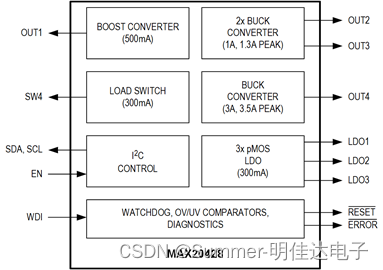
VCR库编写一个爬虫程序来爬取图片,代码如下所示:
require 'vcr'
require 'open-uri'
# 使用VCR库录制一次HTTP请求
VCR.use_cassette('vip_crawler') do# 设置主机和端口proxy_host = ''proxy_port = ''# 创建一个HTT理对象proxy = URI.parse("http://#{proxy_host}:#{proxy_port}")# 使用代理对象打开网页response = open("https://www.vip.com/", proxy: proxy)# 获取网页内容html = response.read# 使用正则表达式匹配图片链接image_links = html.scan(/<img.*src=['"]([^'"]+)[\s>]/i)# 遍历所有图片链接,下载图片image_links.each do |link|image_url = link[0]File.open(image_url, 'wb') do |file|file.write(open(image_url).read)endend
end
首先使用VCR库录制一次HTTP请求,然后设置主机和端口,创建一个HTTP对象,象打开网页,获取网页内容,使用正则表达式匹配图片链接,遍历所有图片链接,下载图片。