1 安装相关依赖库
yum install -y gcc gcc-c++ make m4 libtool boost-devel zlib-devel openssl-devel libcurl-devel- yum:是yellowdog updater modified 的缩写,Linux中的包管理工具
- gcc:一开始称为GNU C Compiler,也就是一个C编译器,后来因为这个项目里集成了更多其他不同语言的编译器,所以就不再只是C编译器,而称为GNU编译器套件(GCC,GNU Compiler Collection),表示一堆编译器的合集
- gcc-c++:是GCC编译器合集里的C++编译器。
- make:是gcc的编译器,m4:是一个宏处理器.将输入拷贝到输出,用来引用文件,执行命令,整数运算,文本操作,循环等.既可以作为编译器的 前端,也可以单独作为一个宏处理器。
- libtool:是一个通用库支持脚本,作用是在编译大型软件的过程中解决了库的依赖问题;将繁重的库依赖关系的维护工作承担下来,提供统一的接口,隐藏了不同平台间库的名称的差异等。安装libtool会自动安装所依赖的automake和autoconfig。
- autoconf:是用来生成自动配置软件源代码脚本(configure)的工具.configure脚本能独立于autoconf运行。
- Automake:会根据源码中的Makefile.am来自动生成Makefile.in文件,Makefile.am中定义了宏和目标,运行automake命令会生成Makefile文件,然后使用make命令编译代码。
- boost-devel zlib-devel openssl-devel libcurl-devel:都是编译时所依赖的库。
2 下载源码
由于Tair依赖tbsys和tbnet库,需要安装这两个库,而这两库需要编译tb-common-utils安装
安装git:
yum install -y git从码云上下载tb-common-utils源码:
git clone https://gitee.com/abc0317/tb-common-utils.git进入tb-common-utils目录
cd tb-common-utils/赋予执行权限
chmod u+x build.sh指定TBLIB_ROOT环境变量 TBLIB_ROOT为需要安装的目录。
export TBLIB_ROOT=/root/tairlib进入源码目录, 执行build.sh进行安装
sh build.sh从码云上下载Tair源码:
cd ~
git clone https://gitee.com/mirrors/Tair.git3 编译安装Tair
cd Tair编译依赖
./bootstrap.sh检测和生成 Makefile (默认安装位置是 ~/tair_bin, 修改使用 --prefix=目标目录)
./configure编译和安装到目标目录
make -j && make install3 配置Tair
基于MDB内存引擎,采用最小化配置方式,1个ConfigServer,1个DataServer搭建Tair集群。
由于MDB 引擎默认使用共享内存,所以需要查看并设置系统的tmpfs的大小,tmpfs是Linux/Unix系统上的一种基于内存的虚拟文件系统。
df -h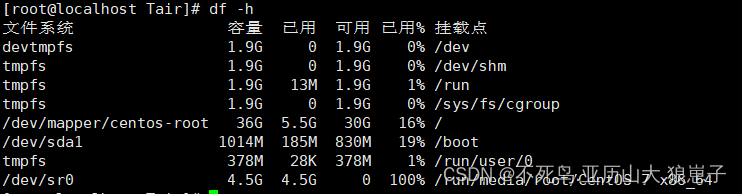
/dev/shm 目录位于 linux 系统的内存中,而不在磁盘里,所以它的效率非常高,这里我们将大小设置1G,
修改/etc/fstab 的这行,如果没有就在末尾加一行
vim /etc/fstab将
tmpfs /dev/shm tmpfs defaults 0 0改为
tmpfs /dev/shm tmpfs defaults,size=1G 0 0改完之后,执行mount使其生效
mount -o remount /dev/shm生效后再使用df -h 查看

切换到Tair安装目录,拷贝默认配置文件准备修改
cd /root/tair_bin/etc
mv configserver.conf.default configserver.conf
mv group.conf.default group.conf
mv dataserver.conf.default dataserver.conf4 修改configserver.conf
[public]
# 主备 ConfigServer 的地址和端口号,第一行为主,第二行为备,目前采用最简单集群只配置一个ConfigServer
#config_server=192.168.1.1:5198
#config_server=192.168.1.2:5198
config_server=192.168.222.154:5198[configserver]
# ConfigServer 的工作端口号,和上面的配置以及 dataserver.conf 里的要一致
port=5198
# 日志文件位置
log_file=logs/config.log
# pid 存储的文件位置
pid_file=logs/config.pid
# 默认日志级别
log_level=warn
# group.conf 文件的位置
group_file=etc/group.conf
# 运行时状态持久化文件的位置
data_dir=data/data
# 使用的网卡设备名设置为你自己当前网络接口的名称,默认为eth0
# 如果不是当前接口网卡会报错'local ip:0.0.0.0, check your `dev_name', `bond0' is preferred if present'
dev_name=ens33
5 修改group.conf
#group name
# 集群分组的名字,tair 支持一组 ConfigServer 管理多个集群 (不建议,避免流量瓶颈在 ConfigServer 上)
#[group_1]
[group_test]# data move is 1 means when some data serve down, the migrating will be start.
# default value is 0
# 是否允许数据迁移,双份数据情况下,要设置为 1 (内部逻辑判断是双份的话,内部也会强制置为1)
_data_move=0
#_min_data_server_count: when data servers left in a group less than this value, config server will stop serve for this group
#default value is copy count.
# 过载保护的参数,当可用的 DataServer 节点少于这个数字时,ConfigServer 不再自动检测宕机并重建路由表(避免逐台击穿而雪崩)
_min_data_server_count=1
#_plugIns_list=libStaticPlugIn.so
# 建表算法的选择和一些参数,一般默认即可
_build_strategy=1 #1 normal 2 rack
_build_diff_ratio=0.6 #how much difference is allowd between different rack
# diff_ratio = |data_sever_count_in_rack1 - data_server_count_in_rack2| / max (data_sever_count_in_rack1, data_server_count_in_rack2)
# diff_ration must less than _build_diff_ratio
_pos_mask=65535 # 65535 is 0xffff this will be used to gernerate rack info. 64 bit serverId & _pos_mask is the rack info,
# 数据的备份数,注意集群一旦初始化,不能修改这个值
_copy_count=1
# 虚拟节点的个数,当集群机器数量很多时,可以调整这个值
# 注意一旦集群初始化完毕,这个值不能修改
_bucket_number=1023
# accept ds strategy. 1 means accept ds automatically
# 该文件的修改会触发 ConfigServer 自动 reload,下面的参数控制是否自动加入本文件新增的 DataServer 节点到集群
# _min_data_server_count 参数也会影响,如果节点总数小于 _min_data_server_count,也不会自动加入
_accept_strategy=1
# 是否允许 failover 机制
# 这个机制工作在 LDB 引擎模式的集群下,当 _min_data_server_count 参数大于集群机器数(阻止自动剔除宕机机器)时,
# 如果该参数为1,宕机的第一个节点会进入 failover 模式,此时备机接管读写请求,同时记录恢复日志,当宕机节点恢复时,
# 自动进入 recovery 模式,根据恢复日志补全数据。注意此时第二台如果宕机,不会自动处理,所以第一台一旦宕机收到告警,
# 请尽快人为干预处理。 **failover 机制想正常工作,需要 dataserver.conf 的 do_dup_depot 为 1 才可以**
_allow_failover_server=0# 下面是 DataServer 节点列表,注释 data center A/B 并不是集群组的概念
# 集群组的配置是当前这个文件所有内容,复制整个内容追加到本文件尾部,可以添加一个集群组
# 注意一个节点不能出现在两个集群组里!配置文件不做该校验。
# data center A
#_server_list=192.168.1.1:5191
#_server_list=192.168.1.2:5191
#_server_list=192.168.1.3:5191
#_server_list=192.168.1.4:5191
_server_list=192.168.222.154:5191# data center B
#_server_list=192.168.2.1:5191
#_server_list=192.168.2.2:5191
#_server_list=192.168.2.3:5191
#_server_list=192.168.2.4:5191#quota info
# 配额信息
# 当引擎是 MDB 时,控制每个 Namespace 的内存配额,单位是字节
# Tair 支持 0~65535 的 Namespace 范围,每个 Namespace 内部的 key 命名空间隔离
# 代码中出现的 area 是 Namespace 的同义词
_areaCapacity_list=0,1124000;6 dataserver.conf
#
# tair 2.3 --- tairserver config
#
[public]
# 主备 ConfigServer 的地址
#config_server=192.168.1.1:5198
#config_server=192.168.1.2:5198
config_server=192.168.222.154:5198[tairserver]
#
#storage_engine:
#
# mdb
# ldb
#
# 使用的引擎,支持 MDB 和 LDB
storage_engine=mdb
local_mode=0
#
#mdb_type:
# mdb
# mdb_shm
#
# 如果引擎是 MDB,这里选择使用普通内存还是共享内存
mdb_type=mdb_shm# shm file prefix, located in /dev/shm/, the leading '/' is must
# MDB 实例的命名前缀,一般在单机部署多个节点时需要修改
mdb_shm_path=/mdb_shm_inst
# (1<<mdb_inst_shift) would be the instance count
# MDB 引擎的实例个数,多个实例减少锁竞争但是会增加元数据而浪费内存
#mdb_inst_shift=3
mdb_inst_shift=0# (1<<mdb_hash_bucket_shift) would be the overall bucket count of hashtable
# (1<<mdb_hash_bucket_shift) * 8 bytes memory would be allocated as hashtable
# MDB 实例内部 hash 表的 bucket 数,24~27均可(取决于实例大小)
mdb_hash_bucket_shift=24
# milliseconds, time of one round of the checking in mdb lasts before having a break
mdb_check_granularity=15
# increase this factor when the check thread of mdb incurs heavy load
# cpu load would be around 1/(1+mdb_check_granularity_factor)
mdb_check_granularity_factor=10#tairserver listen port
port=5191supported_admin=0
# 工作时的 IO 线程数和 Worker 线程数
#process_thread_num=12
process_thread_num=4#io_thread_num=12
io_thread_num=4# 双份数据时,往副本写数据的 IO 线程数,只能是 1
dup_io_thread_num=1
#
#mdb size in MB
#
# MDB 引擎使用的存储数据的内存池总大小 这里 slab_mem_size控制MDB内存池的总大小,mdb_inst_shift 控制实例的个数,每个实例的大小是 slab_mem_size/(1 << mdb_inst_shift) MB,注意这里一个实例必须大于512MB且小于64GB
#slab_mem_size=4096
slab_mem_size=512log_file=logs/server.log
pid_file=logs/server.pidis_namespace_load=1
is_flowcontrol_load=1
tair_admin_file = etc/admin.conf# 是否在put操作遍历 hash 表冲突链时,顺带删除已经 expired 的数据
# 会导致 put 的时延增大一点点,但是有利于控制过期数据很多的场景下内存增幅
put_remove_expired=0
# set same number means to disable the memory merge, like 5-5
mem_merge_hour_range=5-5
# 1ms copy 300 items
mem_merge_move_count=300log_level=warn
# 改为当前接口
# 如果不是当前接口网卡会报错'local ip:0.0.0.0, check your `dev_name', `bond0' is preferred if present'
dev_name=ens33
ulog_dir=data/ulog
ulog_file_number=3
ulog_file_size=64
check_expired_hour_range=2-4
check_slab_hour_range=5-7
dup_sync=1
dup_timeout=500# 是否使用 LDB 集群间的数据自动同步
do_rsync=0rsync_io_thread_num=1
rsync_task_thread_num=4rsync_listen=1
# 0 mean old version
# 1 mean new version
# 这里只能是 1
rsync_version=1
# 同步的详细配置地址,也可以使用 file:// 来指定本地磁盘的配置位置
rsync_config_service=http://localhost:8080/hangzhou/group_1
rsync_config_update_interval=60# much resemble json format
# one local cluster config and one or multi remote cluster config.
# {local:[master_cs_addr,slave_cs_addr,group_name,timeout_ms,queue_limit],remote:[...],remote:[...]}
# rsync_conf={local:[10.0.0.1:5198,10.0.0.2:5198,group_local,2000,1000],remote:[10.0.1.1:5198,10.0.1.2:5198,group_remote,2000,800]}
# if same data can be updated in local and remote cluster, then we need care modify time to
# reserve latest update when do rsync to each other.
rsync_mtime_care=0
# rsync data directory(retry_log/fail_log..)
rsync_data_dir=./data/remote
# max log file size to record failed rsync data, rotate to a new file when over the limit
rsync_fail_log_size=30000000
# when doing retry, size limit of retry log's memory use
rsync_retry_log_mem_size=100000000# depot duplicate update when one server down
# failover 机制的 DataServer 开关,见 group.conf 相关说明
do_dup_depot=0
dup_depot_dir=./data/dupdepot# 默认的流控配置,total 为整机限制
[flow_control]
# default flow control setting
default_net_upper = 30000000
default_net_lower = 15000000
default_ops_upper = 30000
default_ops_lower = 20000
default_total_net_upper = 75000000
default_total_net_lower = 65000000
default_total_ops_upper = 50000
default_total_ops_lower = 40000[ldb]
#### ldb manager config
## data dir prefix, db path will be data/ldbxx, "xx" means db instance index.
## so if ldb_db_instance_count = 2, then leveldb will init in
## /data/ldb1/ldb/, /data/ldb2/ldb/. We can mount each disk to
## data/ldb1, data/ldb2, so we can init each instance on each disk.
data_dir=data/ldb
## leveldb instance count, buckets will be well-distributed to instances
ldb_db_instance_count=1
## whether load backup version when startup.
## backup version may be created to maintain some db data of specifid version.
ldb_load_backup_version=0
## whether support version strategy.
## if yes, put will do get operation to update existed items's meta info(version .etc),
## get unexist item is expensive for leveldb. set 0 to disable if nobody even care version stuff.
ldb_db_version_care=1
## time range to compact for gc, 1-1 means do no compaction at all
ldb_compact_gc_range = 3-6
## backgroud task check compact interval (s)
ldb_check_compact_interval = 120
## use cache count, 0 means NOT use cache,`ldb_use_cache_count should NOT be larger
## than `ldb_db_instance_count, and better to be a factor of `ldb_db_instance_count.
## each cache mdb's config depends on mdb's config item(mdb_type, slab_mem_size, etc)
ldb_use_cache_count=1
## cache stat can't report configserver, record stat locally, stat file size.
## file will be rotate when file size is over this.
ldb_cache_stat_file_size=20971520
## migrate item batch size one time (1M)
ldb_migrate_batch_size = 3145728
## migrate item batch count.
## real batch migrate items depends on the smaller size/count
ldb_migrate_batch_count = 5000
## comparator_type bitcmp by default
# ldb_comparator_type=numeric
## numeric comparator: special compare method for user_key sorting in order to reducing compact
## parameters for numeric compare. format: [meta][prefix][delimiter][number][suffix]
## skip meta size in compare
# ldb_userkey_skip_meta_size=2
## delimiter between prefix and number
# ldb_userkey_num_delimiter=:
####
## use blommfilter
ldb_use_bloomfilter=1
## use mmap to speed up random acess file(sstable),may cost much memory
ldb_use_mmap_random_access=0
## how many highest levels to limit compaction
ldb_limit_compact_level_count=0
## limit compaction ratio: allow doing one compaction every ldb_limit_compact_interval
## 0 means limit all compaction
ldb_limit_compact_count_interval=0
## limit compaction time interval
## 0 means limit all compaction
ldb_limit_compact_time_interval=0
## limit compaction time range, start == end means doing limit the whole day.
ldb_limit_compact_time_range=6-1
## limit delete obsolete files when finishing one compaction
ldb_limit_delete_obsolete_file_interval=5
## whether trigger compaction by seek
ldb_do_seek_compaction=0
## whether split mmt when compaction with user-define logic(bucket range, eg)
ldb_do_split_mmt_compaction=0## do specify compact
## time range 24 hours
ldb_specify_compact_time_range=0-6
ldb_specify_compact_max_threshold=10000
## score threshold default = 1
ldb_specify_compact_score_threshold=1#### following config effects on FastDump ####
## when ldb_db_instance_count > 1, bucket will be sharded to instance base on config strategy.
## current supported:
## hash : just do integer hash to bucket number then module to instance, instance's balance may be
## not perfect in small buckets set. same bucket will be sharded to same instance
## all the time, so data will be reused even if buckets owned by server changed(maybe cluster has changed),
## map : handle to get better balance among all instances. same bucket may be sharded to different instance based
## on different buckets set(data will be migrated among instances).
ldb_bucket_index_to_instance_strategy=map
## bucket index can be updated. this is useful if the cluster wouldn't change once started
## even server down/up accidently.
ldb_bucket_index_can_update=1
## strategy map will save bucket index statistics into file, this is the file's directory
ldb_bucket_index_file_dir=./data/bindex
## memory usage for memtable sharded by bucket when batch-put(especially for FastDump)
ldb_max_mem_usage_for_memtable=3221225472
######## leveldb config (Warning: you should know what you're doing.)
## one leveldb instance max open files(actually table_cache_ capacity, consider as working set, see `ldb_table_cache_size)
ldb_max_open_files=65535
## whether return fail when occure fail when init/load db, and
## if true, read data when compactiong will verify checksum
ldb_paranoid_check=0
## memtable size
ldb_write_buffer_size=67108864
## sstable size
ldb_target_file_size=8388608
## max file size in each level. level-n (n > 0): (n - 1) * 10 * ldb_base_level_size
ldb_base_level_size=134217728
## sstable's block size
# ldb_block_size=4096
## sstable cache size (override `ldb_max_open_files)
ldb_table_cache_size=1073741824
##block cache size
ldb_block_cache_size=16777216
## arena used by memtable, arena block size
#ldb_arenablock_size=4096
## key is prefix-compressed period in block,
## this is period length(how many keys will be prefix-compressed period)
# ldb_block_restart_interval=16
## specifid compression method (snappy only now)
# ldb_compression=1
## compact when sstables count in level-0 is over this trigger
ldb_l0_compaction_trigger=1
## whether limit write with l0's filecount, if false
ldb_l0_limit_write_with_count=0
## write will slow down when sstables count in level-0 is over this trigger
## or sstables' filesize in level-0 is over trigger * ldb_write_buffer_size if ldb_l0_limit_write_with_count=0
ldb_l0_slowdown_write_trigger=32
## write will stop(wait until trigger down)
ldb_l0_stop_write_trigger=64
## when write memtable, max level to below maybe
ldb_max_memcompact_level=3
## read verify checksum
ldb_read_verify_checksums=0
## write sync log. (one write will sync log once, expensive)
ldb_write_sync=0
## bits per key when use bloom filter
#ldb_bloomfilter_bits_per_key=10
## filter data base logarithm. filterbasesize=1<<ldb_filter_base_logarithm
#ldb_filter_base_logarithm=12[extras]
######## RT-related ########
#rt_oplist=1,2
# Threashold of latency beyond which would let the request be dumped out.
rt_threshold=8000
# Enable RT Module at startup
rt_auto_enable=0
# How many requests would be subject to RT Module
rt_percent=100
# Interval to reset the latency statistics, by seconds
rt_reset_interval=10######## HotKey-related ########
hotk_oplist=2
# Sample count
hotk_sample_max=50000
# Reap count
hotk_reap_max=32
# Whether to send client feedback response
hotk_need_feedback=0
# Whether to dump out packets, caches or hot keys
hotk_need_dump=0
# Whether to just Do Hot one round
hotk_one_shot=0
# Whether having hot key depends on: sigma >= (average * hotk_hot_factor)
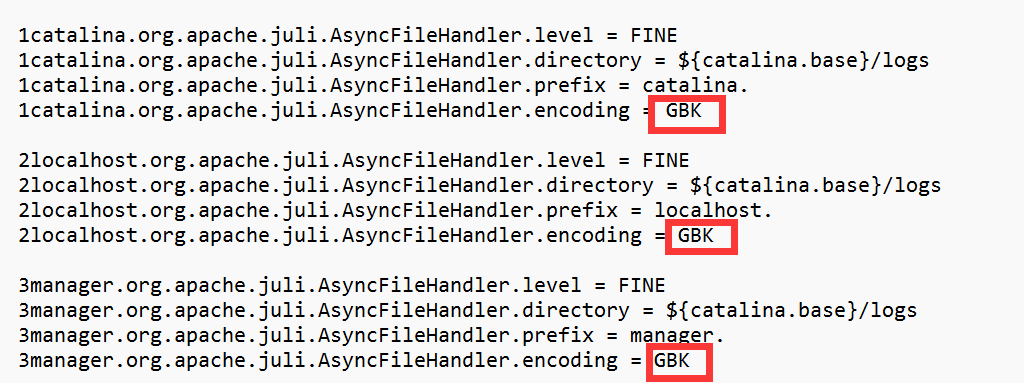
hotk_hot_factor=0.8在CentOS 7下,安装目录下的 tair.sh 启动脚本有一行代码(55行)需要修改
tmpfs_size=`df -m |grep tmpfs | awk '{print $2}'`
#这行改成下面这一行
tmpfs_size=`df -m |grep /dev/shm | awk '{print $2}'`7 启动Tair实例
tair启动需要跟参数,直接使用./tair.sh命令效果如下:
![]()
start_ds启动数据节点
./tair.sh start_dsstart_cs启动config配置节点
./tair.sh start_cs查看启动
ps -ef | grep tair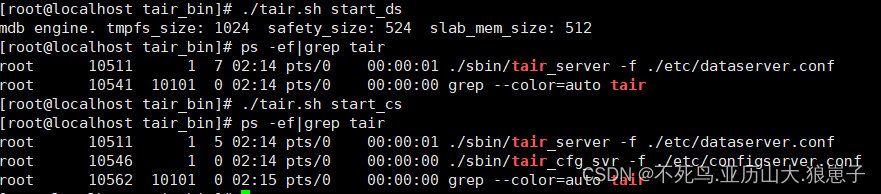
8 使用自带客户端测试读写
./sbin/tairclient -c 192.168.222.154:5198 -g group_test写入数据测试
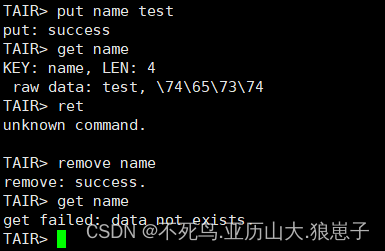
9 停止tair服务
停止数据节点
./tair.sh stop_ds停止配置节点
./tair.sh stop_cs





![[UNILM]论文实现:Unified Language Model Pre-training for Natural Language.........](https://img-blog.csdnimg.cn/direct/bdb2bfeb4c9b41ada63ef02eb2e2200c.png)