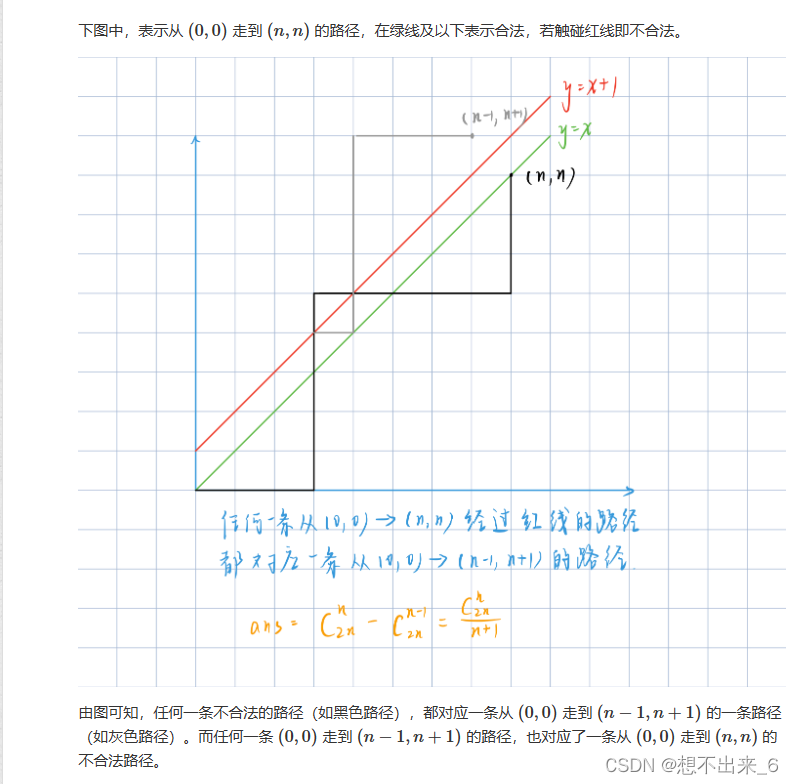
在火山引擎相关的业务中绝大部分的机器学习和数据湖的算力都运行在云原生 K8s 平台上。云原生架构下存算分离和弹性伸缩的计算场景,极大的推动了存储加速这个领域的发展,目前业界也衍生出了多种存储加速服务。但是面对计算和客户场景的多样性,还没有一个业界标准的存储加速实践,很多用户在做选型的时候也面临着诸多困惑。我们在火山引擎上构建了云原生的存储加速服务,适配机器学习和数据湖的多种计算场景,致力于给业务提供简单易用的透明加速服务。本次分享将结合我们在火山引擎上的业务实践分享对于存储加速的经验总结和思考。
火山引擎大数据文件存储技术负责人-郭俊
云原生存储加速诉求

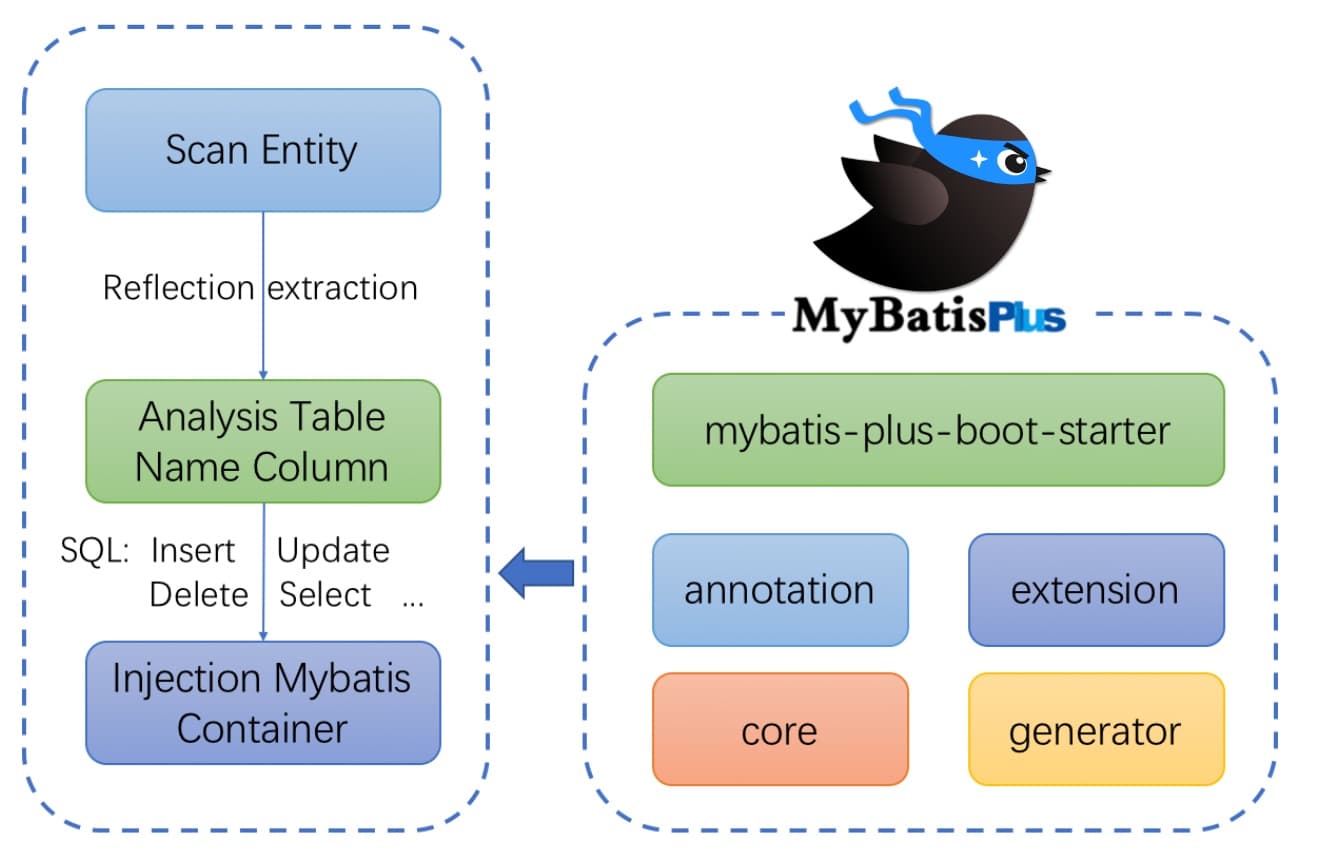
云原生业务基础服务主要可以分为三部分:计算、存储和中间件。
-
顶层是计算业务,大部分都是基于 K8s 底座运行的。在计算底座基础上会进行一些大数据任务以及 AI 训练任务,再往上就是各种各样的计算框架。
-
底层是存储服务,目前来看存算分离是业界未来的趋势,对于云上一些标准的存储服务,可以分成以下三大类:
-
第一类是对象存储,主要以 AWS S3 为标品,各个云厂商在标准能力基础上也都有一些创新服务;
-
第二类是 NAS,传统的定位是一个远程的文件存储,现在各个云厂商基本上也都有标准的 NAS 存储产品;
-
第三类是各种并行的文件系统,称为 PFS,它的设计初衷是支持传统的企业 HPC 场景,能够支持大并发和大吞吐的数据读取。现在在云上主要用来支持大规模的 AI 训练场景。
-
-
中间层是各种存储中间件。因为存储天生的本地性限制,很多时候无法配合计算业务做大规模并发或者弹性调度。所以业界在整个计算业务和存储服务之间,又推出了一些存储和加速的中间件。比如 ALLUXIO 就是一个典型的存储加速的代表,另外 JuiceFS 本身也有很多缓存和加速的能力。存储加速在本质上还是为了给计算业务提供更好的弹性读写的能力。
痛点
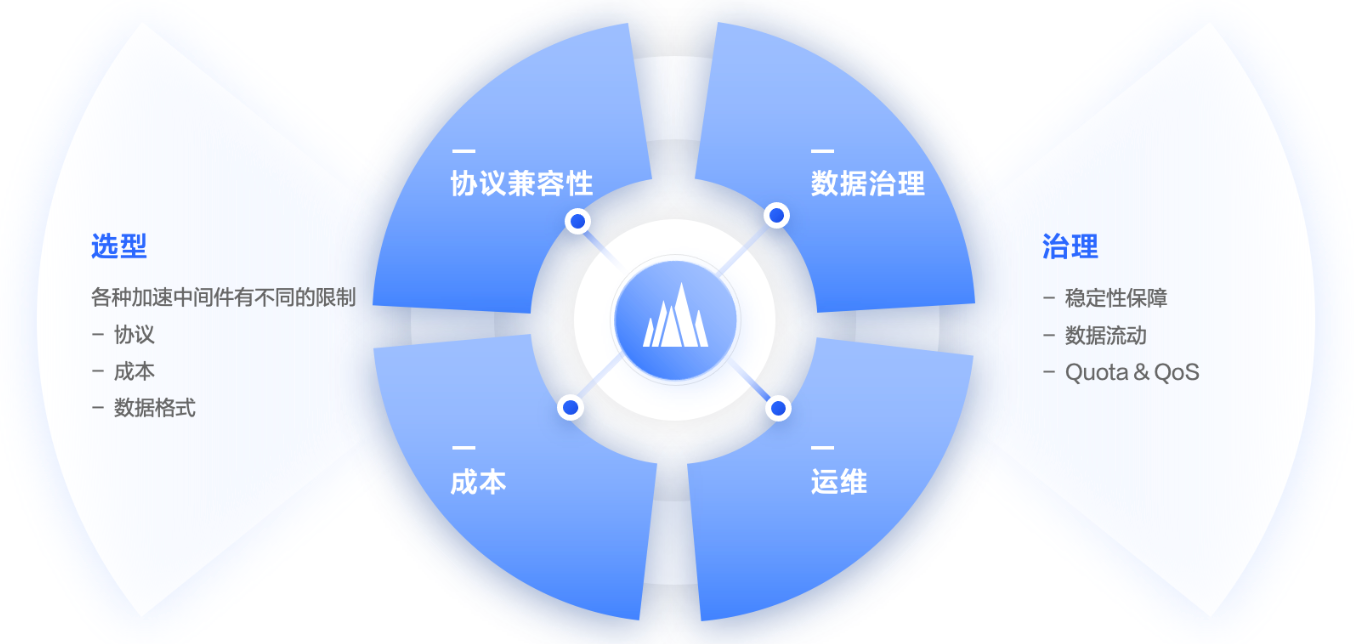
从业务视角来看,存储和加速存在如下痛点:
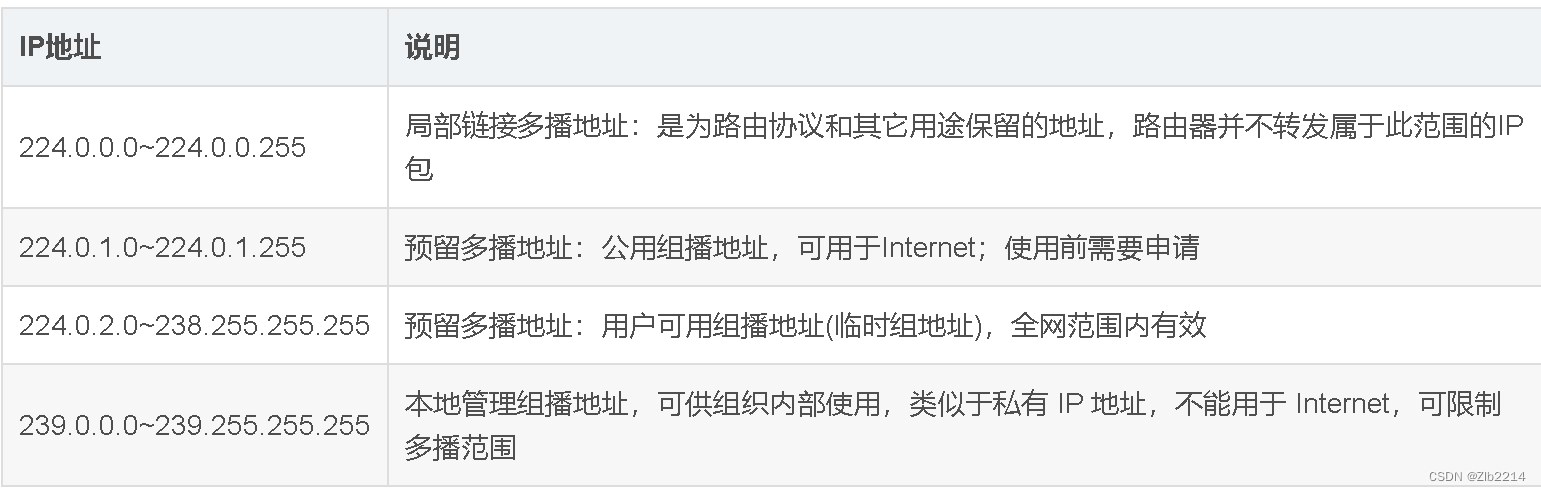
第一个痛点是选型。因为各种加速的中间件没有业界统一的标准,每个中间件都有一些不同的限制。对于该痛点可以通过以下几个视角去看,首先是协议的兼容性,中间件产品对业务呈现怎样的协议,是对象存储协议,还是部分兼容 POSIX 的协议,还是有100% POSIX 协议;另外,成本模型的差异,同等加速带宽需要付出的成本价格;第三个是数据格式,存储底座的数据格式和数据目录是要透传给业务,还是在中间件重新组装和转换。
第二个痛点是中间件产品的治理。对于存储加速的中间件产品,应该怎样去做运维和稳定性的保障,在底层存储服务之间的数据流动,以及quota和qos的管控方面,有没有一些能力的支持。
常见方案

上图是当前业界常见的存储加速方案。
-
第一个是对象存储+Alluxio,不足之处是 POSIX 的兼容性受限。POSIX 的兼容性主要受限于对象存储本身的能力,没有办法支持原子目录的 Rename、目录删除以及随机写、覆盖写、追加写等功能。优势在于整体的成本相对还是比较廉价的,因为是基于对象存储,且 Alluxio 本身是一个透明的数据格式,在对象存储上看到的目录结构和数据都可以直接呈现给业务。
-
第二个方案是对象存储+JuiceFS。这个方案比较大的一个优点是整体的 POSIX 兼容性是非常优秀的。整体的成本也比较廉价的,因为它很多时候会用到一些计算机上的本地盘作为缓存加速的介质。需要注意的是它的数据格式是私有格式,因为数据存储在对象存储上是会切块的,所以从对象存储上看不到完整的文件。这一方案的治理成本因人而异,如果所有的业务都是基于 JuiceFS 服务进行的话,几乎不需要治理成本。但是如果要在 JuiceFS 和其他存储服务做一些数据流动的话,就会需要进行很多治理工作。
-
第三个方案是基于各种并行文件系统的服务。优点是 POSIX 的兼容性好、数据格式透明、治理成本低。但是由于使用了一些高性能的组件,在业界的价格相对是比较昂贵的。
-
最后一个方案是,各个云厂商都推出了对象存储与 PFS 结合的能力,愿景是冷数据存放在对象存储,热数据在 PFS。但实际的业务体验并不是很方便,两边的数据流动也需要很多的治理成本。
什么是“好”的存储加速
我们理解的“好”的存储加速应该满足支持透明加速、多协议兼容、可以弹性伸缩、拥有基础的数据治理能力等特性。
透明加速

透明加速的诉求之一是需要对服务化的加速能力做到开箱即用,拥有稳定 SLA 的保障,也可以做到按量付费。另一个诉求是对底座存储的原生协议加速后直接透出给业务,从业务视角可以不需要对代码层面进行修改,仅需要做一些配置上的适配调整就能看到底座存储上原始的目录结构和数据格式。目前无论是云存储还是企业存储,各个存储服务都已经比较成熟了,我们不是要去重新造轮子,只是希望将透明加速能力做好,更好地解决业务上的问题。
多协议兼容

基于对象存储的多协议兼容,需要做以下四个方面的优化:
-
首先是基础加速能力,包括支持 S3 协议、目录树缓存,以及自动回写到对象存储的能力;
-
第二是 Rename 优化,现在很多云厂商都支持了单个对象原子的 Rename 操作,主要是对接到单个对象的 Rename API,在一定程度上优化目录 Rename 的性能;
-
第三是 Append 支持,对接云厂商 Appendable 对象,支持 Close-Open-Append 这种常见的写入模式;
-
第四是 FUSE 挂载,提供 CSI 支持和 FUSE 挂载高可用能力,在 FUSE 进程崩溃重新拉起后还能继续保持业务 IO 的延续性。
而在基于对象存储的这套加速方案上,主要会遇到以下三个问题。
-
第一个问题是 POSIX 的兼容性不足,由于很多机器学习训练作业都是基于标准的 POSIX 文件系统构建的,所以无法基于这套方案运行。
-
第二个问题是如果用户想基于这套架构推进业务,那么很多时候都需要做一些业务层面 IO 模型的改造,这对于算法工程师来说是很难实现的。
-
第三个问题是由于上述两方面的限制,很多用户会把这个方案当成高效的只读缓存进行构建业务,也就限制了这个方案使用价值的上限。
为了解决以上问题,在调研了市场上的相关产品之后,我们决定基于 NAS 来解决 POSIX 兼容性的问题。NAS 作为标准的云存储产品,天生具备完整的 POSIX 能力。通过在加速层适配 NAS 作为存储底座,做好协议适配和一致性保障工作,解决 NAS 产品本身的带宽和性能瓶颈。在成本方面,容量型 NAS 的价格比对象存储要昂贵一点,但整体性价比仍然在可接受范围内。
弹性伸缩
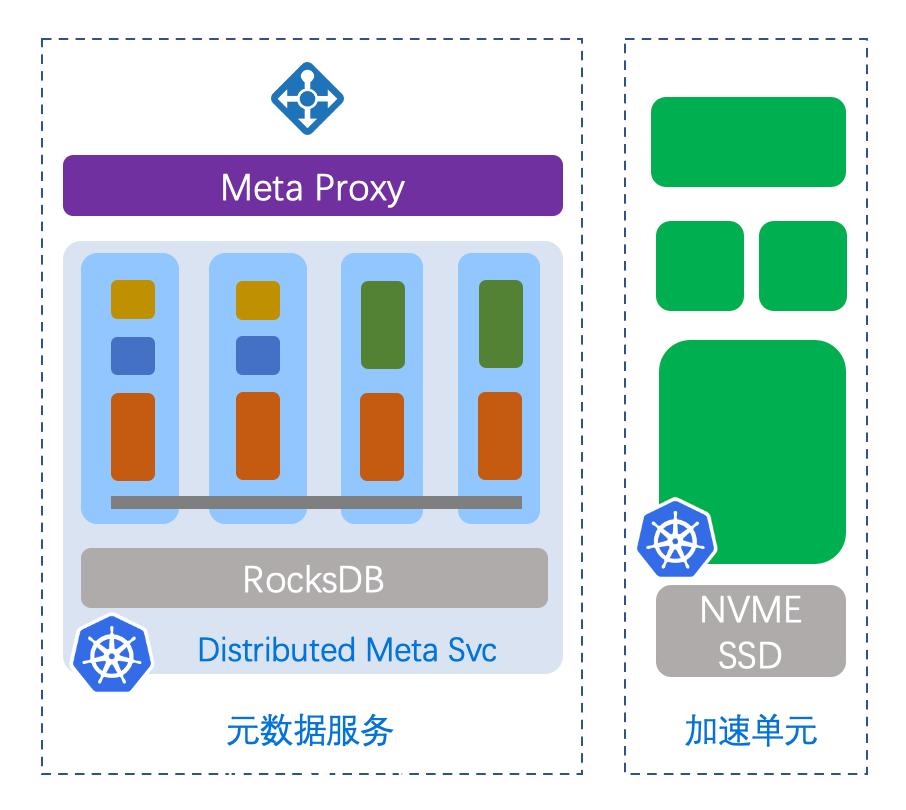
在加速层还需要实现弹性伸缩的能力,加速组件也需要基于云原生的架构,因此整个数据面基于 NVME SSD 进行构建,拥有分布式的元数据,数据面的加速也是基于原生平台构建的。所以无论元数据还是数据面,都可以拥有弹性伸缩的能力。
数据治理
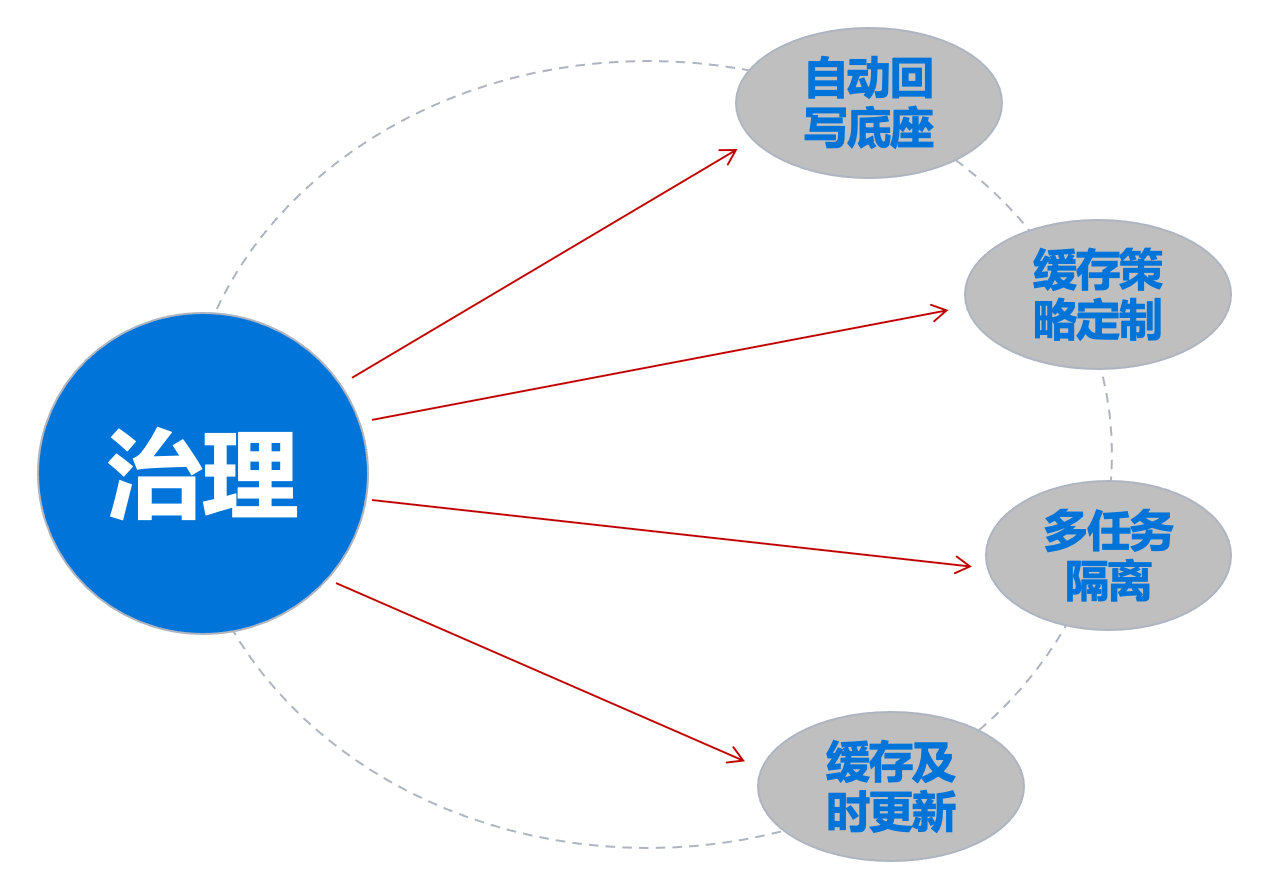
数据治理方面需要以下重要特性:
-
自动回写底座:很多业务在通过加速组件写入数据的时候,非常关心数据在对象存储底座上的可见性,因为会有很多下游业务需要依赖上一个业务的输出文件才能够发起后续的业务。所以我们需要有不需要过多人工干预的、确定性的回刷策略。
-
缓存策略定制:需要更多缓存策略的支持,比如典型的 LRFU、TTL 等,支持业界通用的预热能力的相关机制。
-
多任务隔离:提供一些任务级别的加速保障。
-
缓存及时更新:支持接入对象存储 Event 的主动更新,也支持基于 TTL 机制的被动拉取更新。
CloudFS 加速实践
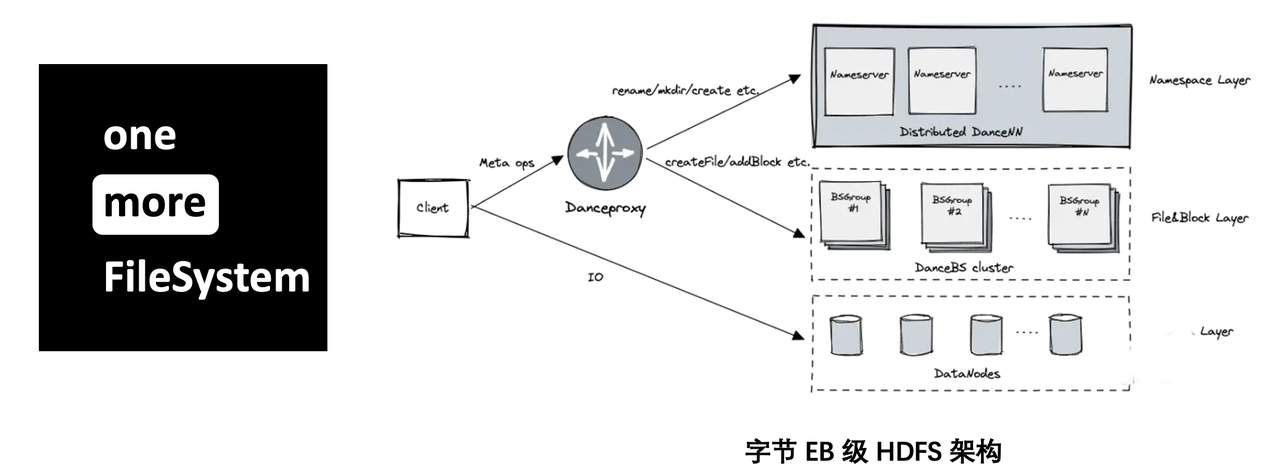
基于字节内部业务对以上存储加速能力的需求,我们推出了一个新的、从字节内部 HDFS 演进而来的 File System 服务,命名为 CloudFS。CloudFS 的整体技术架构与内部 HDFS 架构本质上是同一套组件在云上做的一些产品化、小型化和多租户的封装。
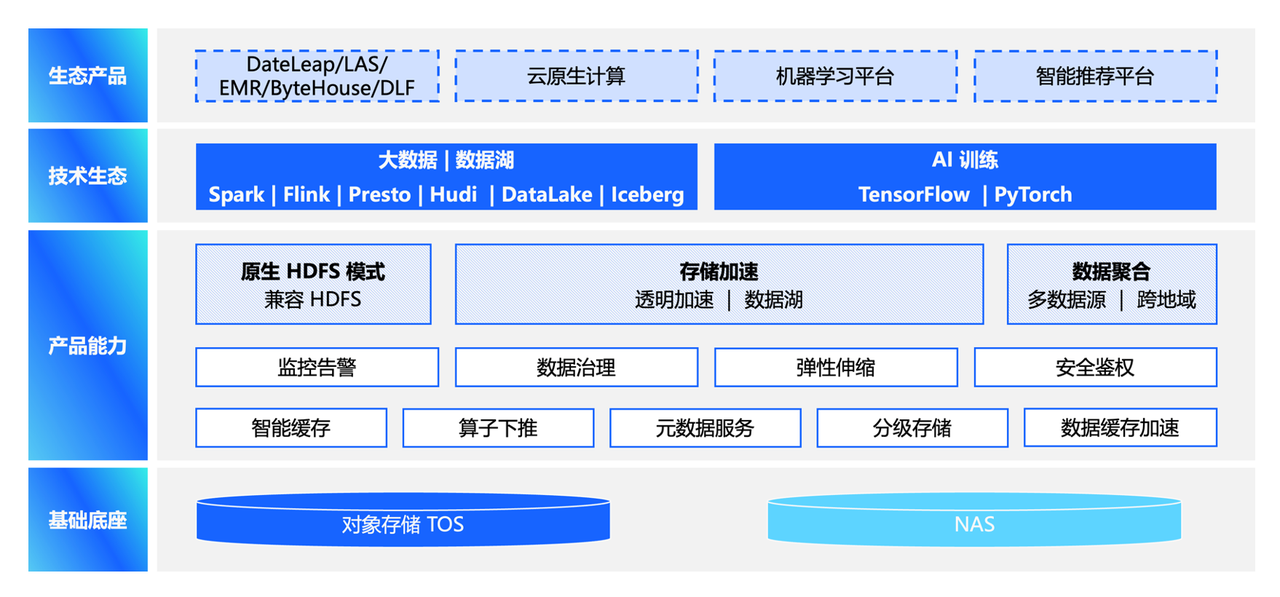
CloudFS 除了拥有存储加速能力以外,也支持原生 HDFS 模式和多数据源聚合的能力。对于底座来说主要支持的还是对象存储,NAS 底座目前还在适配开发阶段,在上层业务上对接了大数据和 AI 训练的各个生态及火山引擎的一些技术产品等。
元数据加速

上图示例中从训练容器的视角能够看到 dataset 里面有两个对象。dataset 目录树结构的视图与最底层的对象存储的目录结构视图是一致的。最基础的技术特性是需要缓存对象存储的目录结构,并且按需拉取。在元数据服务里面,复制了对象存储的目录树结构,但是是用目录树层次结构的方式存储的,而不是对象存储的平铺目录结构。另外,我们订阅了对象存储的事件通知用于支持主动更新,主动的事件通知和被动的按需拉取尽可能保证了整个元数据的一致性。另外,同一个 Bucket 被挂载了多次就可能会存在重复的 Object,我们在元数据层面对同一个 Object 做了去重,最大化缓存空间利用率。
数据面缓存
接着介绍一下整个数据面的缓存。我们把对象切成多个数据块,每个数据块可以有多个 Replica,如上图中的 r1、r2 就是同一个数据库的两个 Replica。数据面缓存策略是比较懒惰的,只有当用户数据第一次访问的时候才会把数据捞上来;同时会支持一个自适应的副本数,根据整个副本的业务负载以及当前缓存节点的业务负载去支持自适应的副本数,所以副本数可以根据业务的压力值进行自调节。在缓存管理策略上,采用了 ARC 缓存算法,可以保存更多的数据,确保热点数据能够保留在缓存里面。
另外我们也支持了预热机制,因为很多用户在跑作业之前,需要将其数据全部保存在缓存里面,这样在后续启动作业的时候就不需要等待的开销。在具体的预热方式上是基于 P2P 协议做的一个大规模预热副本的分发。对于写缓存来说,拥有一个多副本的写缓存机制,可以异步/同步地回写到底座上。比如一个 Block 写完之后会立刻将其刷新到对象存储上,但是对于对象存储的对象来说,关闭这个文件的时候才能够看到这个底座上的文件长度或内容的更新。
FUSE 业务入口改造
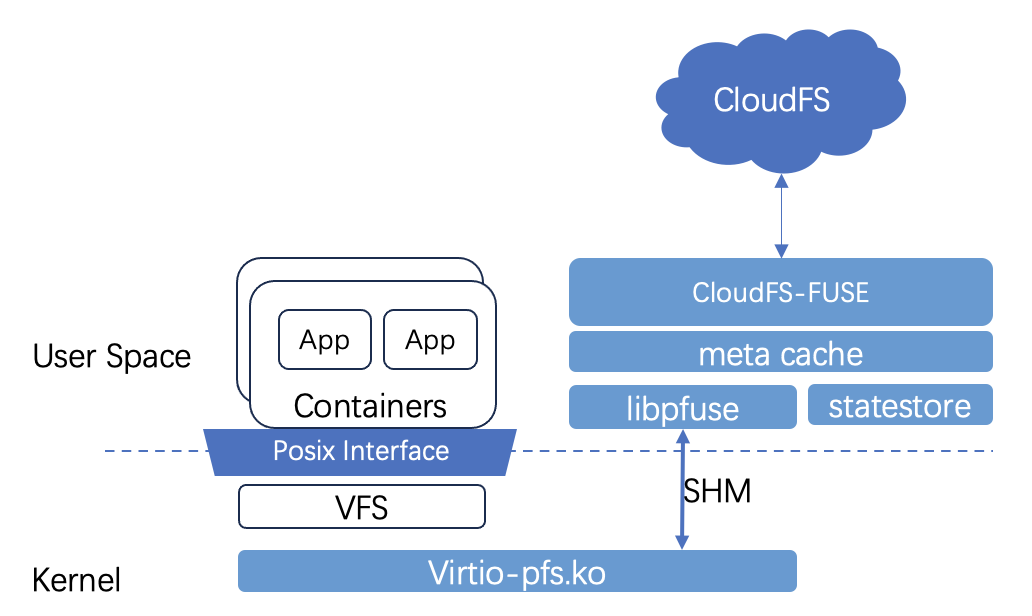
我们对 FUSE 入口做了一些改造来提升其稳定性。首先是 FUSE virtio 的改造。替换了/dev/fuse,使得性能得到了很大的提升。同时对于 FUSE 进程做了一定的高可用保障,在 FUSE 崩溃重启后,可以实时恢复到之前的状态。所以对于业务 IO 来说,它可以感受到一点卡顿,但是它的上层不会挂掉,还可以继续跑。有很多训练作业是一次性要跑很长时间的,所以对训练作业的稳定性还是有比较大的收益。另外 FUSE 也支持 Page Cache,最大化利用系统的内存资源。最后一个特性优化是同步 close 文件,因为 FUSE 原来的基于 /dev/fuse 的这套方案,在 close 文件的时候,它真正 close 底层的文件是异步的,我们在此基础上做了同步 close 文件的支持,这样可以更好地确保文件的可见性。当然了这部分改造需要先安装一个内核模块,所以目前在火山操作系统里面,默认标准的 veLinux 操作系统都已经内置了,如果是其它系统,可能需要去安装一些模块才能开启这个功能。
业务实践—AML 平台训练加速
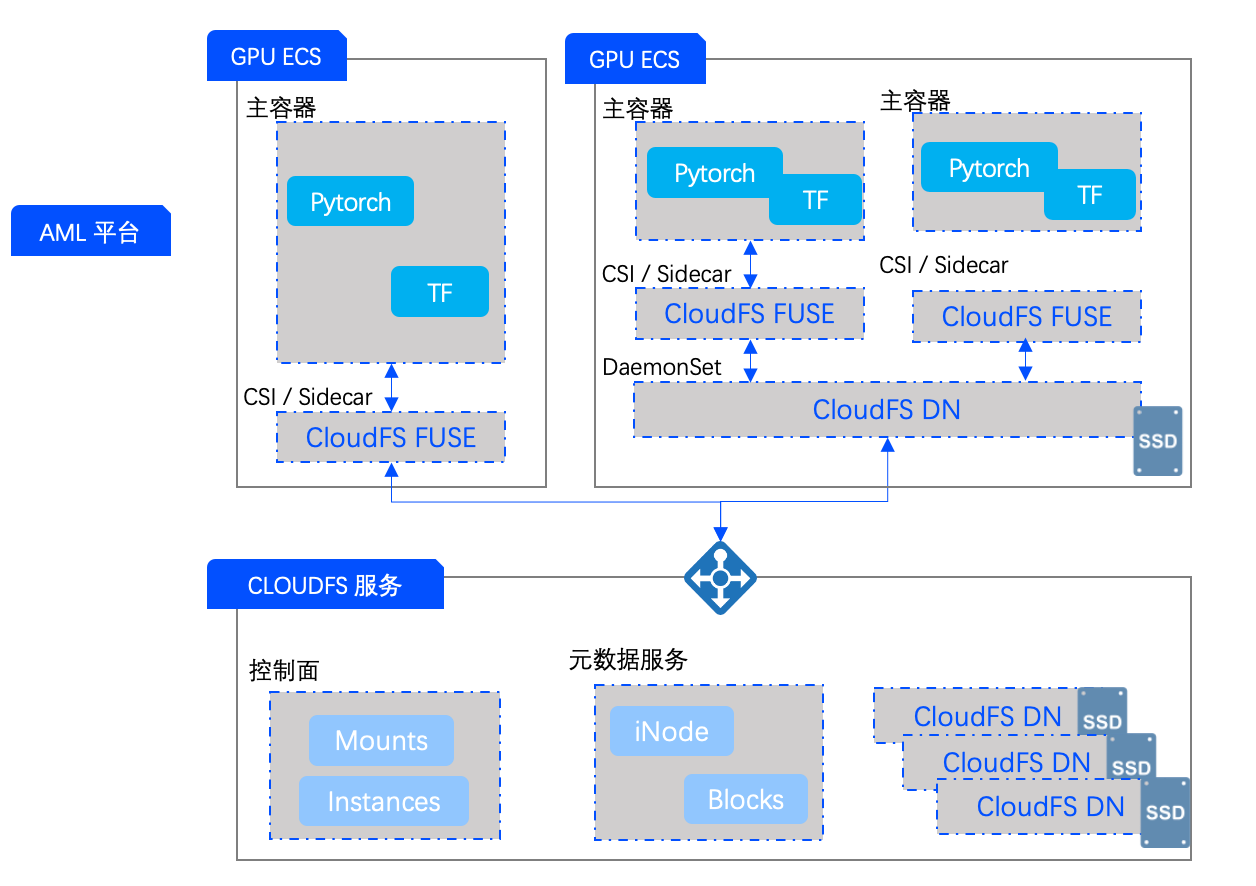
在对火山引擎 AML 平台的训练加速实践中,因为 GPU 机器型号较多,有的有本地盘,有的没有,所以对于没有本地盘的训练场景,需要提供一些服务端加速存储空间的支持;而对于有本地盘的机型,则需要把加速 GPU 机器上的本地盘进行接管。所以对于加速单元 DataNode,本质上是一个介于半托管和全托管之间的形态,很多时候是混合使用的场景。
所以我们在 CloudFS 服务端,构建了控制面和元数据服务,也可以支持加速单元 DataNode。但是服务端的 DataNode 是按需创建的,如果本地 GPU 机器上的 ECS 有加速能力足够的本地盘,那么就不需要构建控制面和元数据服务,如果它需要借助服务端做一些缓存能力的扩容,也可以对其进行实时扩容。加速单元 DataNode 通过 ENI 接入业务网络,所以整体的缓存带宽也不会有损耗。
业务实践—数据湖多云纳管加速
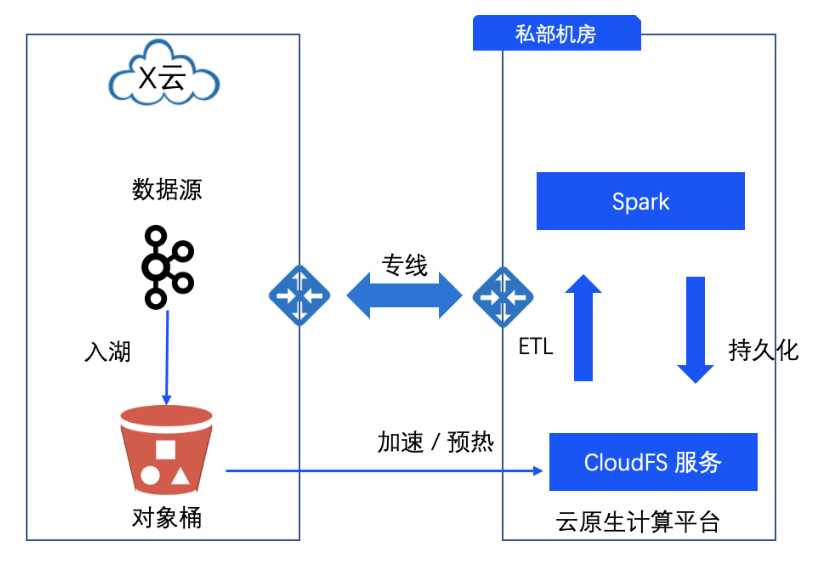
在混合云场景下的大数据业务实践中,CloudFS 作为火山云原生计算平台的组件,会部署在客户的私部机房。我们对其他云厂商的对象桶做了适配,可以把远端公有云对象桶上一些新的数据加速/预热到这个私部的机房中。在此基础上相关业务可以在私部机房内完成后续的大数据处理工作。
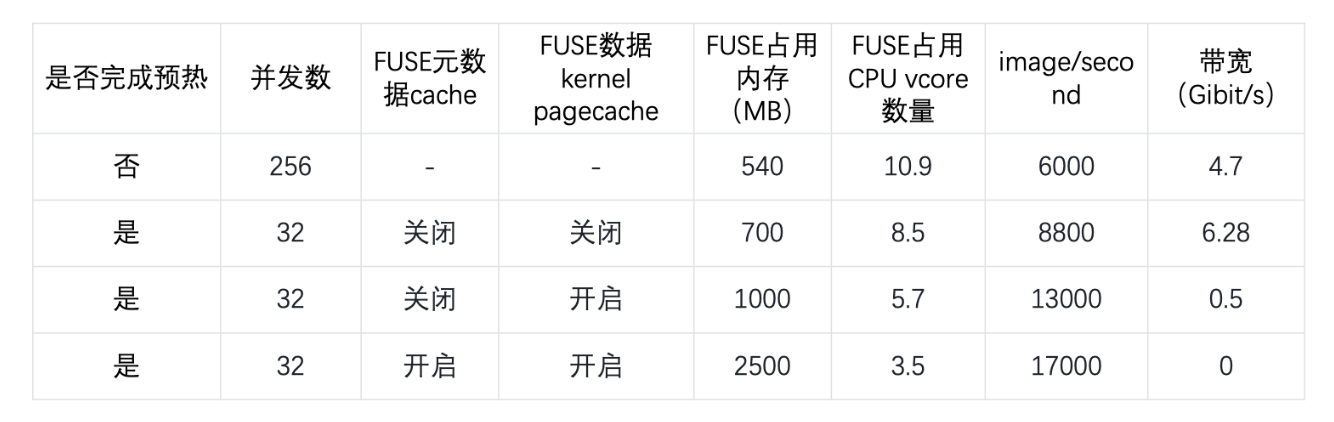
第一部分的测试工作中对 IO 打流进行了简单的测试,结合缓存功能以及 Page Cache 的关闭做了一些对比。如果没有预热,第一遍要从对象存储读,整体对于业务并发的需求就会更高。如果达到 256 的并发, 那它整个的 image/second 能够做到 6000 多,这对于并发要求是非常高的。如果已经全部缓存命中的情况下就只需要 32 个并发就可以达到 8800 的 image/second。当开启了 Page Cache 或者是 FUSE 端的元数据缓存,这个数据结果可以做到更高。
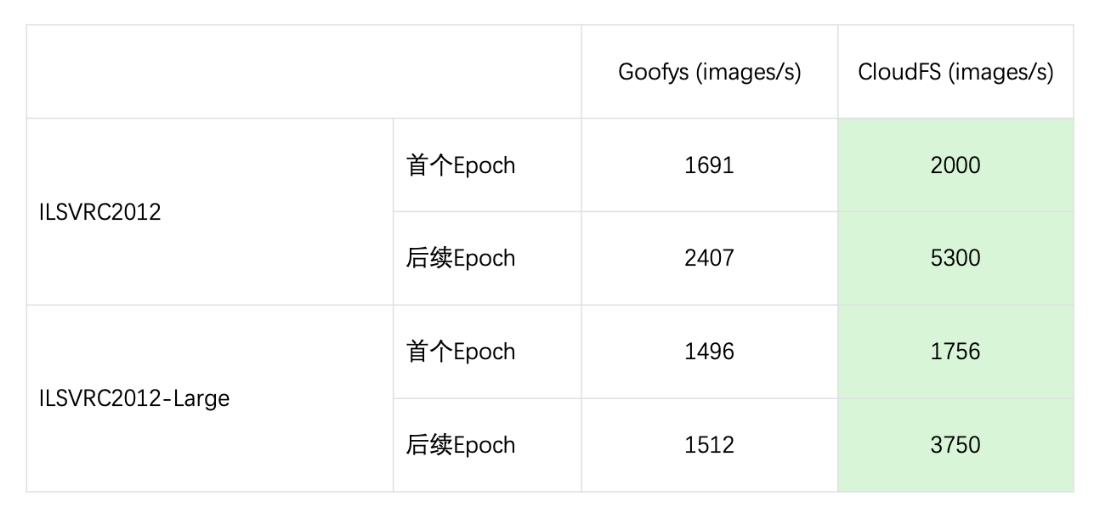
第二部分的测试是基于这个数据集已经运行了一些简单的基于学习训练的任务负载后,与 Goofys 做了一个对比,无论是在 Epoch 缓存是否命中的场景都会对性能有比较大的提升。只是因为第一个 Epoch 是从底层存储上拿到的,所以性能提升不是很明显,到缓存全部命中之后就会有两倍多的能力提升。
未来规划
未来的规划主要包括三方面:
首先是继续打磨 NAS 底座;
第二是实现更加细粒度的缓存优化;
最后是建立缓存的细粒度弹性伸缩机制。
问答环节:
Q:哪些场景需要 CloudFS 加速,HDFS 加速的性能如何?
A:哪些场景需要加速取决于底层带宽是不是有瓶颈。如果计算业务和 HDFS 集群之间带宽足够,并且 QPS 要求也不高,那么就不需要做存储加速。但如果像在公有云上,对象存储的带宽很多时候是受限的,QPS 一般也会有一个限制,当不能满足业务要求时,就需要来做这样的一个加速。
Q:缓存弹性伸缩是怎么做的?
A:目前还在做优化,整体的思路其实很简单,还是看业务负载。如果带宽比较低的时候,就去掉一些加速单元节点。如果负载达到了一个阈值,那就扩容几个加速单元节点,因为这个用的都是火山的 ECS,这个机制其实是基于 ECS 保证这个带宽资源的弹性的。
Q:CloudFS 最多可以存储多少 iNode 元数据?过多对集群的可用性和稳定性有影响吗?
A:目前规模上限是 50 亿。在字节内部 HDFS 的分布式元数据架构中已经解决了稳定性相关的问题。

![[Mac软件]Adobe XD(Experience Design) v57.1.12.2一个功能强大的原型设计软件](https://img-blog.csdnimg.cn/90aa798e3f794ba2a93e298844537ba1.png)