在面试的时候,面试官常常会问一些问题:
- k8s是什么?有什么用?
- k8s由哪些组件组成?
- pod的启动流程?
- k8s里有哪些控制器?
- k8s的调度器里有哪些调度算法?
- pod和pod之间的通信过程?
- 外面用户访问pod数据流程?
- 你常用哪些命令?
- 容器的类型?
- 3种探针?
- pod的升级?
- HPA、VPA、CA?
- 污点和容忍?
- 有状态的应用和无状态的应用?
- ingress相关?
- RBAC相关?
- CI/CD 持续集成、持续交付 jenkins?
- pod有多少种状态?
- pod的重启策略?
下面,就让我来详细说明一些这些问题
1. k8s是什么?有什么用?
k8s就是一个编排容器的工具,一个可以管理应用全生命周期的工具,从创建应用,应用的部署,应用提供服务,扩容缩容应用,应用更新,都非常的方便,而且可以做到故障自愈。
例如:一个服务器挂了,K8s可以自动将这个服务器上的服务调度到另外一个主机上进行运行,无需进行人工干涉。
所以 k8s 一般都是和 Docker 搭配起来使用的。
2. k8s由哪些组件组成?
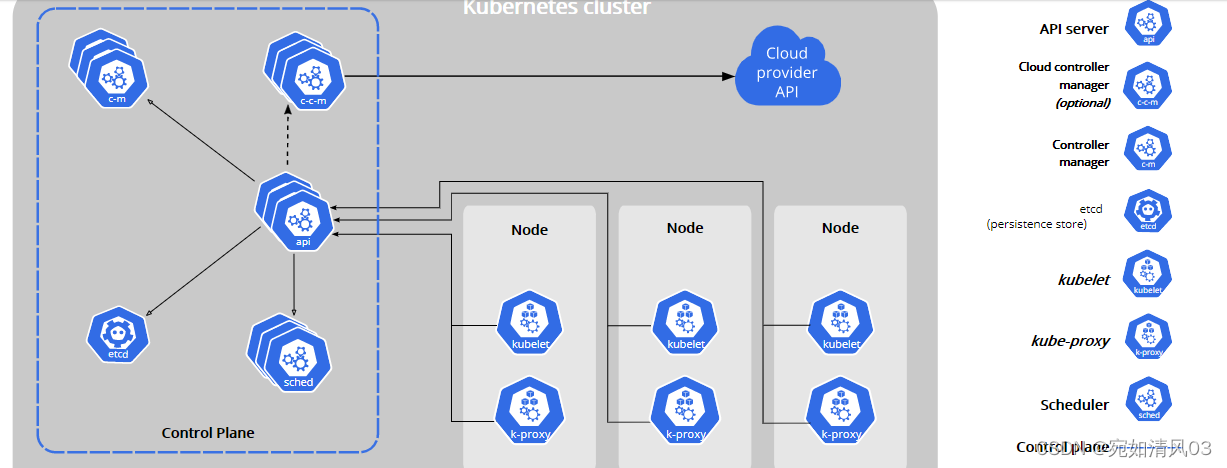
k8s的master里有哪些组件?
- 1.etcd 存放数据
- 2.scheduler 调度器 --》例如:容器(pod)到底在那个node服务器上启动
- 3.api-server 接口: master和node之间通信和交换数据
- 4.controller 控制器: deployment 部署控制器,replicaSET 副本控制器等
k8s的node节点上有哪些组件?
- 1.kubulet 帮助启动容器的
- 2.kubu-proxy 负责网络通信和负载均衡
master上
API Server
API 服务器是 Kubernetes 控制平面的组件, 该组件负责公开了 Kubernetes API,负责处理接受请求的工作。 API 服务器是 Kubernetes 控制平面的前端。
etcd
数据库, 一致且高可用的键值存储,用作 Kubernetes 所有集群数据的后台数据库。
kube-scheduler
调度器, 负责监视新创建的、未指定运行节点(node)的 Pods, 并选择节点来让 Pod 在上面运行。
kube-controller-manager
控制器管理器,负责运行控制器进程
cloud-controller-manager
嵌入了特定于云平台的控制逻辑,与公有云进行对接的控制器
node上
kubelet
它保证容器(containers)都运行在 Pod 中。
单独的程序,在宿主机里运行
[root@k8smaster kubernetes]# ps aux|grep kubelet
root 1020 6.7 2.2 1951916 87964 ? Ssl 09:58 7:01 /usr/bin/kubeletkube-proxy
是集群中每个节点(node)上所运行的网络代理
kube-proxy 维护节点上的一些网络规则, 这些网络规则会允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了可用的数据包过滤层,则 kube-proxy 会通过它来实现网络规则。 否则,kube-proxy 仅做流量转发。
单独的程序,在宿主机里运行
[root@k8smaster kubernetes]# ps aux|grep kube-proxy
root 3548 0.2 0.8 744320 32848 ? Ssl 09:59 0:13 /usr/local/bin/kube-proxy --config=/var/lib/kube-proxy/config.conf --hostname-override=k8smaster
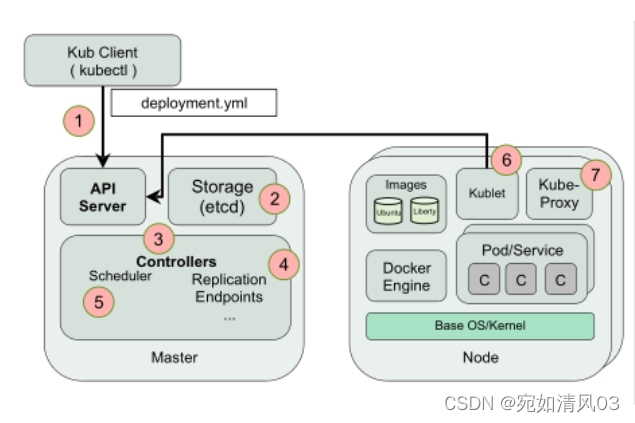
root 100881 0.0 0.0 112828 992 pts/0 S+ 11:42 0:00 grep --color=auto kube-proxy3. pod的启动流程?

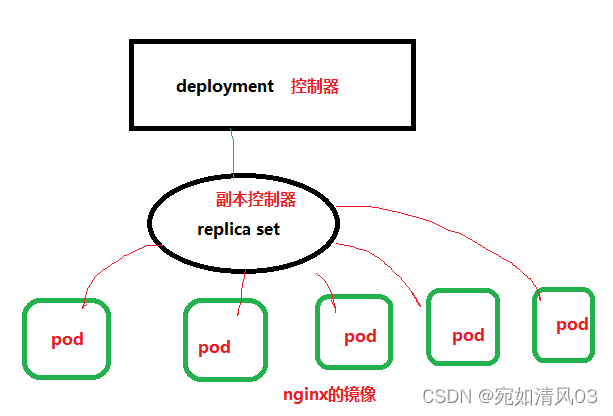
4. k8s里有哪些控制器?
deployment-部署控制器
一旦运行了 Kubernetes 集群,就可以在其上部署容器化应用程序。 为此,您需要创建 Kubernetes Deployment 配置。Deployment 指挥 Kubernetes 如何创建和更新应用程序的实例。创建 Deployment 后,Kubernetes master 将应用程序实例调度到集群中的各个节点上。
创建 Deployment 时,您需要指定应用程序的容器映像以及要运行的副本数。
deployment控制器会去node节点上去创建pod,根据你指定的镜像名字,在pod里创建需要的容器
删除deployment,就自动删除启动的pod
ReplicaSet-副本的控制器
光从ReplicaSet这个控制器的名字(副本集)也能想到它是用来控制副本数量的,这里的每一个副本就是一个Pod。ReplicaSet它是用来确保我们有指定数量的Pod副本正在运行的Kubernetes控制器,意在保证系统当前正在运行的Pod数等于期望状态里指定的Pod数目。
一般来说,Kubernetes建议使用Deployment控制器而不是直接使用ReplicaSet,Deployment是一个管理ReplicaSet并提供Pod声明式更新、应用的版本管理以及许多其他功能的更高级的控制器。所以Deployment控制器不直接管理Pod对象,而是由 Deployment 管理ReplicaSet,再由ReplicaSet负责管理Pod对象。
daemonSet-守护进程控制器
当我们启动pod的时候,每个node节点上只启动一个pod
举例: 假如我们有6个node,需要在每个node上一个安装一个监控使用的pod ,就可以使用Daemon Sets--》特别适合日志采集和数据收集的pod
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本
job-批处理控制器
Job控制器用于Pod对象运行一次性任务,容器中的进程在正常运行结束后不会对其进行重启,而是将Pod对象置于"Completed"(完成)状态,若容器中的进程因错误而终止,则需要按照重启策略配置确定是否重启,未运行完成的Pod对象因其所在的节点故障而意外终止后会被调度。
cronjob-计划任务控制器
CronJob 用于执行周期性的动作,例如备份、报告生成等。 这些任务中的每一个都应该配置为周期性重复的(例如:每天/每周/每月一次); 你可以定义任务开始执行的时间间隔。
计划任务相关
5. k8s的调度器里有哪些调度算法?
- 1.deployment: 全自动调度,根据node的算力(cpu,内存,带宽,已经运行的pod等)--》到底是如何给node评分的,最底层的机制
- 2.node selector:定向调度
- 3.nodeaffinity --》尽量把不同的pod放到一台node上
- 4.podaffinity --》尽量把相同的pod放到一起
- 5.taints和tolerations 污点和容忍
taints和toleration是怎么样查看的?如何知道哪些机器上有污点,哪些pod可以容忍?
[root@scmaster ~]# kubectl describe node scmaster|grep -i taint
Taints: node-role.kubernetes.io/master:NoSchedule
[root@scmaster ~]#[root@scmaster ~]# kubectl describe pod etcd-scmaster -n kube-system |grep -i tolerations
Tolerations: :NoExecute op=Exists
[root@scmaster ~]#
6. pod和pod之间的通信过程?
同一个Pod中的容器通信
同一个pod中的容器是共享网络ip地址和端口号的,通信显然没问题
集群内Pod之间的通信
Pod会有独立的IP地址,这个IP地址是被Pod中所有的Container共享的,那多个Pod之间的通信能通过这个IP地址吗?我们可以将此类pod间的通信分为两个维度:
集群中同一台机器中的Pod
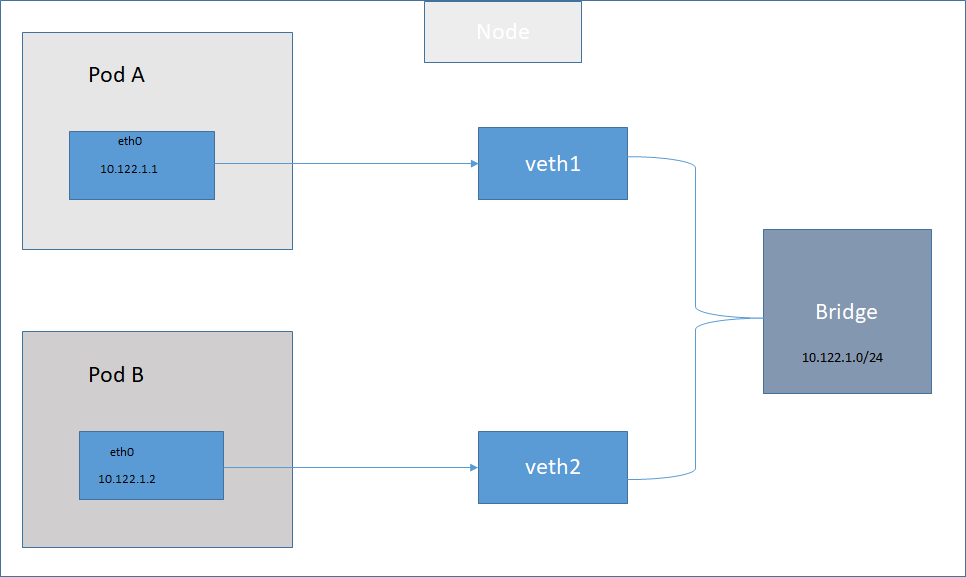
pause 容器启动之前,会为容器创建虚拟一对 ethernet 接口,一个保留在宿主机 vethxxx(插在网桥上),一个保留在容器网络命名空间内,并重命名为eth0。两个虚拟接口的两端,从一端进入,另一端出来。任何 Pod 连接到该网桥的 Pod 都可以收发数据。
集群中不同机器之间的通信是通过网络插件实现的
Kubernetes跨主机容器之间的通信组件,目前主流的是flannel和calico
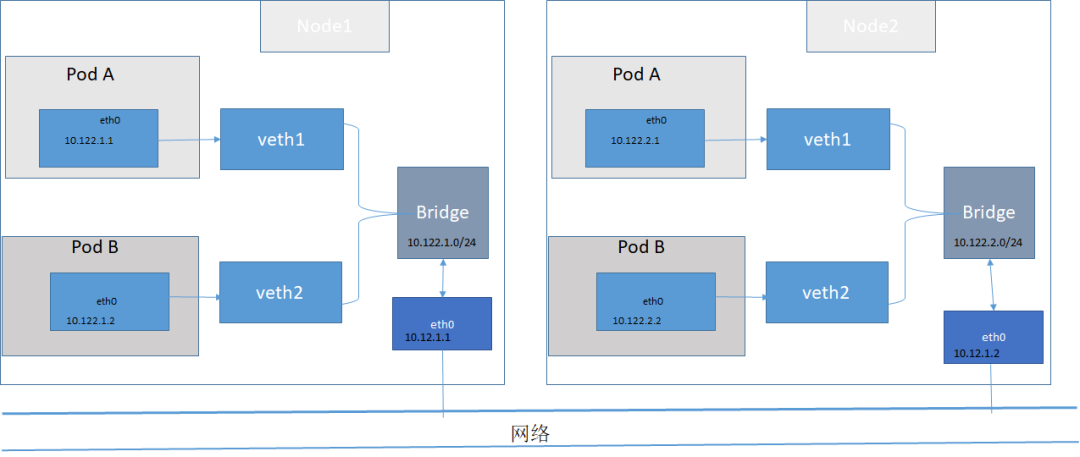
其中跨整个集群的 Pod ip 是唯一的,当报文从一个节点转发到另外一个节点时,报文首先通过 veth,然后通过网桥,转发到物理适配器网卡,最后转发到其它节点的虚拟网桥,进而到达 veth 目标容器。
flannel和calico参考:https://www.cnblogs.com/xiaoyuxixi/p/13304602.html
7. 外面用户访问pod数据流程?

8. 常用命令
- kubectl get 资源对象
- kubectl describe 查询详细信息
- kubectl logs 查看日志
- kubectl exec -it 容器名 -- bash 进入容器
- kubectl apply -f *.yml 执行yml文件
- kubectl delete -f *.yml 删除前面执行的yml文件创建的内容
9. 容器的类型有哪些?
init初始化容器
初始化(init)容器像常规应用容器一样,只有一点不同:初始化(init)容器必须在应用容器启动前运行完成。 Init 容器的运行顺序:一个初始化(init)容器必须在下一个初始化(init)容器开始前运行完成。
为一个pod里后面启动的容器准备一些条件
容器启动有先后顺序,同时一个pod里的容器也是可以有依赖的
与普通容器不同之处:Init 容器不支持 lifecycle、livenessProbe、readinessProbe 和 startupProbe, 因为它们必须在 Pod 就绪之前运行完成
pause容器
Pause容器 全称infrastucture container(又叫infra)基础容器,作为init pod存在,其他pod都会从pause 容器中fork出来
- 1、每个Pod里运行着一个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷
- 2、因此他们之间通信和数据交换更为高效,在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个Pod中。
- 3、同一个Pod里的容器之间仅需通过localhost就能互相通信。
在创建一个pod的时候,最先创建的容器
pause容器--》把pod的公用的命名空间都创建好--》init容器---》app容器


sidecar容器
Sidecar模式是一种将应用功能从应用本身剥离出来作为单独进程的方式。该模式允许我们向应用无侵入添加多种功能,避免了为满足第三方组件需求而向应用添加额外的配置代码。
就像边车加装在摩托车上一样,在软件架构中,sidecar附加到主应用,或者叫父应用上,以扩展/增强功能特性,同时Sidecar与主应用是松耦合的。
当另一个容器被添加到一个pod中,为主容器提供额外的功能,但不需要改变主容器,它被称为一个sidecar容器
一个或多个共享同一个pod的容器至少要共享两样东西
- 一个文件系统-这意味着你可以使用共享卷在同一个pod中的两个或多个容器之间共享文件。共享卷是简单的共享文件夹。
- 网络-同一Pod中的容器之间的通信可以通过回环接口 - localhost进行。
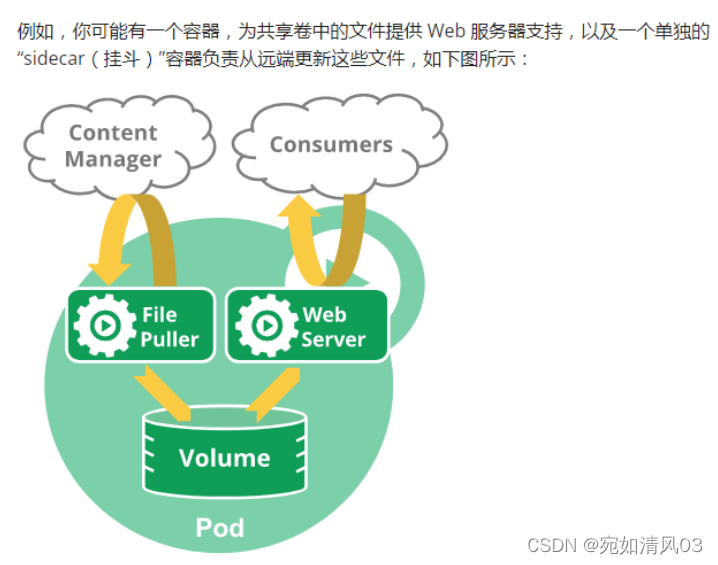
Sidecar模式的好处
- 通过将公用基础设施相关功能抽象到不同的层来降低微服务的代码复杂性
- 由于我们不需要在每个微服务中编写配置代码,因此减少了微服务架构中的代码重复
- P应用和底层平台之间实现了松耦合
工作模式:
app容器
应用程序容器 跑业务代码的容器
10. 3种探针
探针:使用探针去试探pod是否能正常提供服务,在pod启动的不同阶段使用不同的方法去监控,判断pod是否正常


案例
apiVersion: v1
kind: Pod
metadata:labels:test: livenessname: liveness-exec
spec:containers:- name: livenessimage: k8s.gcr.io/busyboxargs:- /bin/sh- -c- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600livenessProbe:exec:command:- cat- /tmp/healthyinitialDelaySeconds: 5periodSeconds: 5
当探针发现pod没有运行的时候,kubelet会根据pod的重启策略,重启pod

11. pod的升级?
参考:https://zhuanlan.zhihu.com/p/342229988
使用Deployment来控制Pod的主要好处之一是能够执行滚动更新。滚动更新允许你逐步更新Pod的配置,并且Deployment提供了许多选项来控制滚动更新的过程。
控制滚动更新最重要的选项是更新策略。在Deployment的YAML定义文件中,由spec.strategy.type字段指定Pod的滚动更新策略,它有两个可选值:
- RollingUpdate (默认值):逐步创建新的Pod,同时逐步终止旧Pod,用新Pod替换旧Pod。
- Recreate:在创建新Pod前,所有旧Pod必须全部终止。
大多数情况下,RollingUpdate是Deployment的首选更新策略。如果你的Pod需要作为单例运行,并且不允许在任何时间存在多副本,这种时候Recreate更新策略会很有用。
使用RollingUpdate策略时,还有两个选项可以让你微调更新过程:
- maxSurge:在更新期间,允许创建超过期望状态定义的
Pod数的最大值。 - maxUnavailable:在更新期间,容忍不可访问的Pod数的最大值
maxSurge和maxUnavailable选项都可以使用整数(比如:2)或者百分比(比如:50%)进行配置,而且这两项不能同时为零。当指定为整数时,表示允许超期创建或者不可访问的Pod数。当指定为百分比时,将使用期望状态里定义的Pod数作为基数。比如:如果对maxSurge和maxUnavailable都使用默认值25%,并且将更新应用于具有8个容器的Deployment,那么意味着maxSurge为2个容器,maxUnavailable也将为2个容器。这意味着在更新过程中,将满足以下条件:
- 最多有10个
Pod(8个期望状态里指定的Pod和2个maxSurge允许超期创建的Pod)在更新过程中处于Ready状态。 - 最少有6个
Pod(8个期望状态里指定的Pod和2个maxUnavailable允许不可访问的Pod)将始终处于Ready状态。
值得注意的一点是,在考虑Deployment应在更新期间运行的Pod数量时,使用的是在Deployment的更新版本中指定的副本数,而不是现有Deployment版本的期望状态中指定的副本数。
可以用另外一种方式理解这两个选项:maxSurge是一次将创建的新Pod的最大数量,maxUnavailable是一次将被删除的旧Pod的最大数量。
让我们具体看一下使用以下更新策略将具有3个副本的Deployment从"v1"更新为" v2"的过程:
replicas: 3
strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 0这个更新策略是,我们想一次新建一个Pod,并且应该始终保持Deployment中的Pod有三个是Ready状态。下面的动图说明了滚动更新的每一步都发生了什么。如果Deployment看到Pod已经完全部署好了将会把Pod标记为Ready,创建中的Pod标记为NotReady,正在被删除的Pod标记为Terminating。
12. HPA、VPA、CA?
参考:https://blog.csdn.net/weixin_41989934/article/details/118645084
HPA 水平Pod自动扩缩器
HAP,全称 Horizontal Pod Autoscaler, 可以基于 CPU 利用率自动扩缩 ReplicationController、Deployment 和 ReplicaSet 中的 Pod 数量。 除了 CPU 利用率,也可以基于其他应程序提供的自定义度量指标来执行自动扩缩。 Pod 自动扩缩不适用于无法扩缩的对象,比如 DaemonSet。
Pod 水平自动扩缩特性由 Kubernetes API 资源和控制器实现。资源决定了控制器的行为。 控制器会周期性的调整副本控制器或 Deployment 中的副本数量,以使得 Pod 的平均 CPU 利用率与用户所设定的目标值匹配。
- HPA 定期检查内存和 CPU 等指标,自动调整 Deployment 中的副本数,比如流量变化:
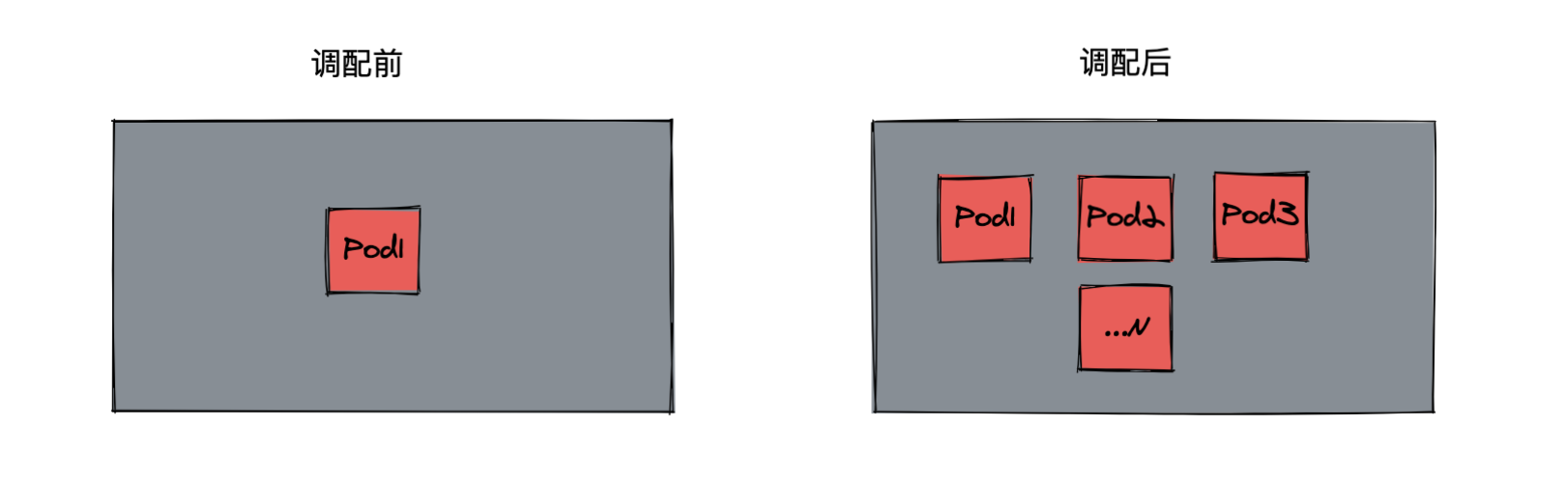
HPA工作原理
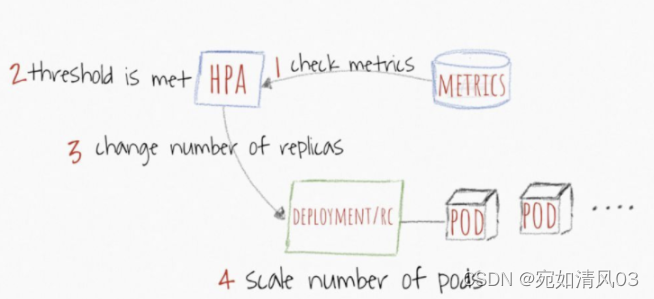
k8s里的HPA功能比传统的集群有什么优势?
1.启动速度
2.扩展性--》自动扩缩
3.资源的消耗方面--》节省服务器
速度
价格--》成本
稳定性
可靠性
metrics server
HPA的指标数据是通过metrics服务来获得,必须要提前安装好
Metrics Server 是 Kubernetes 内置自动缩放管道的可扩展、高效的容器资源指标来源。
Metrics Server 从 Kubelets 收集资源指标,并通过Metrics API在 Kubernetes apiserver 中公开它们, 以供Horizontal Pod Autoscaler和Vertical Pod Autoscaler 使用,比如CPU、文件描述符、内存、请求延时等指标,metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等。还可以通过 访问指标 API kubectl top,从而更轻松地调试自动缩放管道
安装参考:https://www.cnblogs.com/scajy/p/15577926.html
示例:
首先我们部署一个nginx,副本数为2,请求cpu资源为200m。同时为了便宜测试,使用NodePort暴露服务,命名空间设置为:hpa
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: nginxname: nginxnamespace: hpa
spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- image: nginxname: nginxresources:requests:cpu: 200m ##memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:name: nginxnamespace: hpa
spec:type: NodePortports:- port: 80targetPort: 80selector:app: nginx
查看部署结果
# kubectl get po -n hpaNAME READY STATUS RESTARTS AGEnginx-5c87768612-48b4v 1/1 Running 0 8m38snginx-5c87768612-kfpkq 1/1 Running 0 8m38s
创建HPA
- 这里创建一个HPA,用于控制我们上一步骤中创建的 Deployment,使 Pod 的副本数量维持在 1 到 10 之间。
- HPA 将通过增加或者减少 Pod 副本的数量(通过 Deployment)以保持所有 Pod 的平均 CPU 利用率在 50% 以内。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: nginxnamespace: hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: nginxminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50查看部署结果
# kubectl get hpa -n hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGEnginx Deployment/nginx 0%/50% 1 10 2 50s
压测观察Pod数和HPA变化
# 执行压测命令
# ab -c 1000 -n 100000000 http://127.0.0.1:30792/This is ApacheBench, Version 2.3 <$Revision: 1843412 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 127.0.0.1 (be patient)
# 观察变化
# kubectl get hpa -n hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGEnginx Deployment/nginx 303%/50% 1 10 7 12m# kubectl get po -n hpaNAME READY STATUS RESTARTS AGEpod/nginx-5c87768612-6b4sl 1/1 Running 0 85spod/nginx-5c87768612-99mjb 1/1 Running 0 69spod/nginx-5c87768612-cls7r 1/1 Running 0 85spod/nginx-5c87768612-hhdr7 1/1 Running 0 69spod/nginx-5c87768612-jj744 1/1 Running 0 85spod/nginx-5c87768612-kfpkq 1/1 Running 0 27mpod/nginx-5c87768612-xb94x 1/1 Running 0 69s
可以看出,hpa TARGETS达到了303%,需要扩容。pod数自动扩展到了7个。等待压测结束;
# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 20%/50% 1 10 7 16m---N分钟后---# kubectl get hpa -n hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGEnginx Deployment/nginx 0%/50% 1 10 7 18m---再过N分钟后---# kubectl get po -n hpaNAME READY STATUS RESTARTS AGEnginx-5c87768612-jj744 1/1 Running 0 11m
hpa示例总结
CPU 利用率已经降到 0,所以 HPA 将自动缩减副本数量至 1。
为什么会将副本数降为1,而不是我们部署时指定的replicas: 2呢?
因为在创建HPA时,指定了副本数范围,这里是minReplicas: 1,maxReplicas: 10。所以HPA在缩减副本数时减到了1。
VPA 垂直Pod自动伸缩
VPA 全称 Vertical Pod Autoscaler,即垂直 Pod 自动扩缩容,它根据容器资源使用率自动设置 CPU 和 内存 的requests,从而允许在节点上进行适当的调度,以便为每个 Pod 提供适当的资源。
它既可以缩小过度请求资源的容器,也可以根据其使用情况随时提升资源不足的容量。
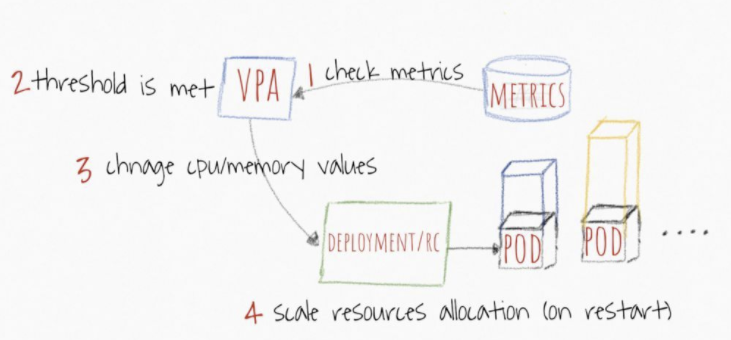
- 有些时候无法通过增加 Pod 数来扩容,比如数据库。这时候可以通过 VPA 增加 Pod 的大小,比如调整 Pod 的 CPU 和内存:
CA 集群自动缩放器
集群自动伸缩器(CA)基于待处理的豆荚扩展集群节点。它会定期检查是否有任何待处理的豆荚,如果需要更多的资源,并且扩展的集群仍然在用户提供的约束范围内,则会增加集群的大小。CA与云供应商接口,请求更多节点或释放空闲节点。它与GCP、AWS和Azure兼容。版本1.0(GA)与Kubernetes 1.8一起发布。
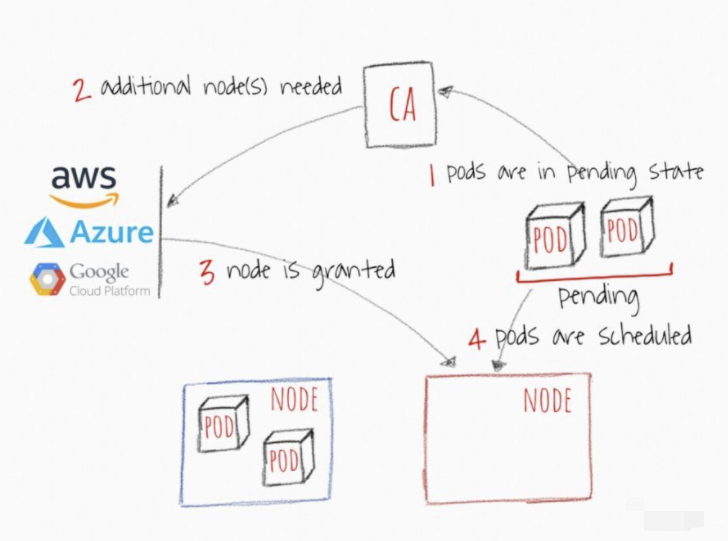
- 当集群资源不足时,CA 会自动配置新的计算资源并添加到集群中:
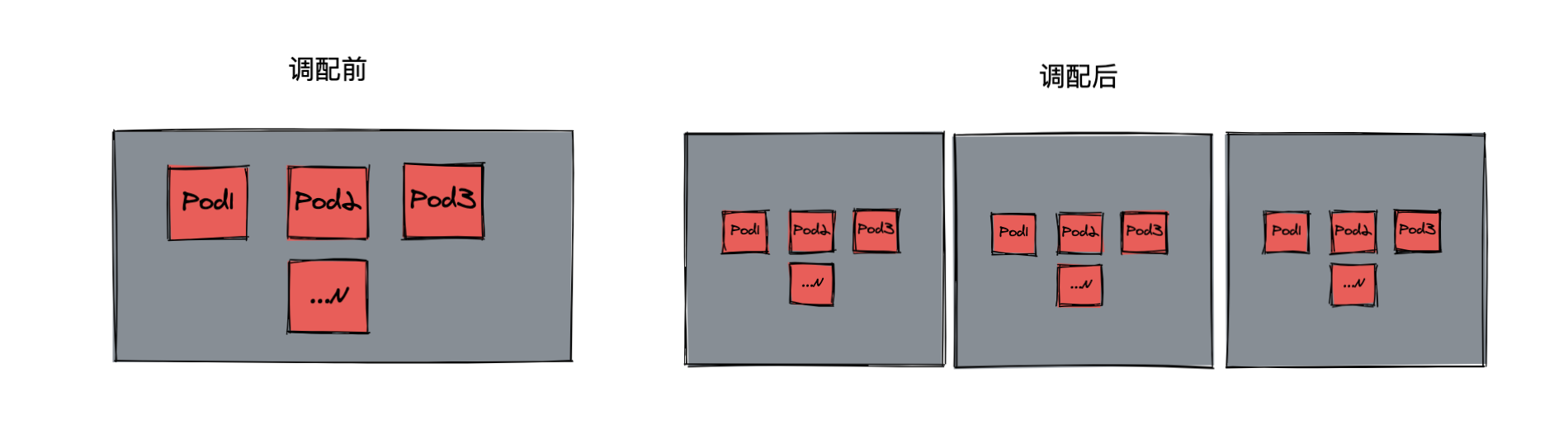
13. 污点和容忍?
Taint需要和Toleration配合使用,让Pod避开那些不合适的Node。在 Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污 点,否则无法在这些Node上运行。
Toleration是Pod的属性,让Pod能够 (注意,只是能够,而非必须)运行在标注了Taint的Node上。
污点: 在node节点上打污点
pod在调度的时候,会选择没有污点的节点去运行
调度器在分配pod到那个节点上的时候,会选择没有污点的节点,去启动pod
容忍:
是pod有污点的节点服务器,任然可以调度到这个节点上去运行
调度器在调度的过程中会查看节点服务器是否有污点,然后看pod的策略里是否能容忍这个污点,如果能容忍就调度到这个节点服务器上,如果不能容忍就不调度过去。
给node1打上污点

申明可以容忍pod对污点的不调度策略
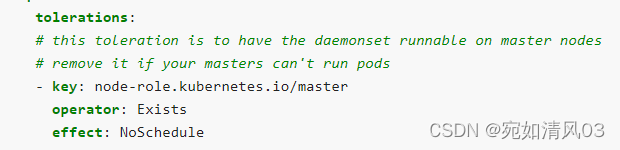

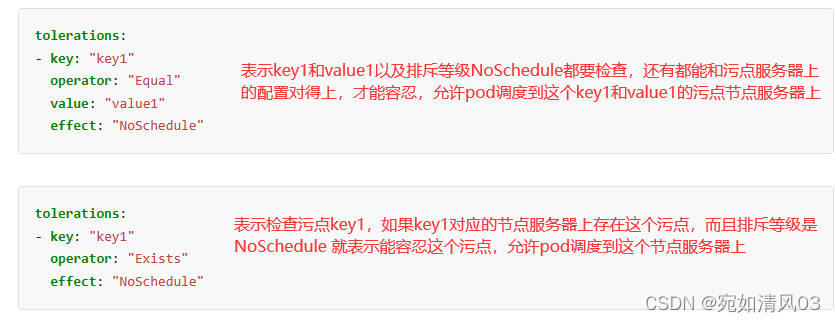
先检查key是否匹配,匹配是看operator是exists或者equal 表示匹配,effect可以理解为允许在有污点的节点上启动这个pod,如果key不匹配,就不允许调度到这个污点节点
equal 操作,需要写key和value,exists不需要接value

为什么master节点上没有业务pod?
答案:因为master节点上有污点,默认业务pod都不调度到master节点
能容忍任何的污点和排斥等级

能接受任何污点并且排斥等级是NoExecute的节点服务器

内置的污点名字

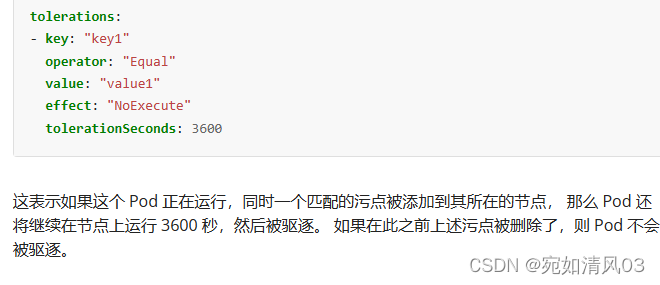
容忍时间
tolerationSeconds: 3600

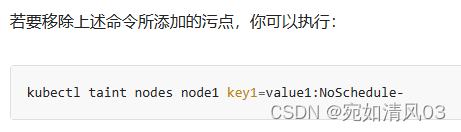
删除污点:在定义污点的语句后加-
14. 有状态的应用和无状态的应用?
有状态应用
可以说是 需要数据存储功能的服务、或者指多线程类型的服务,队列等。(mysql数据库、kafka、zookeeper等)。每个实例都需要有自己独立的持久化存储
特点:
- 缩容的时候是顺序进行的,不是随机的
- pod的编号是有顺序的
- 每个实例都需要有自己独立的持久化存储
案例:
nginx: 无状态 : 启动的时候,不必须按照顺序,并且pod是随机分配id
web服务: 访问任意一个web服务器,得到结果都是一样的,而且网页数据也是从同一个地方获取
mysql: 有状态 : 启动的时候,必须按照顺序,并且pod是有固定的编号,不允许随机分配
master ,slave
写数据--》master上写
无状态的应用
(1)、是指该服务运行的实例不会在本地存储需要持久化的数据,并且多个实例对于同一个请求响应的结果是完全一致的。
(2)、多个实例可以共享相同的持久化数据。例如:nginx实例,tomcat实例等
(3)、相关的k8s资源有:ReplicaSet、ReplicationController、Deployment等,由于是无状态服务,所以这些控制器创建的pod序号都是随机值。并且在缩容的时候并不会明确缩容某一个pod,而是随机的,因为所有实例得到的返回值都是一样,所以缩容任何一个pod都可以。
15. ingress相关
参考:https://blog.csdn.net/ZhouXin1111112/article/details/132669303?spm=1001.2014.3001.5501
16. RBAC相关
参考:https://blog.csdn.net/ZhouXin1111112/article/details/132670500?spm=1001.2014.3001.5502
17. CI/CD 持续集成、持续交付 jenkins
参考:https://blog.csdn.net/ZhouXin1111112/article/details/132577550?spm=1001.2014.3001.5502
18. pod有多少种状态
Kubernetes 中的 Pod 有以下几种状态:
- Pending(挂起):Pod 已经被 Kubernetes API 接受,但它的容器镜像还没有被拉取,或者 Pod 所需的节点资源(CPU、内存等)还没有满足。在这个状态中,Pod 是不可调度的。
- Running(运行):Pod 已经调度到了节点上并且所有容器都已经创建,至少有一个容器仍在运行中或者在启动过程中。
- Succeeded(成功):Pod 中的所有容器都已经正常终止,并且不会再重启。
- Failed(失败):Pod 中至少有一个容器已经以非零状态退出。
- Unknown(未知):无法获取 Pod 的状态。这种状态通常是由于与 Pod 相关的 API 调用失败或者 Pod 控制器处于错误状态导致的。
除了上述状态之外,Pod还有一些特殊的条件状态,它们记录了 Pod 的一些细节信息,例如 Pod 是否处于调度中、容器镜像是否拉取成功等。这些状态和条件状态可以通过 kubectl describe pod 命令获取,这些条件状态:
- PodScheduled:表示 Pod 是否已经被调度到了节点上。
- ContainersReady:表示 Pod 中的所有容器是否已经准备就绪。
- Initialized:表示 Pod 中的所有容器是否已经初始化。
- Ready:表示 Pod 是否已经准备就绪,即所有容器都已经启动并且可以接收流量。
- CrashLoopBackOff: 容器退出,kubelet正在将它重启
- InvalidImageName: 无法解析镜像名称
- ImageInspectError: 无法校验镜像
- ErrImageNeverPull: 策略禁止拉取镜像
- ImagePullBackOff: 正在重试拉取
- RegistryUnavailable: 连接不到镜像中心
- ErrImagePull:通用的拉取镜像出错
- CreateContainerConfigError: 不能创建kubelet使用的容器配置
- CreateContainerError: 创建容器失败
- m.internalLifecycle.PreStartContainer 执行hook报错
- RunContainerError: 启动容器失败
- PostStartHookError: 执行hook报错
- ContainersNotInitialized: 容器没有初始化完毕
- ContainersNotReady: 容器没有准备完毕
- ContainerCreating:容器创建中
- PodInitializing:pod 初始化中
- DockerDaemonNotReady:docker还没有完全启动
- NetworkPluginNotReady: 网络插件还没有完全启动
- Evicte: pod被驱赶
19. pod的重启策略?
Pod 的 spec 中包含一个 restartPolicy 字段,其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。


![[SUCTF2019]SignIn 题解](https://img-blog.csdnimg.cn/1496bedd7dcb4a2ea7beba2798b40ffc.png)