目录
简单泛型
元组库
通过泛型实现栈类
泛型接口
泛型方法
可变参数和泛型方法
通用Supplier
简化元组的使用
使用Set创建实用工具
本笔记参考自: 《On Java 中文版》
继承的层次结构有时会带来过多的限制,例如:编写的方法或类往往要依赖于具体的类型。尽管接口突破了单一继承层次结构,但我们可能会想要更加“泛用”的代码,这也是面向对象编程的目的之一。
为了让代码不再依赖于特定的接口与类,Java 5引入了泛型的概念。
||| 在术语中,“泛型” 是指“适用或者可以兼容大批的类”。
泛型可以生成参数化类型,以此来支持适用于多种类型的组件。当我们创建了某个参数化类型的实例时,类型转换会自动发生,并且在编译期间确保类型的正确性。
然而,Java在正式引入泛型之前,已经有了近十年的历史,这意味着在此期间无数工作者创建并使用的库并不会涉及泛型。为了兼容这些旧的库与程序,Java的设计者不得不在Java的泛型上“走些远路”。因此,Java的泛型可能不会如同其他一些语言来得好用。
简单泛型
泛型设计的目的之一,就是用于创建集合类。集合比起数组要更加灵活,并且会具备不同的特性(实际上,集合也是复用性最高的库之一)。
假设有一个类,它持有一个简单的对象,具有简单的操作:
【例子:简单的类】
class Automobile {
}public class Holder1 {private Automobile a;public Holder1(Automobile a) {this.a = a;}Automobile get() {return a;}
}对于这个类而言,具体的对象限制了对它的复用。如果这个类表示着某个功能模块,我们可能就需要为每一个模块写一份相似的代码。
在Java 5之前,如果要解决这个问题,我们可以使用Object对象:
【例子:使用Object对象创建通用的类】
public class ObjectHolder {private Object a;private ObjectHolder(Object a) {this.a = a;}public void set(Object a) {this.a = a;}public Object get() {return a;}public static void main(String[] args) {ObjectHolder h2 =new ObjectHolder(new Automobile());Automobile a = (Automobile) h2.get();h2.set("传入不是Automobile的类型(字符串)");String s = (String) h2.get();h2.set(1); // 发生自动装箱Integer x = (Integer) h2.get();}
}通过这种方式,ObjectHolder类实现了对不同类型对象的持有。但这依旧不够“具体”,尽管通过一个集合持有许多不同的对象在一些时候会有用,但更多时候,我们会将具体类型的对象放入特定的集合中。
泛型的一个目的就是指定集合能够持有的对象类型,并且通过编译器强制执行这一规范:
【例子:使用泛型创建简单的类】
public class GenericHolder<T> {private T a;public GenericHolder(){}public void set(T a){this.a = a;}public T get(){return a;}public static void main(String[] args) {GenericHolder<Automobile> h3 =new GenericHolder<>(); // 钻石语法h3.set(new Automobile()); // 在编译时,会检测类型Automobile a = h3.get();// h3.set("类型不对,不允许输入");// h3.set(1);}
}这里第一次正式提到了泛型语法:
public class GenericHolder<T> {此处的【T】被称为类型参数,在此处作为一个类型占位符使用。在使用时,【T】会被替换为具体的类型。
从main()中可以看到,泛型需要在尖括号语法中定义其要存储的类型。通过这种方式,我们可以强制 h3 只存储指定类或其的子类。
这里也体现了Java中泛型的核心理念:只需告诉泛型所需的类型,剩下的细节由编译器来处理。
一个好的理解方式是,将泛型视同其他的类型,只是泛型恰好有类型参数而已。
元组库
有时,我们会希望能够从方法中返回多个对象。一般,我们需要通过一个特殊的类(集合)来实现这一功能。但这种实现往往会受到具体类型的限制。因此,在这里使用泛型是一个不错的选择(同时,我们也可以享受到泛型带来的编译时检查)。
通过泛型打包多个对象,这一概念的实现就是元组(或称数据传输对象、信使)。这种对象有一个限制,它只能读取,不能写入。
元组一般不会设置长度限制,且允许每一个对象是不同的类型。但为了接收方便,我们仍会指定元素的类型:
【例子:一个持有两个对象的元组】
public class Tuple2<A, B> {public final A a1;public final B b1;public Tuple2(A a, B b) {a1 = a;b1 = b;}public String rep() {return a1 + "," + b1;}@Overridepublic String toString() {return "(" + rep() + ")";}
}类型参数的不同使得元组可以隐式地按序存储数据。
首先分析一下两个final对象:
public final A a1;
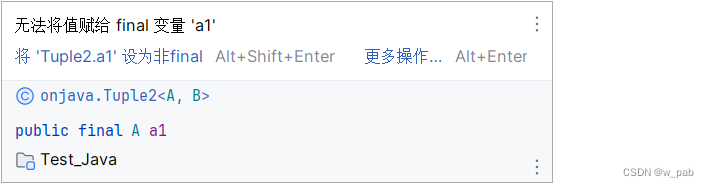
public final B b1;尽管这两个对象是public的,但final关键字保证了它们不会在初始化后被再次更改。若强行赋值,会看到如下报错:
同时,这种写法也允许外部读取这两个对象。比起使用get()方法而言,这种方法在提供了与private等价的安全性的同时,也更加简洁。
并不建议对a1和b1进行重新赋值。若需要,那么更好的方法是创建一个新的元组。
我们也可以在现有元组的基础上创建一个更长的元组。通过继承,可以轻易做到:
【例子:更长的元组】
public class Tuple3<A, B, C> extends Tuple2<A, B> {public final C c3;public Tuple3(A a, B b, C c) {super(a, b);c3 = c;}@Overridepublic String rep() {return super.rep() + "," + c3;}
}乃至于更长的元组,这里不展示更多了:

接下来就可以尝试使用元组了:
【例子:使用元组】
先定义一些类,用以放入元组中:
public class Amphibian {}public class Vehicle {}然后就是使用元组了:
import onjava.Tuple2;
import onjava.Tuple3;public class TupleTest {static Tuple2<String, Integer> f() {// 会发生自动装箱(int -> Integer)return new Tuple2<>("Hi", 123);}static Tuple3<Amphibian, Vehicle, Integer> g() {return new Tuple3<>(new Amphibian(), new Vehicle(), 321);}public static void main(String[] args) {// 当接受时,需要设置好对应的元组元素Tuple2<String, Integer> t1 = f();System.out.println(f());System.out.println(g());}
}程序执行的结果是:
![]()
通过泛型,可以轻松地使方法返回一组对象。
通过泛型实现栈类
Java中的栈(Stack)主要由两部分组成:泛型类Stack<T>和LinkedList<T>。栈的结构较为简单,而通过泛型,我们也可以独立实现自己的栈类:
【例子:实现一个栈类】
public class LinkedStack<T> {// 使用内部类实现结点(结点同样是一个泛型):private static class Node<U> {U item;Node<U> next;Node() {item = null;next = null;}Node(U item, Node<U> next) {this.item = item;this.next = next;}boolean end() {return item == null &&next == null;}}// 设置空的结点头(也被称为末端哨兵)private Node<T> top = new Node<>();public void push(T item) {// 在创建新结点的同时完成结点之间的链接// top指向栈顶元素top = new Node<>(item, top);}public T pop() {T result = top.item;if (!top.end())top = top.next; // top向下移动return result;}public static void main(String[] args) {LinkedStack<String> lss = new LinkedStack<>();for (String s : "第一 第二 第三".split(" "))lss.push(s);String s;while ((s = lss.pop()) != null)System.out.println(s);}
}程序执行的结果是:

top(哨兵)的存在,使得我们可以在栈上进行移动,并完成各种操作。
泛型接口
接口的参数同样可以是泛型。java.util.function.Supplier就是一个典型的例子:

实际上,这一接口同时还是Java定义的生成器,其中的生成方法是T get(),能够根据实现生成一个新的对象。
生成器设计模式来自于工厂方法设计模式,它们都用于创建对象。不同的地方在于,生成器不需要传入参数(即不需要额外信息)来生成对象。
这是一个创建Supplier<T>的例子:
【例子:实现Supplier<T>】
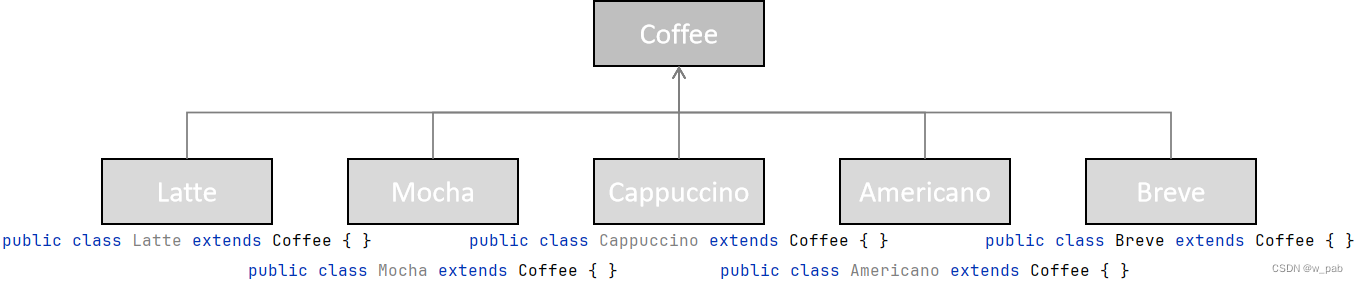
先设计一个简单的继承结构,首先确定基类Coffee:
public class Coffee {private static long counter = 0;private final long id = counter++;@Overridepublic String toString() {return getClass().getSimpleName() + " " + id;}
}之后我们需要的只是打印对象,因此子类只需要其名称即可。
然后是Supplier<T>的实现:
import generics.coffee.*;import java.lang.reflect.InvocationTargetException;
import java.util.Iterator;
import java.util.Random;
import java.util.function.Supplier;
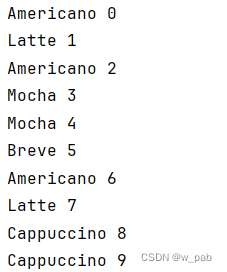
import java.util.stream.Stream;public class CoffeeSupplierimplements Supplier<Coffee>, Iterable<Coffee> {private Class<?>[] types = {Latte.class, Mocha.class,Cappuccino.class, Americano.class, Breve.class};private static Random random = new Random(47);public CoffeeSupplier() {}private int size = 0;public CoffeeSupplier(int sz) {size = sz;}@Overridepublic Coffee get() {try {return (Coffee) types[random.nextInt(types.length)].getConstructor().newInstance();} catch (InstantiationException |NoSuchMethodException |InvocationTargetException |IllegalAccessException e) {throw new RuntimeException(e);}}class CoffeeIterator implements Iterator<Coffee> {int count = size;@Overridepublic boolean hasNext() {return count > 0;}@Overridepublic Coffee next() {count--;return CoffeeSupplier.this.get();}@Overridepublic void remove() { //该方法未实现,因此返回异常throw new UnsupportedOperationException();}}@Overridepublic Iterator<Coffee> iterator() {return new CoffeeIterator();}public static void main(String[] args) {Stream.generate(new CoffeeSupplier()).limit(5).forEach(System.out::println);//由于实现了Iterable接口// 因此可以将CoffeeSupplier用于for-in语句for (Coffee c : new CoffeeSupplier(5))System.out.println(c);}
}程序执行的结果是:
---
再看一个例子,使用Supplier生成斐波那契数列:
【例子:生成斐波那契数列】
import java.util.function.Supplier;
import java.util.stream.Stream;public class Fibonacci implements Supplier<Integer> {private int count = 0;@Overridepublic Integer get() {return fib(count++);}private int fib(int n) {if (n < 2) return 1;return fib(n - 2) + fib(n - 1);}public static void main(String[] args) {Stream.generate(new Fibonacci()).limit(18).map(n -> n + " ").forEach(System.out::print);}
}程序执行的结果是:
![]()
这里需要注意的是类型参数:
![]()
这里使用的类型参数是Integer,而在类内部我们只使用了int类型。之所以需要使用包装类来规定类型参数,是因为泛型不允许将基本类型作为类型参数(涉及到类型擦除)。
【扩展】
进一步地,若我们想要实现一个可以迭代(Iterable)的斐波那契数列,有两个方法:
- 一:改装原有的类,并添加Iterable接口。这一方法有一个缺点:我们并不总是能够获得原始代码(或者代码的控制权)。
因此这里选择使用第二个方法:
- 二:使用适配器生成所需的接口。
【例子:使用继承生成适配器】
import java.util.Iterator;public class IterableFibonacci extends Fibonacciimplements Iterable<Integer> {private int n;public IterableFibonacci(int count) {n = count;}@Overridepublic Iterator<Integer> iterator() {return new Iterator<Integer>() {@Overridepublic boolean hasNext() {// 需要设置这样的一个n(边界),用于判断是否返回falsereturn n > 0;}@Overridepublic Integer next() {n--;return IterableFibonacci.this.get();}@Overridepublic void remove() {//未实现,返回异常throw new UnsupportedOperationException();}};}public static void main(String[] args) {for (int i : new IterableFibonacci(18))System.out.print(i + " ");}
}程序执行的结果是:
![]()
泛型方法
除了对整个类进行泛型化外,还可以对单个的方法使用泛型化,这就成了泛型方法。
泛型方法的行为会随着类型参数的改变而变化,并且不受类的影响。一般情况下,泛型方法会更加方便,因为相比于整个类,单一方法的泛型化往往更加清晰。
因此,可以“尽量”使用泛型方法。
除此之外,若某个方法是静态的,那么它将无法访问类的泛型类型参数。此时,若方法需要使用到泛型,那么该方法就必须被设置为泛型方法。
下面的例子展示了定义泛型方法的方式:
【例子:定义泛型方法】
public class GenericMethods {// 泛型参数列表(即<T>)需要放在返回值之前public <T> void f(T x) {System.out.println(x.getClass().getName());}public static void main(String[] args) {GenericMethods gm = new GenericMethods();gm.f("");gm.f(1);gm.f(1.0);gm.f(1.0F);gm.f('c');gm.f(gm);}
}程序执行的结果是:

就如同例子中的f()方法一样:
![]()
必须在返回值前设置<T>表示的类型参数列表。除此之外,泛型方法和泛型类的使用还有一个区别:泛型类在实例化时必须指定类型参数,而泛型方法不用,编译器会处理好一切。这就是类型参数推断。
可变参数和泛型方法
泛型方法也兼容可变参数列表:
【例子:包含可变参数列表的泛型方法】
import java.util.ArrayList;
import java.util.List;public class GenericVarargs {@SafeVarargspublic static <T> List<T> makeList(T... args) {List<T> result = new ArrayList<>();for (T item : args)result.add(item);return result;}public static void main(String[] args) {List<String> ls = makeList("A");System.out.println(ls);ls = makeList("A", "B", "C");System.out.println(ls);ls = makeList("ABCDEFGHIJKLMNOPQRSTUVWXYZ".split(""));System.out.println(ls);}
}程序执行的结果是:
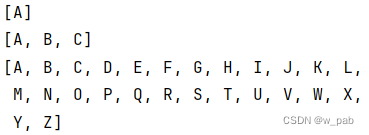
此处的@SafeVarargs注解表示,我们向系统承诺不会对变量参数列表进行任何修改(实际上我们也没有做任何修改)。若没有这个注解,编译器就会产生警告。
![]()
(警告会在编译时产生,但依旧可以通过编译并产生.class文件)
通用Supplier
可以提供泛型创建更通用的Supplier。下面的例子可以为任何一个具有无参构造器的类生成一个Supplier:
import java.lang.reflect.InvocationTargetException;
import java.util.function.Supplier;public class BasicSupplier<T> implements Supplier<T> {private Class<T> type;public BasicSupplier(Class<T> type) {this.type = type;}@Overridepublic T get() {try {// newInstance()只对public的类有效return type.getConstructor().newInstance();} catch (InstantiationException |NoSuchMethodException |InvocationTargetException |IllegalAccessException e) {throw new RuntimeException(e);}}// 根据类型标记(token)返回一个默认的Supplierpublic static <T> Supplier<T> create(Class<T> type) {return new BasicSupplier<>(type);}
}若一个类符合以下条件,则可以通过上述代码创建其对象的基本实现:
- 该类是public的。
- 该类具有无参构造器。
静态方法create()具有独立的类型参数。通过这个方法,可以方便地创建一个BasicSupplier对象。下面是BasicSupplier类的使用例:
【例子:BasicSupplier的使用例】
为了展示BasicSupplier的功能,先创建一个简单的类:
public class CountedObject {private static long counter = 0;private final long id = counter++;public long id() {return id;}@Overridepublic String toString() {return "CountedObject " + id;}
}现在可以通过BasicSupplier为CountedObject创建Supplier:
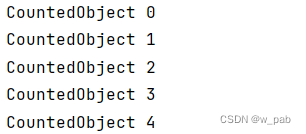
import java.util.stream.Stream;public class BasicSupplierDemo {public static void main(String[] args) {Stream.generate(BasicSupplier.create(CountedObject.class)).limit(5).forEach(System.out::println);}
}程序执行的结果是:
这么做有两个好处:
- 减少了我们生成Supplier对象所需的代码编写量。
- 创建BasicSupplier时,泛型强制要求传入Class对象,也为create()方法提供了类型判断。
简化元组的使用
通过静态导入(static)和类型参数推断,就可以整合之前创建的元组:
【例子:更通用的元组】
public class Tuple {public static <A, B> Tuple2<A, B> tuple(A a, B b) {return new Tuple2<>(a, b);}public static <A, B, C> Tuple3<A, B, C> tuple(A a, B b, C c) {return new Tuple3<>(a, b, c);}public static <A, B, C, D> Tuple4<A, B, C, D>tuple(A a, B b, C c, D d) {return new Tuple4<>(a, b, c, d);}public static <A, B, C, D, E> Tuple5<A, B, C, D, E>tuple(A a, B b, C c, D d, E e) {return new Tuple5<>(a, b, c, d, e);}
}可以用于之前类似的方式测试这个新类:
【例子:测试新的元组】
import onjava.Tuple2;
import onjava.Tuple3;
import onjava.Tuple4;
import onjava.Tuple5;
// 静态导入Tuple:
import static onjava.Tuple.*;public class TupleTest2 {static Tuple2<String, Integer> f() {return tuple("Hello", 47);}static Tuple2 f2() {return tuple("Hello", 47);}static Tuple3<Amphibian, String, Integer> g() {return tuple(new Amphibian(), "Hello", 47);}static Tuple4<Vehicle, Amphibian, String, Integer> h() {return tuple(new Vehicle(), new Amphibian(), "Hello", 47);}static Tuple5<Vehicle, Amphibian,String, Integer, Double> k() {return tuple(new Vehicle(), new Amphibian(),"Hello", 47, 11.1);}public static void main(String[] args) {Tuple2<String, Integer> ttsi = f();System.out.println(ttsi);System.out.println(f2());System.out.println(g());System.out.println(h());System.out.println(k());}
}程序执行的结果是:
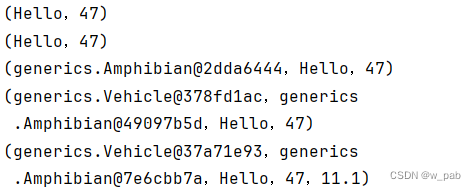
这里需要注意的是f2(),它返回了一个未参数化的Tuple2对象。尽管如此,但由于我们并未试图获取f2()的结果(并将其放入参数化的Tuple2中),因此编译器没有发出警告。
使用Set创建实用工具
可以利用Set创建一系列表示数学关系的方法:
import java.util.HashSet;
import java.util.Set;public class Sets {// 合并a、b(取并集)public static <T> Set<T> union(Set<T> a, Set<T> b) {Set<T> result = new HashSet<>(a);result.addAll(b);return result;}// 取a、b中都存在的元素(取交集)public static <T>Set<T> intersection(Set<T> a, Set<T> b) {Set<T> result = new HashSet<>(a);result.retainAll(b);return result;}// 从超集中减去子集:public static <T> Set<T>difference(Set<T> superset, Set<T> subset) {Set<T> result = new HashSet<>(superset);result.removeAll(subset);return result;}// 获取所有不在交集中的元素public static <T> Set<T>complement(Set<T> a, Set<T> b) {return difference(union(a, b), intersection(a, b));}
}通过将数据复制到一个新的HashSet中,我们可以保证进行的修改不会影响原本的数据。
接下来就可以使用这些Set工具了。为此,我们还需要先创建一些用于存储的枚举:
【例子:创建枚举】
package generics.watercolors;public enum Watercolors {RED, GREEN, BLUE, YELLOW, ORANGE,PURPLE, CYAN, MAGENTA, WHITE, BLACK
}接下来就可以使用这个枚举类型展示Set工具的用法了:
【例子:使用创建的Set工具】
import generics.watercolors.Watercolors;import static generics.watercolors.Watercolors.*;import java.util.EnumSet;import java.util.Set;import static onjava.Sets.*;public class WatercolorSets {public static void main(String[] args) {Set<Watercolors> set1 =EnumSet.range(RED, MAGENTA);Set<Watercolors> set2 =EnumSet.range(BLUE, BLACK);System.out.println("set1: " + set1);System.out.println("set2: " + set2);System.out.println("union(set1, set2): " +union(set1, set2));Set<Watercolors> subset = intersection(set1, set2);System.out.println("intersection(set1, set2): " +subset);System.out.println("difference(set1, subset): " +difference(set1, subset));System.out.println("difference(set2, subset): " +difference(set2, subset));System.out.println("complement(set1, set2): " +complement(set1, set2));}
}程序执行的结果是:

还可以用这些工具比较不同Collection之间的区别:
【例子:不同Collection之间的区别】
import onjava.Sets;import java.lang.reflect.Method;
import java.util.*;
import java.util.stream.Collectors;public class CollectionMethodDifferences {static Set<String> methodSet(Class<?> type) {return Arrays.stream(type.getMethods()).map(Method::getName).collect(Collectors.toCollection(TreeSet::new));}static void interfaces(Class<?> type) {System.out.print("【" + type.getSimpleName() +"】继承了的接口:");System.out.println(Arrays.stream(type.getInterfaces()).map(Class::getSimpleName).collect(Collectors.toList()));}static Set<String> object =methodSet(Object.class);static {object.add("加载Object的方法");}static voiddifference(Class<?> superset, Class<?> subset) {System.out.print("【" + superset.getSimpleName() +"】继承自【" + subset.getSimpleName() +"】,并添加了这些方法:");Set<String> comp = Sets.difference(methodSet(superset),methodSet(subset));comp.removeAll(object); // 忽略所有Object类中的方法System.out.format(comp + "%n");interfaces(superset);}// 方便打印static voidprintDifference(Class<?> superset, Class<?> subset) {System.out.println();difference(superset, subset);}public static void main(String[] args) {System.out.println("【Collection】中的方法有:" +methodSet(Collection.class));interfaces(Collection.class);printDifference(Set.class, Collection.class);printDifference(HashSet.class, Set.class);printDifference(LinkedHashSet.class, HashSet.class);}
}程序执行的结果是:

(也可以用于查看Map之间的区别。因为集合类较多,这里不一一展示。)