String s3 = new String("a") + new String("b")会不会在常量池中创建对象?
答案:不会,首先需要解释“+”字符串拼接的理解。
采用 + 运算符拼接字符串时:
- 如果拼接的都是字符串直接量,则在编译时编译器会将其直接优化为一个完整的字符串,和你直接写一个完整的字符串是一样的,所以效率非常的高。
- 如果拼接的字符串中包含变量,则在编译时编译器采用StringBuilder对其进行优化,即自动创建StringBuilder实例并调用其append()方法,将这些字符串拼接在一起,效率也很高。但如果这个拼接操作是在循环中进行的,那么每次循环编译器都会创建一个StringBuilder实例,再去拼接字符串,相当于执行了 new StringBuilder().append(str).toString(),所以此时效率很低。
所以 字符串常量池中有没有"ab"的创建,主要在于StringBuilder.toString()方法中创建String对象的构造方法与new String("ab")的构造方法不同。toString()调用的构造方法是直接复制StringBuilder数组中的值,并没有使用到字面量"ab",字符串中常量池中不会创建字符串"ab"

也许你会问为啥
new String(value, 0, count);
为啥没有在字符串常量池中创建
这里又引出一个面试题
new String("abc") 是去了哪里,仅仅是在堆里面吗?
在执行这句话时,JVM会先使用常量池来管理字符串直接量,即将"abc"存入常量池。然后再创建一个新的String对象,这个对象会被保存在堆内存中。并且,堆中对象的数据会指向常量池中的直接量。

输出为false ,false
注意我的用词在执行这段话的时候字符串常量才会存入常量池,因此又引出一个面试题
字符串常量是什么时候进入到字符串常量池的?
Java 的类加载过程要经历加载(Loading)、链接(Linking)、初始化(Initializing)等几个步骤,在链接这个步骤,又分为验证(Verification)、准备(Preparation)以及解析(Resolution)等几个步骤。
在 Java HotSpot 虚拟机中,字符串字面量在类加载的解析阶段并不会被填充到字符串常量池中,而是存储在运行时常量池中。这意味着,虽然这些字符串常量的值在编译期间已经确定,但实际的字符串对象还没有创建。
只有当代码中实际使用到这个字符串字面量时,虚拟机才会在字符串常量池中创建对应的 String 实例。这种处理方式可以避免预先创建大量可能并不会被使用的字符串对象,从而节省内存。
String s3 = new String("a") + new String("b")会创建几个对象?
答:6个 , 堆中会有 String对象 a, String对象 b,以及这两个对象指向字符串常量池中的 ’a‘ 与 ’b‘。
然后字符串拼接的时候会创建StringBuilder对象,然后toString的时候会创建一个String对象。
那么又来了一个面试题
如何将这种存在于堆中又不在字符串常量词的字符串对象存入字符串常量池?
答:intern()方法,用于将字符串对象手动添加到字符串常量池中。调用intern()方法时,如果字符串常量池中已经存在相同内容的字符串,将会返回常量池中的引用;如果不存在,则会在常量池中创建新的字符串。
所以
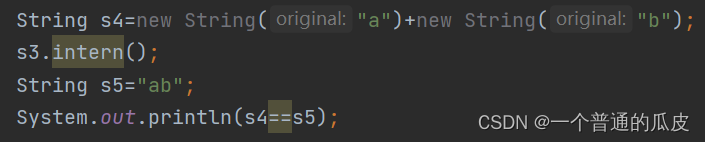
输出ture
而
输出false
这里我有一个疑问,为啥调用s3.intern()方法之后 s3的指向变成了常量池中的“ab”了,希望大佬解释一下,这里就是我最近学到的java字符串相关内容