一. SQL(Structured Query Language):
结构化查询语言。SQL语法不区分关键字的大小写,多条SQL语句必须以;分隔。
二. SQL的作用:
SQL可以访问和处理数据库,包括数据的增删改查(插入,删除,更新,查询)、数据库的创建、表的创建存储过程、以及视图的创建、表的设置、权限等。
三. 常用的SQL语句和相关语法:
1. 增删改查:
(增insert into...values...,删delete from...where...,改update...set...where...,查select...from...where...)
(1)select语句:
从数据库中选取数据,结果存储在一个结果表中。如select * from table_name;select name,id from costoms;
扩充:select distinct语句,其中distinct关键字返回唯一不同的值。如select distinct c1,c2 from t;
(2)where子句:
提取满足指定条件的记录。如select xxx form t where xxxx=xx ...;
注:SQL使用单引号来环绕文本值(大部分数据库也接受双引号)。
此外,where子句常用的运算符有:=, <>/!=(不等于), <, >, <=, >=, between ...and ..., like(搜索某种模式), in(指定针对某个列的多个可能值)。
(3)and/or:
基于一个以上的条件进行过滤。
(4)order by:
排序(默认为升序),降序使用dese关键字。
(5)insert into:
向表中插入新记录。如insert into web(name,url,country) values("百度",'https://www.baidu.com','CN');
(6)update语句:
更新表中的记录。如update web set country=‘USA’ where name=‘xxx’;
(7)delete语句:
删除表中的记录。如delete from web where name=‘Facebook’ and country=‘USA’;
扩充:提到delete语句,不得不说一下其他删除语句。
① truncate语句:truncate table 表名,用于清空表中的所有数据,但不会删除表结构。
② delete语句:delete from 表名 where 条件,用于删除部分/所有数据,但不会删除表结构。
③ drop语句:drop table 表名,会将整张表的行数据和表结构一起删除掉。
三者的区别在于:
① 数据恢复方面:delete 可以恢复删除的数据,而 truncate 和 drop 不能恢复删除的数据。
② 执行速度方面:drop > truncate > delete。
③ 删除数据方面:drop 是删除整张表,包含行数据和字段、索引等数据,而 truncate 和 drop 只删除了行数据。
④ 添加条件方面:delete 可以使用 where 表达式添加查询条件,而 truncate 和 drop 不能添加 where 查询条件。
⑤ 重置自增列方面:在 InnoDB 引擎中,truncate 可以重置自增列,而 delete 不能重置自增列。
truncate和drop是DDL 语句,也就是 Data Definition Language 数据定义语言,它是用来维护存储数据的结构指令,所以这点也是和 delete 命令是不同的,delete 语句属于 DML,Data Manipulation Language 数据操纵语言,用来对数据进行操作的。其中,DDL不放到rollback segment中,不能回滚;而DML会放到rollback segment中,事务提交才生效。
(8)group by语句:
结合聚合函数,根据一个或多个列对结果集进行分组。
(9)having子句:
跟在group by后面,用于筛选分组后的各组数据。语句通常为select ... group by ... having...;
(10)exists运算符:
判断查询子句是否有记录,返回TRUE/FALSE。如select web.name, web.url from web where exists(select count form access_log where ...);
2. 高级语法:
(1)select top/limit/rownum子句:
top规定返回的记录数,并非所有数据库系统都支持,limit是MySQL支持,rownum是Oracle支持。
(2)like操作符:
用于在where子句中搜索列中的指定模式。如select * form web where name like ‘C%’;
(3)SQL通配符:
① %:代表0/多个字符。
② _:代表1个字符。
③ [charlist]:字符列中的任意单一字符。
④ [^charlist]/[!charlist]:不在字符列中的任意单一字符。
(4)in操作符:
允许在where子句中规定多个值。如select * from web where name in (‘Google’,‘百度’);
(5)between操作符:
选取介于两个值之间的数据范围的值。
(6)as:
别名,为表/列指定别名,也可以直接省略,用空格代替。如select custom_name name,new_date date from web w where ...;
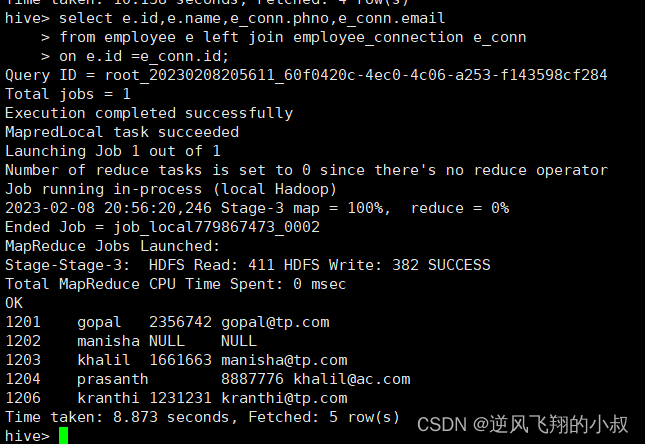
(7)join连接:
把来自2个/多个表的行结合起来,分为left join,right join,inner join,outer join。
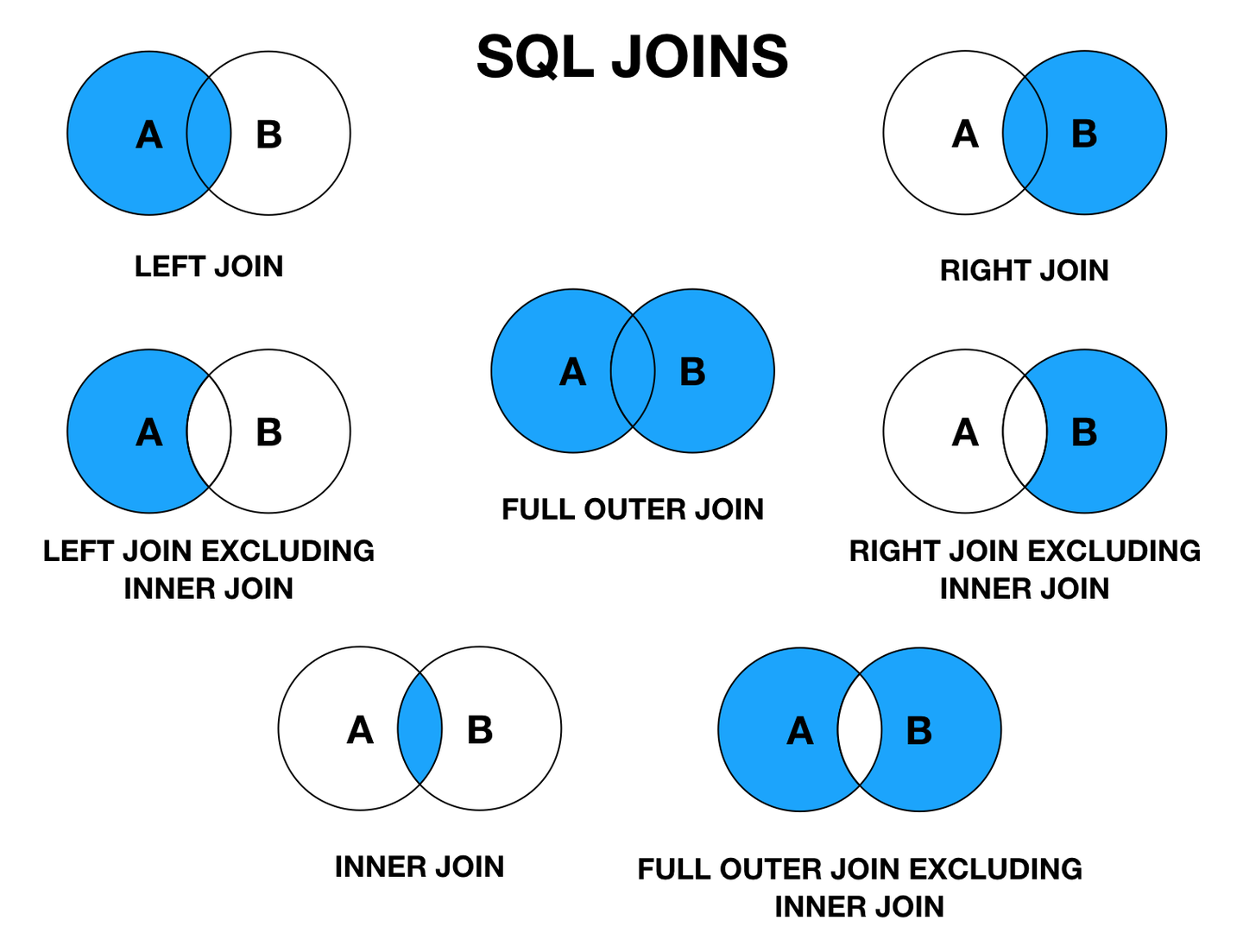
如上图所示,inner join内连接需要两个表都存在满足条件才返回;left(outer)join返回左表中的所有行,right (outer)join同理;full (outer)join只要其中一个表存在满足条件的记录即可。self join将一个表连接到自身;cross join交叉连接。
注:对于相同属性名可以使用using代替on,如xx1 join xx2 using(cust_id);等价于xx1 join xx2 on xx1.cust_id = xx2.cust_id;
(8) union操作符:
合并2个/多个select语句的结果,union内部的每个select语句必须拥有相同数量的列,且列拥有相似的数据结构,union结果集中的列名同union中第一个select语句中的列名。如select country from web union select country from apps order by country;
(9)select into语句:
从一个表复制数据,然后将数据插入到另一个新表中。如select * into web from websites;
(10)insert into...select...语句:
将数据插入到一个已存在的表中。如insert into web(name,country) select app_name,country from apps;
(11)create语句:
create table/database 表名/数据库名;
(12)SQL约束:
① NOT NULL ② UNIQUE ③ PRIMARY KEY ④ FOREIGN KEY ⑤ CHECK ⑥ DEFULT
注意:每个表可以有多个unique约束,但是只能有一个主键约束,并且主键列中不能包含NULL值。外键指向另一个表的unique key(唯一约束的键)。check约束用于限制列中值的范围。default约束向列中插入默认值。
(13)index语句:
创建索引,create(unique) index 索引名 on 表名(列名);删除索引,drop index 索引名 on 表名;
创建索引的作用:索引是用于快速查询和检索数据的数据结构,创建唯一性索引可以保证数据库中每一行数据的唯一性;但是会占用物理文件存储空间,并且增删改查时需要索引动态修改,会降低SQL执行效率。
(14)alter语句:
修改。
① 添加新列于指定位置:Alter table XXX[表名称] ADD 列名 列属性【varchar(8)】after 列名
② 唯一索引:Alter table XXX[表名称] ADD UNIQUE INDEX uniq_索引名称(列名)
③ 全文索引:Alter table XXX[表名称] ADD FULLTEXT INDEX full_索引名称(列名)
④ 普通索引 :Alter table XXX[表名称] ADD INDEX 索引名称(列名)
⑤ 删除列:Alter table XXX[表名称] drop column 列名
⑥ 删除键/索引:Alter table XXX[表名称] drop key/index
⑦ 添加表注释:Alter table XXX[表名称] comment '表注释';
⑧ 添加字段注释:Alter table XXX[表名称] modify column column_name varchar(10) comment 'xx';
(15)auto increment字段:
设置表字段值自动增加(AUTO_INCREMENT)格式: create table tablename(字段名 数据类型 auto_increment ,... ... );
(16)view视图:
基于SQL语句的结果集的可视化的表。view是虚拟表,本身不含数据,不能对其进行索引操作。
(17)trigger触发器:
与表操作有关的数据库对象,表的操作事件出发表上的触发器的执行。
语法:create trigger trigger_name trigger_time trigger_event on table_name for each row(行级监听,MySQL的固定写法) begin trigger_statements end;
触发时机是before/after;触发器的监听事件是insert/update/delete。
① 查看触发器:show trigger;② 删除触发器:drop trigger if exists trigger_name;
四. SQL函数:
1. date数据类型:
① date格式:YYYY-MM-DD。
② datetime格式:日期和date格式相同,时间格式为HH:MM:SS。
③ timestamp格式:和datetime格式相同。
④ year格式:YYYY或者YY。
2. aggregate函数:
① AVG()② COUNT()③ FIRST()④ LAST()⑤ MAX()⑥ MIN()⑦ SUM()
3. scalar函数:
① UCASE()将某个字段转换为大写。
② LCASE()将某个字段转换为小写。
③ MID()从文本字段提取字符。
④ LEN()返回长度。
⑤ ROUND()指定小数位数的四舍五入。
⑥ NOW()⑦ FORMATE()
五. 数据库:
1. 基本概念:
码:属性列。
元组:行。
候选码:能唯一标识一个元组,而其子集不可。候选码可能有多个。
主码:唯一,也叫主键,不可为空。
外码:也叫外键,可以为空。
主属性:候选码中的属性;非主属性:不包含在任何候选码中的属性。
2. ER图(实体联系图):
实体,属性,联系(1对1,1对多,多对多)。
3. 数据库范式:
1NF:第一范式,属性不可分,所有关系型数据库的的最基本要求。
2NF:第二范式,1NF基础上,消除了非主属性对码的部分函数依赖。
3NF:第三范式,2NF基础上,消除了非主属性对码的传递函数依赖。
4. 存储过程:
SQL语句的集合,中间加了逻辑控制语句。
优点:比单纯SQL语句执行快,由于存储过程是预编译过的。
缺点:难以调试和扩展,没有移植性,还会小号数据库资源。
5. 数据库设计的步骤:
① 需求分析:分析用户的需求,包括数据、功能以及性能需求。
② 概念结构设计:E-R模型。
③ 逻辑结构设计:将E-R图转换为表,实现E-R模型到关系模型的转变。
④ 物理结构设计:数据库所需的存储结构和存取路径。
⑤ 数据库实施:编程,测试和试运行。
⑥ 数据库的运行和维护:系统的运行与数据库的日常维护。