一: 数据分析高级语法:序列(Series)
# -*- coding:utf-8 -*-from pandas import Seriesprint('-------------------------------------序列Series定义与取值-------------------------------------------') print("""Series序列可以省略,此时索引号默认从0开始;索引可以使指定的字母,或者字符串Series序列也可以任务是一维列表""") X = Series(["a", 2, "螃蟹"], index=[1, 2, 3]) print("Series数据类型: ", type(X)) print() print(X) print() A = Series([1, 2, 3, 22, 140, 23, 123, 2132131, 232222222222]) print(A) print() print("序列A的第二个值: ", A[1]) print() B = Series([11, 23, 33, 44, 55, 56], index=['A', 'B', 'C', 'D', 'E', 'F']) print() print("序列B: ") print(B) print() print(B.__dict__.keys())print('访问序列的A的值:', B['A']) print('访问序列的B的值:', B['B'])print('-------------------------------------------------------------------------------------------------')print()AA = Series([14, 24, 53, 33], index=['First', 'Second', 'Three', 'Four']) print("序列AA") print(AA) print() print("序列AA['Second']的取值: ", AA['Second']) print("序列AA[1]的取值: ", AA[1]) print() try:print(AA['Six']) except Exception as err:print("series is not exits,stack: ", err)
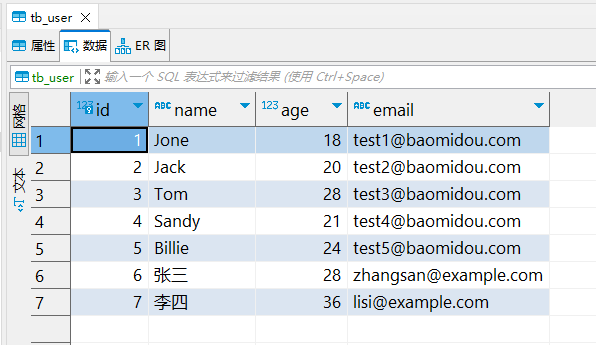
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\dataanalysis\DataAnalysisExecutorSerias.py
-------------------------------------序列Series定义与取值-------------------------------------------Series序列可以省略,此时索引号默认从0开始;
索引可以使指定的字母,或者字符串
Series序列也可以任务是一维列表
Series数据类型: <class 'pandas.core.series.Series'>1 a
2 2
3 螃蟹
dtype: object0 1
1 2
2 3
3 22
4 140
5 23
6 123
7 2132131
8 232222222222
dtype: int64序列A的第二个值: 2
序列B:
A 11
B 23
C 33
D 44
E 55
F 56
dtype: int64dict_keys(['_is_copy', '_mgr', '_item_cache', '_attrs', '_flags', '_name'])
访问序列的A的值: 11
访问序列的B的值: 23
-------------------------------------------------------------------------------------------------序列AA
First 14
Second 24
Three 53
Four 33
dtype: int64序列AA['Second']的取值: 24
序列AA[1]的取值: 24series is not exits,stack: 'Six'
Process finished with exit code 0
二: 数据分析高级语法: 数据框(DataFrame)
后续补充完整:..................