Hash算法
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。
Hash算法在安全加密领域MD5、SHA等加密算法,数据存储和查找的Hash表等方面均有应用。Hash表的数据查询效率极高,时间复杂度达到O(1)。Hash表通常使用数组下标与数据进行对应的方式进行存储,查找时,通过数据计算出下标(通常是取模)得到下标,然后通过下标直接访问数据。当然,当数组空间有限时,不同的数据计算出相同的下标的情况必然发生,这种情况叫Hash冲突,而解决Hash冲突的常用方法有开放寻址法、拉链法(常用)。
如下图,1和6这两个数据通过对5取模,得到的下标都是1,发生了Hash冲突。
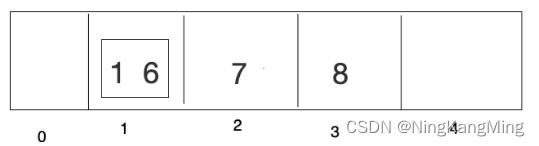
开放寻址法:1放进去了,6再来的时候,向前或者向后找空闲位置存放。但这种方法存在明显缺陷,即数组长度是一定的,当数组被用完时,发生Hash冲突后将无法解决。
拉链法:当发生Hash冲突时,以链表将冲突数据串起来。即数组元素存的一个链表,而不是一个简单数值了。发生Hash冲突时,只需要把新数据放到链表头即可。查找数据时,遍历链表。当然,当链表过长会影响查询性能。此时可以把链表转自平衡二叉查找树(如红黑树,Java8的ConcurrentHashMap 就是使用数组 + 链表 + 红黑树来实现的),这样一来,查询性能将从O(n)降低到 O(log(n))。
Hash算法应用场景
-
安全加密
日常用户密码加密通常使用的都是 md5、sha等哈希函数,因为不可逆,而且微小的区别加密之后的结果差距很大,所以安全性更好。
-
唯一标识
比如 URL 字段或者图片字段要求不能重复,这个时候就可以通过对相应字段值做 md5 处理,将数据统一为 32 位长度从数据库索引构建和查询角度效果更好,此外,还可以对文件之类的二进制数据做 md5 处理,作为唯一标识,这样判定重复文件的时候更快捷。
-
数据校验
比如从网上下载的很多文件(尤其是P2P站点资源),都会包含一个 MD5 值,用于校验下载数据的完整性,避免数据在中途被劫持篡改。
-
散列函数
-
负载均衡
对于同一个客户端上的请求,尤其是已登录用户的请求,需要将其会话请求都路由到同一台机器,以保证数据的一致性,这可以借助哈希算法来实现,通过用户 ID 尾号对总机器数取模(取多少位可以根据机器数定),将结果值作为机器编号。
-
分布式缓存
分布式缓存和其他机器或数据库的分布式不一样,因为每台机器存放的缓存数据不一致,每当缓存机器扩容时,需要对缓存存放机器进行重新索引((参考redis分片集群扩容hash槽重分配) ),这里应用到的也是哈希算法的思想。
普通Hash算法存在的问题
普通Hash算法应用在分布式环境中会存在比较大的问题,比如通过Hash算法将同一会话的客户端路由到相同的服务器上,实现会话保持。当服务器扩缩容时,客户端需要重新取服务器数量进行取模得到Hash索引,确定目标服务器,这时,这些客户端的会话会丢失。(当然,实际的会话保持通常会通过分布式缓存,如redis来实现)。如何将服务器的扩缩容的影响减到最小?这就是一致性Hash算法需要解决的问题。
一致性Hash算法
一致性Hash算法思路如下:
将0到2^32-1作为Hash环,即原本是对有限的服务器数量进行取模,现在是对2^32进行取模,这样取模结果范围更广了,也就是Hash环更大了。这样一来,生产中不可能会使用2^32这么多服务器,扩缩容对客户端的影响是很小的。客户端访问时,是将客户端IP地址对2^32取模,然后得出一个索引值,根据这个值,顺时针找最近的服务器节点,如下图
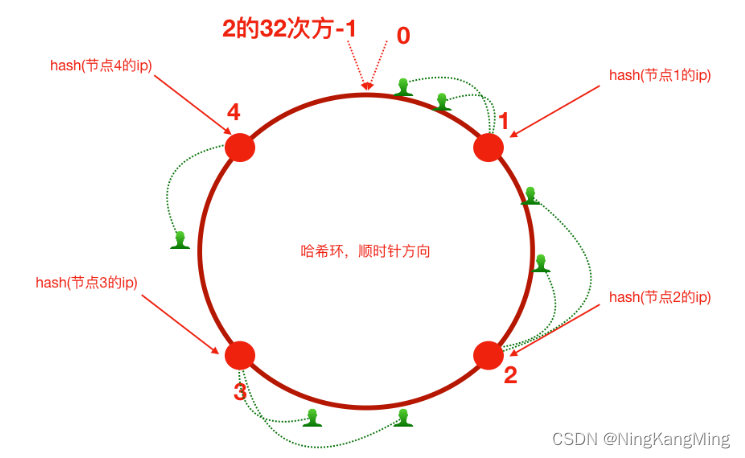
假设服务器3下线,原来路由到3的客户端重新路由到服务器4,这样一来,影响到的只是原来路由到服务器3的这部分客户端,这在分布式系统里非常有用,避免了大量请求迁移。
1)如前所述,每一台服务器负责一段,一致性Hash算法对于节点的增减都只需要重定位环空间的一小部分数据,具有较好的容错性和可扩展性。
但是一致性哈希算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜问题。比方说按顺时针的情况下,服务节点1和2很近,1到2的区间的客户端由服务器2负责,然后剩下的大区间只能由1负责,这就是数据都倾斜到服务节点1上了。
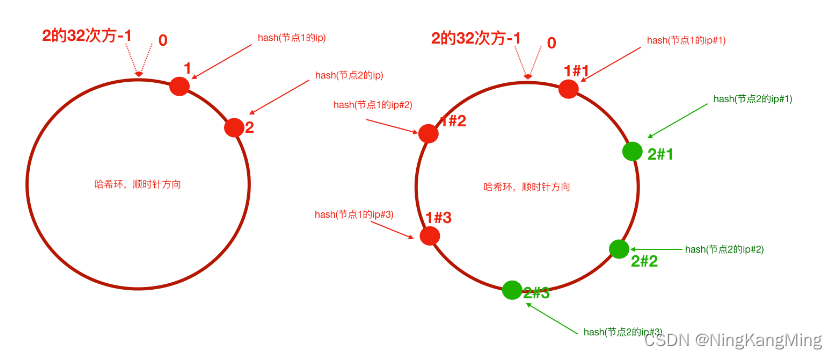
2)为了解决这种数据倾斜问题,一致性哈希算法引入 了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
具体做法可以在服务器IP或主机名的后面增加编号来实现。比如,可以为每台服务器计算三个虚拟节点,于是可以分别诸“节点1的IP#1”、“节点1的IP#2”、“节点1的IP#3”的哈希值,于是形成六个虚拟节点,当客户端被路由到虚拟节点的时候其实是被路由到该虚拟节点所对应的真实节点。
nginx配置一致性Hash负载均衡策略
ngx_http_upstream_consistent_hash模块是一个负载均衡器,通过一致性Hash算法来为客户端选择合适的后端节点。
该模块可以根据配置参数采取不同的方式将请求均匀映射到后面机器。
consistent_hash $remote_addr :根据客户端IP映射
consistent_hash $request_uri :根据客户端uri映射
consistent_hash $args :根据客户端携带的参数进行映射
ngx_http_upstream_consistent_hash是一个第三方模块,需要我们下载安装后使用
1,下载
https://github.com/replay/ngx_http_consistent_hash
2,编译nginx(进入nginx的源码目录)
./configure —add-module=/root/ngx_http_consistent_hash-master make make install
3,配置使用
upstream test_server_nodes {#ip_hash;consistent_hash $request_uri;server 192.168.43.71:7771;server 192.168.43.72:7772;
}