第一代数据仓库——Vertica
最初,Uber使用MySQL作为他们的主要数据存储。然而,随着业务的扩展和数据量的增长,他们开始需要一个更强大的解决方案来进行大规模的数据分析和处理。
因此,Uber选择了Vertica作为他们的第一代数据仓库。Vertica是一个高性能的列式存储数据库,专为分布式大规模数据分析设计,能处理PB级别的数据,并支持SQL和许多BI工具。它为Uber的数据分析提供了更快、更强大的支持。(跟ClickHouse有点像)

目前Vertica国内用的很少,数据格式为JSON是比较低效的。
第二代数据仓库——HBase
HBase是一个分布式、可扩展、支持大数据存储的NoSQL数据库,它是Google的BigTable的开源实现,作为Hadoop生态系统的一部分,HBase旨在提供高吞吐量的随机读写操作。HBase的核心特性包括水平可扩展性、列式存储、强一致性等。
在Uber的第二代数据仓库中,HBase被用作主要的数据存储和查询引擎,数据存储在HBase中,应用通过HBase的接口进行读写操作。同时,这个阶段的Uber还利用了Hadoop MapReduce等其他技术来进行数据处理和分析。
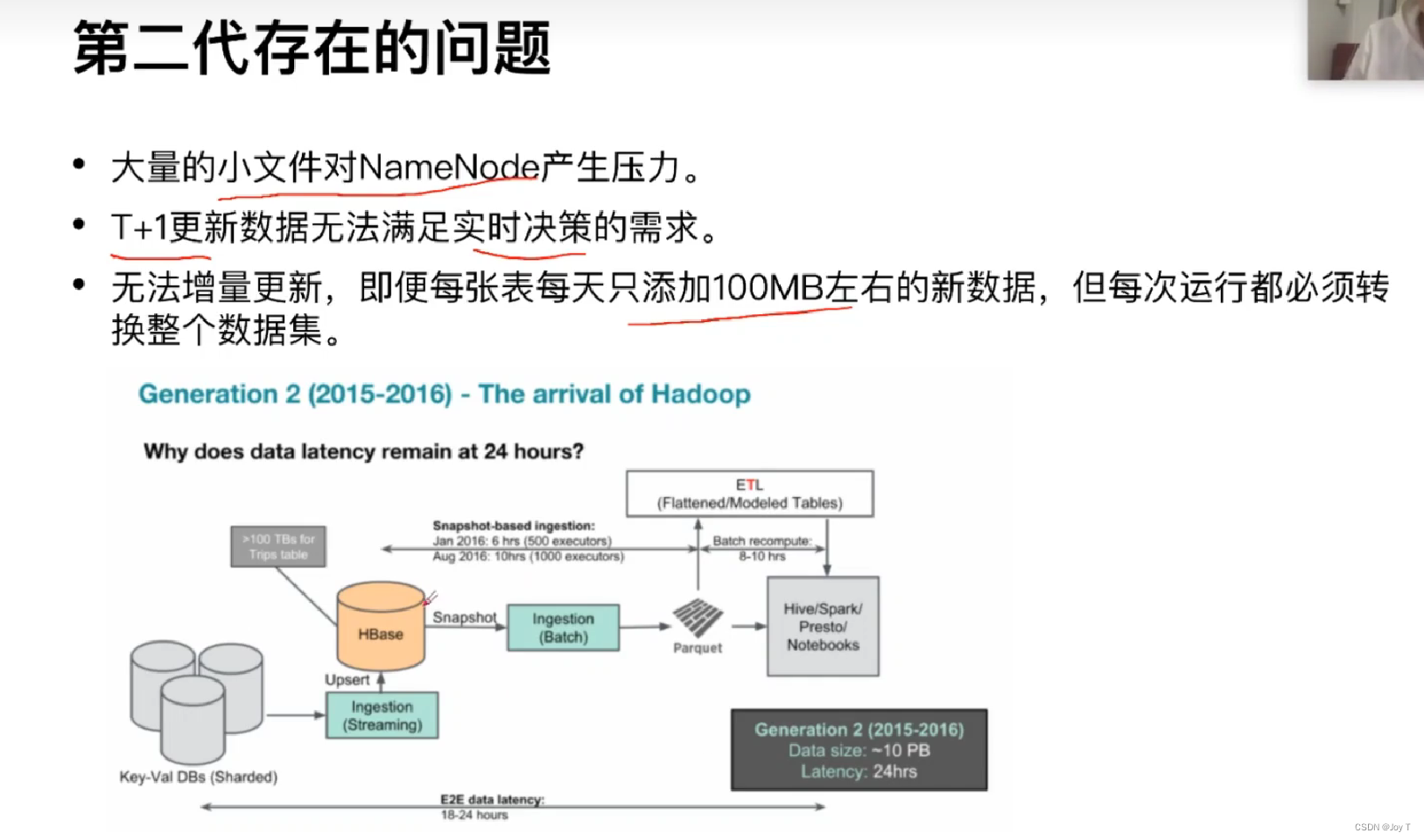
第二代底层优化为以HBase为中心,如上图所示,尽管HBase提供了大规模数据的随机读写能力,但是也存在小文件处理、增量更新能力不足的缺点。每次都是和原本的整个数据集做LEFT JOIN,每次都需要耗费几个小时用于更新数据集。
HBase本质上是一个Key-Value存储系统,它的设计并不是为了处理大量小文件,而是为了处理大量的大文件。此外,虽然HBase支持随机写入,但对于大规模的增量更新,特别是在处理大规模数据集的时候,这种更新操作可能需要花费相当长的时间。
特别是,在Uber的场景下,由于其业务的快速增长和对实时性的需求,HBase可能无法满足其所有的需求。这就是为什么Uber开始寻找更好的解决方案,并最终开发了Apache Hudi。
第三代数据仓库——Hudi
Hudi简介
Hudi是一个开源的大数据存储服务,它提供了更高效的增量处理能力,允许快速地更新和插入大数据集,这使得Uber可以更快速地处理数据并提供更实时的服务。(通常是分钟级别的实时,而不是秒级的实时。秒级其实Hudi也能实现,但如果算秒的话,资源消耗就太大了)
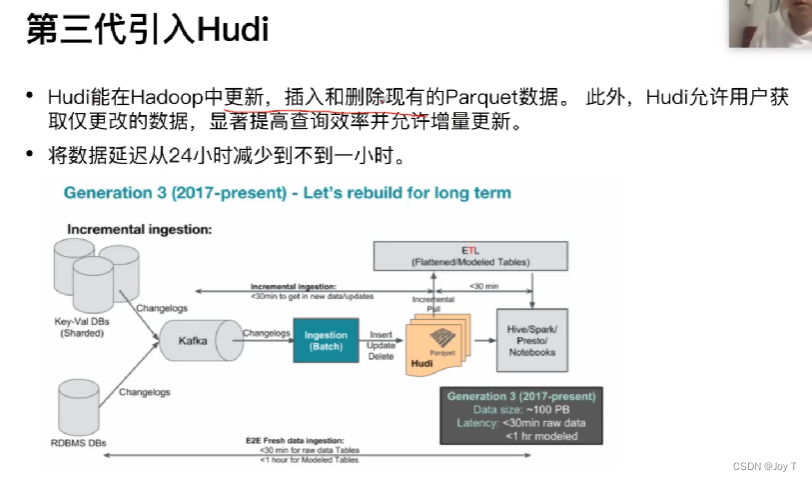
Uber发现他们需要一个能支持实时和分析混合型工作负载的解决方案。这导致了他们创建Apache Hudi,一个为快速、增量数据管道而构建的分布式数据存储框架。通过使用Apache Hudi,Uber能够以接近实时的速度更新他们的数据仓库,并且提供更快的数据查询性能。其底层的数据集格式是Parquet。

Hudi架构
数据流入与集成
数据首先通过Kafka流入。Kafka是一个分布式流处理平台,它可以实时处理大量的事件数据。当数据事件在源系统中发生时,它们被发送到Kafka中,然后在此处进行缓冲。
存储与格式
从Kafka接收的数据被转化并存储为Parquet格式。Parquet是一种列式存储格式,特别适用于分析查询。列式存储可以提供更好的压缩率并提高查询性能。(所以你看,大数据分析中,列式存储是多么常用与重要!)
实时变更与Hudi
当新数据进入或现有数据发生变化时,我们不再需要重写整个Parquet文件。这时,Hudi(Apache Hudi)的作用显现出来。Hudi可以快速地将这些变更应用到现有的Parquet文件上,从而确保数据是最新的。Hudi还提供了一种机制,允许用户查询到一个特定时间点的数据版本,这在时间旅行查询或数据回滚中很有用。
Change Log & 原信息
当数据变更发生时,Hudi通过Change log来记录这些变化。这意味着,即使数据发生了更改,其历史版本的记录仍然可以被检索和访问。
底层存储
尽管Hudi和Parquet提供了数据的逻辑视图和格式,但物理数据需要存储在某个地方。在云环境中,数据可以存储在云存储服务中,如Amazon S3或Google Cloud Storage。但在一般的学生项目中,数据直接存储在服务器的HDFS(Hadoop Distributed FileSystem)中,这是一个可扩展和分布式的文件系统,特别设计用于存储大规模数据。
计算层访问
一旦数据被处理并存储,上游的计算层(如Spark, Hive或Presto)可以直接读取这些最新的数据,并进行相应的数据分析和处理。

Hudi组件


总体来说,Hudi底层是支持列式和行式数据存储格式,列式用于优化读操作,行式优化写操作。我们将行式写操作通过compact转化为列式操作,这样就能快速实现查询。如果没有这种区分,就像Delta Lake一样,只有列式数据,我们的写操作就必须将原有的所有parquet数据取出然后再增量添加,这个就是Hudi和其他数据湖的最大的底层差别!

元数据维护数据当时存在的状态!
Hudi表类型
COW表——写时复制

在新增结果之后,进行写时复制,没有改变的记录值都是从原有的文件中复制过来。这个和Delta Lake一样。

注意下面一行的 Snapshot 快照,一般情况下更改文件记录之后,原有的文件(比如File 0)不会立刻消失,而是作为待处理的文件,用于之后的复制。但是复制过后此时的Snapshot变成新的File0' 1' ,这样就会导致原有的File 0 File1虽然一般还是存在于磁盘中,但是已经无法被读取,File 0'和File 1'作为新的快照用于更新的文件的复制操作。(Incremental就是增量)
MOR表——读时合并
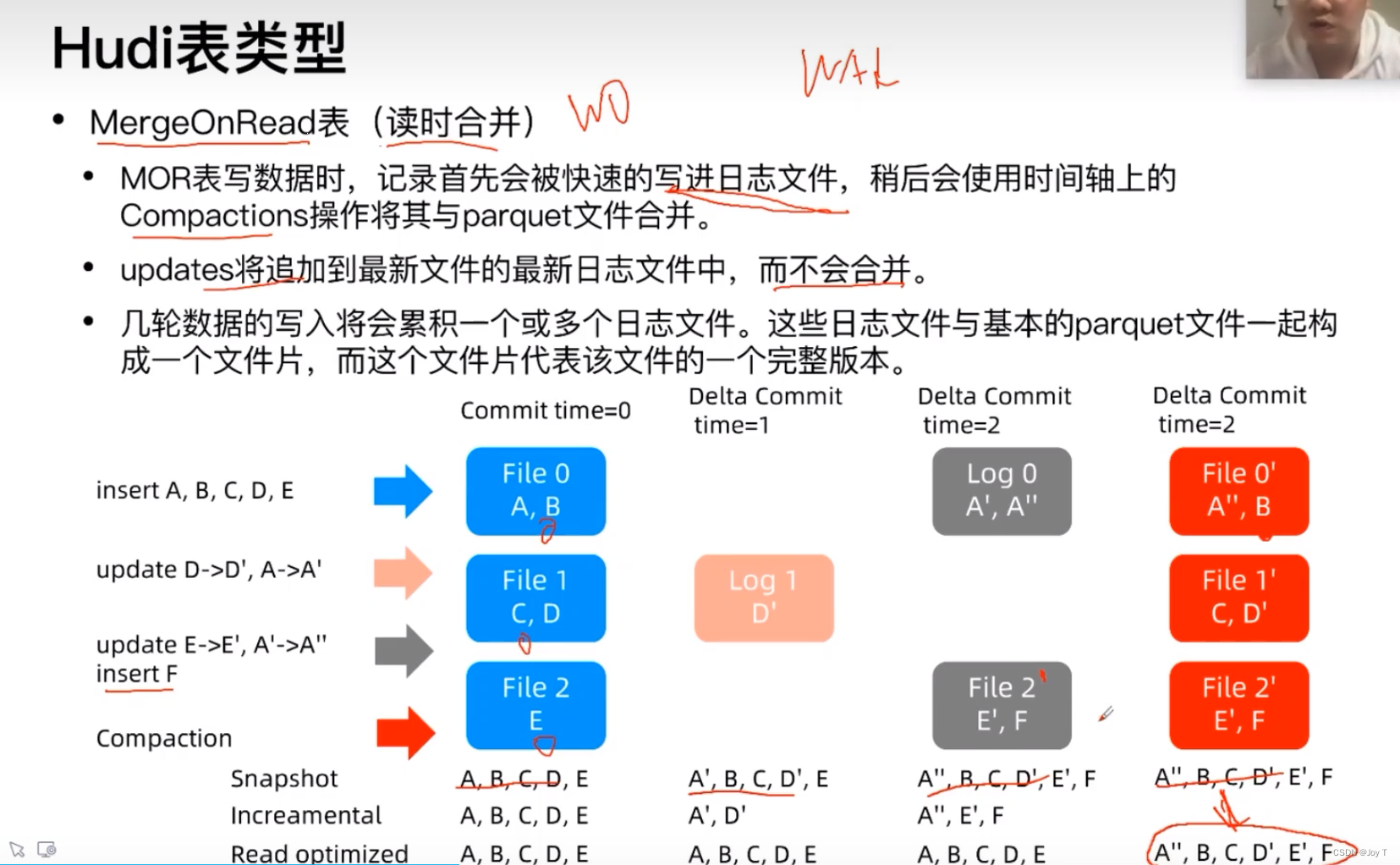
这个MOR表还蛮有意思的,读时才合并,说明你不用每写一次就合并一次,本质上优化写操作,但是对读操作也有一点影响。从底层来看,就是将所有的更新updates追加到log日志文件中,不会立即更改记录(但是insert/delete确实需要立刻改变原本的File文件,上图中的insert F就能体现),等到最后某一时刻需要读实时信息时,就会将所有的updates与原本的parquet文件合并产生新的文件。虽然在这之前没有产生新的File,但是作者认为它处于时刻准备的阶段,这也就是为什么每次的快照都能同时更新到最新状态。
但是注意,像上面File 2'其实是没有update E'这一个Log的,因为在更改E的同时,F的增加一定会改变File2形成File 2',此时不需要再用Log存储E的改变,直接随着F的增加而更改到文件中也比较方便。
对于最后一行的Read optimized,在没有读操作的时候Read optimized为ABCDE,表示还没有合并;当有读操作的时候(最右侧一列),此时读到的文件就是快照,而且完全转化为了列存的格式,就是这个意思。