注解处理器介绍
什么是APT?
在JDK6的时候引入了JSR269的标准,即APT(Annotation Processing Tool),用于在编译时处理源代码中的注解,从而生成额外的代码、配置文件或其他资源。与传统的运行时反射相比,APT在编译时进行处理,可以提高性能并在编译阶段捕获一些问题,减少运行时错误。
APT的工作原理
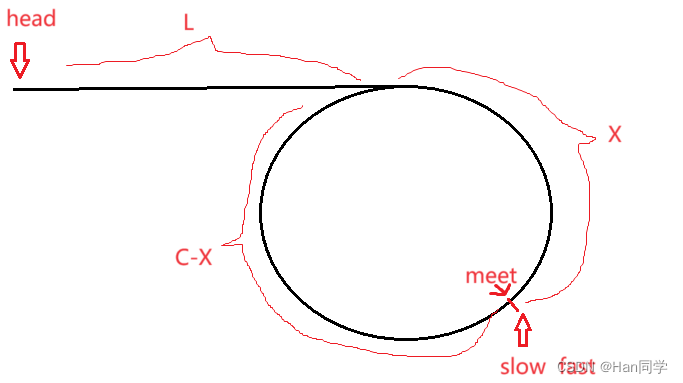
Java 编译器的工作流程
在介绍注解处理器工作原理之前,我们先来了解一下 Java 编译器的工作流程。

如上图所示,Java 源代码的编译过程可分为三个步骤:
- 将源文件解析为抽象语法树;
- 调用已注册的注解处理器;
- 生成字节码。
如果在第 2 步调用注解处理器过程中生成了新的源文件,那么编译器将重复第 1、2 步,解析并且处理新生成的源文件。每次重复我们称之为一轮(Round)。也就是说,第一轮解析、处理的是输入至编译器中的已有源文件。如果注解处理器生成了新的源文件,则开始第二轮、第三轮,解析并且处理这些新生成的源文件。当注解处理器不再生成新的源文件,编译进入最后一轮,并最终进入生成字节码的第 3 步。
APT的工作流程包括以下阶段:
- 扫描阶段:编译器会扫描源代码,找出带有特定注解的元素。
- 编译器检查源码中所有的注解元素,如果没有则整个流程直接结束,否则继续
- 编译器检查开发者注册了哪些
AnnotationProcessor,如果没有则整个流程直接结束,否则继续 - 编译器拿着所有收集到的注解元素去问
Processor们进行认领 - 当所有注解类型被认领完毕,此阶段结束,进入下一阶段
- 若仍有注解类型没有被认领,但已经没有多余的处理器了,同样此阶段结束,进入下一阶段
- 处理阶段:注解处理器将被触发,对扫描到的元素进行处理,并生成新的源代码或资源文件。
- 编译器将从源码中收集到的注解元素作为输入开启一轮处理
- 所有开发者注册的注解处理器将排好队串行处理编译器传入的注解元素,在这里需要注意的是注解处理器之间并没有明确的排序规则,可以认为是乱序的,而且每一次可能不一样,不可依赖
- 若某个注解处理器在处理过程中生产出了新的源码文件,那么此轮处理会立即结束。新生成的源码文件及目前还没处理完的源码元素加在一起作为下一轮的输入(若新生成的源码中没有注解元素,其实是没有意义的)
- 新一轮处理中,所有的注解处理器依然会被触发,所以需要开发者做好识别,不要产生重复生成新文件的BUG
- 直到所有注解处理器串行处理后不再产生新文件,处理阶段结束
- 生成阶段:生成的代码或资源会被编译器包含在编译结果中,最终生成可执行的应用程序。
APT的用途和优势
APT可以应用于许多场景,包括:
- 自动生成代码:通过自定义注解处理器,可以根据注解自动生成代码,减少重复工作。比如
lombok、MapStruct - 静态检查和约束:利用APT进行静态检查,强制执行编码规范,提高代码质量。
- 生成配置文件:生成配置文件或资源,提供更灵活的配置方式。
优势包括:
- 提高性能:在编译时处理,减少了运行时开销。
- 增强编译时类型检查:通过生成额外代码,可以在编译阶段捕获一些潜在问题。
- 自动化任务:可以根据需要自动执行一些任务,如代码生成、配置文件生成等。
如何使用APT
要使用APT,需要在项目中配置注解处理器,通常是通过Maven或Gradle来实现。在编译时,注解处理器会自动触发,对带有指定注解的元素进行处理。下面是一个简单的使用APT的示例:
假设我们要实现自动序列化功能,可以使用注解@Serializable标记需要序列化的类,然后通过APT生成相应的序列化和反序列化代码。
首先,定义注解和注解处理器:Serializable,通过APT可以生成与之相关的代码。
@Retention(RetentionPolicy.SOURCE)
@Target(ElementType.TYPE)
public @interface Serializable { }
编写自定义的注解处理器需要实现javax.annotation.processing.AbstractProcessor类,并重写process方法。在process方法中,可以获取被注解标记的元素,并进行相应的处理。
package com.demo.bytecode.apt; import javax.annotation.processing.AbstractProcessor;
import javax.annotation.processing.RoundEnvironment;
import javax.annotation.processing.SupportedAnnotationTypes;
import javax.annotation.processing.SupportedSourceVersion;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.Element;
import javax.lang.model.element.ElementKind;
import javax.lang.model.element.TypeElement;
import javax.tools.JavaFileObject;
import java.io.IOException;
import java.io.Writer;
import java.util.Set; @SupportedAnnotationTypes("com.demo.bytecode.apt.Serializable")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class SerializableProcessor extends AbstractProcessor { @Override public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) { for (TypeElement annotation : annotations) { for (Element element : roundEnv.getElementsAnnotatedWith(annotation)) { if (element.getKind() == ElementKind.CLASS) { String className = element.getSimpleName().toString(); String packageName = processingEnv.getElementUtils().getPackageOf(element).toString(); generateSerializerClass(packageName, className); generateDeserializerClass(packageName, className); } } } return true; } private void generateSerializerClass(String packageName, String className) { String serializerClassName = className + "Serializer"; StringBuilder serializerClassCode = new StringBuilder(); serializerClassCode.append("package ").append(packageName).append(";\n\n"); serializerClassCode.append("import java.io.Serializable;\n"); serializerClassCode.append("import java.io.ObjectOutputStream;\n"); serializerClassCode.append("import java.io.IOException;\n\n"); serializerClassCode.append("public class ").append(serializerClassName) .append(" implements Serializable {\n\n"); serializerClassCode.append(" private static final long serialVersionUID = 1L;\n\n"); serializerClassCode.append(" public static void serialize(").append(className) .append(" obj, ObjectOutputStream out) throws IOException {\n"); serializerClassCode.append(" out.writeObject(obj);\n"); serializerClassCode.append(" }\n"); serializerClassCode.append("}\n"); try { JavaFileObject serializerFile = processingEnv.getFiler().createSourceFile(packageName + "." + serializerClassName); try (Writer writer = serializerFile.openWriter()) { writer.write(serializerClassCode.toString()); } } catch (IOException e) { e.printStackTrace(); } } private void generateDeserializerClass(String packageName, String className) { String deserializerClassName = className + "Deserializer"; StringBuilder deserializerClassCode = new StringBuilder(); deserializerClassCode.append("package ").append(packageName).append(";\n\n"); deserializerClassCode.append("import java.io.Serializable;\n"); deserializerClassCode.append("import java.io.ObjectInputStream;\n"); deserializerClassCode.append("import java.io.IOException;\n\n"); deserializerClassCode.append("public class ").append(deserializerClassName) .append(" implements Serializable {\n\n"); deserializerClassCode.append(" private static final long serialVersionUID = 1L;\n\n"); deserializerClassCode.append(" public static ").append(className) .append(" deserialize(ObjectInputStream in) throws IOException, ClassNotFoundException {\n"); deserializerClassCode.append(" return (").append(className).append(") in.readObject();\n"); deserializerClassCode.append(" }\n"); deserializerClassCode.append("}\n"); try { JavaFileObject deserializerFile = processingEnv.getFiler().createSourceFile(packageName + "." + deserializerClassName); try (Writer writer = deserializerFile.openWriter()) { writer.write(deserializerClassCode.toString()); } } catch (IOException e) { e.printStackTrace(); } }
}
- 在
resources下新建一个META-INF/services的目录; - 在
services下新建一个javax.annotation.processing.Processor的文件,并将要注册的Annotation Processor的全路径写入。

javax.annotation.processing.Processor内容如下:com.demo.bytecode.apt.SerializableProcessor上述配置后Maven编译会报如下错误
服务配置文件不正确, 或构造处理程序对象javax.annotation.processing.Processor: Provider com.demo.bytecode.apt.SerializableProcessor not found时抛出异常错误
通过Maven的编译插件的配置指定如下:
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <compilerArgument>-proc:none</compilerArgument> </configuration> </plugin> </plugins>
</build>
将上述apt代码打包,这样在我们项目中就可以使用了。 在项目中引入依赖
<dependency> <groupId>com.demo</groupId> <artifactId>bytecode-apt</artifactId> <version>1.0-SNAPSHOT</version>
</dependency>
项目编译引入jar
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> <compilerArguments> <verbose></verbose> <bootclasspath>${java.home}/lib/rt.jar:${java.home}/lib/jce.jar:${java.home}/lib/jsse.jar </bootclasspath> </compilerArguments> <annotationProcessorPaths> <path> <groupId>com.demo</groupId> <artifactId>bytecode-apt</artifactId> <version>1.0-SNAPSHOT</version> </path> </annotationProcessorPaths> </configuration> </plugin> </plugins>
</build>
定义一个方法
@Serializable
public class Product { private Long id; private String name; private double price;// get set 略
}
Maven编译后在目录下生成了序列化及反序列化类

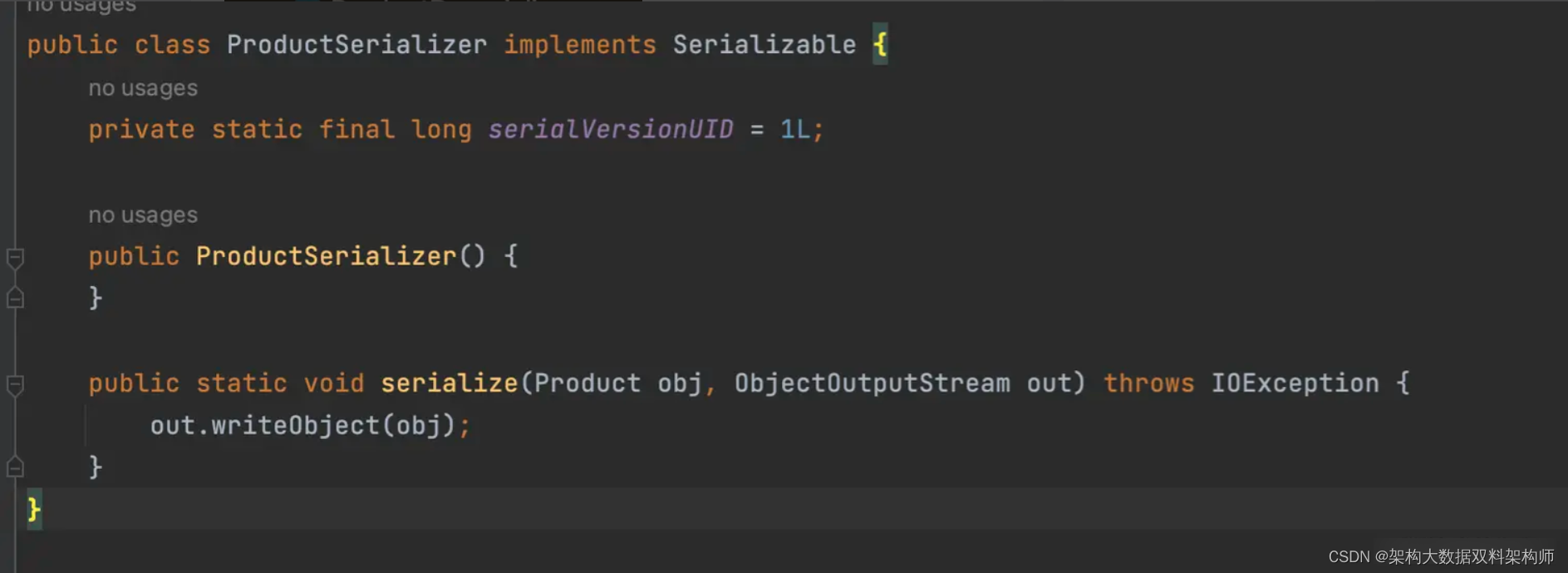
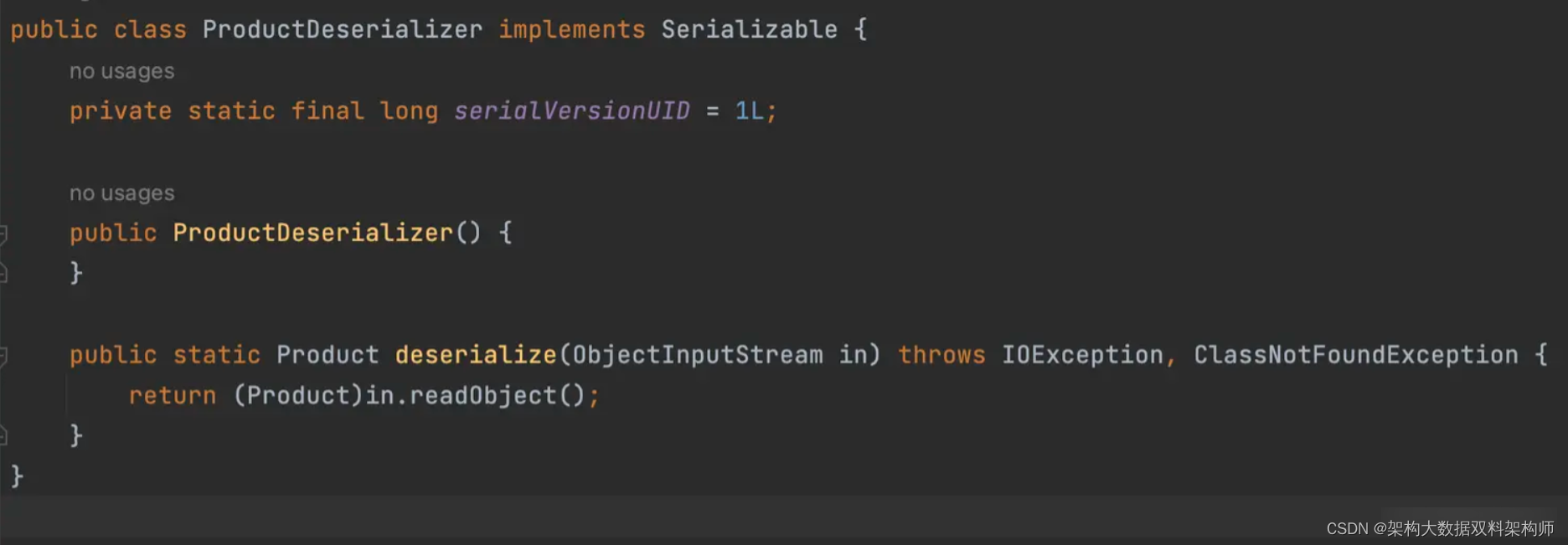
以上示例中的代码仅为示范,实际项目中可能需要更多的处理和逻辑。这些示例演示了如何使用APT来生成代码,以及如何编写自定义的注解处理器来自动化生成和处理代码。
总结
通过本文的详细介绍,读者对APT的概念、原理和应用应该有了更深入的理解。APT作为一个强大的编译时工具,可以帮助开发者实现自动化、提高代码质量和性能,并在项目开发中发挥重要作用。随着技术的不断演进,APT有望在Java开发中扮演更加重要的角色。








![2023年中国纸箱机械优点、市场规模及发展前景分析[图]](https://img-blog.csdnimg.cn/img_convert/1627efa273e9d7f4a633393bb15c4acf.png)