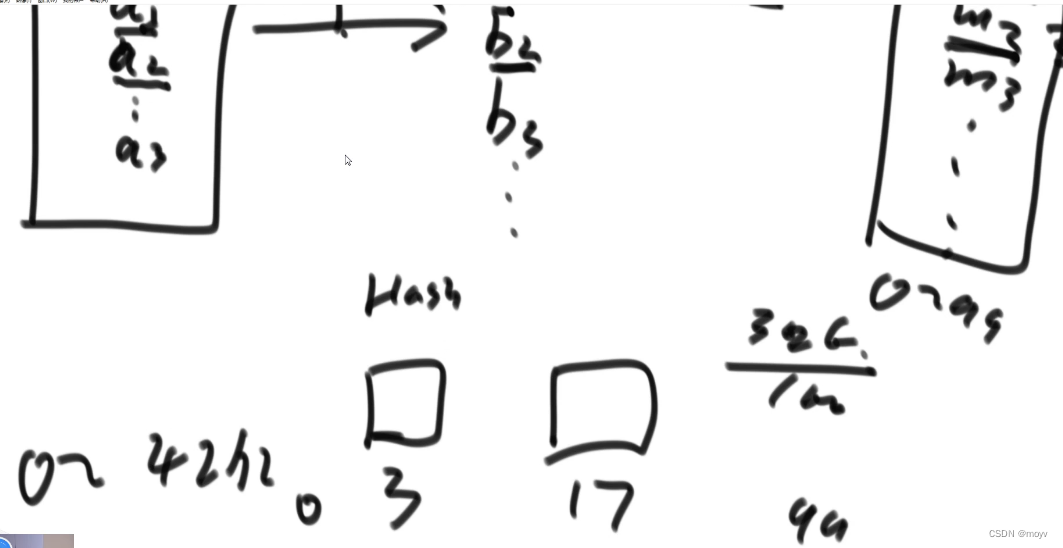
一致性哈希
数据种类均匀分配
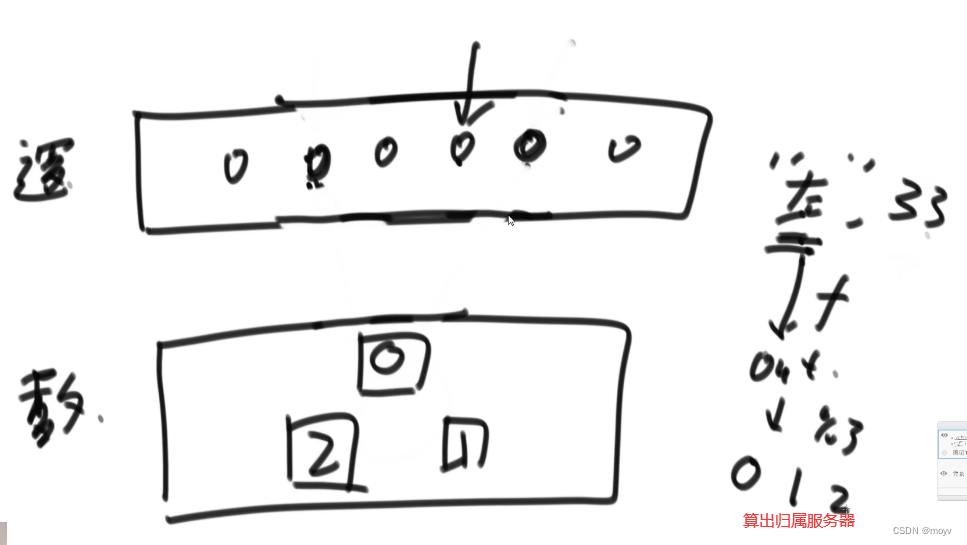

数据迁移的代价是全量的
一致性哈希:一致性哈希(Consistent Hashing)是一种特殊的哈希算法,由麻省理工学院在1997年提出。这种哈希算法旨在解决分布式缓存的问题,尤其是当移除或添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。这解决了简单哈希算法在分布式哈希表(Distributed Hash Table,DHT)中存在的动态伸缩等问题。
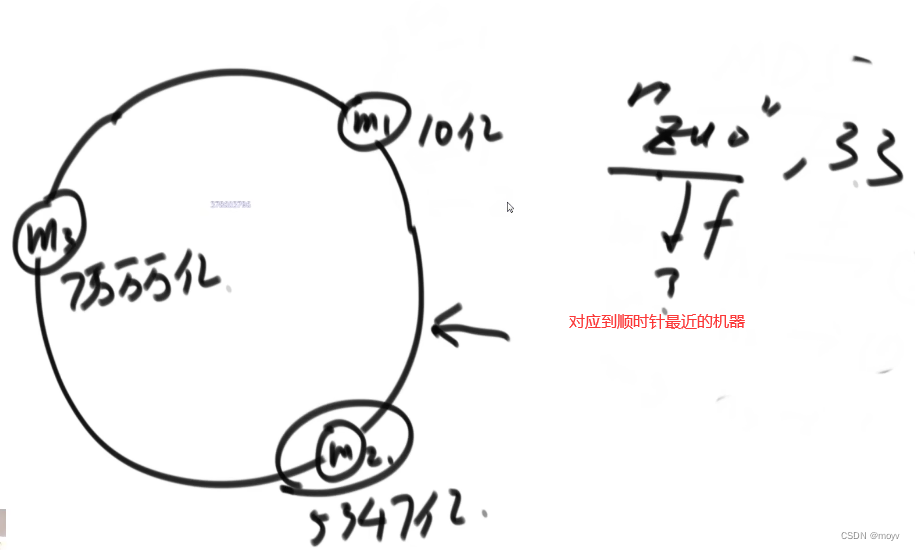
逻辑端
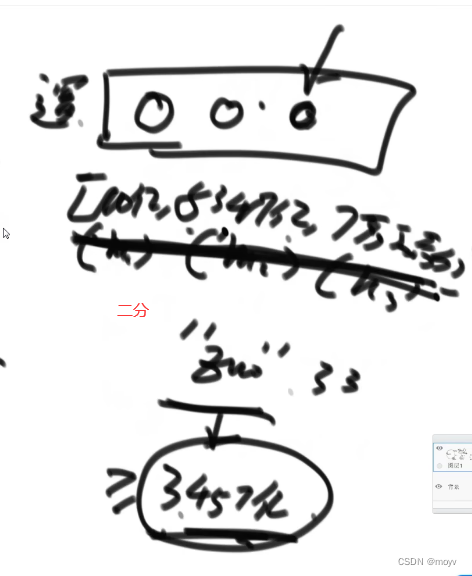
增加服务器数据迁移
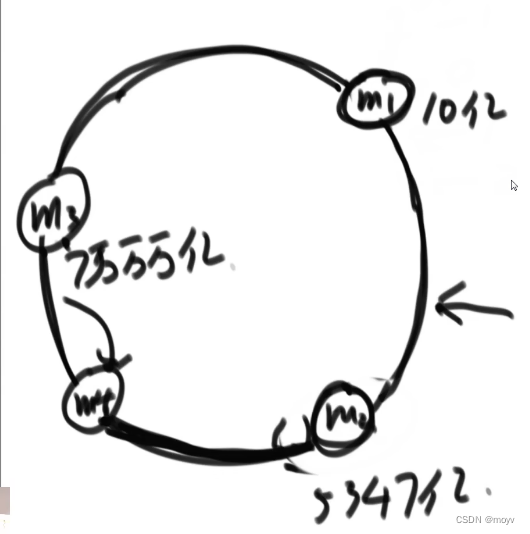
删4给3
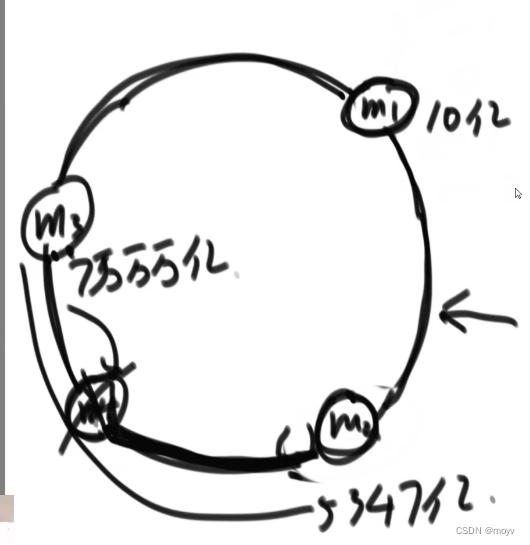
但开始可能不均分,增减之后可能不均衡
解决方法:虚拟结点技术
三个机器分别分配一千个字符串
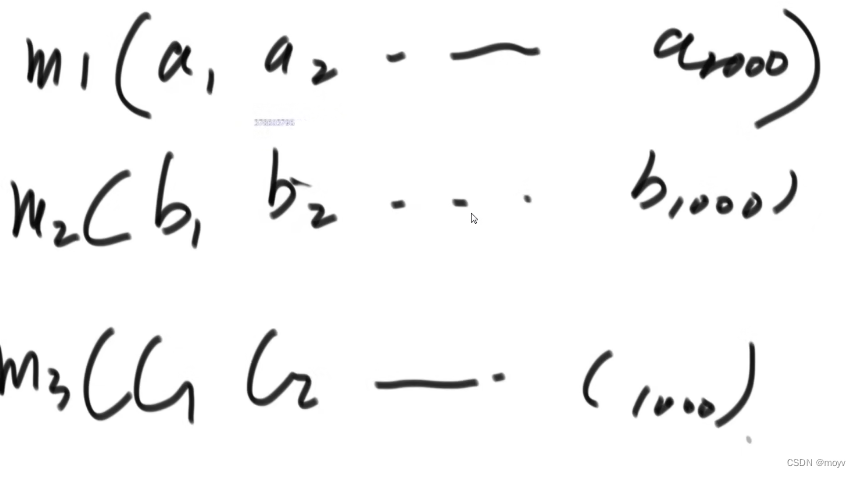
虚拟结点抢环,按照比例
增减都按照比例