第5章 深度学习用于计算机视觉
本章包括以下内容:
理解卷积神经网络(convnet)
使用数据增强来降低过拟合
使用预训练的卷积神经网络进行特征提取
微调预训练的卷积神经网络
将卷积神经网络学到的内容及其如何做出分类决策可视化
本章将介绍卷积神经网络,也叫 convnet,它是计算机视觉应用几乎都在使用的一种深度 学习模型。你将学到将卷积神经网络应用于图像分类问题,特别是那些训练数据集较小的问题。 如果你工作的地方并非大型科技公司,这也将是你最常见的使用场景。
5.1 卷积神经网络简介
我们将深入讲解卷积神经网络的原理,以及它在计算机视觉任务上为什么如此成功。但在此之前,我们先来看一个简单的卷积神经网络示例,即使用卷积神经网络对 MNIST 数字进行分 类,这个任务我们在第 2 章用密集连接网络做过(当时的测试精度为 97.8%)。虽然本例中的卷 积神经网络很简单,但其精度肯定会超过第 2 章的密集连接网络。
下列代码将会展示一个简单的卷积神经网络。它是 Conv2D 层和 MaxPooling2D 层的堆叠。 很快你就会知道这些层的作用。
from keras import layers
from keras import modelsmodel = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))print(model.summary())Model: "sequential"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================conv2d (Conv2D) (None, 26, 26, 32) 320 max_pooling2d (MaxPooling2 (None, 13, 13, 32) 0 D) conv2d_1 (Conv2D) (None, 11, 11, 64) 18496 max_pooling2d_1 (MaxPoolin (None, 5, 5, 64) 0 g2D) conv2d_2 (Conv2D) (None, 3, 3, 64) 36928 =================================================================
Total params: 55744 (217.75 KB)
Trainable params: 55744 (217.75 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
None重要的是,卷积神经网络接收形状为 (image_height, image_width, image_channels) 的输入张量(不包括批量维度)。本例中设置卷积神经网络处理大小为 (28, 28, 1) 的输入张量, 这正是 MNIST 图像的格式。我们向第一层传入参数 input_shape=(28, 28, 1) 来完成此设置。 我们来看一下目前卷积神经网络的架构。
可以看到,每个 Conv2D 层和 MaxPooling2D 层的输出都是一个形状为 (height, width, channels) 的 3D 张量。宽度和高度两个维度的尺寸通常会随着网络加深而变小。通道数量由传 入 Conv2D 层的第一个参数所控制(32 或 64)。
下一步是将最后的输出张量[大小为 (3, 3, 64)]输入到一个密集连接分类器网络中, 即 Dense 层的堆叠,你已经很熟悉了。这些分类器可以处理 1D 向量,而当前的输出是 3D 张量。 首先,我们需要将 3D 输出展平为 1D,然后在上面添加几个 Dense 层。
5.2 在小型数据集上从头开始训练一个卷积神经网络
我们将 2000 张图像用于训练,1000 张用于验证,1000 张用于测试。
会得到 71% 的分类精度。此时主要的问题在于过拟合。
然后,我们会介绍数据增强(data augmentation),它在计算机视觉领域是一种非常强大的降低过拟合的技术。使用 数据增强之后,网络精度将提高到 82%。
5.3 节会介绍将深度学习应用于小型数据集的另外两个重要技巧:用预训练的网络做特征提 取(得到的精度范围在 90%~96%),对预训练的网络进行微调(最终精度为 97%)。总而言之, 这三种策略——从头开始训练一个小型模型、使用预训练的网络做特征提取、对预训练的网络进行微调——构成了你的工具箱,未来可用于解决小型数据集的图像分类问题。
5.2.1 深度学习与小数据问题的相关性
深度学习的一个基本特性就是能够独立地在训练数据中找到有趣的特征,无须人为的特征工程,而这只在拥有大量训练样本时才能实现。
深度学习模型本质上具有高度的可复用性
5.2.2 下载数据
本节用到的猫狗分类数据集不包含在 Keras 中。它由 Kaggle 在 2013 年末公开并作为一项 计算视觉竞赛的一部分,当时卷积神经网络还不是主流算法。你可以从 https://www.kaggle.com/c/dogs-vs-cats/data 下载原始数据集(如果没有 Kaggle 账号的话,你需要注册一个,别担心,很 简单)。
不出所料,2013 年的猫狗分类 Kaggle 竞赛的优胜者使用的是卷积神经网络。最佳结果达到 了 95% 的精度。
这个数据集包含 25 000 张猫狗图像(每个类别都有 12 500 张),大小为 543MB(压缩后)。 下载数据并解压之后,你需要创建一个新数据集,其中包含三个子集:每个类别各 1000 个样本的训练集、每个类别各 500 个样本的验证集和每个类别各 500 个样本的测试集。
代码清单 5-4 将图像复制到训练、验证和测试的目录
import os, shutil, pathlib# 原始数据集的解压目录
original_dataset_dir = 'D:\\dataset\\dogs-vs-cats\\train\\train'# 保存小数据集的目录,创建一个名为cats_and_dogs_small的文件夹
base_dir = 'D:\dataset\cats_and_dogs_small'
os.mkdir(base_dir)
#
# 以下对应划分后的训练、验证和测试的目录
# 在名为cats_and_dogs_small的文件夹下创建三个文件夹分别为train、validation、test
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
#
# 在train文件夹下创建猫的训练图像文件夹cats
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)# 在train文件夹下创建狗的训练图像目录狗的训练图像文件夹dogs
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)# # 猫的验证图像目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)# 狗的验证图像目录
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)# 猫的测试图像目录
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)# 狗的测试图像目录
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)# 将前 1000 张猫的图像复制到 train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
#
for fname in fnames:src = os.path.join(original_dataset_dir, fname)dst = os.path.join(train_cats_dir, fname)shutil.copyfile(src, dst)# 将接下来 500 张猫的图像复制到 validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:src = os.path.join(original_dataset_dir, fname)dst = os.path.join(validation_cats_dir, fname)shutil.copyfile(src, dst)# 将接下来的 500 张猫的图像复制到 test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:src = os.path.join(original_dataset_dir, fname)dst = os.path.join(test_cats_dir, fname)shutil.copyfile(src, dst)# 将前 1000 张狗的图像复制到 train_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:src = os.path.join(original_dataset_dir, fname)dst = os.path.join(train_dogs_dir, fname)shutil.copyfile(src, dst)# 将接下来 500 张狗的图像复# 制到 validation_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:src = os.path.join(original_dataset_dir, fname)dst = os.path.join(validation_dogs_dir, fname)shutil.copyfile(src, dst)# 将接下来 500 张狗的图像复制到 test_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:src = os.path.join(original_dataset_dir, fname)dst = os.path.join(test_dogs_dir, fname)shutil.copyfile(src, dst)5.2.3 构建网络
我们将复用相同的总体结构,即卷积神经网络由 Conv2D 层(使用 relu 激活)和 MaxPooling2D 层交替堆叠构成。
但由于这里要处理的是更大的图像和更复杂的问题,你需要相应地增大网络,即再增加一 个 Conv2D+MaxPooling2D 的组合。这既可以增大网络容量,也可以进一步减小特征图的尺寸, 使其在连接 Flatten 层时尺寸不会太大。本例中初始输入的尺寸为 150×150(有些随意的选择),所以最后在 Flatten 层之前的特征图大小为 7×7。
注意 网络中特征图的深度在逐渐增大(从 32 增大到 128),而特征图的尺寸在逐渐减小(从 150×150 减小到 7×7)。这几乎是所有卷积神经网络的模式。
你面对的是一个二分类问题,所以网络最后一层是使用 sigmoid 激活的单一单元(大小为 1 的 Dense 层)。这个单元将对某个类别的概率进行编码。
from keras import layers
from keras import modelsmodel = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))print(model.summary())配置模型用于训练
# 代码清单 5-6 配置模型用于训练
from keras import optimizersmodel.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(lr=1e-4),metrics=['acc'])5.2.4 数据预处理
你现在已经知道,将数据输入神经网络之前,应该将数据格式化为经过预处理的浮点数张量。
现在,数据以 JPEG 文件的形式保存在硬盘中,所以数据预处理步骤大致如下。
(1) 读取图像文件。
(2) 将 JPEG 文件解码为 RGB 像素网格。
(3) 将这些像素网格转换为浮点数张量。
(4) 将像素值(0~255 范围内)缩放到 [0, 1] 区间(正如你所知,神经网络喜欢处理较小的输
入值)。
这些步骤可能看起来有点吓人,但幸运的是,Keras 拥有自动完成这些步骤的工具。Keras 有一个图像处理辅助工具的模块,位于 keras.preprocessing.image。特别地,它包含 ImageDataGenerator 类,可以快速创建 Python 生成器,能够将硬盘上的图像文件自动转换 为预处理好的张量批量。
# 代码清单 5-7 使用 ImageDataGenerator 从目录中读取图像
from keras.preprocessing.image import ImageDataGenerator# 将所有图像乘以 1/255 缩放
train_datagen = ImageDataGenerator(rescale=1. / 255)
test_datagen = ImageDataGenerator(rescale=1. / 255)train_generator = train_datagen.flow_from_directory(train_dir, # 目标目录target_size=(150, 150), # 将所有图像的大小调整为 150×150batch_size=20,class_mode='binary') # 因为使用了 binary_crossentropy损失,所以需要用二进制标签validation_generator = test_datagen.flow_from_directory(validation_dir,target_size=(150, 150),batch_size=20,class_mode='binary')# 代码清单 5-8 利用批量生成器拟合模型
history = model.fit_generator(train_generator,steps_per_epoch=100,epochs=30,validation_data=validation_generator,validation_steps=50)# 代码清单 5-9 保存模型
model.save('cats_and_dogs_small_1.h5')# 代码清单 5-10 绘制训练过程中的损失曲线和精度曲线
import matplotlib.pyplot as pltacc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
因为训练样本相对较少(2000 个),所以过拟合是你最关心的问题。前面已经介绍过几种 降低过拟合的技巧,比如 dropout 和权重衰减(L2 正则化)。现在我们将使用一种针对于计算 机视觉领域的新方法,在用深度学习模型处理图像时几乎都会用到这种方法,它就是数据增强 (data augmentation)。
5.2.5 使用数据增强 | data augmentation
过拟合的原因是学习样本太少,导致无法训练出能够泛化到新数据的模型。如果拥有无限的数据,那么模型能够观察到数据分布的所有内容,这样就永远不会过拟合。数据增强是从现 有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加 (augment)样本。其目标是,模型在训练时不会两次查看完全相同的图像。这让模型能够观察 到数据的更多内容,从而具有更好的泛化能力。
# 代码清单 5-11 利用 ImageDataGenerator 来设置数据增强
datagen = ImageDataGenerator(rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')在 Keras 中,这可以通过对 ImageDataGenerator 实例读取的图像执行多次随机变换来实现。
rotation_range 是角度值(在 0~180 范围内),表示图像随机旋转的角度范围。
width_shift 和 height_shift 是图像在水平或垂直方向上平移的范围(相对于总宽 度或总高度的比例)。
shear_range 是随机错切变换的角度。
zoom_range 是图像随机缩放的范围。
horizontal_flip 是随机将一半图像水平翻转。如果没有水平不对称的假设(比如真 实世界的图像),这种做法是有意义的。
fill_mode是用于填充新创建像素的方法,这些新像素可能来自于旋转或宽度/高度平移。
我们来看一下增强后的图像(见图 5-11)。

# 代码清单 5-12 显示几个随机增强后的训练图像import matplotlib.pyplot as pltfnames = [os.path.join(train_cats_dir, fname) forfname in os.listdir(train_cats_dir)]# 选择一张图像进行增强
img_path = fnames[3]# 读取图像并调整大小
img = image.load_img(img_path, target_size=(150, 150))# 将其转换为形状 (150, 150, 3) 的 Numpy 数组
x = image.img_to_array(img)# 将其形状改变为 (1, 150, 150, 3)
x = x.reshape((1,) + x.shape)# 生成随机变换后的图像批量。
# 循环是无限的,因此你需要在某个时刻终止循环
i = 0
for batch in datagen.flow(x, batch_size=1):plt.figure(i)imgplot = plt.imshow(image.array_to_img(batch[0]))i += 1if i % 4 == 0:break
plt.show()如果你使用这种数据增强来训练一个新网络,那么网络将不会两次看到同样的输入。但网 络看到的输入仍然是高度相关的,因为这些输入都来自于少量的原始图像。你无法生成新信息, 而只能混合现有信息。因此,这种方法可能不足以完全消除过拟合。为了进一步降低过拟合, 你还需要向模型中添加一个 Dropout 层,添加到密集连接分类器之前。
# 代码清单 5-13 定义一个包含 dropout 的新卷积神经网络
from keras import layers
from keras import modelsmodel = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(lr=1e-4),metrics=['acc'])5.3 使用预训练的卷积神经网络
想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络。 预训练网络(pretrained network)是一个保存好的网络,之前已在大型数据集(通常是大规模图 像分类任务)上训练好。如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征 的空间层次结构可以有效地作为视觉世界的通用模型,因此这些特征可用于各种不同的计算机 视觉问题,即使这些新问题涉及的类别和原始任务完全不同。
举个例子,你在 ImageNet 上训 了一个网络(其类别主要是动物和日常用品),然后将这个训练好的网络应用于某个不相干的任 务,比如在图像中识别家具。这种学到的特征在不同问题之间的可移植性,是深度学习与许多早期浅层学习方法相比的重要优势,它使得深度学习对小数据问题非常有效。
本例中,假设有一个在 ImageNet 数据集(140 万张标记图像,1000 个不同的类别)上训练 好的大型卷积神经网络。ImageNet 中包含许多动物类别,其中包括不同种类的猫和狗,因此可 以认为它在猫狗分类问题上也能有良好的表现。
我们将使用 VGG16 架构,它由 Karen Simonyan 和 Andrew Zisserman 在 2014 年开发(参见 Karen Simonyan 和 Andrew Zisserman 于 2014 年发表的文章“Very deep convolutional networks for large-scale image recognition”。) 。
对于 ImageNet,它是一种简单而又广泛使用的卷积神经网络架构。虽然 VGG16 是一个比较旧的模 型,性能远比不了当前最先进的模型,而且还比许多新模型更为复杂,但我之所以选择它,是因为它的架构与你已经熟悉的架构很相似,因此无须引入新概念就可以很好地理解。这可能是你第一次遇到这种奇怪的模型名称——VGG、ResNet、Inception、Inception-ResNet、Xception 等。你会习惯这些名称的,因为如果你一直用深度学习做计算机视觉的话,它们会频繁出现。
使用预训练网络有两种方法:特征提取(feature extraction)和微调模型(fine-tuning)。两种方法我们都会介绍。首先来看特征提取。
5.3.1 特征提取
特征提取是使用之前网络学到的表示来从新样本中提取出有趣的特征。然后将这些特征输入一个新的分类器,从头开始训练。
如前所述,用于图像分类的卷积神经网络包含两部分:首先是一系列池化层和卷积层,最后是一个密集连接分类器。第一部分叫作模型的卷积基(convolutional base)。对于卷积神经网络而言,特征提取就是取出之前训练好的网络的卷积基,在上面运行新数据,然后在输出上面训练一个新的分类器(见图 5-14)。
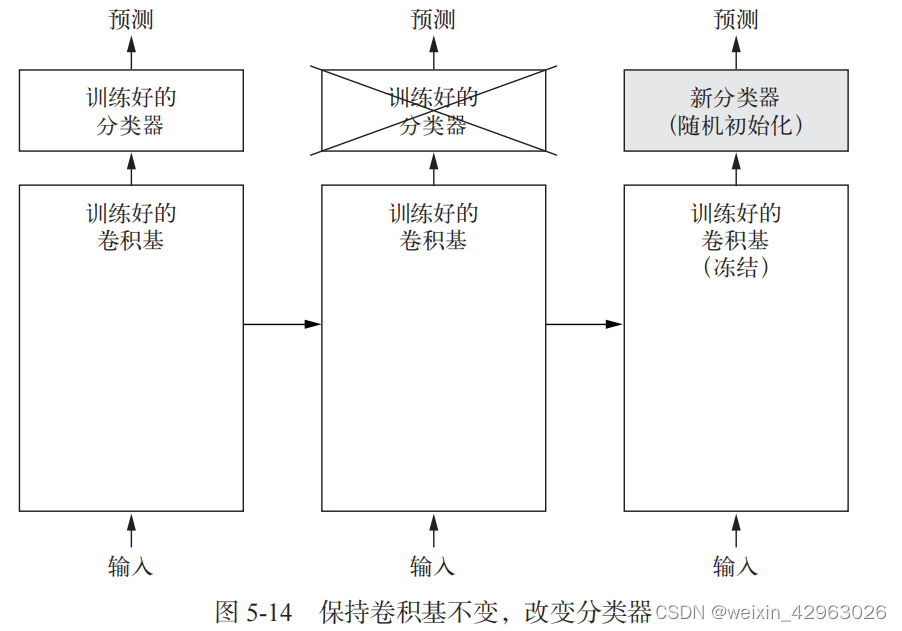
为什么仅重复使用卷积基?我们能否也重复使用密集连接分类器?一般来说,应该避免这 么做。原因在于卷积基学到的表示可能更加通用,因此更适合重复使用。卷积神经网络的特征图表示通用概念在图像中是否存在,无论面对什么样的计算机视觉问题,这种特征图都可能很有用。
但是,分类器学到的表示必然是针对于模型训练的类别,其中仅包含某个类别出现在整 张图像中的概率信息。此外,密集连接层的表示不再包含物体在输入图像中的位置信息。密集连接层舍弃了空间的概念,而物体位置信息仍然由卷积特征图所描述。如果物体位置对于问题很重要,那么密集连接层的特征在很大程度上是无用的。
注意,某个卷积层提取的表示的通用性(以及可复用性)取决于该层在模型中的深度。模型中更靠近底部的层提取的是局部的、高度通用的特征图(比如视觉边缘、颜色和纹理),而更靠近顶部的层提取的是更加抽象的概念(比如“猫耳朵”或“狗眼睛”)。因此,如果你的新数 据集与原始模型训练的数据集有很大差异,那么最好只使用模型的前几层来做特征提取,而不是使用整个卷积基。
本例中,由于 ImageNet 的类别中包含多种狗和猫的类别,所以重复使用原始模型密集连接
层中所包含的信息可能很有用。但我们选择不这么做,以便涵盖新问题的类别与原始模型的类
别不一致的更一般情况。我们来实践一下,使用在 ImageNet 上训练的 VGG16 网络的卷积基从
猫狗图像中提取有趣的特征,然后在这些特征上训练一个猫狗分类器。
VGG16 等模型内置于 Keras 中。你可以从 keras.applications 模块中导入。下面是 keras.applications 中的一部分图像分类模型(都是在 ImageNet 数据集上预训练得到的):
Xception
Inception V3
ResNet50
VGG16
VGG19
MobileNet
# 代码清单 5-16 将 VGG16 卷积基实例化
from keras.applications import VGG16conv_base = VGG16(weights='imagenet',include_top=False,input_shape=(150, 150, 3))
print(conv_base.summary())这里向构造函数中传入了三个参数。
weights 指定模型初始化的权重检查点。
include_top 指定模型最后是否包含密集连接分类器。默认情况下,这个密集连接分
类器对应于 ImageNet 的 1000 个类别。因为我们打算使用自己的密集连接分类器(只有
两个类别:cat 和 dog),所以不需要包含它。
input_shape 是输入到网络中的图像张量的形状。这个参数完全是可选的,如果不传
入这个参数,那么网络能够处理任意形状的输入。
最后的特征图形状为 (4, 4, 512)。我们将在这个特征上添加一个密集连接分类器。
接下来,下一步有两种方法可供选择。
在你的数据集上运行卷积基,将输出保存成硬盘中的 Numpy 数组,然后用这个数据作 为输入,输入到独立的密集连接分类器中(与本书第一部分介绍的分类器类似)。这种 方法速度快,计算代价低,因为对于每个输入图像只需运行一次卷积基,而卷积基是目 前流程中计算代价最高的。但出于同样的原因,这种方法不允许你使用数据增强。
在顶部添加 Dense 层来扩展已有模型(即 conv_base),并在输入数据上端到端地运行 整个模型。这样你可以使用数据增强,因为每个输入图像进入模型时都会经过卷积基。 但出于同样的原因,这种方法的计算代价比第一种要高很多。
这两种方法我们都会介绍。首先来看第一种方法的代码:保存你的数据在 conv_base 中的
输出,然后将这些输出作为输入用于新模型。
1. 不使用数据增强的快速特征提取
首先,运行 ImageDataGenerator 实例,将图像及其标签提取为 Numpy 数组。我们需要调用 conv_base 模型的 predict 方法来从这些图像中提取特征。
# 代码清单5 - 17 使用预训练的卷积基提取特征
import os
import numpy as np
from keras.preprocessing.image import ImageDataGeneratorbase_dir = 'D:\dataset\cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1. / 255)
batch_size = 20def extract_features(directory, sample_count):features = np.zeros(shape=(sample_count, 4, 4, 512))labels = np.zeros(shape=(sample_count))generator = datagen.flow_from_directory(directory,target_size=(150, 150),batch_size=batch_size,class_mode='binary')i = 0for inputs_batch, labels_batch in generator:features_batch = conv_base.predict(inputs_batch)features[i * batch_size: (i + 1) * batch_size] = features_batchlabels[i * batch_size: (i + 1) * batch_size] = labels_batchi += 1if i * batch_size >= sample_count:breakreturn features, labels# break,注意,这些生成器在循环中不断生成数据,所以你必须在读取完所有图像后终止循环train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
目前,提取的特征形状为 (samples, 4, 4, 512)。我们要将其输入到密集连接分类器中,
所以首先必须将其形状展平为 (samples, 8192)。
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))现在你可以定义你的密集连接分类器(注意要使用 dropout 正则化),并在刚刚保存的数据
和标签上训练这个分类器。
# 代码清单5 - 18 定义并训练密集连接分类器
from keras import models
from keras import layers
from keras import optimizersmodel = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),loss='binary_crossentropy',metrics=['acc'])history = model.fit(train_features, train_labels,epochs=30,batch_size=20,validation_data=(validation_features, validation_labels))训练速度非常快,因为你只需处理两个 Dense 层。即使在 CPU 上运行,每轮的时间也不 到一秒钟。 我们来看一下训练期间的损失曲线和精度曲线。
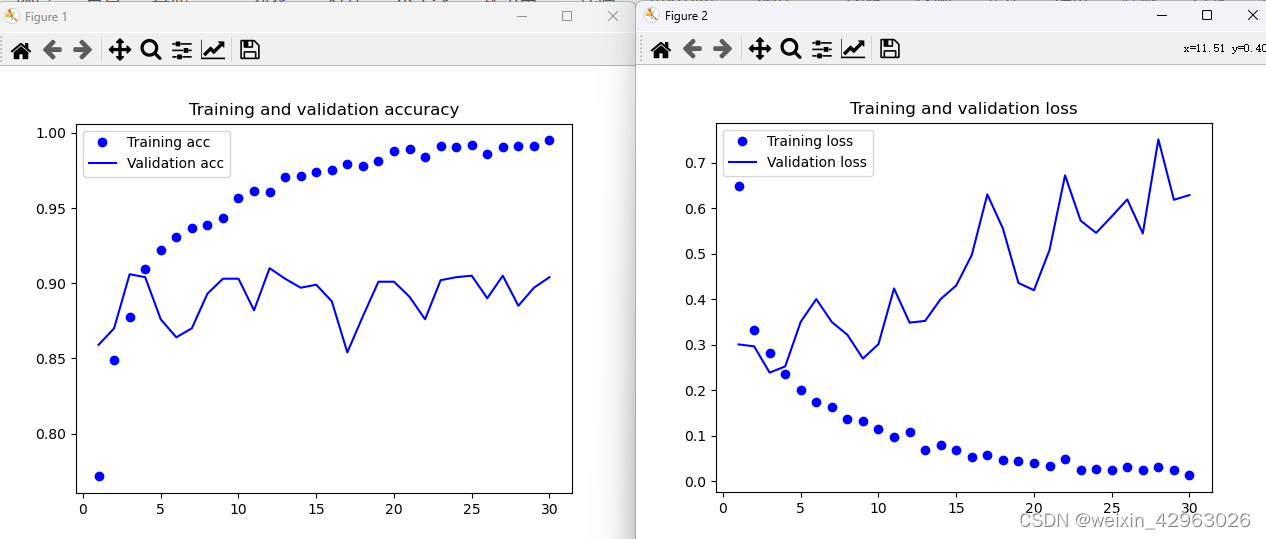
我们的验证精度达到了约 90%,比上一节从头开始训练的小型模型效果要好得多。但从图中也可以看出,虽然 dropout 比率相当大,但模型几乎从一开始就过拟合。这是因为本方法没有使用数据增强,而数据增强对防止小型图像数据集的过拟合非常重要。
2. 使用数据增强的特征提取
下面我们来看一下特征提取的第二种方法,它的速度更慢,计算代价更高,但在训练期间 可以使用数据增强。这种方法就是:扩展 conv_base 模型,然后在输入数据上端到端地运行模型。
注意 本方法计算代价很高,只在有 GPU 的情况下才能尝试运行。它在 CPU 上是绝对难以运
行的。如果你无法在 GPU 上运行代码,那么就采用第一种方法。
(这一部分遇到困难)