https://ceph.com/en/
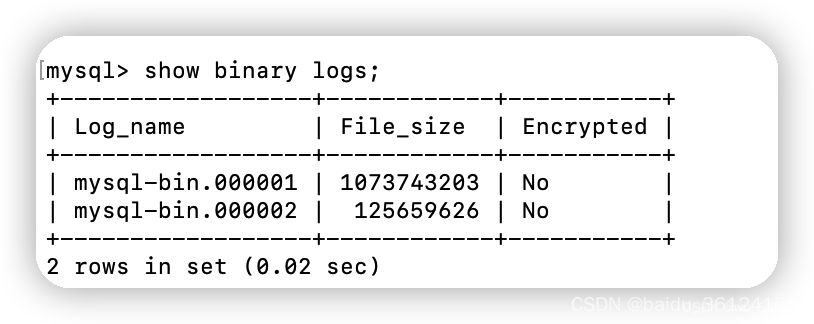
ceph组件介绍
Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。
OSD
OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD。
MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
Object
Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据。
PG
PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
RADOS
RADOS全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
Libradio
Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
CRUSH
CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
RBD
RBD全称RADOS block device,是Ceph对外提供的块设备服务。
RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
CephFS
CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
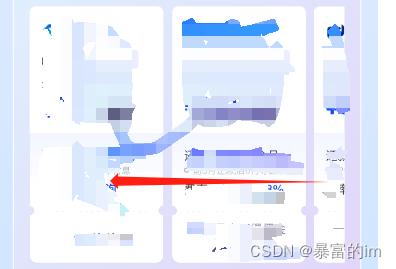
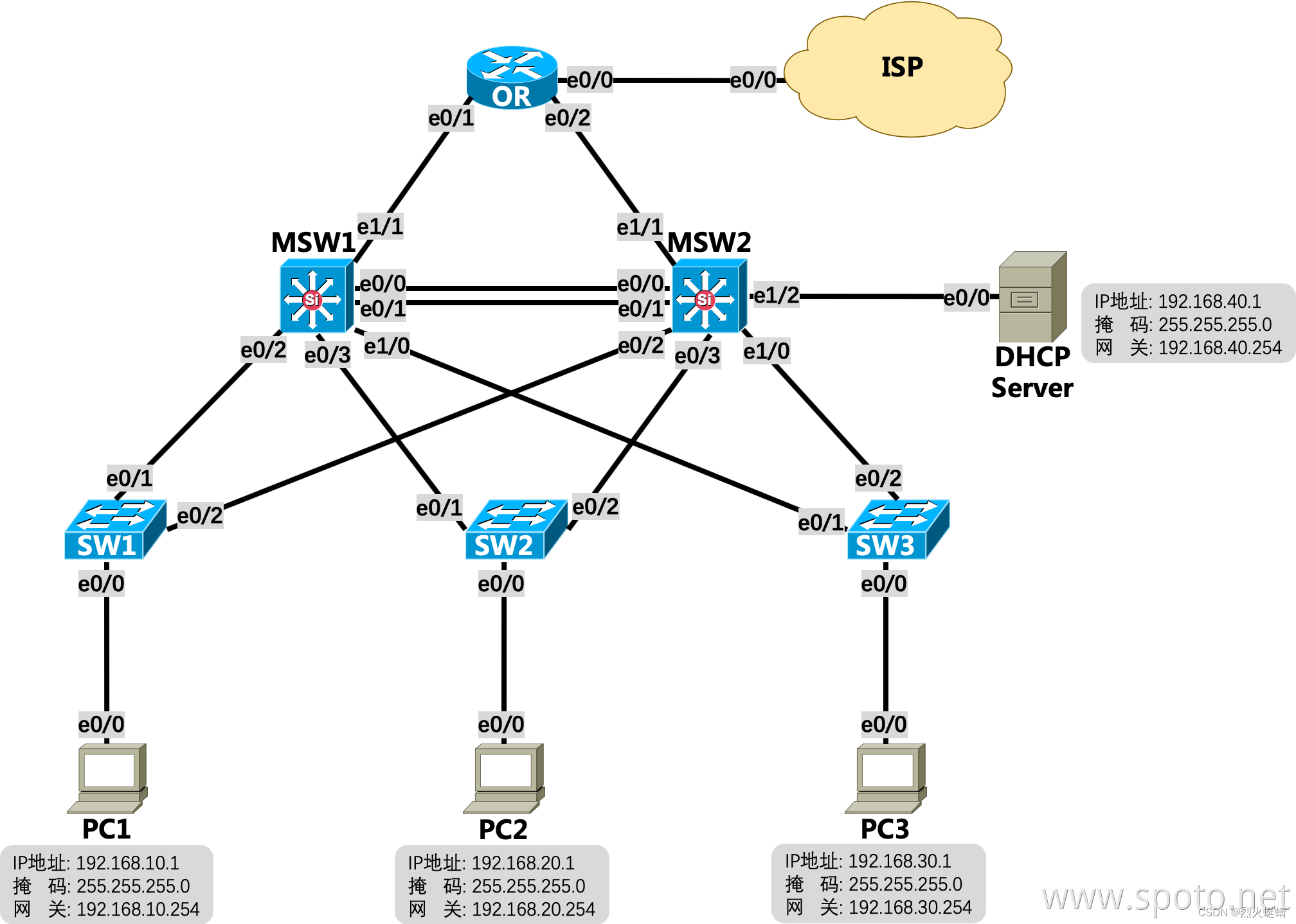
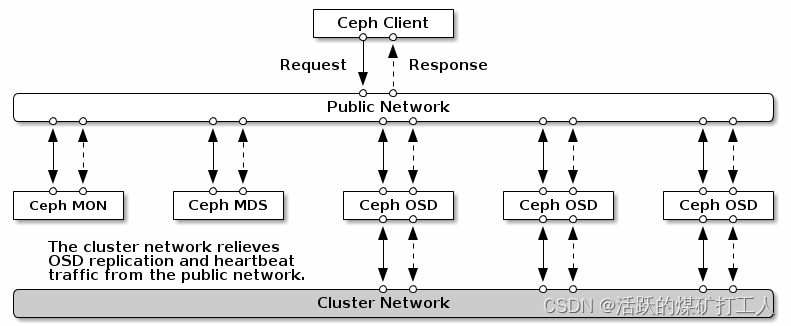
建议运行带有两个网络的Ceph存储集群:公共(前端)网络和集群(后端)网络。为了支持两个网络,每个Ceph节点都需要有多个NIC。
为什么要做内外网分离
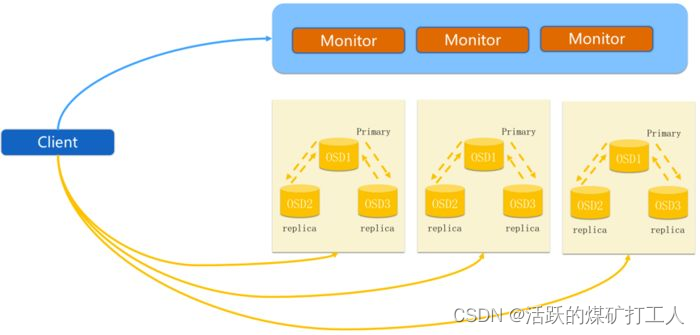
Ceph 的客户端,如RBD,会直接和 OSD 互联,以上传和下载数据,这部分是直接提供对外下载上传能力的;Ceph 一个基本功能是提供数据的冗余备份,OSD 负责数据的备份,跨主机间的数据备份当然要占用带宽,而且这部分带宽是无益于 Ceph 集群的吞吐量的。只有一个网络,尤其是有新的存储节点加入时,Ceph 集群的性能会因为大量的数据拷贝而变得很糟糕。建立内网是为了降低 OSD 节点间数据复制对 Ceph 整体的影响,那么只要在 OSD 节点上加内网就可以了,上图非常清晰的描述了内网和外网覆盖的范围。
做内外网分离,必不可少的前提条件是 OSD 服务器上必须有两张可用的网卡,并且网络互通,确保这点我们就可以开始了。所以对于性能有一定要求的用户,还是有必要配置内外网分离的。
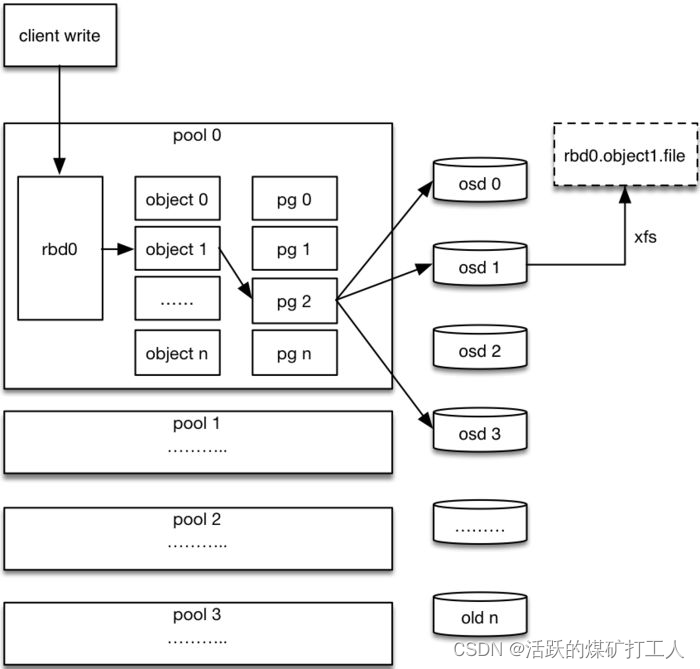
步骤:
- 客户端创建一个pool,需要为这个pool指定pg的数量。
- 创建pool/image rbd设备进行挂载。
- 用户写入的数据进行切块,每个块的大小默认为4M,并且每个块都有一个名字,名字就是object+序号。
- 将每个object通过pg进行副本位置的分配。
- pg根据cursh算法会寻找3个osd,把这个object分别保存在这三个osd上。
- osd上实际是把底层的disk进行了格式化操作,一般部署工具会将它格式化为xfs文件系统。
- object的存储就变成了存储一个文rbd0.object1.file。
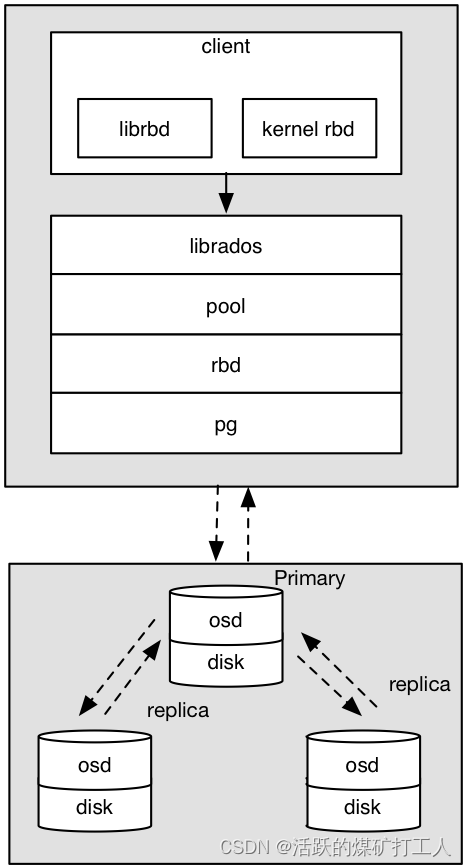
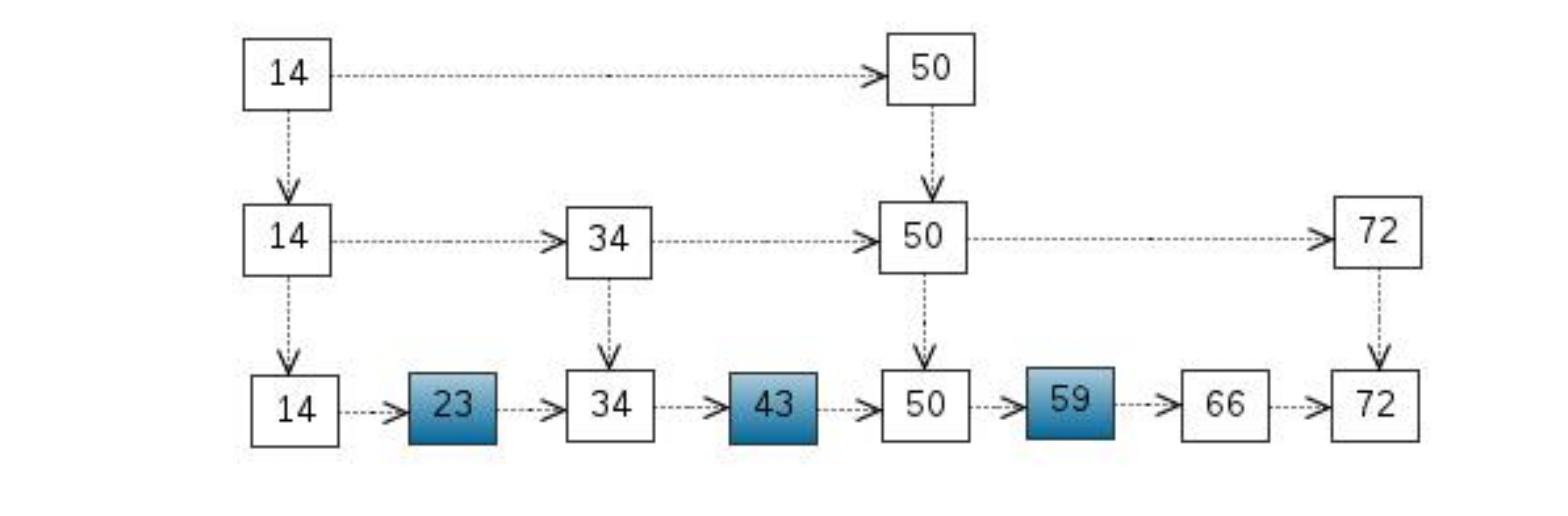
用简单hash解决对象obj到虚拟节点pg的映射,但是为了解决pg到实际物理节点osd的映射问题,ceph提出了crush算法。
crush算法是一个伪随机的路由选择算法,输入pg的id,osdmap等元信息,通过crush根据这个pool配置的crush rule规则的伪随机计算,最终输出存储这个pg的副本的osd列表。由于是伪随机的,只要CRUSH Map、crush rule规则相同,在任意的机器上,针对某个pg id,计算的最终的osd列表都是相同的。
CRUSH算法的全称为:Controlled Scalable Decentralized Placement of Replicated Data,可控的、可扩展的、分布式的副本数据放置算法。
pg到OSD的映射的过程算法叫做CRUSH 算法。(一个Object需要保存三个副本,也就是需要保存在三个osd上)。
CRUSH算法是一个伪随机的过程,他可以从所有的OSD中,随机性选择一个OSD集合,但是同一个PG每次随机选择的结果是不变的,也就是映射的OSD集合是固定的。
Pg id由简单hash算法求出,计算公式如下:
Id = Int(Hash(object_name)%PG_num)
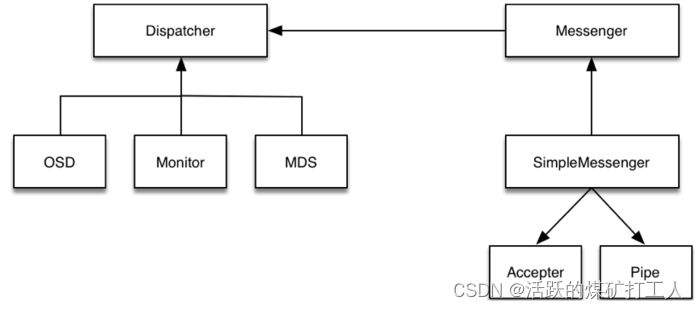
Ceph通信框架设计模式
订阅发布模式又名观察者模式,它意图是“定义对象间的一种一对多的依赖关系,
当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新”。
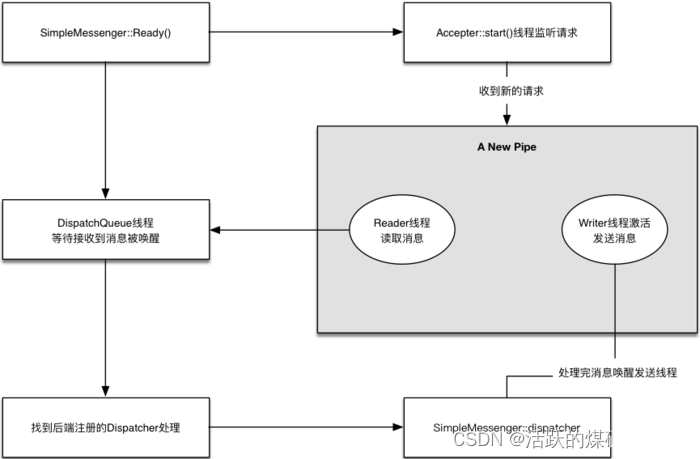
步骤:
Accepter监听peer的请求, 调用 SimpleMessenger::add_accept_pipe() 创建新的 Pipe 到 SimpleMessenger::pipes 来处理该请求。
Pipe用于消息的读取和发送。该类主要有两个组件,Pipe::Reader,Pipe::Writer用来处理消息读取和发送。
Messenger作为消息的发布者, 各个 Dispatcher 子类作为消息的订阅者, Messenger 收到消息之后, 通过 Pipe 读取消息,然后转给 Dispatcher 处理。
Dispatcher是订阅者的基类,具体的订阅后端继承该类,初始化的时候通过 Messenger::add_dispatcher_tail/head 注册到 Messenger::dispatchers. 收到消息后,通知该类处理。
DispatchQueue该类用来缓存收到的消息, 然后唤醒 DispatchQueue::dispatch_thread 线程找到后端的 Dispatch 处理消息。
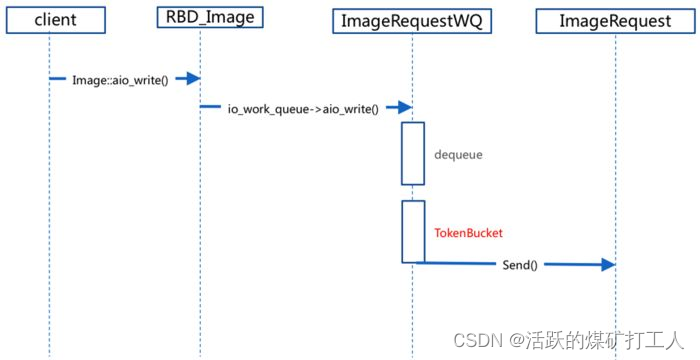
令牌桶限流模型
用户发起请求异步IO到达Image中。
请求到达ImageRequestWQ队列中。
在ImageRequestWQ出队列的时候加入令牌桶算法TokenBucket。
通过令牌桶算法进行限速,然后发送给ImageRequest进行处理。
资料来源
https://docs.ceph.com/en/latest/rados/configuration/mon-osd-interaction/
https://www.cnblogs.com/djoker/p/15955734.html
https://blog.csdn.net/uxiAD7442KMy1X86DtM3/article/details/81059215
http://www.51niux.com/?id=164
https://blog.csdn.net/easonwx/article/details/124306477
https://zhuanlan.zhihu.com/p/647566166