要点一:数据与智能的关系
1. 一切的核心都是数据,数据和智能之间是密切相关的。
数据是对客观现实的描述,而信息是数据转化而来的。
例如,24是数据,但说“今天的气温是24摄氏度”是信息,而说“班可以分成24个小组”是数据。
2. 数据和信息是可以互相转化的,人类通过人类的语义结构(semantics)来赋予数据信息。
处理数据成为信息是由人类主观导向的,加入了对数据的理解和认知。
3.信息可以通过观察现象总结出结论,形成理论。两个关键词:phenomenon和theory。知识体系是由现象和理论的循环构成的, 理论对现象可以进行验证、修正或解释,理论对现象的作用包括检验、预测和解释, 知识通过变成信息,再变成智能。
要点二:人工智能和数据的关系
人工智能是基于知识库和新现象的探索,通过不断提升自身能力来实现智能;大数据和人工智能之间存在深层次联系;人工智能在画图等方面展现出了技术能力,但有时也会出现别扭的效果,引发恐怖谷现象;恐怖谷理论解释了为何人物模型越像人越受欢迎的规律;人工智能和数据在行为学和组织行为方面也有涉及。
1.智能产生的基础本质上还是人类的知识库还是人类的知识库。
2.恐怖谷效应。有些人物模型精细的图片会让人感到别扭,这种现象被称为恐怖谷效应。恐怖谷理论解释了为什么AI在某一阈值后会被人们反感。恐怖谷效应不仅仅存在于计算机图形领域,也存在于其他领域,如游戏、毛绒玩具等。恐怖谷效应的原因是人对于陌生、不熟悉的事物会感到不适,但随着迭代精度的提高,人们逐渐接受了这种现象。恐怖谷效应是一个跨学科的概念,涉及到技术、管理、组织等多个维度。



要点三:大数据专业学习指南※


1. 学习数据分析需要掌握数据的存储、清洗和处理(可视化、数据挖掘、最优化)等技能。
2. 建议学习《数据库系统概论》(王珊和萨世轩)和《数据挖掘概念与技术》(韩家伟)两本书,解决数据存储和分析问题。学习PYTHON编程语言,可以使用B站上的教程(小甲鱼)或者《零基础入门学PYTHON 》一书。
3. 对于计算机专业的同学,建议学习《普林斯顿微积分读本》和《韩江磊的算法基础课》等课程。有人觉得数学难,但有人建议可以尝试普林斯顿微积分教材。


要点四:大数据的学习定义
1. 麦肯锡公司将大数据定义为数据量过大且复杂到无法使用传统工具处理的数据集合。Gartner公司将大数据定义为具有高数量、高速度和高延伸性特性的数据集合。
每天人类社会产生的数据量约为2.5QB级别,其中2的10次方就是1024。主要原因是设备多、信息内存大以及延展性高。
大数据指的是数据量大(volume)且类型多样的数据(variety)、第三个(velocity)是流动的。然后我们今天的流媒体数据是很常见的.数据的类型比较复杂、流媒体数据是常见的、数据是不确定的这些特性共同出现时,是大数据。

2. 传统的分析问题方式是通过观察现象提出问题,然后收集数据验证观点。大数据分析方式是通过左手的数据和右手的算法,将算法应用于数据中得出结果。大数据分析可以挖掘隐藏的模式和有用的信息,提高决策和预测的准确性。




要点五:数据可视化和数据挖掘的分类聚类关联※
1. 数据分析部分的逻辑是先解决过去和现在的问题,即可视化。 接下来是预测和规范。



2. 数据可视化工具可以展示过去和现在的数据情况,具备一定的解释性。
类型一:理解和修改已有代码即可
A.Matplotlib — Visualization with Python
左边是各种类型的图,如饼图、柱状图、条形图、散点图和气泡图。选择一种图形后,可以进入相应的界面,其中包含PYTHON代码。这些图形可以通过使用jupiter notebook来实现。
B.seaborn
https://seaborn.pydata.org/
类型二:导入数据(在进行改动,难度比全改简单)
绘制网页(图形比较复杂之后可以借用这些形式):
Apache ECharts(还需要改代码)
chartcool:(有些不免费)(https://www.ichartcool.com/zh/index.html)







左边是代码,右边是显示。代码是JavaScript和TypeScript两种不同的编码体系。这种平台适合处理复杂的图形,比如流动的图形和公交路线图。还有一个工具叫做Chat库,更适合用户使用。



要点六:数据挖掘
1. 数据挖掘处理的问题是什么?解决what will happen和why will happen。数据挖掘解决的问题是站在数据可视化的基础上。

A.对数据挖掘的总体印象
数据挖掘是基于数字的,可以将文字和网页转化为数字进行处理。数据挖掘里边你看这有data mining、test mining和web mining。这东西就是数据挖掘,文本挖掘和网页挖掘,一切的核心都是数据挖掘,可以使用数学模型将文字转化为数字。
图形可以通过RGB编码标准将其转化为数字。
数据挖掘可以处理不同类型的数据,如文字、图像、音频和视频。

B.数据挖掘是挖隐藏的模适合关系,数据挖掘的任务可以分为分类、聚类和关联三类。
不同的数据挖掘算法服务于不同的任务,如人工神经网络适用于分类任务,遗传算法适用于聚类任务。
数据挖掘的目标是挖掘隐藏的模式和关系,通过对数据进行分析和整理,实现对数据的预测和决策。
数据挖掘的应用范围广泛,包括抖音推荐、头条搜索、AI画图和特斯拉自动驾驶等。
数据挖掘需要掌握经典算法和数据库数据挖掘等技术,以实现对大量数据的分析和挖掘。

3.算法的基础与应用
A.万物皆算法,包括西红柿炒鸡蛋和人的行为,感知和视觉神经传输是一种算法。算法是指完成一项任务的步骤和规范。人工智能可以通过算法实现各种事情。

B.关联问题解释了淘宝购物车中的商品关系,类似于商业领域中的购物篮分析。 聚类问题解释了机器视觉中的目标识别和扫地机器人如何看到世界。 分类问题解释了自动驾驶中的复杂问题,如chatgpt。


讨论了一个分数叫做支持度,它表示某个事物在某个方面的得分情况。例如,假设有八张购物小票,每张小票代表一个支持度分数,表示在购买的物品中,面包的得分情况。具体来说,支持度分数是N分之X,其中N代表购物小票的数量,X代表面包的出现次数。因此,面包的支持度分数是8分之X,表示在这八张购物小票中,面包出现了8次。


支持度表示两个物品之间的关系,支持度越大关系越大。置信度来解决无法理解的复杂公式或定义的问题。
4. 这个技巧可以用于其他课程中难以理解的公式或定义。




4.如何将算法细化为PYTHON代码。
强调了掌握算法和数学的重要性。 提到了分析现实问题的步骤,包括讲算法、细化为PYTHON代码、导入数据和跑出结果。


5. 提到了Apriori算法,是一个代表性的三页分析的四最后一页是整合的。

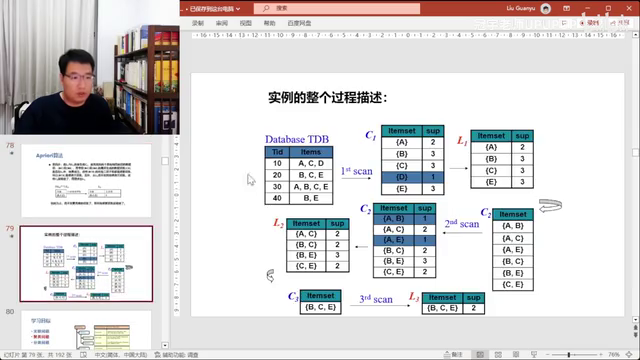


频繁出现的物品集的子集一定是频繁的;不频繁出现的物品级的超级它一定不频繁。比如:电池不频繁出现,所以它和其他物品的组合也不频繁。



6. 聚类问题是指将散列的点分成若干堆,通过衡量点与中心点的距离来确定堆的分组。 聚类算法可以帮助找出数据中相似的群体,并观察他们的共同特性。聚类算法在日常生活中的应用包括推荐商品、了解用户购买偏好等。
机器人的视觉聚类问题是通过将不同像素格的RGB数字进行聚类,分出不同的层次。人眼和机器人的视觉看到的世界是一样的,但在大脑中的还原过程可能存在差异,这需要通过聚类算法来解决。
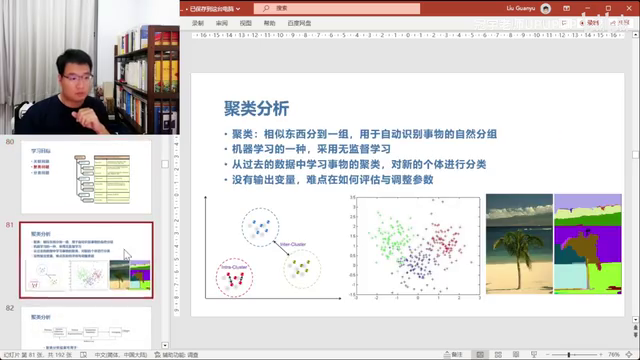


7.分类问题及神经网络的实现
分类的过程需要借助历史数据和新数据的特征来进行训练和分类。训练分类器是分类问题的一个重要部分,通过训练分类器,可以将新数据分成不同的组。



A. 人类大脑中有大量的神经元,每个神经元与其他神经元相连。神经元的放电时间为1秒钟,而计算机晶体管的放电时间为10的负10次方秒,是神经元的七倍快。人类的视觉识别速度为0.1秒,而计算机目前无法达到这个速度。
神经网络在处理重复和复杂问题时比计算机快,但在没有训练过的情况下,计算机仍然比人类快。自动驾驶利用神经网络识别路况并让车辆进行相关操作,未来的5G时延可以实现在云端处理。

神经网络和自动驾驶


B.遗传算法是一种简单的迭代方法,可以用于人工选择。


遗传算法的上限非常高,可以帮助解决不知道结果的问题。 遗传算法可以在不断迭代中帮助解决实验中的问题.遗传算法可以用于解决各种问题,包括组合数学和计算机科学领域的问题。


要点七:数据挖掘和自然语言处理的影响
用户在抖音和头条上的操作也是遗传算法的筛选过程,最终决定了推送的内容。通过不断迭代,用户的偏好会影响推送内容的策略,但回到之前的迭代路径是不可能的。



1. 技术原理非常简单,将文字、图像、音频视频转化为数字,进行数据挖掘。自然语言处理有趣,通过将文字转化为数字,利用分类关联进行数据挖掘,发现文字之间的关联。数据挖掘的对象是文字和文字之间的关联。

1. NLP(自然语言处理)是一种处理语言的能力,不同语言文字的处理能力不同,英文相对容易,汉语没有空格,所以处理起来更困难。
2. 在自然语言处理的应用过程中,情感分析是一种常见的应用。情感分析是指对文本进行情感分析,理解文本中的情感倾向。情感分析可以应用于各种领域,如营销、广告、客户服务等。
3. 情感分析需要通过学习和训练来提高处理能力,可以使用各种算法和模型来实现。

 技术原理是将数字转换成算法来处理各个领域的问题。
技术原理是将数字转换成算法来处理各个领域的问题。
4. 在数据分析、自然语言处理和挖掘等领域中,需要了解相关专业知识。学好本专业基础上,了解相关技术可以为职业发展提供优势,不一定要跨学科学习IT专业,因为该专业供大于求。



要点八:提出的问题。
1. 讨论了未来数据分析专业在工商、劳经等相关专业中的角色和影响。
2. 提出了思考未来应该从事什么样的工作或学习什么样的技能来提升竞争优势。
3. 强调了写出判断和规划的重要性。




![[react]脚手架create-react-app/vite与reac项目](https://img-blog.csdnimg.cn/direct/7e6e5b22e9b64317b0ce9551b8162802.png)
![助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于YOLOv6开发构建生活场景下城市部件检测识别系统](https://img-blog.csdnimg.cn/direct/059f8286d0a0453685e9480e7405622a.png)