一、说明
多标签分类是一项具有挑战性的机器学习任务,其中输入可以同时属于多个类。传统的多标签分类方法通常依赖于将问题转化为一系列二元分类任务或使用集成方法。然而,深度学习的出现开创了多标签分类的新时代,ML-Net 等模型突破了该领域的可能性界限。

二、对 ML-Net 的需求
传统的多标签分类方法面临一些局限性。一项重大挑战是处理标签依赖性和相关性,其中一个标签的存在或不存在可能会影响其他标签的可能性。使用传统技术捕获这些依赖性具有挑战性。
此外,随着数据集变得越来越大、越来越复杂,需要能够有效处理高维输入数据和大量输出标签的模型。这就是 ML-Net(一种基于深度学习的方法)发挥作用的地方。
三、了解 ML-Net
ML-Net 是一种专门为多标签分类任务而设计的深度神经网络架构。它由 Tsoumakas 等人开发,利用深度学习的力量来解决传统多标签分类方法的缺点。
3.1 ML-Net 的关键组件
- 嵌入层:ML-Net 通常从嵌入层开始,该嵌入层将离散输入(例如文本或分类数据)转换为连续向量表示。此嵌入过程有助于捕获输入特征之间的语义关系。
- 卷积神经网络 (CNN):CNN 通常在 ML-Net 中用于处理结构化或图像数据。他们擅长学习层次特征,这对于识别多标签分类中的复杂模式至关重要。
- 递归神经网络 (RNN):在涉及序列数据(例如文本或时间序列)的情况下,RNN 可以合并到 ML-Net 中以对时间依赖性和模式进行建模。
- 多标签输出层:ML-Net 的输出层旨在产生多标签预测。通常,每个输出节点使用 sigmoid 激活函数,允许模型独立为每个标签分配概率。
- 损失函数:ML-Net 采用专门的损失函数(通常是二元交叉熵)来解释问题的多标签性质。它鼓励模型准确预测每个标签的存在或不存在。
- 标签嵌入: ML-Net 的显着特征之一是它使用标签嵌入。这些嵌入表示连续向量空间中标签之间的关系,使模型能够有效地捕获标签依赖性和相关性。
3.2 ML-Net的优点
- 标签依赖性:ML-Net 擅长捕获复杂的标签依赖性和相关性,这是多标签分类任务中的关键因素。标签嵌入和深度神经网络的使用使模型能够学习标签之间复杂的关系。
- 可扩展性: ML-Net 可以处理具有大量标签和高维输入数据的大规模多标签分类问题。深度学习模型的可扩展性是当今大数据时代的显着优势。
- 灵活性: ML-Net 是一个灵活的框架,可以适应各种类型的输入数据,包括文本、图像和结构化数据。它的多功能性使其适用于解决广泛的现实问题。
- 最先进的性能: ML-Net 在多标签分类的各种基准数据集上展示了最先进的性能。它超越传统方法的能力使其越来越受欢迎。
3.3 挑战和未来方向
虽然 ML-Net 代表了多标签分类方面的重大进步,但仍然存在需要解决的挑战。其中包括处理不平衡的数据集、减少计算要求和提高可解释性。
ML-Net 的未来方向可能涉及探索更高效的架构、开发处理动态标签集的技术以及增强其可解释性以获得关键应用程序中用户的信任。
四、代码
我可以为您提供一个使用 ML-Net 使用 Python、TensorFlow 和 Keras 进行多标签图像分类的简化示例。请注意,对于具有真实数据集和广泛训练的完整代码,您需要访问带标签的图像数据集,该数据集通常很大并且需要大量计算资源。此示例旨在说明该概念,但您需要根据您的特定数据集和要求进行调整。
在运行代码之前,请确保已安装 TensorFlow 和 Keras。您可以使用 pip 安装它们:
pip install tensorflow keras这是一个基本示例:
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt# Generate synthetic data (replace with your dataset loading code)
# This is just a simple example with random data
num_samples = 1000
num_labels = 5
image_size = (64, 64, 3)X = np.random.rand(num_samples, *image_size)
Y = np.random.randint(2, size=(num_samples, num_labels))# Split the data into training and testing sets
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)# Define ML-Net architecture
input_layer = Input(shape=image_size)
conv1 = Conv2D(32, (3, 3), activation='relu')(input_layer)
max_pool1 = MaxPooling2D((2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu')(max_pool1)
max_pool2 = MaxPooling2D((2, 2))(conv2)
flatten = Flatten()(max_pool2)
dense1 = Dense(128, activation='relu')(flatten)
output_layer = Dense(num_labels, activation='sigmoid')(dense1)model = Model(inputs=input_layer, outputs=output_layer)# Compile the model
model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])# Train the model
history = model.fit(X_train, Y_train, batch_size=32, epochs=10, validation_split=0.2)# Evaluate the model on the test data
test_loss, test_accuracy = model.evaluate(X_test, Y_test)
print(f'Test Loss: {test_loss}, Test Accuracy: {test_accuracy}')# Plot training history
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()此代码演示了如何使用合成数据创建简单的 ML-Net 模型以进行多标签图像分类。您应该用您自己的数据集替换合成数据,并针对您的特定任务对模型架构和超参数进行适当调整。
Test Loss: 0.707078754901886, Test Accuracy: 0.05999999865889549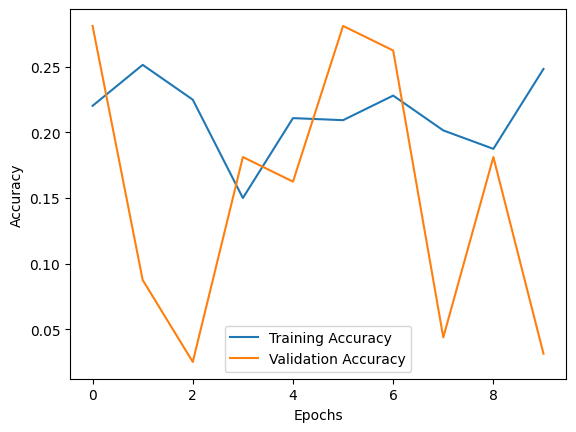
提供的代码还包括训练历史的基本图,显示训练和验证准确性在不同时期的变化情况。
五、结论
ML-Net 证明了深度学习在多标签分类领域带来革命性变革的力量。它能够对复杂的标签依赖关系进行建模并处理大规模、高维数据,这使其成为从文本分类到图像标记等广泛应用的宝贵工具。随着该领域研究的不断发展,ML-Net 及其后继者很可能在塑造多标签分类的未来方面发挥关键作用。埃弗顿戈梅德博士




![[C/C++] 数据结构 LeetCode:用队列实现栈](https://img-blog.csdnimg.cn/80fe4cf53fa4475d8c75f7a3725877b8.png)