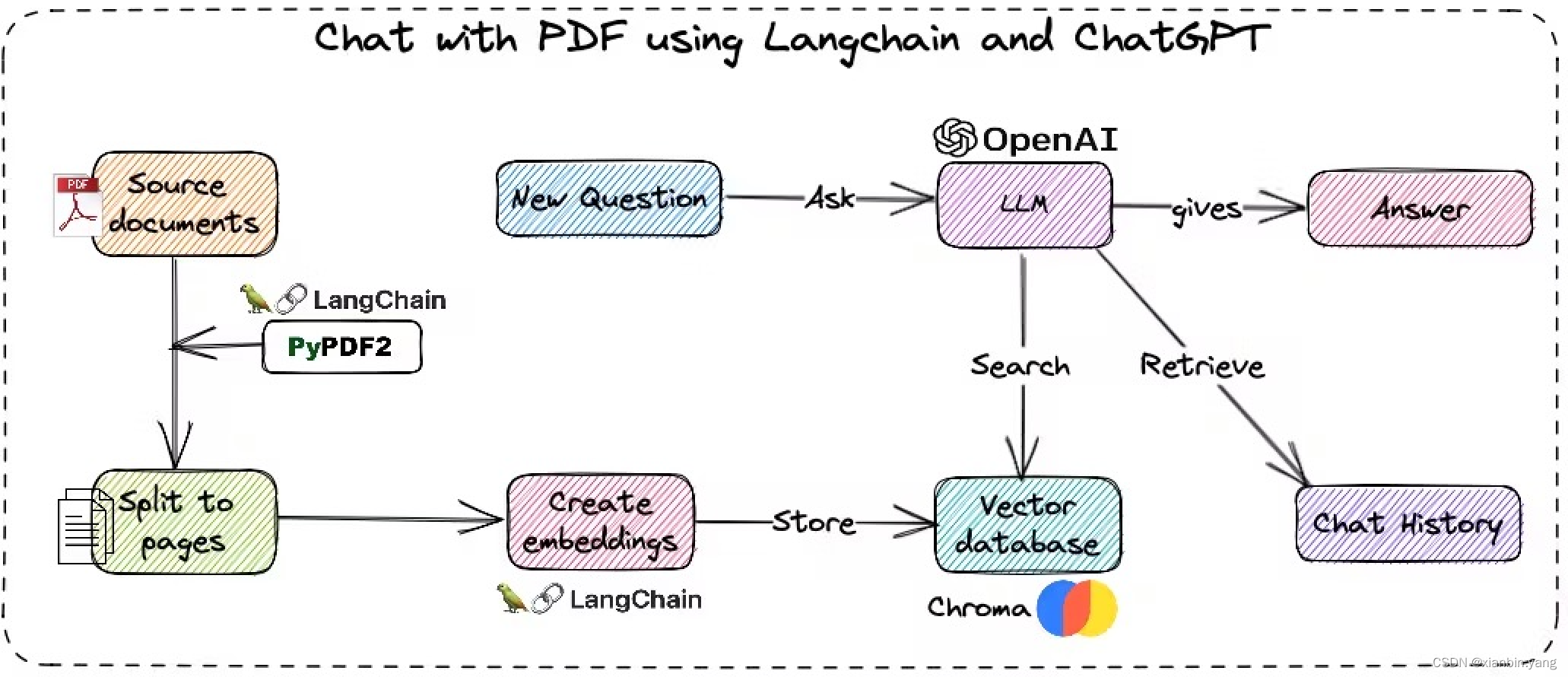
目录
什么是hdfs
原理
包含哪些部分
hdfs 的读取过程
hdfs 的写过程
NN 和 2NN 工作机制 (元数据持久化机制)
(一)第一阶段: NameNode 启动
(二)第二阶段: Secondary NameNode 工作
datanode的工作机制
小文件处理方案
yarn 的运行原理
任务提交阶段:
任务初始化阶段:
任务分配阶段:
什么是shuffle
mapshuffle的过程
mapshuffle优化办法
reduce shuffle
数据倾斜的原因
mapreduce 数据倾斜的解决方案
hive
存储结构
分区和分桶的区别
四个By
常用场景
hive 优化
1. 首先从 fetch 抓取的角度来看:
2. 本地模式
3. 表优化
hive 的数据倾斜
1) group by
2) count(distinct)
3) 不同数据类型关联产生数据倾斜
4) mapjoin
常用的开窗函数
over()窗口函数的语法结构
什么是hdfs
HDFS指的是Hadoop分布式文件系统(Hadoop Distributed File System),是Apache Hadoop框架中的一个分布式 文件系统。它被设计用来在集群中存储和处理大规模数据集。 HDFS可以提供高可靠性、高吞吐量和高扩展性。
原理
1. HDFS将大文件分成多个块(block),每个块默认大小为128MB或256MB,然后将这些块分散存储在集群中 的多个节点上。
2. 每个块都会有多个副本(replica),默认情况下是3个副本,这些副本会存储在不同的节点上,以保证数据的 可靠性和容错性。
3. HDFS采用了主从架构,其中一个NameNode负责管理文件系统的元数据信息,包括文件目录结构、文件块信 息、副本位置等;多个DataNode负责存储和管理实际的数据块。
4. 客户端访问HDFS时,会先向NameNode请求文件的元数据信息,然后根据元数据信息找到对应的数据块所在 的DataNode,最终从DataNode获取数据。
5. HDFS还提供了数据的校验和机制,可以检测数据在传输过程中是否发生错误,以保证数据的完整性。
包含哪些部分
1. NameNode:负责管理文件系统的元数据信息,包括文件目录结构、文件块信息、副本位置等。 NameNode 是HDFS的核心组件之一,是一个单点故障,因此需要进行备份和容错处理。
2. DataNode:负责存储和管理实际的数据块。 DataNode是HDFS的工作节点,每个节点上都会运行一个 DataNode进程,用于管理本地存储的数据块。
3. Secondary NameNode:负责协助NameNode进行元数据信息的备份和恢复工作。 Secondary NameNode并 不是NameNode的备份,它只是定期从NameNode获取元数据信息,并将其合并为一个镜像文件,以备份和 恢复使用。
4. HDFS客户端:包括命令行工具和API等,用于与HDFS交互,完成文件上传、下载、删除等操作。客户端通过 与NameNode交互获取文件的元数据信息,并根据元数据信息找到对应的数据块所在的DataNode,最终从 DataNode获取数据。
hdfs 的读取过程

答案一 : (来源csdn)
( 1) HDFS client创建DistributedFileSystem 对象,通过该对象向 NameNode 请求下载文件, NameNode 通过查询 元数据,找到文件块所在的 DataNode 地址。 ( 2)挑选一台 DataNode (要考虑结点距离最近选择原则、 DataNode负载均衡)服务器,请求读取数据。 ( 3) DataNode 开始传输数据给客户端(从磁盘里面读取数据输入 流,以 Packet 为单位来做校验),串行读取,即先读取第一个块,再读取第二个块拼接到上一个块后面。 (4)客 户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
答案二: (来源chatgpt)
1. 客户端向NameNode请求文件的元数据信息,包括文件的块信息、块所在的DataNode等。
2. NameNode返回文件的元数据信息给客户端。
3. 客户端根据元数据信息找到对应的数据块所在的DataNode,然后向DataNode发送读取数据块的请求。
4. DataNode接收到客户端的请求后,从本地磁盘读取对应的数据块,并将数据块传输给客户端。
5. 客户端接收到数据块后,将其缓存在本地内存中,然后继续请求下一个数据块,直到读取完整个文件。
需要注意的是, HDFS支持多个客户端同时读取同一个文件,每个客户端都可以从不同的DataNode节点读取数据 块,从而实现了高并发和高吞吐量的文件读取。此外, HDFS还提供了数据的校验和机制,可以检测数据在传输过程 中是否发生错误,以保证数据的完整性。
hdfs 的写过程
答案一 : (来自csdn)

( 1) HDFS client创建DistributedFileSystem 对象,通过该对象向 NameNode 请求上传文件, NameNode 检查权 限,并判断目标文件是否已存在。
( 2)如果权限许可,目标文件也存在, NameNode进行响应,返回是否可以上传 文件。
( 3)客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
(4) NameNode 返回 3 个 DataNode 节点(默认副本数为3),分别为 dn1、dn2、dn3。(这一步要考虑服务器是否可用、副本存储节点选择策略、 DataNode负载均衡)
( 5) 客户端创建FSDataOutputStream数据流对象,通过该对象请求dn1 (即DataNode1) 上传(或写)数据(即建立传输通道), dn1 收到请求会继续调用dn2建立通道,然后 dn2 调用 dn3,这样dn1~dn3 的通信通道建立完成。
( 6)传输通道建立完成后, dn1、dn2、dn3 逐级应答客户端。
( 7)客户端开始往 dn1 上 传第一个 Block (先从磁盘读取数据放到一个本地内存缓存),以Packet为单位(每次发送的是一个Packet对象), dn1 收到一个 Packet (直接从内存中)传给 dn2 ,dn2 传给 dn3。需要注意的是,这里传输的packet大小是64K,这 个64K的packet其实就是一个缓冲队列,里面包含多个(chunk和chunksum),一个chunk是512byte,其校验码 chunksum是4byte。dn1 每传一个 packet会放入一个应答队列(即ack队列,起备份作用)等待应答,当所有的 DataNode应答成功后,会将该packet从应答队列中移除。
( 8)当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 到服务器。(重复执行 3-7 步)。
( 9)所有的Block传输完毕并确认完成后, HDFS CLient关闭FSDataOutputStream数据流对象。然后, HDFS Client 联系NameNode,确认数据写完成, NameNode 在内存中对其元数据进行增删改(然后再通过 SecondaryNameNode对元数据进行修改)。注意,此时只是把更新操作记录到编辑日志Editlog,并没有真正合并编 辑日志和镜像文件,只有触发checkPoint才合并。
答案二: (来自chatgpt)
1. 客户端向NameNode请求创建文件,并指定文件的名称、大小、块大小等信息。
2. NameNode接收到客户端的请求后,根据文件大小和块大小等信息,计算出需要创建的数据块数量,然后返回 给客户端一个数据块列表,包括每个数据块的ID和副本位置等信息。
3. 客户端根据数据块列表,将文件分成多个数据块,并将每个数据块写入到对应的DataNode节点上。在写入数 据块之前,客户端会先向DataNode节点发送一个写入请求,并获取一个写入管道(pipeline)。
4. 客户端将数据块写入到写入管道中,然后DataNode节点将数据块存储到本地磁盘上,并将数据块传输给下一 个节点。这样,数据块就会依次传输到所有的副本位置上,从而实现了数据的备份和容错。
5. 当所有的数据块都写入完成后,客户端向NameNode发送一个完成请求,告知NameNode文件已经创建完 成。
NN 和 2NN 工作机制 (元数据持久化机制)
(一)第一阶段: NameNode 启动
( 1)第一次启动 NameNode 格式化后,创建 镜像文件fsimage 和 编辑日志 edits_inprogress_001 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
( 2)客户端对元数据进 行增删改的请求。
( 3) NameNode 记录更新操作到edits_inprogress_001 中
(4) NameNode 在内存中对元数据 进行增删改(然后再通过SecondaryNameNode对元数据进行修改)。
(二)第二阶段: Secondary NameNode 工作
( 1) Secondary NameNode 询问 NameNode 是否需要 CheckPoint (即是否需要服务),带回 NameNode是否可服务的条件。 CheckPoint触发条件:定时时间到; Edits中 的数据满了。
( 2) Secondary NameNode 请求执行 CheckPoint (即请求服务)。
( 3) NameNode 滚动正在写的 edits_inprogress_001 日志,将其命名为edits_001,并生产新的日志文件edits_inprogress_002,以后再有客户端操 作,日志将记录到edits_inprogress_002中。 (4)将编辑日志edits_001和镜像文件fsimage拷贝到 SecondaryNameNode。
( 5) Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
( 6)生成新的镜 像文件 fsimage.chkpoint。
( 7)拷贝 fsimage.chkpoint 到 NameNode。
( 8) NameNode 将 fsimage.chkpoint 重 新命名成 fsimage (此时的fsimage是最新的)。
保证高效、稳定、可靠的原因
1. 数据的分布式存储: HDFS将大文件分成多个数据块,并将这些数据块存储在多个DataNode节点上,从而实 现了数据的分布式存储。这样可以大大提高文件的读写效率和可靠性。
2. 数据的备份和容错: HDFS通过多副本机制,将每个数据块存储在多个DataNode节点上,从而实现了数据的 备份和容错。当某个节点发生故障时,系统可以自动切换到其他节点上读取数据,从而保证了数据的可靠性和 稳定性。
3. 数据的校验和机制: HDFS在数据传输过程中使用校验和机制,可以检测数据在传输过程中是否发生错误,从 而保证数据的完整性和正确性。
4. NameNode的高可用: HDFS通过Secondary NameNode等机制,实现了NameNode节点的备份和恢复,从而 提高了系统的可靠性和稳定性。
5. 大规模集群管理: HDFS支持大规模集群管理,可以自动调整节点的负载均衡、优化数据传输路径等,从而提 高系统的效率和稳定性。
6. HDFS利用了零拷贝技术来提高数据传输的效率。
datanode的工作机制

1. 存储数据块:当客户端向HDFS上传文件时, NameNode会将文件划分为多个数据块,并将这些数据块分配给 多个DataNode节点进行存储。每个DataNode节点会将自己存储的数据块信息发送给NameNode,以便 NameNode进行管理。一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本 身,一个是元数据的校验信息包括数据块的长度,块数据的校验和,以及时间戳。
2. 备份数据块:为了保证数据的可靠性, HDFS会将每个数据块存储在多个DataNode节点上,称为数据块的备 份。当一个DataNode节点发生故障时,系统可以自动切换到其他节点上读取数据。
3. 数据块的复制:为了保证数据块的备份, DataNode会定期将自己存储的数据块复制到其他节点上。这个过程 称为数据块的复制。
4. 数据块的删除:当文件被删除时,对应的数据块也会被删除。当一个DataNode节点上的数据块不再需要时, 该节点会将其删除,并将信息发送给NameNode。
5. 心跳检测:为了保证DataNode节点的可靠性和稳定性,每个DataNode节点会定期向NameNode发送心跳信 息,以表明自己的状态。如果NameNode在一段时间内没有收到某个DataNode节点的心跳信息,就会认为该 节点发生故障,并将其标记为不可用。 心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的 命令如复制块数据到另一台机器,或删除某个数据块。 如果超过 10 分钟 + 30s 没有收到某个 DataNode 的心 跳,则认为该节点不可用。
6. DataNode 启动后向 NameNode 注册, 之后周期性(默认 6 小时) *的向 NameNode 上报所有的块信息。同 时、DN 扫描自己节点*块信息列表的时间,检查DN中的块是否完好,如果某块磁盘损坏,就将该块磁盘上存 储的所有 BlockID报告给NameNode。
小文件处理方案
1. 合并小文件:将多个小文件合并成一个大文件,从而减少NameNode内存的占用和存储空间的浪费。可以使用 Hadoop提供的SequenceFile格式将多个小文件合并为一个大文件,或者使用Hadoop Archive ( HAR)将多个 小文件打包成一个归档文件。
2. 小文件归档:将多个小文件归档到一个大文件中,从而减少NameNode内存的占用和存储空间的浪费。可以使 用Apache Hadoop Archives ( HAR)将多个小文件打包成一个归档文件。
3. 数据分区:将数据按照一定规则分区,使得每个分区中包含的文件数目不超过一个阈值。这样可以将小文件分 散到多个分区中,从而减少NameNode内存的占用和存储空间的浪费。
4. 数据压缩:对于一些文本类型的小文件,可以采用压缩的方式来减少存储空间的占用。 Hadoop提供了多种压 缩算法,如gzip、bzip2等。
yarn 的运行原理
答案一
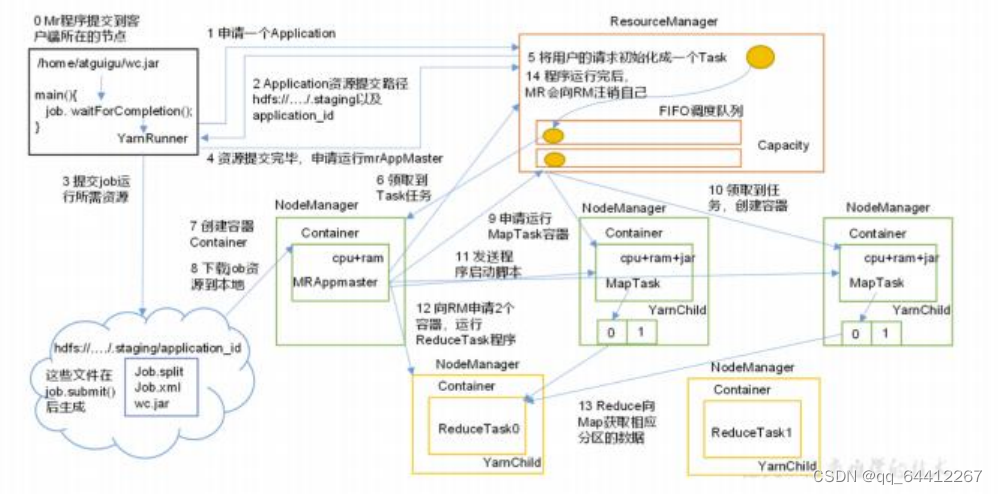
答案二
任务提交阶段:
1.client 【申请计算资源的应用】 向整个集群提交job,同时申请一个job_id;
2. ResourceManager【 RM】 向Client返回资源提交路径和job_id 【每个job都是一个唯一的id】 ;
3. client根据返回数据的值发送jar包、 Configuration、 InputSplit 【数据分片信息】,也就是上传计算所需的资源 到指 定位置
4. client 上传完成资源后,向ResourceManager 发送执行作业请求, RM接收到请求后,会创建一个Application Manager【AM】 来管理这个job
任务初始化阶段:
5、ApplicationManager 将 job添加到 Resource Scheduler 【 RS资源调度器】中; RS维护了一 个队列,所有需要执行 的job都会在这个队列中,并按一定的规则等待执行
6、当轮到你的job执行时, RS会通知AM 有空闲NodeManager【 NM】 分配给它来执行job 了 7、AM让分配的NM 开辟 Container 【容器】 , 并在Container中 启动job对应的 Application Master【AMs】
8、AMs获取步骤3中在hdfs上提交的文件,根据分片信息生成 Task
【Task种类可以是: map/reduce task】
任务分配阶段:
9、AMs向RM申请运行Task的任务资源
10、RM把需要运行的Task分配给空闲的NM ,NM分别领取 Task并创建用于执行task的Container
任务运行阶段
11、AMs通知所有接受到该Task的NM启动计算
12、NM启动计算
13、如果NM上的该Task执行结束后 还有新的Task,则向RM申请新的Container运行新的Task
14、所有Task执行完成即Job完成后, AMs会向RM申请注销 自己
任务完成阶段
15、框架更新计算的进度与状态。
答案三(工作机制)
1客户端运行mr 会创建一个yarnrunner
2去ResourceManager申请运行一个application
3会返回一个hdfs的路径
4客户端将数据进行切片发送的hfds (job.split,jop.xml ,wc.jar)
5.提交完毕申请运行mrappmaster
6.ResourceManager将用户的请求初始化成一个task
7.将请求发给送到队列中
8.然后我们这请求就会被执行
9执行了就会启动一个mrappmaster
10申请运行maptask容器(数量根据切片分)
11申请到了container容器
12mrappmaster就可以container中运行maptask了
13maptaskc从hdfs获取数据进行计算运算完了之后会把数据按照分区进行存储(写到本地)
14mrappmaster会再次去ResourceManager申请运行redcetask
15申请到足够数量的container
16mrappmaster在container运行reducetask
17会根据数据的分区获取到自己的数据
18reducetask运行完之后会把数据再次存放到hdfs中
19都运行完成之后mrappmaster会申请注销自己
什么是shuffle
Shuffle是指在MapReduce过程中,将Map阶段的输出结果按照Key值进行归并排序,并将排序后的结果分发到 Reduce节点上进行进一步处理的过程。主要作用是:
1. 排序:将Map任务输出的数据按照Key值进行排序,以便在Reduce任务中进行合并和计算。
2. 分区:将排序后的数据按照Reduce任务的数量进行分区,以便将数据均匀地分配到各个Reduce任务中。
3. 压缩:对Shuffle产生的大量数据进行压缩,以减少网络传输的数据量,提高传输效率。
4. 缓存:将Shuffle产生的数据缓存在内存中,以便在Reduce任务中进行快速的读取和处理。
mapshuffle的过程

概念: shuffle过程是对Map的结果进行分区、排序、分割,然后将属于同一划分(分区)的输出合并在一起并写在磁 盘上,最终得到一个分区有序的文件
1.map()的数据会写入到内存(环形缓冲区:默认大小: 100mb),当数据达到缓冲区总容量的80% (阈值)时,会 将我们的数据spill到本地磁盘
1)分区(partitioner):分区决定map输出的数据将会被哪个reduce任务进行处理 2)排序:会对我们分区中的数据 进行排序 3) spill写磁盘:将内存中的数据写入到本地磁盘(hadoop.tmp.dir) 2.当Map阶段数据处理完成之后,我 们会将spill到磁盘的数据进行一次合并
1)将各个分区的数据合并在一起 2)分区合并之后再次排序
mapshuffle优化办法

reduce shuffle


1. 复制copy
1. MapTask所在的NodeManager以获取输出文件
2. reduce任务有少量复制线程,因此能够并行取得map输出。默认线程数为5
2. 归并merge
Copy 过来的数据会先放入内存缓冲区中
如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。
在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内 存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。
3. reduce
一个reduce任务完成全部的复制和排序后输出。
数据倾斜的原因
1)、key分布不均匀
某些key的数量过于集中,存在大量相同值的数据
存在大量异常值或空值。
2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
mapreduce 数据倾斜的解决方案
1. 预处理数据:在进行MapReduce计算之前,可以对数据进行预处理,将数据进行分区、抽样等操作, 以避免数据倾斜。
2. 动态调整分区:可以根据实时计算的情况,动态调整数据的分区,以达到负载均衡的效果。
3. Combiner函数:在MapReduce的过程中,可以使用Combiner函数对中间结果进行合并,以减少数据 传输和处理的负担。
4. 增加Reduce数量:如果Reduce节点的负载过高,可以增加Reduce节点的数量,以达到负载均衡的效 果。
5. 数据重分布:可以将数据进行重分布,将负载过高的数据块重新分配到其他节点上,以达到负载均衡的 效果。
hive
存储结构
hive 的数据存储其实是在HDFS文件系统中的。 hive 提供了一种查询HDFS 中文件的一种方式。面向列的格式的存 储。 hive 的存储结构支持
1. 文本文件格式(Text File Format):文本文件格式是最常用的文件格式之一,它以文本形式存储数据,每行 数据以分隔符分隔。
2. 序列文件格式(Sequence File Format):序列文件格式是Hadoop中的一种二进制文件格式,它可以高效地 存储大量小文件,也可以用于MapReduce中的中间结果输出。
3. RCFile格式(Record Columnar File Format): RCFile是一种列式存储格式,它将每列数据存储在一起,可 以提高查询效率。
4. ORC文件格式(Optimized Row Columnar): ORC文件格式是一种 高效的列式存储格式,它可以压缩数 据、支持谓词下推等特性,能够在查询效率和存储空间之间取得平衡。
5. Parquet文件格式: Parquet是一种跨平台的列式存储格式,它支持多种编程语言和数据处理框架, 能够高效地 存储和查询大规模的结构化数据。
1. 数据库(Database): Hive的数据存储是基于数据库的,每个数据库可以包含多个表。
2. 表(Table):表是Hive中的最基本的数据存储单元,它由一组有序的列和行组成。每个表都有一个表名和一 组列定义,列定义包括列名、数据类型、注释等信息。
3. 分区(Partition):为了提高查询效率, Hive支持对表进行分区存储。分区是指将表按照某个列的值进行划 分,每个分区对应一个子目录,该子目录下存储了该分区对应的数据文件。
4. 桶(Bucket):桶是将表按照哈希函数的结果进行划分,每个桶对应一个数据文件。桶可以进一步提高查询效 率,特别是在对大表进行聚合操作时。
5. 外部表(External Table):外部表是指表的数据并不存储在Hive的数据仓库中,而是存储在其他位置,比如 HDFS上或者本地文件系统上。外部表可以让Hive直接访问已经存在的数据,而无需将数据导入到Hive的数据 仓库中。
分区和分桶的区别
1. 分区每个区对应的是目录,分桶每个桶对应的是文件
2. 分区的依据是某个字段,字段值相同则放在相同区中;分桶的依据hash函数
3. 分区的优点是为了提高查询效率;分桶可以进一步提高效率,主要是在聚合的时候。
4. 分区每个区大小不一定相同;分桶每个桶基本相同。
四个By
1. order by 统一排序。
2. sort by
分区内排序
3. distribute by
与sort by配合使用 在分区内排序
4. cluster by
如果sort by 和 distribute by 字段相同,则cluster by 用替换,这样只能升序排序。
常用场景
1. 行转列
SELECT id, name, subject FROM students LATERAL VIEW explode(split(subjects, ',')) subjectsTable AS subject;
2. 列转行
3. 根据json属性查询
4. 爆炸函数
hive 优化
结合项目
结合原理
做项目的时候过优化,比如XXX项目,功能测试的时候是没有问题的,但是压力测试的时候就发现有慢的情况。
结合hive 的原理,从一下这几个方面进行处理。
1. 首先从 fetch 抓取的角度来看:
Hive的 fetch 抓取主要是能使某些简单计算任务不再使用MapReduce,例如select * from 等操作,直接查询本 地文件将其输出到控制台。
原则是:在某些情况下尽量不跑mr,比如查询几个字段,全局查找,字段查, limit查等情况
none模式
所有涉及hdfs的读取查询都走mapreduce任务。这种模式适合于大数据量的查询,因为它可以利用 mapreduce的并行处理能力来加速查询。
但是,如果数据量较小,使用这种模式可能会导致性能下降,因为mapreduce的启动和调度开销较 大。(数据量大的时候用)
minimal模式:。(数据量小的时候用,简单查询)
在进行简单的select*,简单的过滤或涉及分区字段的过滤时走mr。
这种模式适合于数据量较小的查询,因为它可以避免mapreduce的启动和调度开销,从而提高查询性 能。
more模式:
在minimal模式的基础上,增加了针对查询语句字段进行一些别名的计算操作。这种模式适合于需要进 行一些计算操作的查询,例如计算字段别名、聚合函数等。但是,由于增加了计算操作,所以性能可能 会有所下降。
2. 本地模式
本地模式即是指一些小的计算任务直接在单台机器上执行,不再分布式执行,主要应用场景是为了针对于,一 些小的任务,可能触发计算网络通信所用的时间比任务计算本身的计算时间还要长,所以小任务直接放在本地 执行
3. 表优化
大表join小表,将数据量小的表放在左边(小表驱动大表) 大表join大表: 空key过滤:将含有空值的字段过滤出 来 空key转换:将为null的key加上随机数打撒到所有分区,避免数据倾斜(但是在我之前的项目当中没有根据 这样的处理,我们的汇总的字段都是要求有数据的,没有空的情况)
4. 分区 分区是按照指定字段逻辑上的将数据划分为一个一个的文件夹
以前做项目的时候,比如订单会根据日期汇总、星期汇总、月度汇总,中间的结果都是按照这些字段进行分区 存放的
分区是为了减少全表扫描,需要的数据只需扫描对应分区即可
分区字段指定的是伪字段,使用时需要定义类型,分区内数据量不一致,例如5- 1有100万条数据, 5-2有500 万数据
5. 分桶 分桶是按照指定字段逻辑上的将数据划分为一个一个的文件 分区字段指定的是真实字段和分桶的个数, 分桶内数据量基本一致,例如按照Name分三个桶,即是按照Name取Hash模以分桶的数量 所以分桶也用于数 据倾斜的情况
订单数据按照商品名称统计的时候,就是按照名称进行分桶处理的
6. 合理设置Map和reduce的数量 合理设置Map和reduce的数量可以有效提高执行速度 . Hive中map和reduce的默认数量是根据输入数据的大小和集群配置来自动计算的。
默认情况下, Hive会将map的数量设置为输入数据的块数,而reduce的数量设置为1。如果输入数据很大, Hive会自动增加map和reduce的数量以提高查询效率。
我们也可以通过设置相关参数来调整map和reduce的数量,例如设置mapred.reduce.tasks参数来指定reduce 的数量。
我们公司的设置的策略是:
map数量 = max(输入数据块数, min(集群节点数, 输入数据块数 * mapreduce.job.maps.max)) // 根据输入块 数、集群节点数字、集中当中可以支持的最大map数量计算,我们有一个公式,那个稍微有点长。
reduce数量 = max(1, min(集群节点数, 输入数据块数 * mapreduce.job.reduces.max))// reduce的数量也一样 用公式计算
经过实践,这种效果还是可以接受的。
另外,复杂任务增加Map数,增加MapTask的数量来提高并行度,提高速度
7. 笛卡尔积 尽量避免容易产生笛卡尔积的操作,尽可能的少关联。
8. 压缩 使用snppy ,lzo ,bzip2 ,gzip等对数据进行压缩,减小数据的体积,提高速度。我们之前都是使用lzo进 行压缩的。
9. 合并小文件 对小文件使用ComlineHiveInputFormat对文件进行合并,将多个小文件合并成一个大文件,减少 map的数量,减少资源消耗
10. JVM重用 反复使用已经创建好的jvm实例,不需要每次执行任务都创建关闭,省去了创建关闭的时间,提高速 度
hive 的数据倾斜
数据倾斜需要考虑几种情况来处理
1) group by
如果是在group by中产生了数据倾斜,是否可以讲group by的维度变得更细,如果没法变得更细,就可以在原分组 key上添加随机数后分组聚合一次,然后对结果去掉随机数后再分组聚合 在join时,有大量为null的join key,则可以 将null转成随机值,避免聚集。 这样增加了处理的阶段,但是避免了一个任务处理大量数据的情况
2) count(distinct)
情形:某特殊值过多(倾斜到特殊值上) 后果:处理此特殊值的 reduce 耗时;只有一个 reduce 任务 解决方式: count distinct 时,将特殊值的情况单独处理,比如可以直接过滤该特殊值的行, 在最后结果中加 1。如果还有其他 计算,需要进行 group by,可以先将值为空的记录单独处理,再和其他计算结果进行 union。
3) 不同数据类型关联产生数据倾斜
情形:比如用户表中 user_id 字段为 int ,log 表中 user_id 字段既有 string 类型也有 int 类型。当按照 user_id 进行两 个表的 Join 操作时。 后果:处理此特殊值的 reduce 耗时;只有一个 reduce 任务
默认的 Hash 操作会按 int 型的 id 来进行分配,这样会导致所有 string 类型 id 的记录都分配 到一个 Reducer 中。 解
决方式:把数字类型转换成字符串类型 select * from users a left outer join logs b on a.usr_id = cast(b.user_id as string)
4) mapjoin
业务数据本身的特性(存在热点key): join的每路输入都比较大,且长尾是热点值导致的,可以对热点值和非热点值分 别进行处理,再合并数据 key本身分布不均: 可以在key上加随机数,或者增加reduceTask数量 同Map join的处理
配置文件开启数据倾斜时负载均衡 set hive.groupby.skewindata=true;
思想:就是先随机分发并处理,再按照 key group by 来分发处理。
控制空值分布:
将为空的 key 转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分不到多个 Reducer。 注:对 于异常值如果不需要的话,最好是提前在 where 条件里过滤掉,这样可以使计算量大大减少
小文件: 设置map输入的小文件合并: set mapred.max.split.size=256000000; //一个节点上split的至少的大小
(这个值决定了多个DataNode上的文件是否需要合并) set mapred.min.split.size.per.node=100000000; //一个 交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)set
mapred.min.split.size.per.rack=100000000; //执行Map前进行小文件合并 set hive.input.format=![img] (file:///C:\Users\45466\AppData\Roaming\Tencent\QQTempSys\%W@GJ$ACOF(TYDYECOKVDYB.png)org .apache.hadoop.hive.ql.io.CombineHiveInputFormat; 设置map输出和reduce输出进行合并的相关参数: //设置 map端输出进行合并,默认为true set hive.merge.mapfiles = true //设置reduce端输出进行合并,默认为false set hive.merge.mapredfiles = true //设置合并文件的大小 set hive.merge.size.per.task = 25610001000 //当输 出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。 set
hive.merge.smallfiles.avgsize=16000000
常用的开窗函数
over()窗口函数的语法结构
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
分组topN,地区内排名。日期内地区排名。 商品分类的排名 、 商家的排名。
函数() over(partition by 列名1 order by 列名2 rows between [[unbounded|num] preceding | current row] and [[unbounded|num] following | current row])
over() 前为一个函数,如果是聚合函数,那么 order by 不能一起使用
rows between:作用为划分表中窗口边界
unbounded preceding:表示表中窗口无上边界
num preceding:表示表中窗口上界到距离当前行向上num行
current row:表示当前行
num following:表示表中窗口下界到距离当前行向下num行
unbounded following:表示表中窗口无下边界
rows between unbounded preceding and unbounded following:
表示本窗口在表中无上边界也无下边界,此时可省略
有无order by 的区别?
有order by 的情况: 逐行累加
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as pv1
from user_pv;

无 order by ,分区内每行的累加结果都是一样的。
select cookieid,createtime,pv, sum(pv) over(partition by cookieid ) as pv1 from user_pv;

窗口函数sql
lag(col,n,val):查询当前行前边第n行数据,如果没有默认为val
lead(col,n,val):查询当前行后边第n行数据,如果没有默认为val
first_value(col,true/false):查询当前窗口第一条数据,第二个参数为true,跳过空值 last_value(col,true/false):查询当前窗口最后一条数据,第二个参数为true,跳过空值
2、排名开窗函数(RANK、 DENSE_RANK、ROW_NUMBER、NTILE)
排名开窗函数可以单独使用 Order by 语句,也可以和 Partition By 同时使用
Partition By 用于将结果集进行分组,开窗函数应用于每一组
Order By 指定排名开窗函数的顺序,在排名开窗函数中必须使用 Order By 语句
NTILE (n): 将所有的数据分配到n个桶当中,返回当前行所在桶的编号。

RANK、DENSE_RANK、ROW_NUMBER 的区别
rank()排序相同时会重复,总数不变,即会出现1、 1、3这样的排序结果;
dense_rank()排序相同时会重复,总数会减少,即会出现1、 1、2这样的排序结果;
row_number()排序相同时不会重复,会根据顺序排序。
3、聚合开窗函数(SUM、AVG、MAX、MIN、COUNT)
聚合开窗函数只能使用 Partition By 子句, Order By 不能与聚合开窗函数一同使用
三种模型
星型模式
业务表只需要一次关联就可以找到对应维度数据
2.雪花模式
维度表还需要再次找维度数据
雪花模式的维度表可以拥有其他的维度表
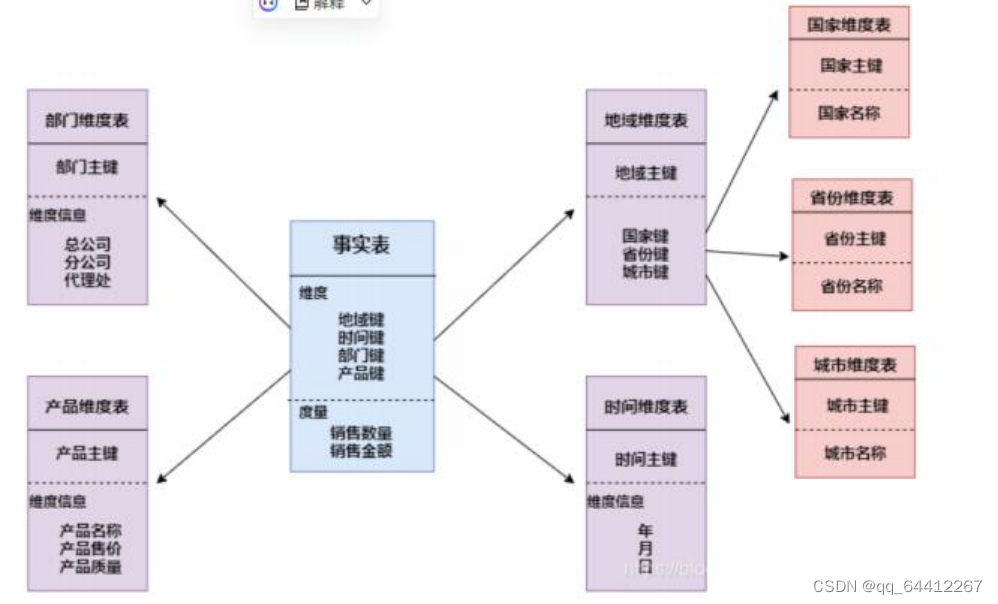
订单-> spu(商品的名称) - > 商品分类。
订单->用户->用户标签
3. 星座模式
基于多张事实表,而且共享维度信息,即事实表之间可以共享某些维度表
永远有限考虑星型模型.