作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
上篇讲了什么是注解,以及注解的简单使用,这篇我们一起用注解+反射模拟几个框架,探讨其中的运行原理。
山寨Junit
上一篇已经讲的很详细了,这里就直接上代码了。请大家始终牢记,用到注解的地方,必然存在三角关系,并且别忘了设置保留策略为RetentionPolicy.RUNTIME。
代码结构

案例代码
MyBefore注解(定义注解)
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MyBefore {
}MyTest注解(定义注解)
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MyTest {
}MyAfter注解(定义注解)
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MyAfter {
}EmployeeDAOTest(使用注解)
/*** 和我们平时使用Junit测试时一样** @author mx*/
public class EmployeeDAOTest {@MyBeforepublic void init() {System.out.println("初始化...");}@MyAfterpublic void destroy() {System.out.println("销毁...");}@MyTestpublic void testSave() {System.out.println("save...");}@MyTestpublic void testDelete() {System.out.println("delete...");}
}MyJunitFrameWork(读取注解)
/*** 这个就是注解三部曲中最重要的:读取注解并操作* 相当于我们使用Junit时看不见的那部分(在隐秘的角落里帮我们执行标注了@Test的方法)** @author mx*/
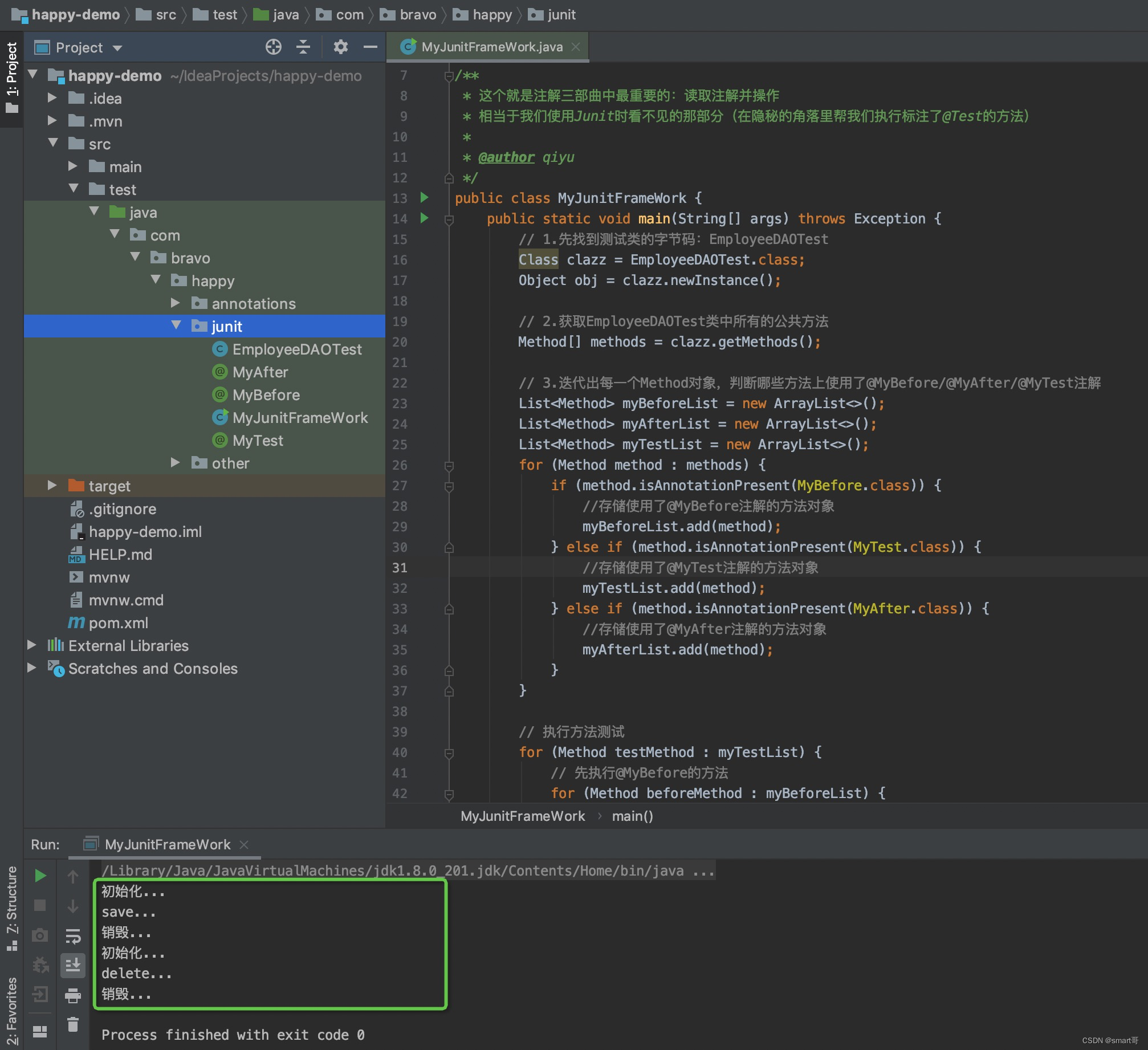
public class MyJunitFrameWork {public static void main(String[] args) throws Exception {// 1.先找到测试类的字节码:EmployeeDAOTestClass clazz = EmployeeDAOTest.class;Object obj = clazz.newInstance();// 2.获取EmployeeDAOTest类中所有的公共方法Method[] methods = clazz.getMethods();// 3.迭代出每一个Method对象,判断哪些方法上使用了@MyBefore/@MyAfter/@MyTest注解List<Method> myBeforeList = new ArrayList<>();List<Method> myAfterList = new ArrayList<>();List<Method> myTestList = new ArrayList<>();for (Method method : methods) {if (method.isAnnotationPresent(MyBefore.class)) {//存储使用了@MyBefore注解的方法对象myBeforeList.add(method);} else if (method.isAnnotationPresent(MyTest.class)) {//存储使用了@MyTest注解的方法对象myTestList.add(method);} else if (method.isAnnotationPresent(MyAfter.class)) {//存储使用了@MyAfter注解的方法对象myAfterList.add(method);}}// 执行方法测试for (Method testMethod : myTestList) {// 先执行@MyBefore的方法for (Method beforeMethod : myBeforeList) {beforeMethod.invoke(obj);}// 测试方法testMethod.invoke(obj);// 最后执行@MyAfter的方法for (Method afterMethod : myAfterList) {afterMethod.invoke(obj);}}}
}执行结果:
山寨JPA
要写山寨JPA需要两个技能:注解+反射。
注解已经学过了,反射其实还有一个进阶内容,之前那篇反射文章里没有提到,放在这里补充。至于是什么内容,一两句话说不清楚。慢慢来吧。
首先,要跟大家介绍泛型中几个定义(记住最后一个):
ArrayList<E>中的E称为类型参数变量ArrayList<Integer>中的Integer称为实际类型参数- 整个
ArrayList<E>称为泛型类型 - 整个
ArrayList<Integer>称为参数化的类型ParameterizedType
好,接下来看这个问题:
class A<T>{public A(){/*我想在这里获得子类B、C传递的实际类型参数的Class对象class java.lang.String/class java.lang.Integer*/}
}class B extends A<String>{
}class C extends A<Integer>{
}我先帮大家排除一个错误答案:直接T.class是错误的。

所以,你还有别的想法吗?
我觉得大部分人可能都想不到,这不是技术水平高低的问题,而是知不知道相关API的问题。知道就简单,不知道想破脑袋也没辙。
我们先不直接说怎么做,一步步慢慢来。
父类中的this是谁?
请先看下面代码:
public class Test {public static void main(String[] args) {new B();}
}class A<T>{public A(){// this是谁?A还是B?Class clazz = this.getClass();System.out.println(clazz.getName());}
}class B extends A<String>{
}请问,clazz.getName()打印的是A还是B?
答案是:B。因为从头到尾,我们new的是B,这个Demo里至始至终只初始化了一个对象,所以this指向B。


好的,到这里我们已经迈出了第一步:在泛型父类中得到了子类的Class对象!
如何根据子类Class获取父类Class?
我们再来分析:
class A<T>{public A(){//clazz是B.classClass clazz = this.getClass();}
}
class B extends A<String>{
}现在我们已经在class A<T>中得到子类B的Class对象,而我们想要得到的是父类A<T>中泛型的Class对象。且先不说泛型的Class对象,我们先考虑如何通过子类B的Class对象获得父类A的Class对象?
查阅API文档,我们发现有这么个方法:

Generic Super Class,直译就是“带泛型的父类”。也就是说调用getGenericSuperclass()就会返回泛型父类的Class对象。这非常符合我们的情况,因为Class A确实是泛型类。试着打印一下:

如何获取带实际类型参数的父类Class?
上面已经证明通过子类Class是可以获取父类Class的,接下来我们尝试如何获取带实际类型参数的父类Class。
虽然genericSuperclass是Type接收的,但可以看出实际类型为ParameterizedTypeImpl:

这里我们不去关心Type、ParameterizedType还有Class之间的继承关系,总之以我们多年的编码经验,子类的方法总是更多,所以毫不犹豫地向下转型:
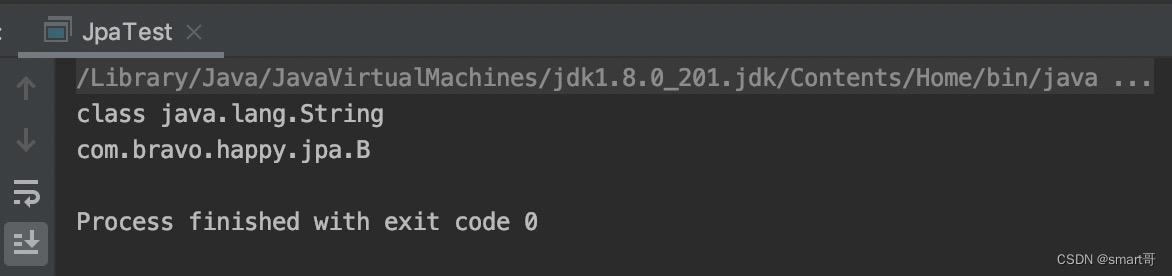
public class JpaTest {public static void main(String[] args) {new B();}
}class A<T> {public A() {Class<? extends A> subClass = this.getClass();// 得到泛型父类Type genericSuperclass = subClass.getGenericSuperclass();// 本质是ParameterizedTypeImpl,可以向下强转ParameterizedType parameterizedTypeSuperclass = (ParameterizedType) genericSuperclass;// 强转后可用的方法变多了,比如getActualTypeArguments()可以获取Class A<String>的泛型的实际类型参数Type[] actualTypeArguments = parameterizedTypeSuperclass.getActualTypeArguments();// 由于A类只有一个泛型,这里可以直接通过actualTypeArguments[0]得到子类传递的实际类型参数Class actualTypeArgument = (Class) actualTypeArguments[0];System.out.println(actualTypeArgument);System.out.println(subClass.getName());}
}class B extends A<String> {
}class C extends A<Integer> {
}
把main方法中的new B()换成new C():
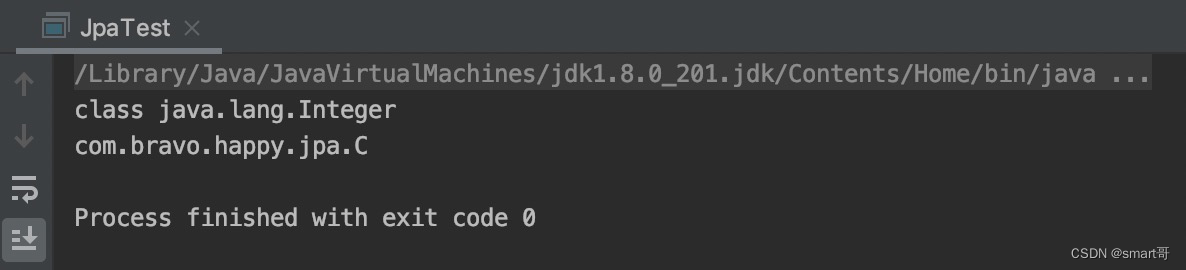
这下成了!现在我们能在父类中得到子类继承时传递的泛型的实际类型参数。
接下来正式开始编写山寨JPA。
第一版JPA
需要额外依赖数据库连接池,这里使用dbcp:
<dependency><groupId>commons-dbcp</groupId><artifactId>commons-dbcp</artifactId><version>1.4</version><scope>test</scope>
</dependency>User
CREATE TABLE `User` (`name` varchar(255) DEFAULT NULL COMMENT '名字',`age` tinyint(4) DEFAULT NULL COMMENT '年龄'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;@Data
@AllArgsConstructor
public class User {private String name;private Integer age;
}BaseDao<T>
public class BaseDao<T> {private static BasicDataSource datasource;// 静态代码块,设置连接数据库的参数static {datasource = new BasicDataSource();datasource.setDriverClassName("com.mysql.jdbc.Driver");datasource.setUrl("jdbc:mysql://localhost:3306/test");datasource.setUsername("root");datasource.setPassword("123456");}// 得到jdbcTemplateprivate JdbcTemplate jdbcTemplate = new JdbcTemplate(datasource);// DAO操作的对象private Class<T> beanClass;/*** 构造器* 初始化时完成对实际类型参数的获取,比如BaseDao<User>插入User,那么beanClass就是user.class*/public BaseDao() {beanClass = (Class<T>) ((ParameterizedType) this.getClass().getGenericSuperclass()).getActualTypeArguments()[0];}public void add(T bean) {// 得到User对象的所有字段Field[] declaredFields = beanClass.getDeclaredFields();// 拼接sql语句,表名直接用POJO的类名,所以创建表时,请注意写成User,而不是t_userStringBuilder sql = new StringBuilder().append("insert into ").append(beanClass.getSimpleName()).append(" values(");for (int i = 0; i < declaredFields.length; i++) {sql.append("?");if (i < declaredFields.length - 1) {sql.append(",");}}sql.append(")");// 获得bean字段的值(要插入的记录)ArrayList<Object> paramList = new ArrayList<>();try {for (Field declaredField : declaredFields) {declaredField.setAccessible(true);Object o = declaredField.get(bean);paramList.add(o);}} catch (IllegalAccessException e) {e.printStackTrace();}int size = paramList.size();Object[] params = paramList.toArray(new Object[size]);// 传入sql语句模板和模板所需的参数,插入Userint num = jdbcTemplate.update(sql.toString(), params);System.out.println(num);}
}UserDao
public class UserDao extends BaseDao<User> {@Overridepublic void add(User bean) {super.add(bean);}
}测试类
public class UserDaoTest {public static void main(String[] args) {UserDao userDao = new UserDao();User user = new User("bravo1988", 20);userDao.add(user);}
}测试结果
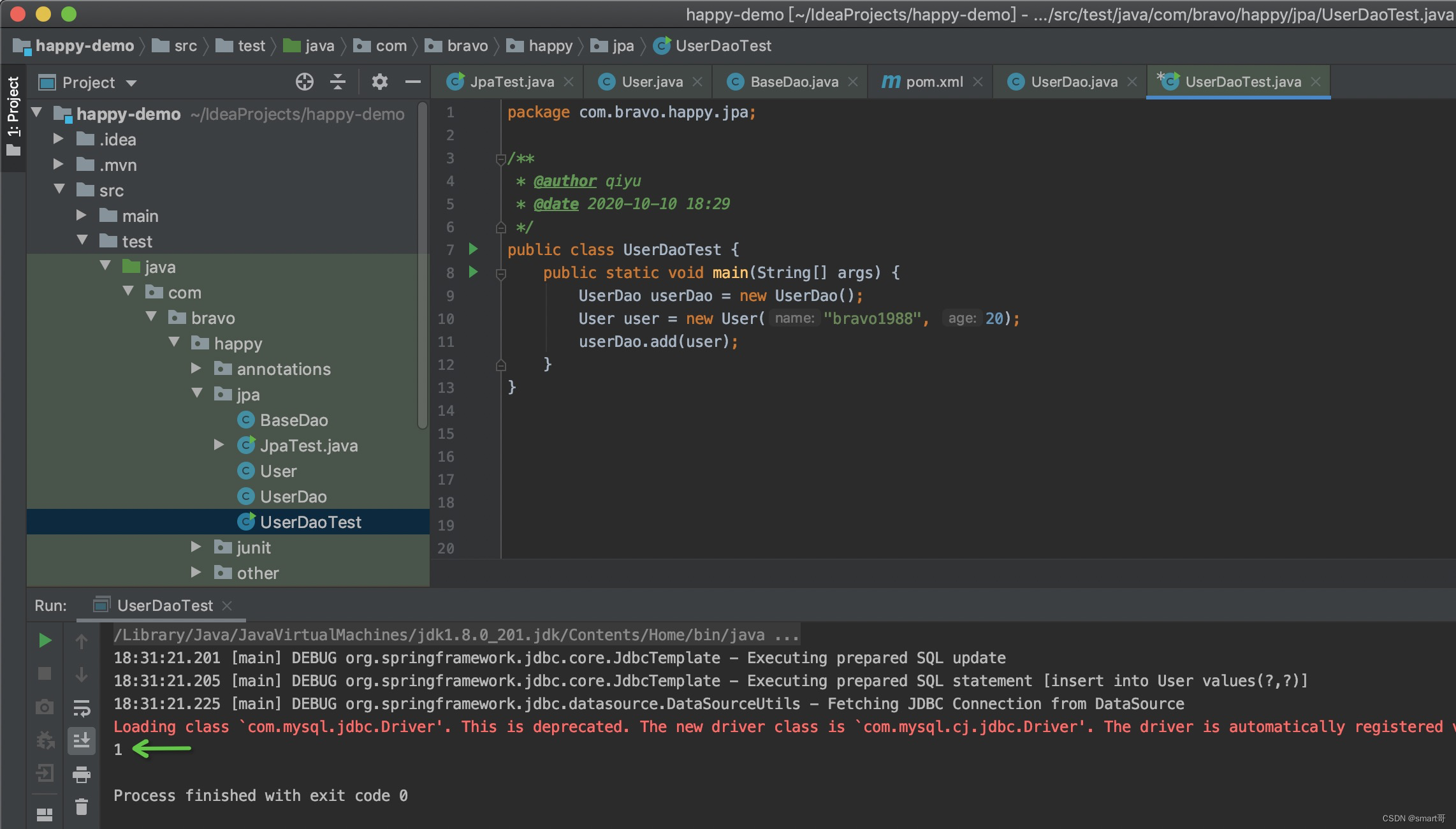
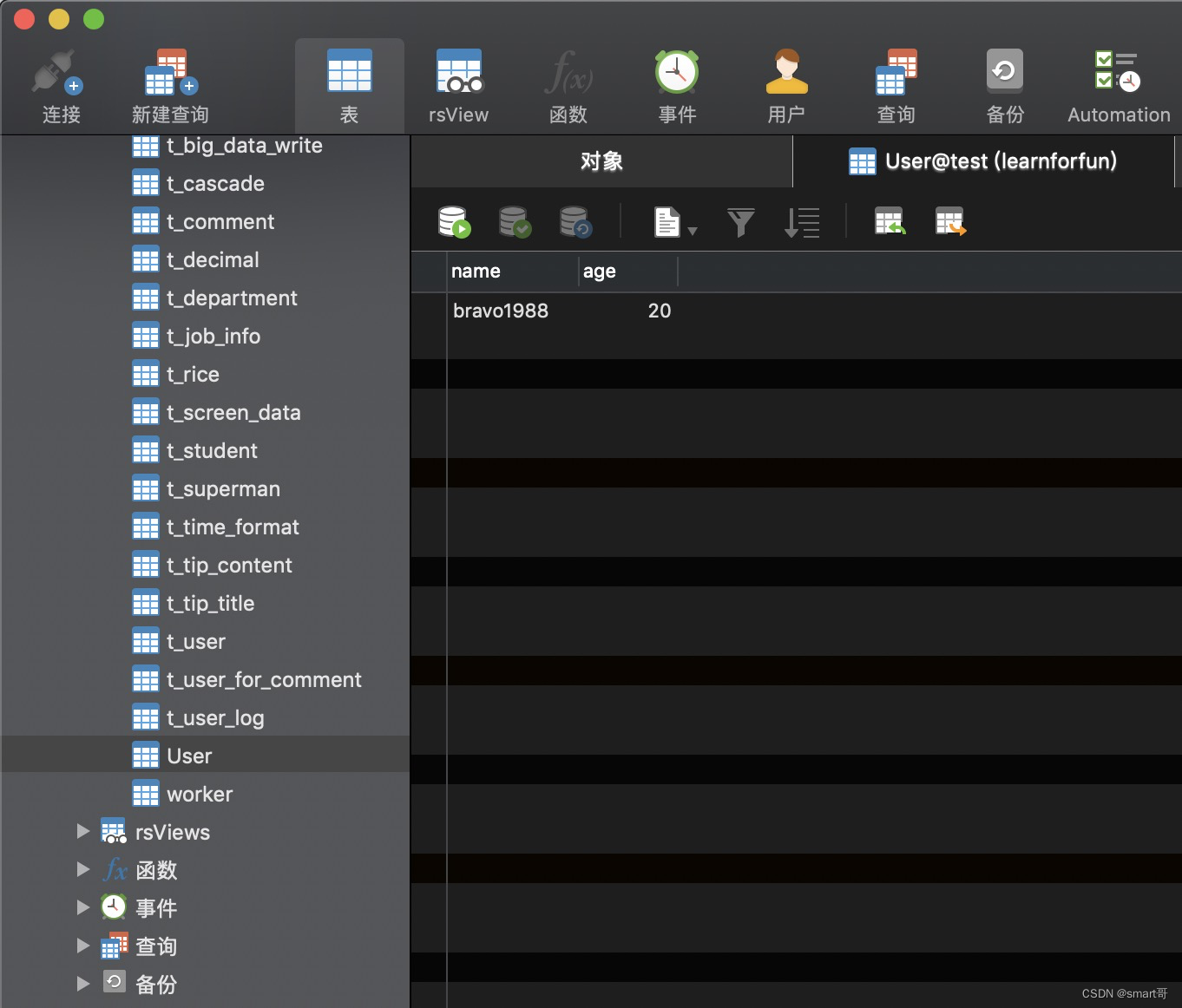
桥多麻袋!这个和JPA有半毛钱关系啊!上一篇的注解都没用上!!
不错,细心的朋友肯定已经发现,我的代码实现虽然不够完美,但是最让人蛋疼的还是:要求数据库表名和POJO的类名一致,不能忍...
第二版JPA
于是,我决定抄袭一下JPA的思路,给我们的User类加一个Table注解,用来告诉程序这个POJO和数据库哪张表对应:
CREATE TABLE `t_jpa_user` (`name` varchar(255) DEFAULT NULL COMMENT '名字',`age` tinyint(4) DEFAULT NULL COMMENT '年龄'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;@Table注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Table {String value();
}新的User类(类名加了@Table注解)



这下真的是山寨JPA了~
另类注解
学习注解时,我们一直强调3个步骤:
- 定义注解
- 使用注解
- 读取注解,完成操作
但实际上,注解最最基本的功能是“标注”,如果我们只需要注解的“标注”功能,不用额外操作时,就可以省略第3步。
比如,日常开发时我们经常需要注明哪些参数可以为null:

此时可以借助注解达到相同甚至更好的效果:
/*** 仅用于标记参数是否可以为null*/
@Target({ElementType.PARAMETER, ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.SOURCE)
@Documented
public @interface Nullable {}

作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬