目录
1.开窗函数的定义
2.数据准备
3.开窗函数之排序
需求:用三种排序方法查询学生的语文成绩排名,并降序显示
4.开窗函数分组
需求:按照科目来分类,使用三种排序方式来排序学生的成绩
5.聚合函数与分组配合使用
6.聚合函数同时和分组以及排序关键字配合使用
--需求1:求出每个用户的总pv数,展示所有信息 默认第一行到最后一行
--需求2:求出每个用户截止到当天,累积的总pv数 默认第一行到当前行
做题思路,开窗函数核心:保证输出结果的记录数和输入的数据记录数一致
7.窗口范围控制
1.默认第一行到当前行
2.第一行到当前行,等效于rows between ..不写,默认就是第一行到当前行
3.向前3行到当前行
4.向前3行 向后1行
5.当前行到最后一行,第一行到最后一行
8.其他函数
1.ntile平分:
注意ntile规则:尽量平均分配 ,优先满足最小(编号1)的桶,彼此最多不相差1个。
1.开窗函数的定义
- 窗口:可以理解为操作数据的范围,窗口有大有小,本窗口中操作的数据有多有少。
- 可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行
-而窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
开窗函数格式: select ... 开窗函数 over(partition by 分组字段名 order by 排序字段名 asc|desc) ... from 表名;

-- 如果有分组操作,select后的字段要么在聚合函数内,要么在group by 后出现
-- 开窗函数: hive和mysql8都能使用
-- 开窗函数本质在表后新增了一列
-- 聚合开窗函数: max min sum avg count
2.数据准备
数据文件score.txt
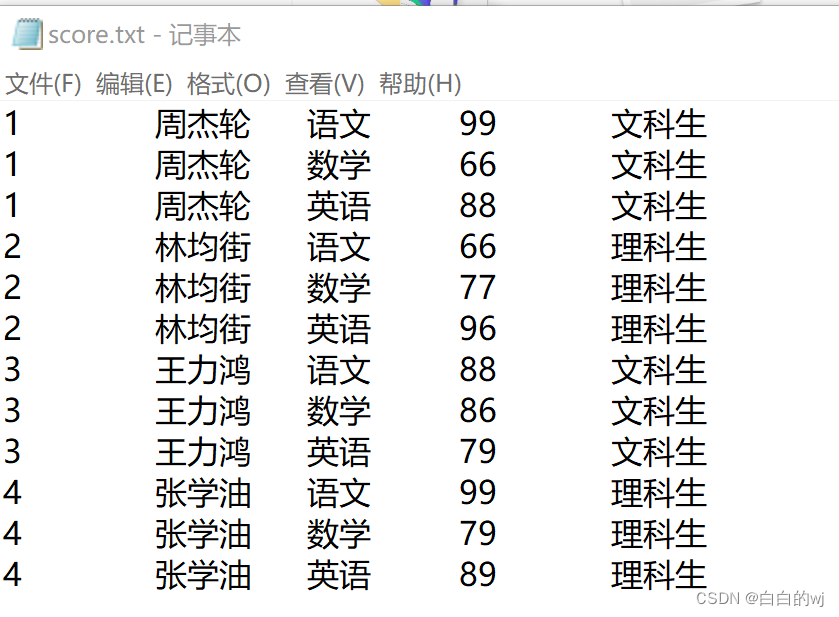
--数据准备
create table students(s_id int,s_name string,subject string,score double,class string
)row format delimited
fields terminated by '\t';--加载数据
load data inpath '/input/score.txt' into table students;--验证数据
select * from students;
3.开窗函数之排序
--查询最高分的学生
select max(score) from students; -- 99
-- 聚合函数配合over()使用,也可以叫开窗函数--查询最高分的学生,并附上他的名字
select s_name,max(score) over() --每一个学生都会匹配一个最高分,数据不正确
from students;
-- 排序开窗函数: row_number rank dense_rank
-- 排序函数必须配合over(order by 排序字段 asc|desc)
row_number: 巧记: 1234 特点: 唯一且连续
dense_rank: 巧记: 1223 特点: 并列且连续
rank : 巧记: 1224 特点: 并列不连续
需求:用三种排序方法查询学生的语文成绩排名,并降序显示
select s_name,subject,score,row_number() over (order by score desc ) ,--唯一且连续dense_rank() over (order by score desc ) ,--并列且连续rank() over (order by score desc ) --并列不连续
from students
where subject = '语文';
4.开窗函数分组
-- 开窗函数分组
-- 注意不能用group by ,需要使用partition by,可以理解成partition by是group by的子句
-- 演示排序函数和分组配合使用: 先分组再组内排序
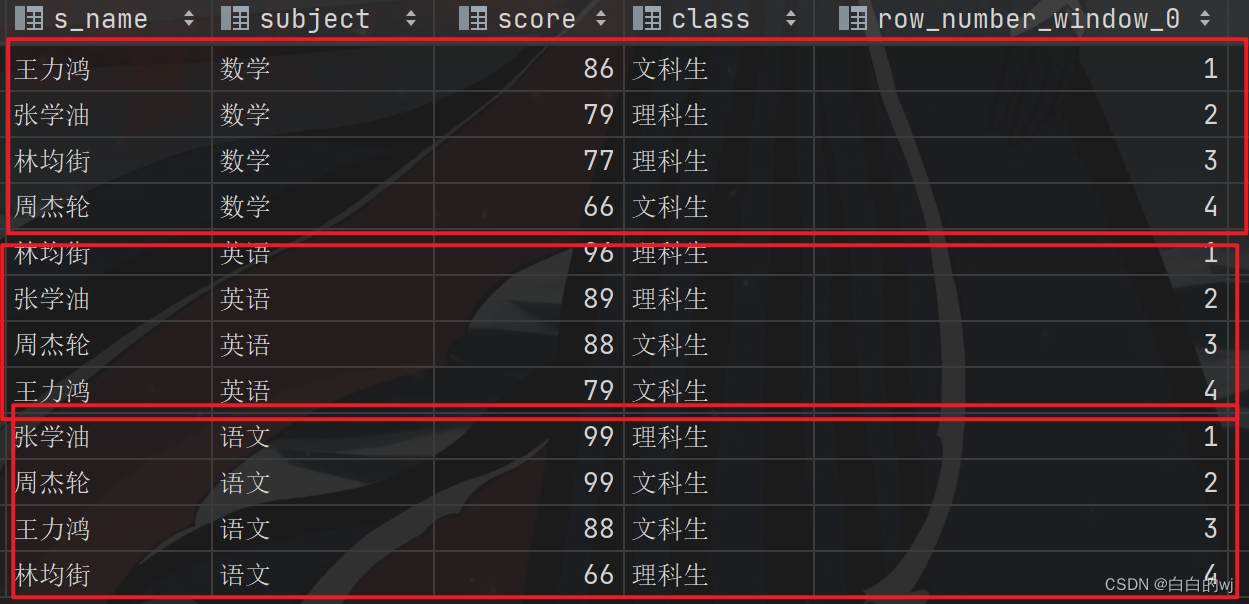
需求:按照科目来分类,使用三种排序方式来排序学生的成绩
select *,row_number() over (partition by subject order by score desc ),dense_rank() over (partition by subject order by score desc ),rank() over (partition by subject order by score desc )
from students;
5.聚合函数与分组配合使用
-- 演示聚合函数和分组配合使用
-- 普通分组
select s_name,max(score)
from students group by s_name;查询每个学生的信息,按照文理科分类,以及平均分
-- 开窗分组
select *,avg(score) over(partition by class)
from students;6.聚合函数同时和分组以及排序关键字配合使用
-- 演示聚合函数同时和分组以及排序关键字配合使用
-- 数据准备
---建表并且加载数据
create table website_pv_info(cookieid string,createtime string, --daypv int
) row format delimited
fields terminated by ',';-- 建表
create table website_url_info (cookieid string,createtime string, --访问时间url string --访问页面
) row format delimited
fields terminated by ',';-- 加载数据
load data inpath '/input/website_pv_info.txt' into table website_pv_info;
load data inpath '/input/website_url_info.txt' into table website_url_info;-- 查询数据
select * from website_pv_info;
select * from website_url_info; 

--需求1:求出每个用户的总pv数,展示所有信息 默认第一行到最后一行
cookie是记住用户记录的一个文件,代表一个用户
select *,sum(pv) over (partition by cookieid)
from website_pv_info; 
--需求2:求出每个用户截止到当天,累积的总pv数 默认第一行到当前行
--sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和
select *,sum(pv) over (partition by cookieid order by createtime)
from website_pv_info;做题思路,开窗函数核心:保证输出结果的记录数和输入的数据记录数一致


7.窗口范围控制
rows between
- preceding:往前
- following:往后
- current row:当前行
- unbounded:起点
- unbounded preceding 表示从前面的起点 第一行
- unbounded following:表示到后面的终点 最后一行
1.默认第一行到当前行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtime) as pv1
from website_pv_info;
2.第一行到当前行,等效于rows between ..不写,默认就是第一行到当前行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtimerows between unbounded preceding and current row) as pv2
from website_pv_info;3.向前3行到当前行
--向前3行至当前行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtimerows between 3 preceding and current row) as pv4
from website_pv_info;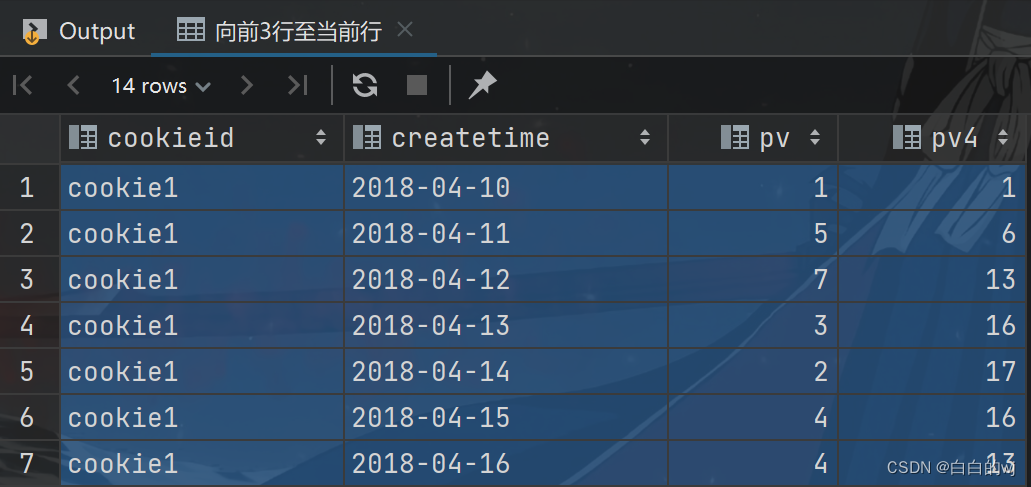
1+5+7=13 , 1+5+7+3=16 , 5+7+3+2=17 , 7+3+2+4=16 , 3+2+4+4=13
相当于查询今天以及前三天的总浏览量,在现实中常称为网站的'最近3天访问量'.
4.向前3行 向后1行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtimerows between 3 preceding and 1 following) as pv5
from website_pv_info;

1+5+7+3+2=18 , 5+7+3+2+4=21
5.当前行到最后一行,第一行到最后一行
--当前行至最后一行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtime
rows between current row and unbounded following) as pv6
from website_pv_info;--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtime
rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;8.其他函数
1.ntile平分:
注意ntile规则:尽量平均分配 ,优先满足最小(编号1)的桶,彼此最多不相差1个。
其他开窗函数: ntile lag和lead first_value和last_value
ntile(x)功能: 将分组排序之后的数据分成指定的x个部分(x个桶)
注意ntile规则:尽量平均分配 ,优先满足最小(编号1)的桶,彼此最多不相差1个。
lag: 用于统计窗口内往上第n行值
lead:用于统计窗口内往下第n行值
first_value: 取分组内排序后,截止到当前行,第一个值
last_value : 取分组内排序后,截止到当前行,最后一个值
注意: 窗口函数结果都是单独生成一列存储对应数据
-- 演示ntile
--把每个分组内的数据均匀分为3桶
SELECTcookieid,createtime,pv,ntile(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;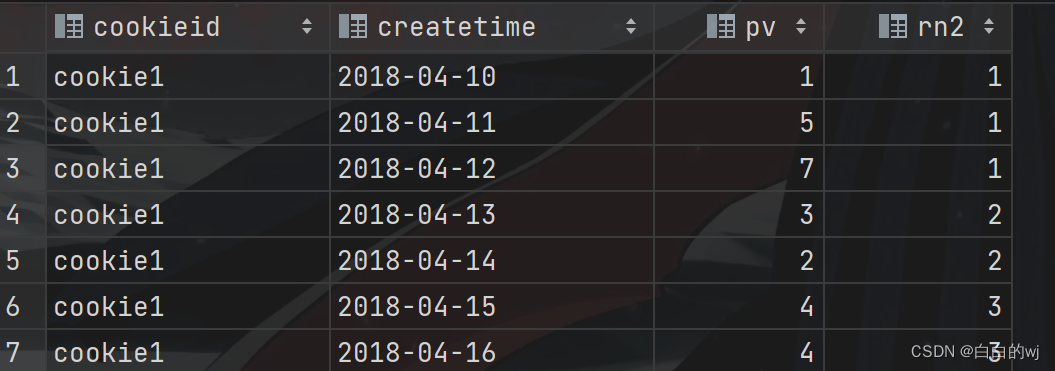
--需求:统计每个用户pv数最多的前3分之1天。
--理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
with tmp as (SELECTcookieid,createtime,pv,NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rnFROM website_pv_info)
SELECT * from tmp where rn =1;
--lag 用于统计窗口内往上第n行值
select cookieid, createtime, url,row_number() over (partition by cookieid order by createtime) rn,lag(createtime, 1) over (partition by cookieid order by createtime) la1,lag(createtime, 2, '2000-01-01 00:00:00') over (partition by cookieid order by createtime) la2
from website_url_info;--lead 用于统计窗口内往下第n行值
select cookieid, createtime, url,row_number() over (partition by cookieid order by createtime) rn,lead(createtime, 1) over (partition by cookieid order by createtime) la1,lead(createtime, 2, '2000-01-01 00:00:00') over (partition by cookieid order by createtime) la2
from website_url_info;--FIRST_VALUE 取分组内排序后,截止到当前行,第一个值
select cookieid, createtime, url,row_number() over (partition by cookieid order by createtime) rn,first_value(url) over (partition by cookieid order by createtime) fv
from website_url_info;--LAST_VALUE 取分组内排序后,截止到当前行,最后一个值
select cookieid, createtime, url,row_number() over (partition by cookieid order by createtime) rn,last_value(url) over (partition by cookieid order by createtime rows between unbounded preceding and unbounded following) fv
from website_url_info;