前言
- 先来谈一下文件的共识
- 文件 = 内容 + 属性。
解释:文件在创建时就有基本属性,比如权限,文件名,文件的创建时间等基本信息。- 文件分为打开的文件与未被打开的文件。
解释:打开的文件由操作系统进行管理。未打开的文件要解决如何找的问题(下面细讲)。- 文件是通过先组织再描述进而间接被管理的。
解释:其中文件通过其共有的属性被描述为 struct file结构体对象,这些结构体之间通过链表的形式被操作系统组织,进而统一的进行管理。- 一个进程可能会打开多个文件,多个进程可能会打开同一份文件。
解释:以IO的角度来看,显示器文件,每个进程都要打开这个文件(多对一)。一个进程创建多个文件进行打开(一对多)。因此每个进程都有属于自己打开的一个或多个文件,因此进程这里就抽象出了 struct files_struct进行管理属于自己打开的文件。
一.文件操作
1.文件描述符
- 文件描述符的本质是什么?
- 本质是数组的下标。
引入问题:为什么要这样做呢?
解释:
- 进程打开与关闭文件,并不一定只打开或者关闭一个文件,因此需要将打开的文件都用数组的方式管理起来。
- 如此以来,进程就多了一种访问的方式,即数组的下标。而数组的下标相当于将文件指针又封装了一次,返回给上层,也就是文件描述符,看起来更加的安全。
- 并且只需要将文件描述符,下层也可以通过数组的形式看出文件指针进行操作,相当于一箭双雕。
光看内容是理解不了的,我们画图更近一步理解一下。
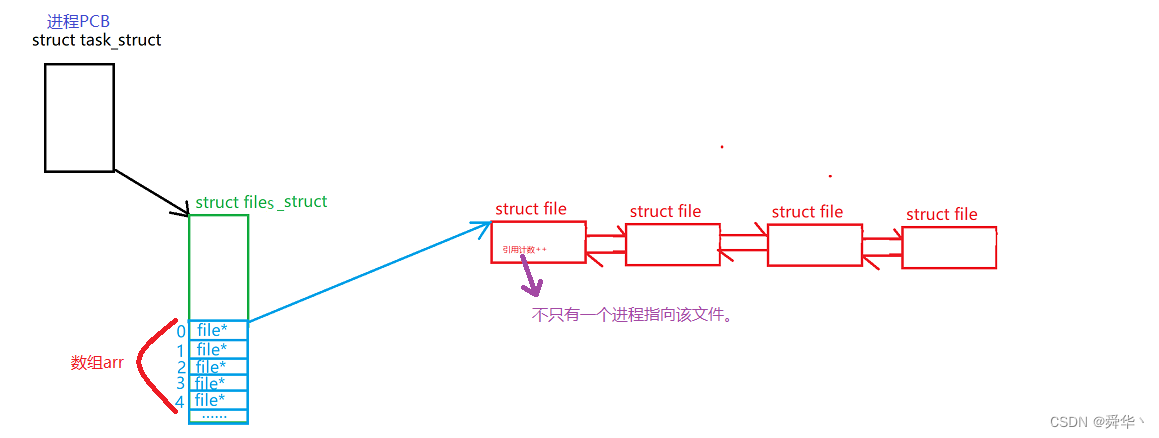
再来解释一下为什么要这样做?而不是直接进程指向file。
解释:
- 文件是操作系统打开,并且由操作系统进行管理的,跟进程关系到不大,进程只是通过系统调用让操作系统对文件访问修改等。
- 每个进程都有自己要打开与关闭的文件,彼此之间是独立的,因此需要每个进程都要有属于自己的files_struct。
2.C文件接口
2.1相对路径
这里我们解决一个小小的疑问:
问题: fopen在用相对路径打开文件时是如何找到路径的?
- 这里我们大胆猜测一下跟进程有关系,下面我们验证。
#include<stdio.h>
int main()
{FILE* fptr = fopen("test.txt","w");while(1);//死循环是为了方便查看进程的相关信息。fclose(fptr);return 0;
}
先看实验的结果:

- 此时进程正在进行死循环。
再查看进程的信息:

最后用pid查看进程的基本信息:
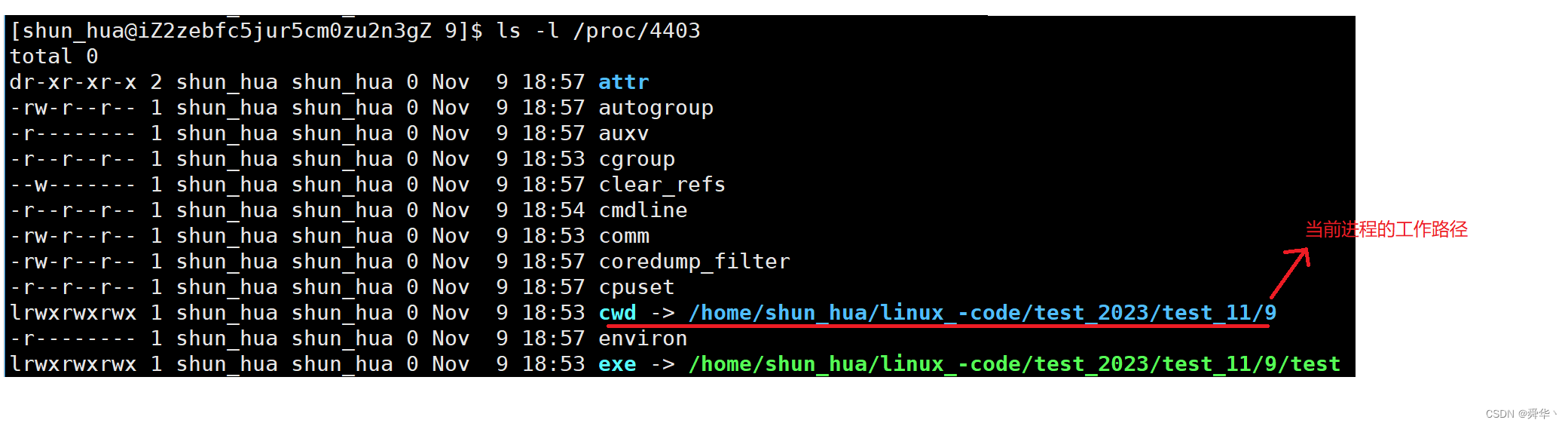
- 到这我们大胆猜测,进程的文件创建的路径与此有关,因此我们把cwd改一下,再查看创建的文件是否还在原路径。
说明:使用chdir接口进行改cwd。
#include<unistd.h>
int chidr(char* path);
参数:所要更改的目录,可以是相对目录,也可以是绝对目录。
返回值:成功返回0,失败返回-1,并且设置合适的错误码。
//补充一点:进程的工作目录必须是合法且当前用户能访问的目录。
更改代码:
#include<stdio.h>
#include<unistd.h>
int main()
{chdir("/home/shun_hua"); FILE* fptr = fopen("test.txt","w");while(1);fclose(fptr);return 0;
}
运行查看结果:

ps命令查看进程状态:
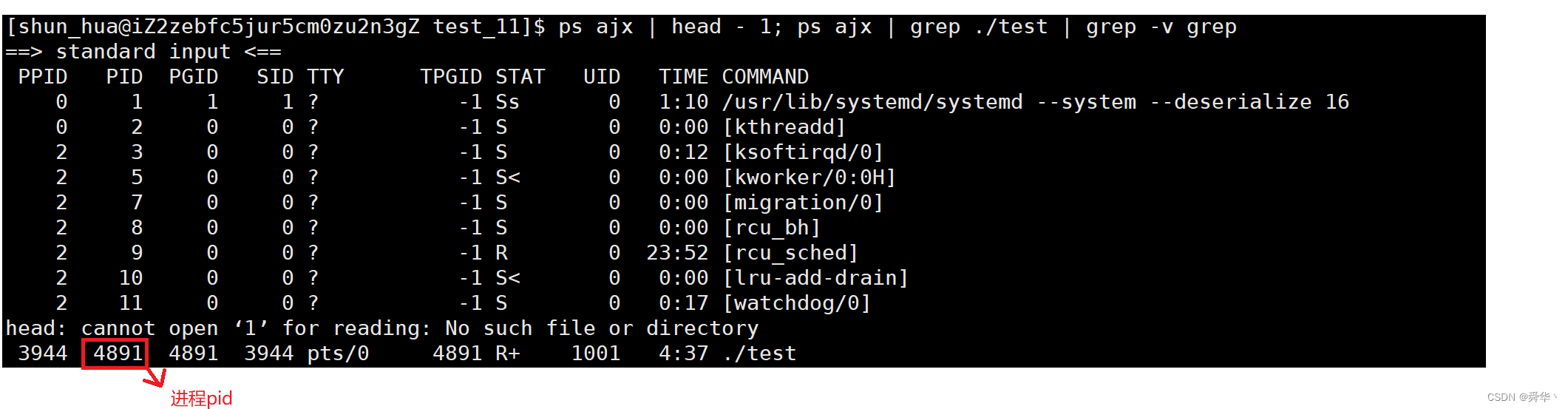
用进程pid查看进程的基本信息:
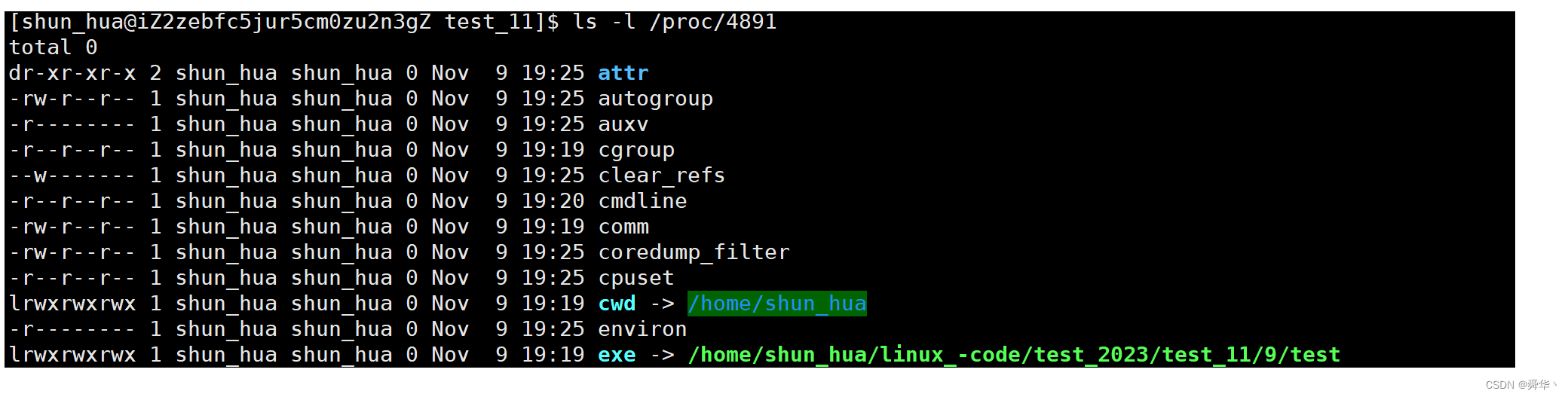
- 综上所述:这里的相对路径与进程的cwd(current working directory,即当前工作目录)有关。
2.2写权限
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{FILE* fptr = fopen("test.txt","w");const char* message = "hello fwrite";fwrite(message,strlen(message),1,fptr);//这里的参数我简单提一下,第一个是内容的指针,第二个是文件的内容的大小,//第三个是这样文件的内容大小的个数, 第4个是文件的指针。fclose(fptr);return 0;
}
提出问题:这里的strlen求出的结果之后还需要 加1吗?
不妨都试一下:
-
不加一的结果:
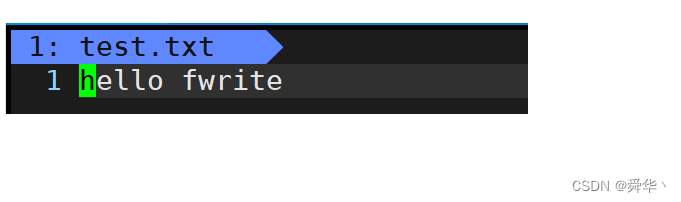
-
加一的结果:

可见:对于\0来说,文本编译器并不认可,因此我们可以得出——
- 字符串以\0结尾只是语言层次为了标记字符串为结尾,从而设置的一个标记位。
- 对于操作系统或者对于一些文本编辑器来看,并不需要这个标记位。
- 多说两句,其实加也是无所谓的,只是用文本编辑器打开之后人看不懂。
3.系统接口
3.1open
- 使用说明
头文件:
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
函数声明:
int open(const char* pathname,int flags,mode_t mode);函数参数:
1. pathname,文件创建的路径。
2. flags,文件打开的方式,具体常见的方式有以下五种:2.1 O_CREAT,文件没有就创建。2.2 O_TRUNC,文件打开即清空。2.3 O_APPEND,文件以追加形式打开。2.4 O_WRONLY,文件以只写方式打开。2.5 O_RDONLY,文件以只读方式打开。2.6 O_RDWR ,文件以读和写的方式打开。
除此之外,如果想要多种功能可以以 | 进行相连。
3.mode,文件的默认打开权限,一般文件设置为666,目录设置为777。补充一点:这里不要忘了,权限掩码(umask)这个东西,最后会影响所看到的结果。
如何设置umask,头文件与此相同,且函数名也为umask。
其函数声明为:mode_t umask(mode_t mask); 返回值:1. 文件打开成功,返回fd,即返回打开的文件描述符。2. 文件打开失败,返回-1,且会设置合适的错误码。这里顺便把close的接口讲了:
头文件:
#include<unistd.h>
函数声明:
int close(int fd);
参数:文件描述符。
返回值:
1.关闭成功,返回0.
2.关闭失败,返回-1,并且会设置合适的错误码。
- 简单使用
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{umask(0);//设置权限掩码为0。int fd = open("test.txt",O_CREAT|O_TRUNC|O_WRONLY,0666);//这里是在当前路径下,以如果没有就创建,并且清空只写的方式进行打开。//文件设置的权限为0666(八进制数),切记不能设置为666(十进制数),if(fd < 0){perror("open");return -1;}close(fd);return 0;
}
说明:perror会在字符串的后面跟上 : + 错误原因 。
- 这里我们再来谈一谈文件打开方式原理,即为什么用 | 就能将功能连接一块。
先看看常用的打开方式其定义:
所在文件:/usr/include/bits/fcntl-linux.h
#define O_RDONLY 00
#define O_WRONLY 01
# define O_TRUNC 01000
# define O_CREAT 0100
# define O_APPEND 02000
- 可见,其设置有一个特点,就是指定的比特位进行设置,通过或的结果进行判断是否为此权限,比如假如设置打开方式为0101(八进制),与O_RDONLY的结果与O_RDONLY的结果相等,则存在此权限,同理或上O_CREAT与O_CREAT也相等,因此也有此权限,等等类似。
3.2write
- 使用说明
头文件:
#include<unistd.h>
函数声明:
ssize_t write(int fd,const void* buf,size_t count);参数:
1. fd,文件描述符。
2. 要写入文件内容的指针。
3. 写入文件内容的大小。返回值:
1.如果写入文件成功,返回写入文件的字节数,0表示啥也没写进去。
2.如果写入文件失败,返回-1,并且设置合适的错误码。
- 简单使用
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
int main()
{umask(0);int fd = open("test.txt",O_CREAT|O_TRUNC|O_WRONLY,0666);if(fd < 0){perror("open");return -1;}const char* message = "hello write\n";write(fd,message,strlen(message));close(fd);return 0;
}
- 实验结果:

3.3read
- 基本说明
头文件:
#include<unistd.h>
函数声明:
ssize_t read(int fd,void* buf,size_t count);
参数:
1. fd,文件描述符
2. buf,存放读入内容的指针。
3. count,读的字节数.
返回值:
1. 读成功,返回读入的字节个数,0意味着读到了文件的末尾。
2. 读失败,返回-1,并设置合适的错误码。
- 简单使用
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>
#define MAX_SIZE (1024)
int main()
{int fd = open("test.txt",O_CREAT|O_TRUNC|O_RDWR,0666);if(fd < 0){perror("open");return -1;}//向文件写入hello write\nconst char* message = "hello write\n";write(fd,message,strlen(message));//等会我们会在这下面加上一句代码://向文件中读入hello write\nchar buf[MAX_SIZE] = {0};read(fd,buf,strlen(message));printf("read:%s\n",buf);close(fd);return 0;
}
- 实验结果:

竟然啥都没读到,这是怎么回事呢?
- 其实很简单,对文件操作,是有一个文件指针的,我们之前向文件里写时,文件指针已经指向hello write\n的最后位置了,肯定读不到,因此我们应该将文件指针调整到开头再开始读。
- 调整文件的接口——lseek
头文件
#include<unistd.h>
#include<sys/type.h>
函数声明
off_t lseek(int fd,off_t offset,int whence);
参数
1. fd,文件描述符
2. offset,移动到相对于whence偏移量offset的位置。
3. whence, 移动的起点位置,常见的有SEEK_SET(文件开头),SEEK_CUR(文件的当前
位置),SEEK_END(文件末尾位置)。
常用的几种:
lseek(fd,0,SEEK_SET);//移动文件指针到开始
lseek(fd,0,SEEK_CUR);//移动文件指针到当前位置
lseek(fd,0,SEEK_END);//移动文件指针到结束位置返回值:
1. 打开成功,返回距离文件开头的字节数。
2. 打开失败,返回-1,并设置合适的错误码。
此时我们只需在上面的代码加上:
lseek(fd,0,SEEK_SET);//移动文件指针到开始
再次运行程序,即可看到:

说明:这里多了一个\n的原因是我们写文件时有一个\n,我们在printf处也加了一个\n,因此有两个\n。
谈完这几个接口,我们接下来就该谈一谈,C接口与系统接口的之间的联系。
先来引入一下:
- 任何用户再访问底层时,必然绕不开操作系统。
- 操作系统给上层提供系统调用接口来间接的访问底层设备。
- 因此:我们肯定C语言的文件接口必然封装了系统调用接口。
如何证明呢?
- C语言的文件操作是通过文件指针来进行实现的。
就比如我们常见的C语言默认打开的三个流,其实就是文件指针。
typedef struct _IO_FILE FILE;
extern struct _IO_FILE *stdin;
extern struct _IO_FILE *stdout;
extern struct _IO_FILE *stderr;
那我们可以判断stdin 与 stdout 与stderror里面必然封装了文件描述符。
实验验证:
#include<stdio.h>
int main()
{printf("stdin_fd:%d\n",stdin->_fileno); printf("stdout_fd:%d\n",stdout->_fileno); printf("stderror_fd:%d\n",stderr->_fileno); return 0;
}
运行结果:

如何验证呢?
我们上面的write与read,其第一个参数就是文件描述符,我们可以使用这两个接口进行验证。
- 从文件描述符0中读入一段数据,再向文件描述符1和2中写入读入的一段数据。
- 实验符合预期也就是,从键盘读入一段数据,再向显示器中打印两端读入的数据。
#include<unistd.h>
#include<string.h>
#define MAX_SIZE (1024)
int main()
{char buf[MAX_SIZE] = {0};//read max MAX_SIZE - 1 from 0 fd to buf;read(0,buf,MAX_SIZE - 1);write(1,buf,strlen(buf));write(2,buf,strlen(buf));return 0;
}- 实验结果:
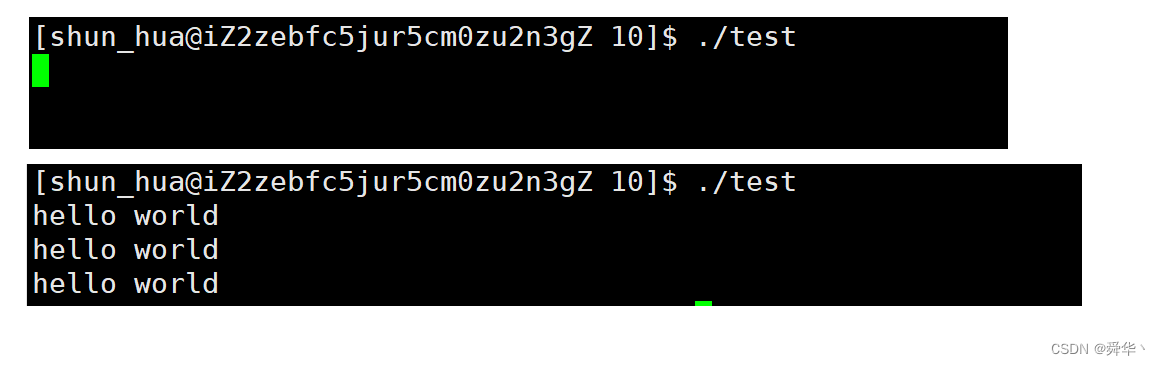
- 首先陷入阻塞状态,说明需要读入信息。
- 然后我们输入 hello world,然后按下回车。
- 最终显示器打印两次 hello world。
- 结论:实验与预期相符,因此可以断定,stdin,stdout,stderr对应的就是 0 1 2 号文件描述符。
这时我们可以接着进行推断,C语言默认打开这三个流是C语言的特性吗?
- 肯定不是,既然是操作系统管理,那么所有语言必然直接或间接的封装了这三个流,也就意味着这是进程的特性。
- 补充:既然C接口是由系统掉用接口进行封装了,那么像一些输入输出,比如scanf必然也封装了read之类的系统调用,printf必然封装了write这类的系统调用。
二.文件重定向
1.基本原理
- 先来看这一样一段代码:
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{//先关闭文件描述符1int fd1 = open("test1.txt",O_CREAT|O_TRUNC|O_RDWR,0666);int fd2 = open("test2.txt",O_CREAT|O_TRUNC|O_RDWR,0666);int fd3 = open("test3.txt",O_CREAT|O_TRUNC|O_RDWR,0666);printf("test1.txt:%d\n",fd1);printf("test2.txt:%d\n",fd2);printf("test3.txt:%d\n",fd3);close(fd1);close(fd2);close(fd3);return 0;
}- 运行结果:

因为前面的文件描述符(0 1 2)是进程默认打开的,这里新打开的文件自然在之后。
- 再来看这样一段代码:
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
int main()
{//先关闭文件描述符1close(1);int fd = open("test.txt",O_CREAT|O_TRUNC|O_RDWR,0666);printf("test.txt:%d\n",fd);printf("hello world\n");return 0;
}
-
实验现象:
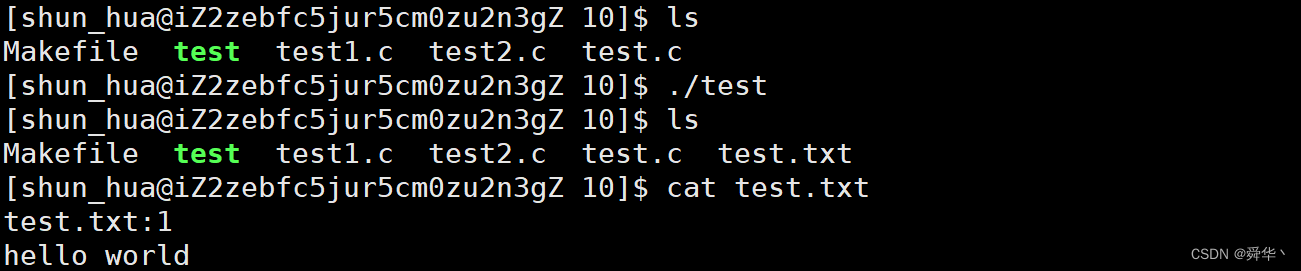
- 首先经过前面的讨论,这里我们关闭的文件描述符1,即stdout。
- 而且printf 默认向stdout里面输出数据。
- 其次这里我们看到的现象为并没有向显示器里面输出,而是向test.txt里面输出。
- 而且我们看到test.txt里面的文件描述符变成了1。
- 总结:这里的1号文件描述符关闭之后,后面打开的文件占据了1号描述符的文职,进而变成了stdout,而语言层面识别看不出来变化,因此向test.txt里面打印了数据。
这是什么原理呢?画个图就比较清晰了。
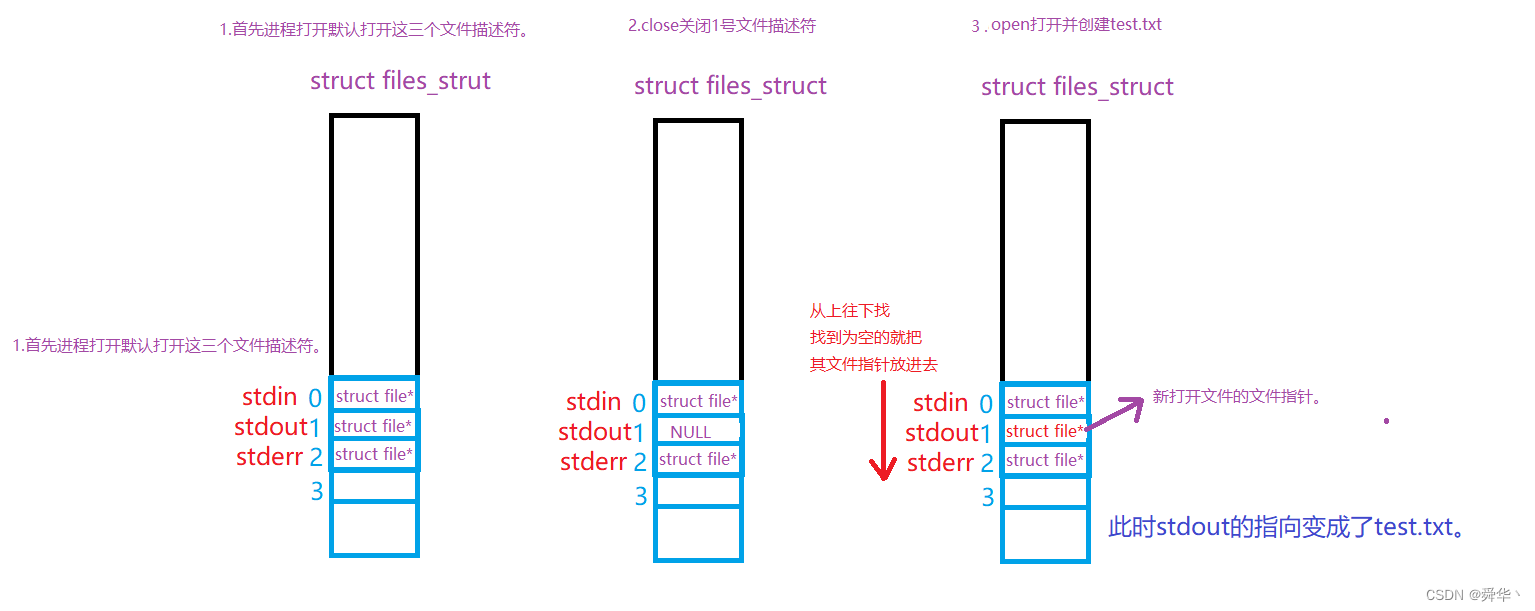
- 可见,stdout只是语言层面的概念,就是1号文件描述符下标存放的文件指针。底层变化,stdout,即下标并没有发生变化,但文件指针发生了变化。
- 可以判断,文件打开的原理本质上就是在指针数组中遍历寻找一个为空的位置,并将打开的文件指针放入其中,返回数组的下标,即所谓的文件描述符。
- 这样的现象我们称之为重定向,但是这里代码的重定向是否过于牵强了呢?
- 毕竟我们是先关闭文件描述符,再将文件打开,之后我们观察到现象,再把这种现象解释为重定向。
- 那有没有直接进行重定向的接口呢?
2.dup2
- 基本说明
头文件
#include<unistd.h>
函数声明
int dup2(int oldfd,int newfd);
参数
1.oldfd,是旧的文件描述符。
2.newfd,是新的文件描述符。
这里的意思是将oldfd下标指向的文件指针覆盖newfd下标的文件指针。
返回值
1. 成功,返回newfd.
2. 失败,返回-1,设置合适的错误码。
- 简单使用
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{int fd = open("test.txt",O_TRUNC | O_CREAT | O_RDWR,0666);//直接进行重定向dup2(fd,1);//将fd指向的文件指针覆盖到1里面。printf("hello world\n");close(fd);return 0;
}
实验结果:

- 此处我们或许会疑惑这里,多个文件描述符存放的文件指针竟然是一样的,这可以吗?
- 理解原理就不难理解,进程中每存放一个文件指针,文件指针指向的file结构体对象的引用计数就会加1,这样在关闭时引用计数减减即可,这样不会出现一个文件释放多次的情况。
- 除此之外,如果你觉得另一个文件指针多余,也可在重定向之后将其关闭。
除此之外,我们还可以解决一个疑惑,即stdout与stderr有什么区别?
先看这样一段代码:
#include<unistd.h>
#include<string.h>
int main()
{const char* message = "hello world\n";write(1,message,strlen(message));write(2,message,strlen(message));return 0;
}
我们先正常执行这一段代码:

到这里应该都理解。
我们再将./test输出的内容重定向到test.txt中。
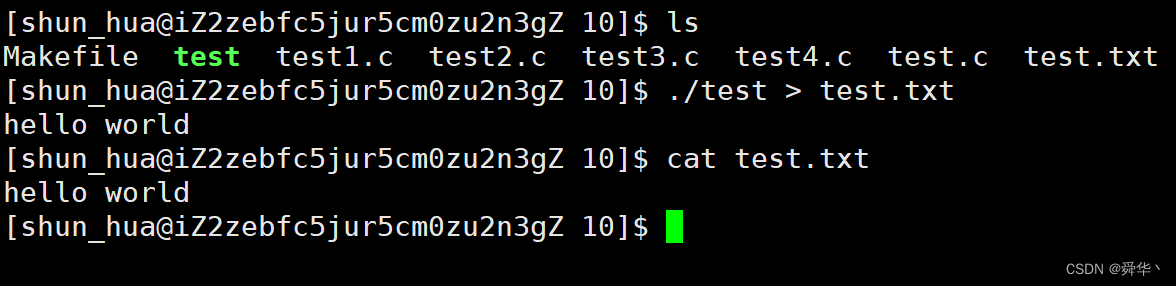
疑惑的是,这里的内容竟然只输出了一半,另一半还打印到了屏幕上,这是怎么回事呢?
- 联想之前的知识,这里其实很容易解释,进程启动时只重定向了,stdout,即1号文件描述符的文件指针为test.txt,而stderr,即2号文件描述符的文件指针并没有进行重定向。
那该如何做呢?
有两种做法:
- ./test 1 > test1.txt 2> test2.txt ; 细节: 第二个 >必须与前面挨着。
- ./test 1 > test1.txt 2>& 1; 细节: >& 必须与前面挨着。
- 第一种

- 第二种

这里多解释一下第二种方法,是在前面的 ./test 1 > test1.txt执行后,1的文件指针已经变为指向test1.txt的, 然后把 1里面的文件指针,再拷贝到2里面。因此 1 2 里面都是test1.txt的文件指针。
- 总结: 除此之外,stdout与stderr没有本质区别。
拓展:
- 程序替换时,会将进程的文件也进行替换吗?
- 答案是不会的,程序替换是替换页表中虚拟地址与物理地址的联系并且在内存中加载相应进程的内容,是与 mm_struct对象有关的。而文件的管理是与 files_struct相关的,两者之间没有必然联系,各干各的,互不影响。
- 如何理解"一切皆文件"?
- 图解
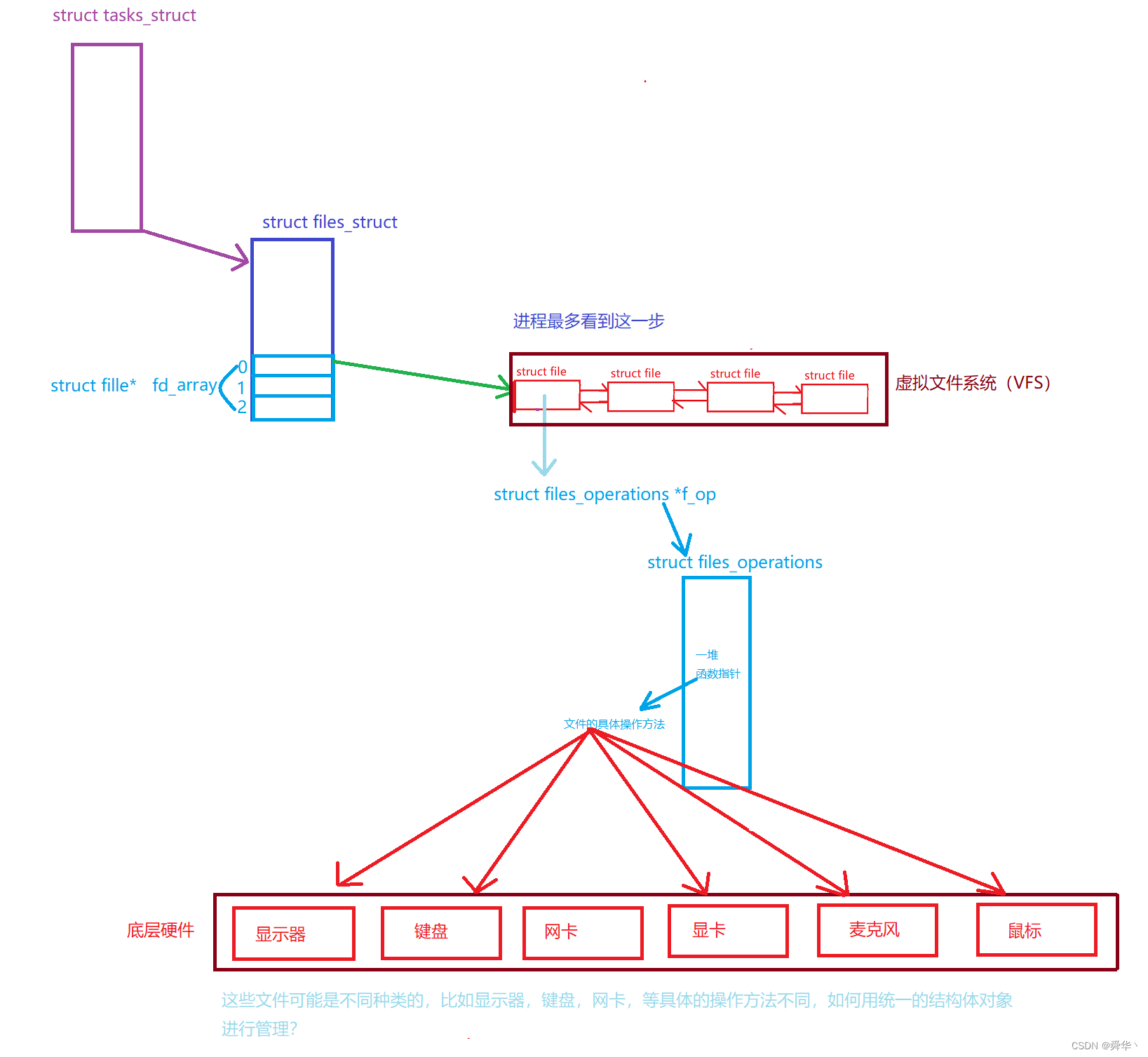
解释:
- 首先在进程看来,只需要看到struct file 即可,而具体的操作方法并不关心,再底层封装了一个 file_operations,即具体的操作方法,里面全部都是函数指针,且当打开一个具体的文件时,会初始化有对应的操作方法。
- 这样做体现是封装 + 多态的思想。既然C语言这么做了,那么可以看出面向对象是历史发展的必然结果,且不是语言特有的思想,是大量工程实验出来的结果。
- 这样封装出来的一套struct file 被称之为 虚拟文件系统(VFS)。
- 课外小知识: bash是媒婆广义上的命令行解释器,而shell是王婆是具体的某个系统的命令行解释器。
三.文件缓存区
缓存区是一个比较抽象的东西,我们在最初的了解printf时,就听过缓存区,可是它到底是个什么,我们是不知道的,或者说是不清楚的,下面我们就来了解一下缓冲区。
1.C缓存区
- 先观察现象
例1:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{printf("hello printf");//向stdout 输出hello worldconst char* message = "hello write";write(1,message,strlen(message));close(1);//在这里我们将文件关闭。return 0;
}
现象:

感觉是不是有点奇怪,write为啥能进行输出呢?而printf不输出呢?
解释:
- 首先我们之前文章中有一个小结论,那就是C语言的缓存区不在内核当中。
- 其次printf与write中我们都没有加 \n,也就意味着我们并没有主动的刷新缓存区。
- 而且C接口,也就是这里的printf必然封装了write之类的写的系统调用接口。
- 由于C语言的缓存区不在内核中,在程序关闭时进行文件刷新时,很显然的前面已经关闭了文件指针/文件描述符,C语言的缓存区刷不到文件里面,所以看不到这里的"hello printf",而write是在close之前掉的,且是直接写到内核缓存区了,因此这里能看到write的信息。
图解:
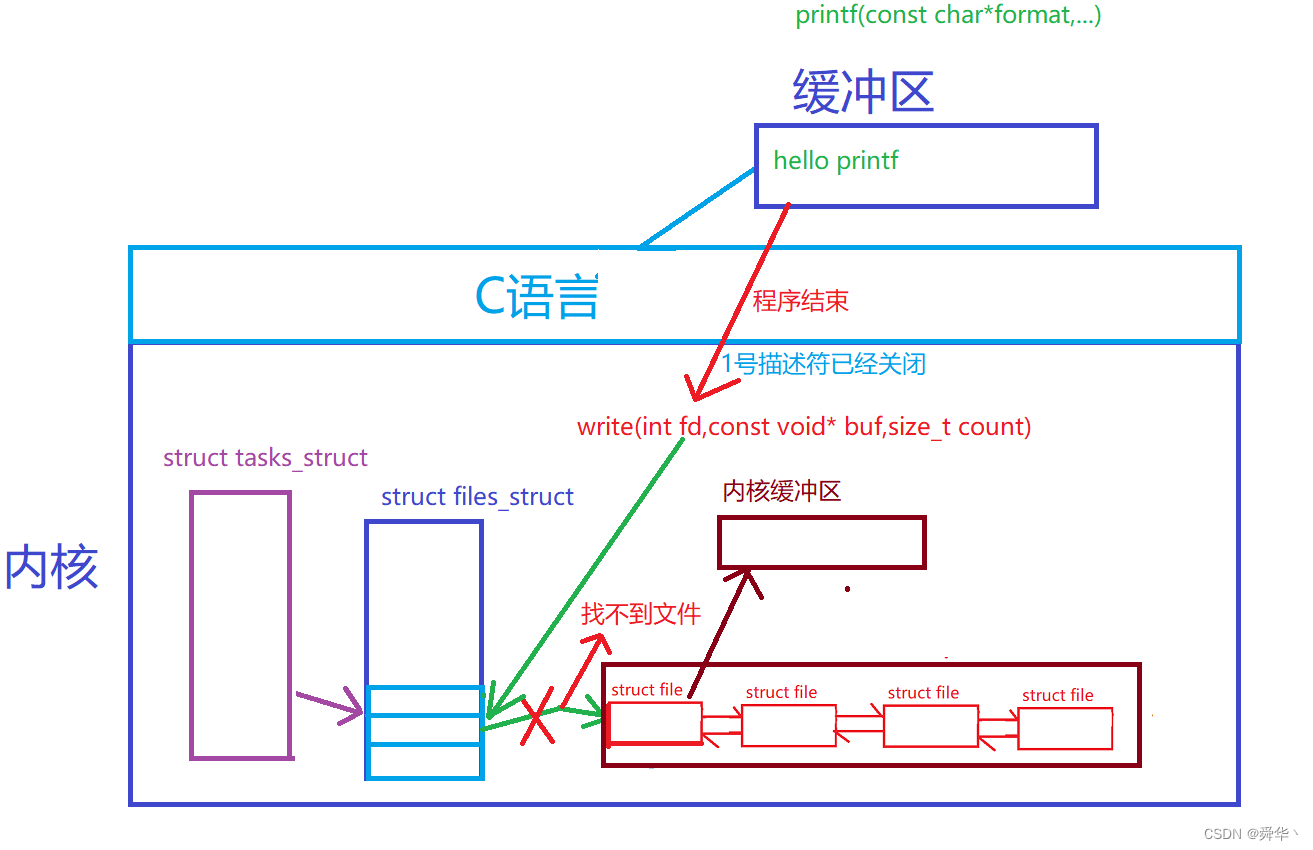
到这里现象想必已经一目了然,那既然这么麻烦,我们为什么还要为C语言设立这样一个缓冲区呢?
解释:
- 我们在用系统调用进行刷新时,是将内存刷新到文件中的,而C语言比系统调用多做了一步——将数据格式化,即变为字符串,变成字符串之后再写入文件,那人就能够看懂了!
- 这样做可以提升磁盘的读写效率,就好比开快递公司,租一辆飞机进行空运快递,肯定是一批快递进行空运,而不是一个快递进行空运,肯定是一批效率高,而不是一个效率高。类比一下C缓存区存放就是快递,而刷新函数就是那辆飞机,目的地是磁盘。
其次存放快递的我们一般之为快递站,那这个快递站——C缓存区在哪?
- 在FILE文件指针指向的FILE对象中,由FILE结构体对象进行管理。
除此之外,快递有的时候,也分轻重缓急,比如有的快递需要紧急运输,有的快递正常运输,有的快递延迟运输。这就对应了C缓存区的刷新方式。
2.刷新方式
- 无缓冲刷新——直接刷
此处我们需要回顾一下刷新缓存区的接口:
头文件
#include <stdio.h>
函数声明
int fflush(FILE *stream)
返回值:成功返回0;失败返回-1并设置错误码。
- 简单使用
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{printf("hello printf");//向stdout 输出hello worldfflush(stdout);//立即刷新。close(1);return 0;
}
现象:

- 行刷新 —— 遇到 \n 再进行刷新(显示器)
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{printf("hello printf\n")close(1);return 0;
}现象:

- 全缓冲 —— 缓冲区满了再进行刷新。
示例:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{FILE* f_ptr = fopen("test.txt","w");int fd = f_ptr->_fileno;const char* message = "hello";int n = 1;while(n <= 1000){fprintf(f_ptr,"%d %s ",n,message);n++;}close(fd);return 0;
}
我们可以看到:

这里在写入第831次时,缓冲区满了,再进行刷新的,除此之外我们可以看出缓存区还是不小的。
其次我们来验证一下文件刷新的方式,上述只是把缓存区撑满了,再刷新的,这里我们试着一边向文件写入一些行刷新的内容,一边看文件中是否有内容进行验证。
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{FILE* f_ptr = fopen("test.txt","w");const char* message = "hello\n";fprintf(f_ptr,"%s",message);sleep(1);fprintf(f_ptr,"%s",message);sleep(1);fprintf(f_ptr,"%s",message);sleep(1);return 0;
}
我们在运行程序的同时,再开辟一个监视窗口用以下脚本打印信息:
while :; do cat test.txt; sleep 1; echo "---------------"; done
现象:
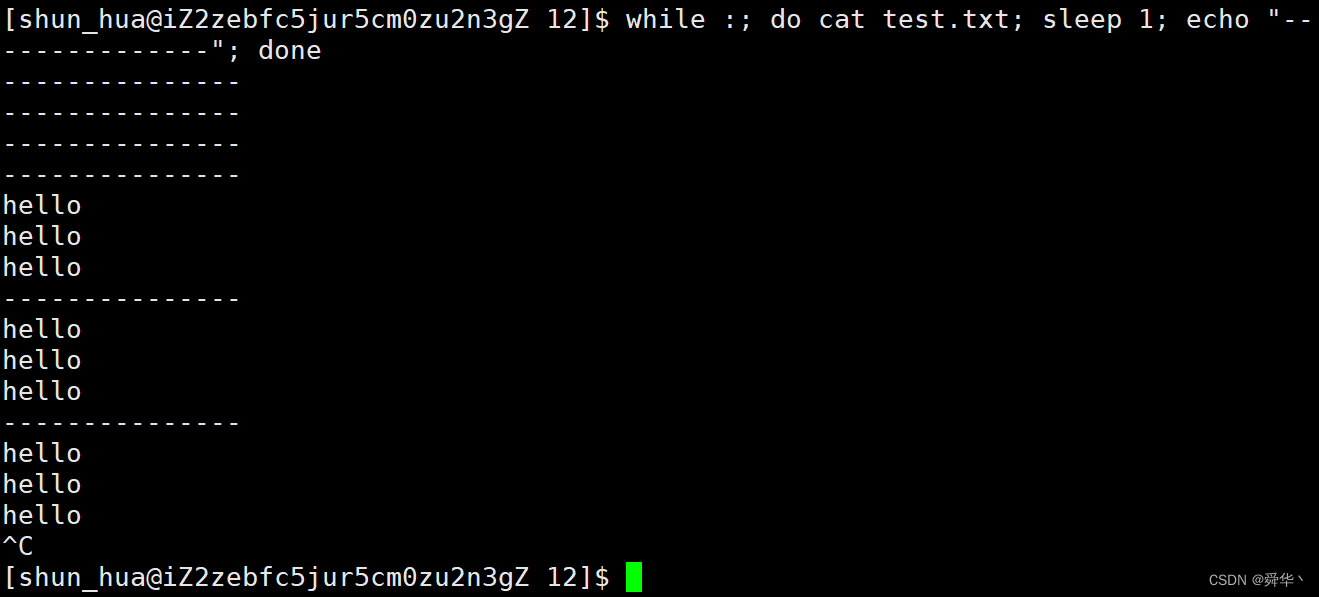
- 由前几秒都没有内容输出,可见文件是全缓冲进行刷新的。
拓展:
思考下面代码的打印结果:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{printf("hello world");//向stdout 输出hello worldfork();return 0;
}
结果:

解释:
- 此处创建了一个进程,父子进程数据在创建后共享,但会发生写时拷贝。
- 缓存区也是数据,在程序关闭时会自动进行刷新,因此父子进程发生写时拷贝,各刷各的互不影响。
四.文件系统
1.磁盘结构
当前我们就来解决一个问题:磁盘如何查找文件?
我们从硬件出发,慢慢过渡到软件。
- 我们当代的文件一般都存在硬盘当中,而硬盘一般我们用的计算机现在都使用的是固态硬盘,但是企业在存储一些大型数据时为了降低成本,一般使用的是机械硬盘。
- 固态硬盘
- 机械硬盘


- 机械硬盘的结构比较便于理解,我们就从它入手,先看这一张图片:

分析:
- 磁盘(盘面):用于存储文件信息,二进制信号,一般有多个磁盘。
- 磁头:用于寻找文件,其与磁盘的距离很小,一般有多个磁头,与磁盘对应。
- 主轴:方便磁头进行定位。
补充:机械硬盘
- 造价低,寿命长。
- 制作环境要求高。
- 马达与磁盘转动声音可能较大。
- 磁盘与磁头一一对应,且不接触,通过空气与电进行写入信息。
抽象出来的逻辑结构是这样的:
- 正面图
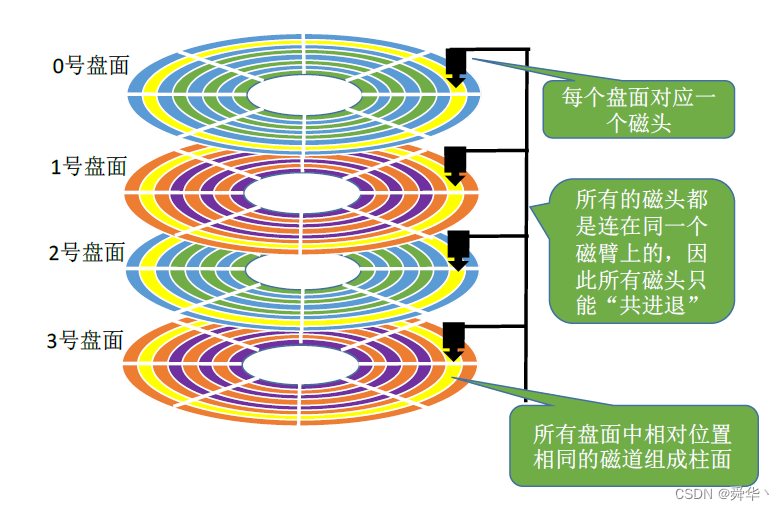
- 所有磁头共进退。
- 柱面:盘面的相对位置相同的磁道形成的立体结构。
- 俯视面
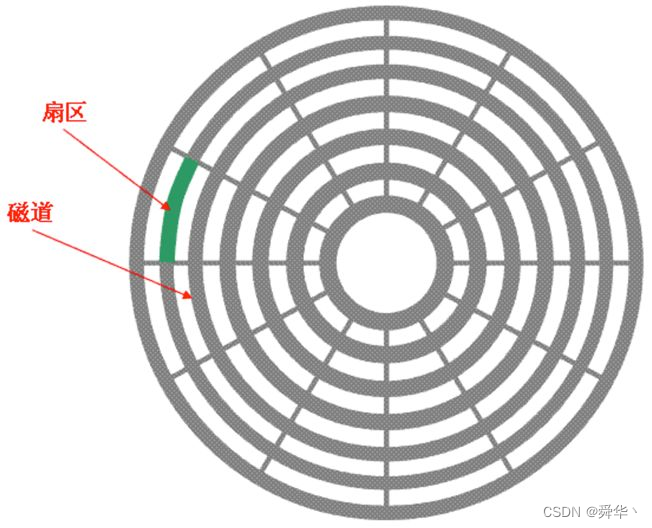
- 磁道:就是磁盘的同心圆的一周。
- 扇区:就是对磁道进行划分的一段,一般为
512byte / 4 KB且扇区是磁盘访问的基本单位。
- 到这里我们应该能大致看出磁盘是如何找到文件的。
解释:
- 第一步:先定位磁盘盘面/磁头(所有磁头共进退)。
- 第二步:再定位磁盘的磁道。
- 第三步:定位磁盘的扇区位置。
硬件大概清楚了,那么接下来我们就来谈谈软件层是如何定位的吧。
首先,得先对磁盘进行行管理,如何管理呢?
-
先来联想一下,我们小时候英语听力的磁带。

-
当我们用复读机进行读取数据时,数据存放在磁带当中进行读取。
-
再回过头来看机械硬盘,如果把磁带的宽度变成0不也是一样吗。
因此我们可以抽象出这样一个线性的磁盘:

但是一般来说,磁盘的容量太大,比如有1000GB,我们还需要,把这1000GB再进行分成若干个单位进行管理,假如分为256GB为一个单位。既然这样我们如果还觉得256GB还大呢?我们可以再分,直到操作系统觉得不大为止。
- 这种分法体现的是
分治的思想。 - 这里的C盘和D盘就是通过把磁盘进行分块进行管理的。

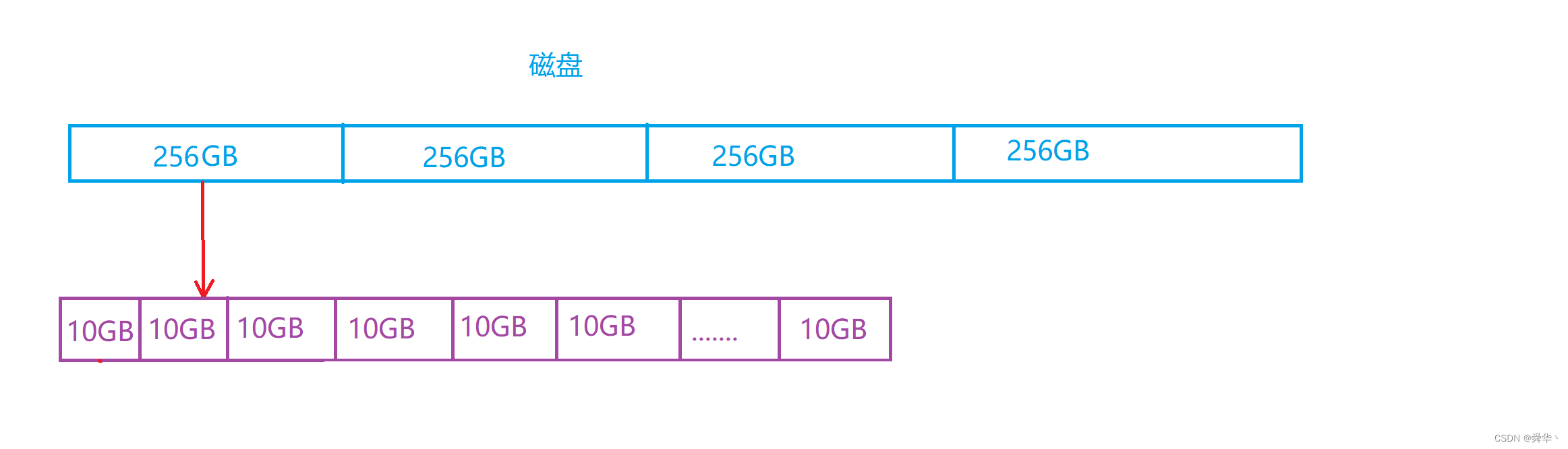
- 与此同时对空间进行切分的同时,也有对应的数组结构对
磁盘,磁道,扇区进行切分,并由在此数据区的编号找到硬件对应的扇区。
假如说,分到10GB能进行管理了,该如何进行管理呢?
对这10GB进行分组,描述组织和管理就是下图的文件系统:
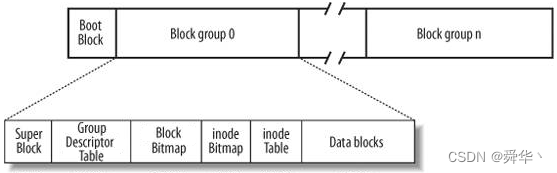
- Block group在开始使用之前,需进行格式化,以便于之后的管理。
这里的innode Table就是存放索引结点(struct innode)的地方,innode存放的是文件的属性,比如说文件的编号,文件的权限,文件的大小,文件的时间信息,还有文件的数据区(Data blocks)。
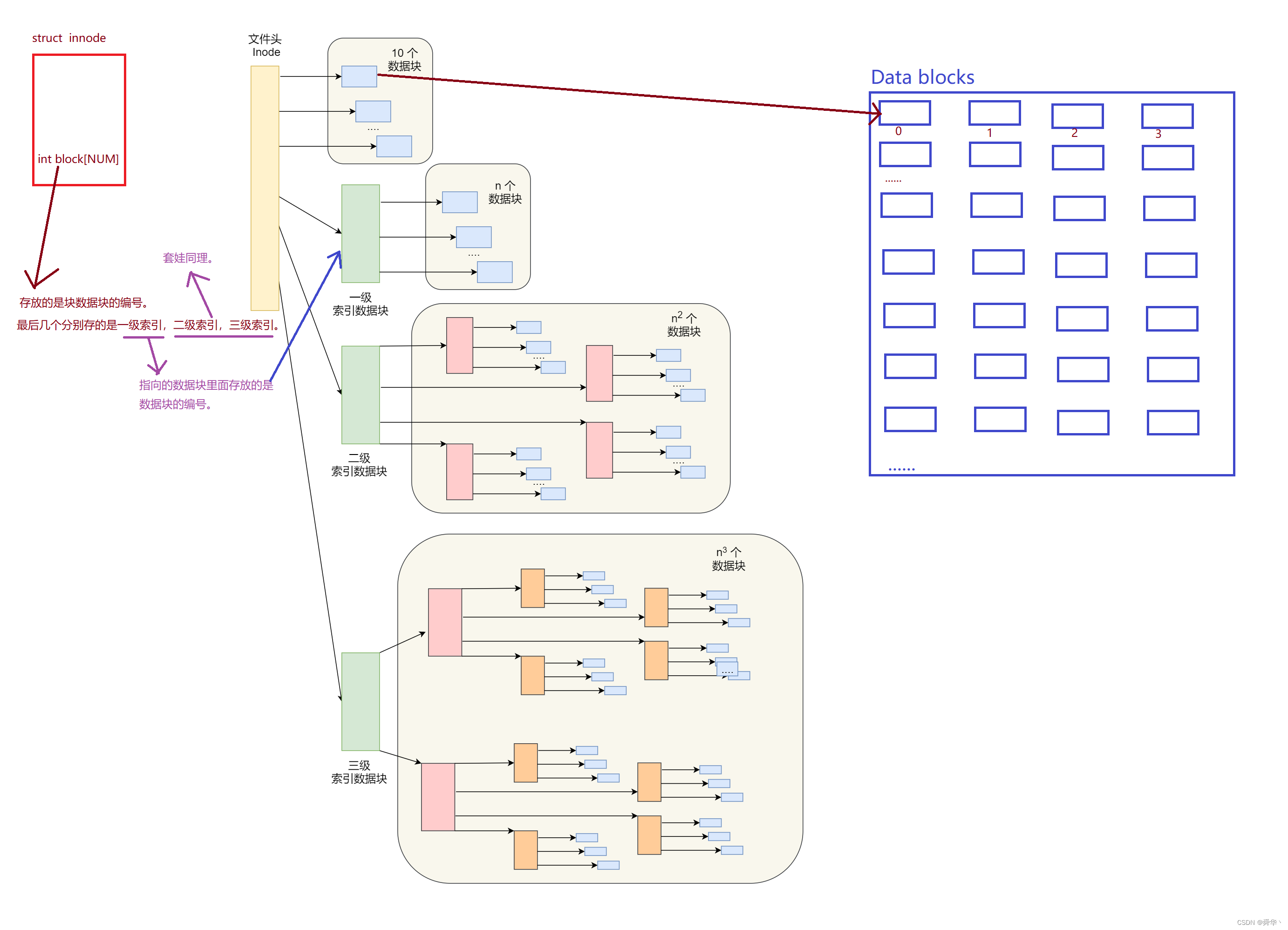
innode有128字节,且innode有唯一的编号。- 文件是通过innode编号进行查找文件的,而不是文件名。
- 如何存储数据呢?
Data block里面存放的是数据块,即用来存放的数据。且每个数据块大小为4KB。
图解:
- 如何删除数据呢?
- 通常我们都知道下载很慢,但删除很快,这是为什么呢?删除文件就意味着这个文件不在了。因此判断在不在,用位图的数据结构查找起来很快且很省内存。
因此:
- 这里的innode Bitmap表示的是innode对应文件是否有效,可以快速删除文件。
- 这里的Block Bitmap表示的是所对应编号的数据是否被使用,可以标记数据块的使用情况,以便于删数据。
拓展:
- Boot Block(引导块)是指存储在存储设备起始扇区的特定区域。通常包含引导加载程序(boot loader),用于启动操作系统。
- Super Block(超级块),通常记录文件系统类型、大小、状态、块大小、inode(索引节点)数量等关键参数。
3.Group Descriptor Table(组描述符),记录的是数据块与innode的使用情况,位图的存储位置,目录以及其它文件信息。- 一级索引的原理为,指向的4KB,即4096byte存放的又是数据块的编号,假设编号类型为int 4字节,可以指向1024个数据块,也就意味着4KB就可管理 4MB的内存。
2.再识目录
之前我们对目录从权限的角度进行了如下解释:
- 没有x权限,目录无法进入。
- 没有r权限,无法查看对应的文件。
- 没有w权限,无法创建新文件。
- 结合我们刚学的:文件是通过innode编号进行索引的,而不是通过文件名进行索引的,且结合常识文件是在目录下进行创建的。
由此我们可以得出如下结论:
- 目录必然存放着innode编号,且与文件名进行映射。
- 文件名是key,innode是val,且在目录下进行索引时不能存在同名文件,因为存在二义性。
- 所谓的r权限,其实就是查看文件名对应的映射。
- 所谓的w权限,其实就是在目录中添加对应的文件名与innode的映射关系。
- 那目录也是文件,其文件也是文件名形式存在,也要进行查找其对应innode,才能找到其目录文件下的innode,如何进行查找呢?
- 递归向上进行查找,找到根目录就进行停止,因为根目录的innode是确定的。
- 为了提升查找的效率,可以借助环境变量,直接索引,也可进行缓存将可能要访问到的目录的路径进行提前的加载。
3.软硬链接
- 软链接(符号链接)
简单使用
ln -s 【指定文件】 【目标文件】
- 对普通文件软链接
对指向文件进行删除:
此时变成了悬空链接,即指向的文件失效了。


- 对目录软链接
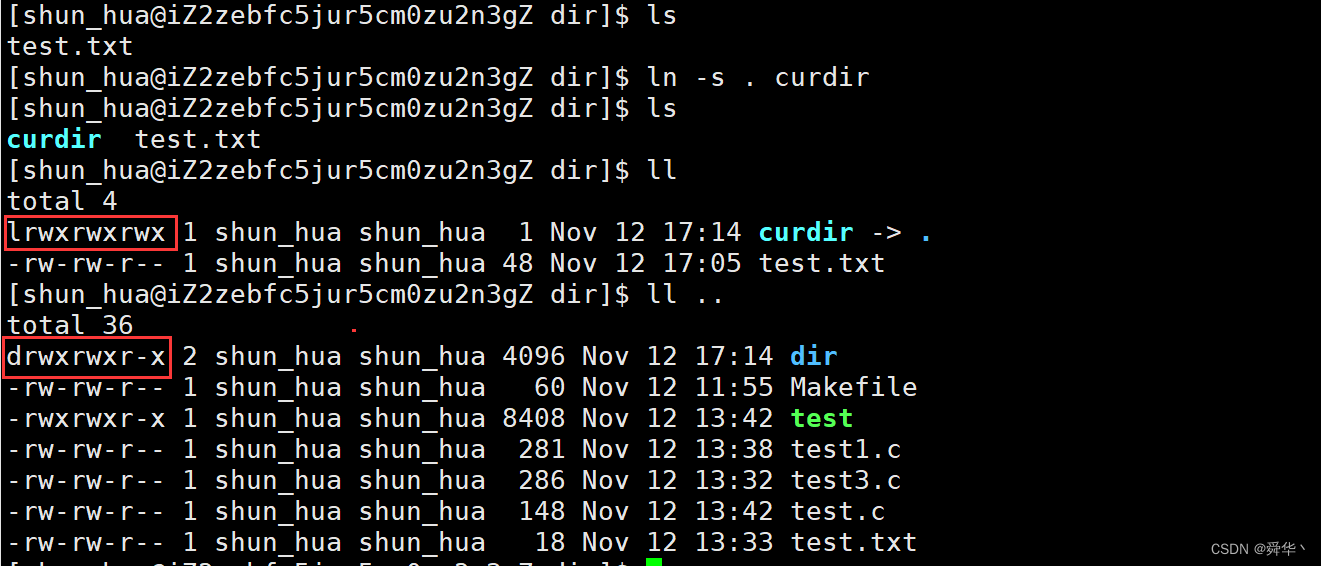
- 总结:软链接产生的只是一种快捷方式,和指向的文件并没有必然的联系,且权限也不相同,而且删除指向文件会使指向文件的快捷方式失效。
- 补充:软连接只是对路径文件名产生的链接,假如再删除再在原目录下创建相同的文件,软连接也能执行,只不过不是相同的文件。
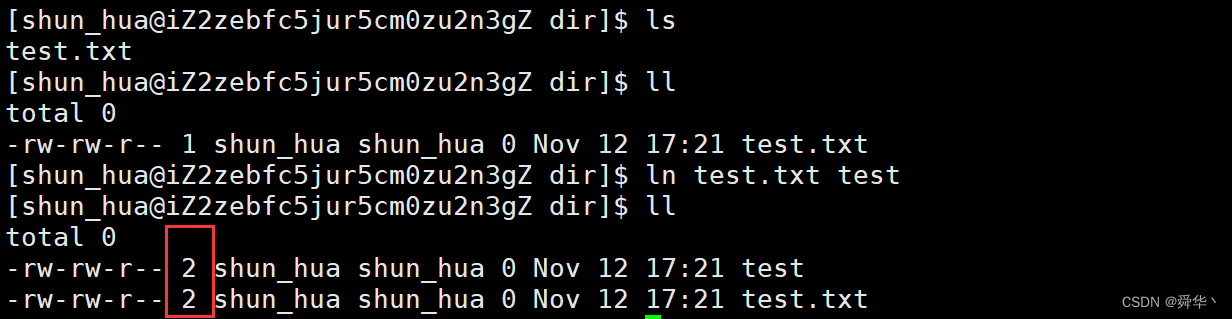
- 硬链接
简单使用
ln 【指定文件】 【目标文件】
- 普通文件
- 可见这里的1变为了2,这里的数字就指向文件的引用个数,简称硬链接数。
- 目录
问题: 为什么不能对目录硬链接呢?
- 其实很简单,假如你要找find某个文件,此时你在某个路径下对上面的一个目录进行硬链接,此时你进入目录时,就避免不了查找硬链接的目录,一旦你查找对应的目录,此时就陷入了死循环。
- 补充:在目录下的 . … 这些文件系统是不会查找的,因此一般查找时不会陷入递归。

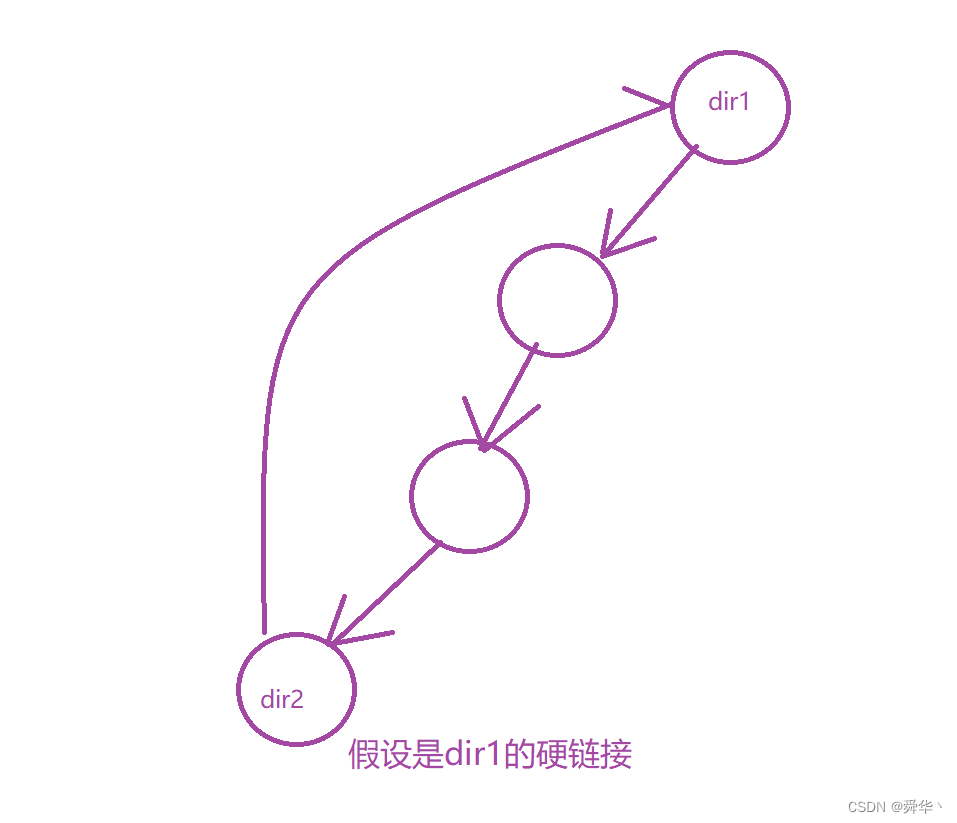
- 总结:硬链接是一种引用,不同文件名指向同一个文件,即拥有相同的inode,且在删除时如果硬链接数大于1,则只需将硬链接数减减即可。
删除链接(也可删除文件):
unlink 【指定文件】
4.物理内存
- 文件如何组织与管理解决了,那文件是如何加载的呢?
- 首先文件要被访问,不能直接在磁盘中访问,这样速度太慢了。
- 因此文件要首先加载到内存中,才能被高效的管理。
因此问题就转换为了:文件是如何被加载到物理内存的?
谈到这里我们就要普及两个概念:
- 页帧(Page Frame):页帧是物理内存(RAM)中的一个固定大小的区域,用于
存储从辅存(如硬盘)中调入的页面内容。操作系统使用页帧来管理物理内存,将页面映射到这些页帧上。- 页框(Page Frame):页框通常指的是在内存管理单元(MMU)中用于存储页面表的一组连续条目。页框包含了用于地址转换的页表项,以便
将虚拟地址映射到物理地址上的对应页帧。
- 总之,页帧就是
管理物理内存的,用于加载硬盘内容,页框是管虚拟地址与物理地址映射的。
那物理内存又是如何被管理的呢?
- 先描述,抽象出具体的属性,再组织,用数据结构的形式进行管理。
- 比如物理内存都有地址,空间大小,是否被使用等基本信息,因此可以通过结构体进行描述,再用结构体数组进行组织,进而管理整个物理内存。
- 因此在Linux系统中,通过struct page arrary[SIZE],这样进行管理内存,每个page管理4Kb的内存,且这个数组所占的内存必然不会太大,否则会影响其它进程,因此这个数组内部采用的是联合体的形式。
- 因此,对物理内存的使用变为了对page数组的管理。
总而言之:
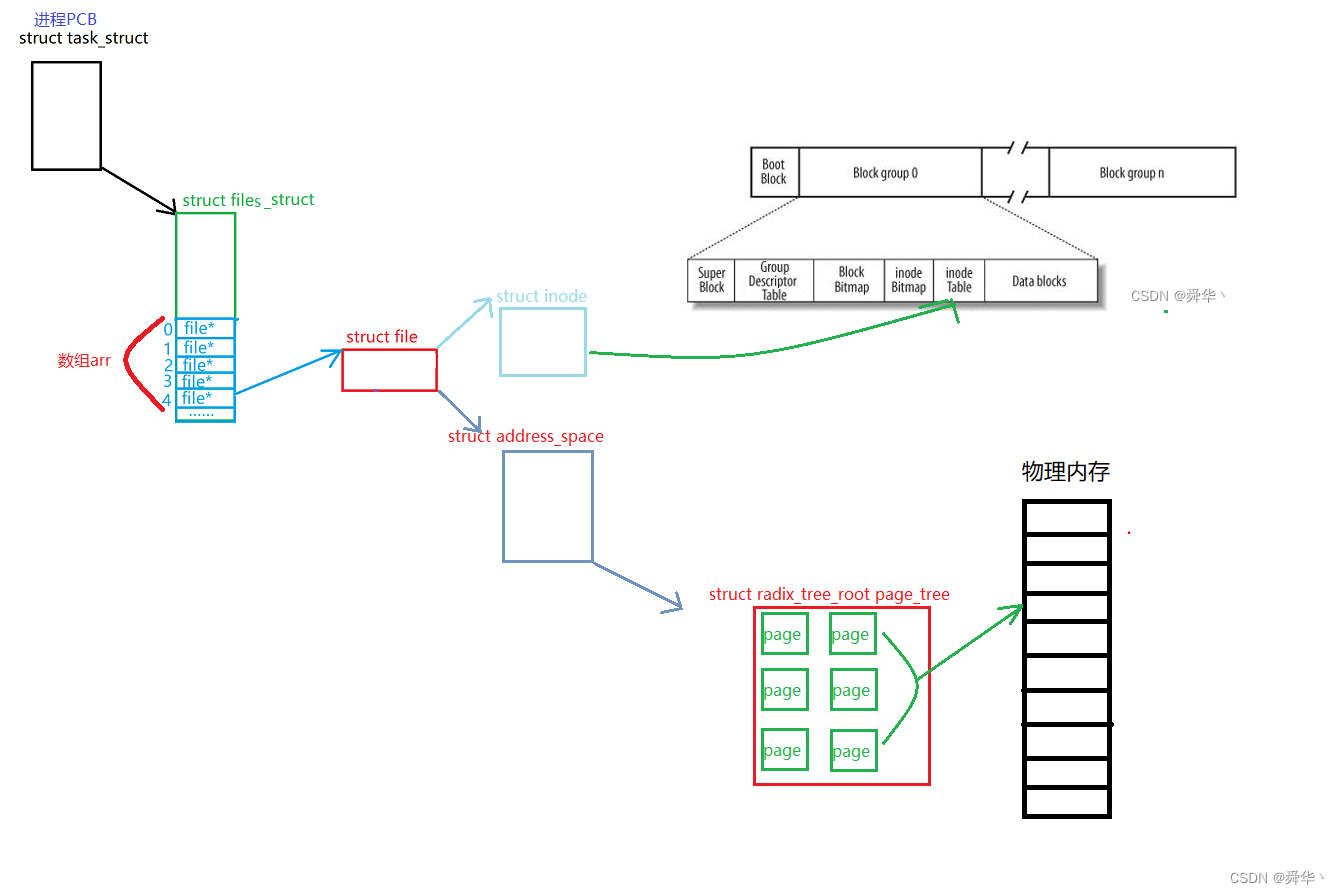
- 打开文件分为找文件和加载文件到内存两步。
- 找文件。通过文件系统对磁盘进行管理,其中的inode可以帮我们找到磁盘中文件的定位。
- 加载文件到内存,找到文件之后,通过page数组进行申请空间,通过页帧加载磁盘文件内容到内存,且页框进行物理与虚拟的映射,从而将文件加载到内存。
注意:这里文件系统的Data blocks,是磁盘中的数据,这里的加载的文件是到内存中去了。
图解:
- 拓展
问题1 : 为什么文件要按照4KB的形式,从磁盘进行加载?
- 局部性原理,下次可能会使用其周围的数据,这样做可以减少外设的访问次数。
- 外设与内存简直就不在同一个量级,可以理解内存像火箭,外设就像汽车,虽然汽车对我们来讲也算快的,但是有更快的火箭,火箭可不想等汽车,因此需要4KB进而一步到位。
问题2: 4KB是如何得到的?
- 大量的科学家进行实验,具体可看学术论文。
问题3 : 大量的IO请求,系统如何进行处理?
- 系统会进行排序(按照盘面,磁道,扇区的优先级),然后一次性的进行处理。因此断电很可能会导致数据的丢失,不管是在系统层面还是在语言层面。
- 总结重点
- 文件描述符的原理,系统接口与C接口的参数,以及相关细节。
- 文件重定向的原理,接口使用,stdin与stderr的一点区别。
- 深入理解文件缓存区,以及刷新方式。
- 文件系统,从磁盘到内存到软件,理解文件的查找与加载,软硬链接。
尾序
如果觉得文章有所收获,顺手点个赞鼓励一下吧!






![文件上传 [ACTF2020 新生赛]Upload1](https://img-blog.csdnimg.cn/7614308207a84c67b39d215a4a7986e5.png)