关于Pandas版本: 本文基于 pandas2.2.0 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
传送门: Pandas API参考目录
传送门: Pandas 版本更新及新特性
传送门: Pandas 由浅入深系列教程
本节目录
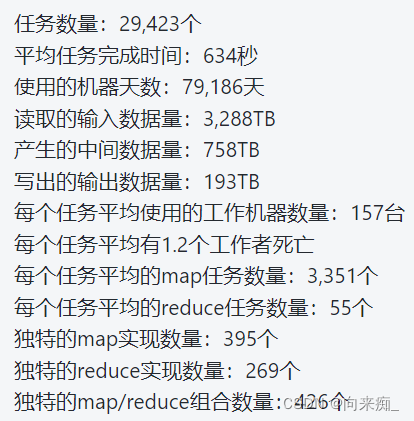
- Pandas.DataFrame.cumsum()
- 计算公式:
- 语法:
- 返回值:
- 参数说明:
- axis 指定计算方向(行或列)
- skipna 忽略缺失值
- *args,**kwargs
- 相关方法:
- 示例:
- 例1:如果是 `Series` 始终保持 `axis=0`,即计算 `Series` 所有元素的累积和。
- 例2:字符串求累和,相当于是字符串拼接
- 例3、计算每列累积和
- 例4、计算每行累积和
- 例5、默认会跳过缺失值,以缺失值上面的最近有效值,进行后面的计算
- 例6、如果不忽略缺失值,后面所有的结果,将都是缺失值。
Pandas.DataFrame.cumsum()
Pandas.DataFrame.cumsum 方法用于返回行或列每一个元素与前面所有元素的累积和。
⚠️ 注意 :
字符串可以求累积和,相当于字符串拼接。 例2
- 字符串不能和任何其他类型数据混用,比如 缺失值、数值,否则报错
TypeError
计算公式:
-
Pandas累积和计算公式:
S i = x 1 + x 2 + … + x i S_i = x_1 + x_2 + \ldots + x_i Si=x1+x2+…+xi
S i S_i Si 表示当前位置的累积和, x 1 + … + x i x_1+ \ldots + x_i x1+…+xi 表示从起始位置加到当前位置。
语法:
DataFrame.cumsum(axis=None, skipna=True, *args, **kwargs)
返回值:
- Series or DataFrame
参数说明:
axis 指定计算方向(行或列)
-
axis : {0 or ‘index’, 1 or ‘columns’}, default 0
axis参数,用于指定计算方向,即按行计算或按列计算累积和:- 如果是
Series此参数无效,将始终保持axis=0,即计算整列的累积和。例1 - 如果是
DataFrame默认为axis=0即计算每一列的累积和。并有以下参值可选:- 0 or ‘index’: 计算每列的累积和。 例3
- 1 or ‘columns’: 计算每行的累积和。例4
- 如果是
skipna 忽略缺失值
-
skipna : bool, default True >
skipna参数,用于指定求累积和的时候是否忽略缺失值,默认skipna=True表示忽略缺失值:- True: 忽略缺失值。当遇到缺失值,会跳过缺失值,以缺失值上面的最近有效值继续后面的计算。 例5
- False: 不忽略缺失。但是后面的所有结果将都是缺失值。例6
*args,**kwargs
- 为了保持与
Numpy的兼容性而保留的参数,一般不需要传递任何内容。
相关方法:
➡️ 相关方法
Series.cumsum
Series 累积和
DataFrame.sum
求和
DataFrame.cummax
累积最大值
DataFrame.cummin
累积最小值
DataFrame.cumprod
累积乘积
示例:
测试文件下载:
本文所涉及的测试文件,如有需要,可在文章顶部的绑定资源处下载。
若发现文件无法下载,应该是资源包有内容更新,正在审核,请稍后再试。或站内私信作者索要。
例1:如果是 Series 始终保持 axis=0,即计算 Series 所有元素的累积和。
import numpy as np
import pandas as pds = pd.Series([24.0, np.nan, 21.0, 33, 26], name="age")
s.cumsum()
0 24.0
1 NaN
2 45.0
3 78.0
4 104.0
Name: age, dtype: float64
例2:字符串求累和,相当于是字符串拼接
import numpy as np
import pandas as pddf = pd.DataFrame({"第一列": ["一", "二", "三"], "第二列": ["四", "五", "六"]})df.cumsum()
| 第一列 | 第二列 | |
|---|---|---|
| 0 | 一 | 四 |
| 1 | 一二 | 四五 |
| 2 | 一二三 | 四五六 |
例3、计算每列累积和
import numpy as np
import pandas as pddf = pd.DataFrame([[2.0, 1.0],[3.0, np.nan],[1.0, 0.0]],columns=list('AB'))df.cumsum()
| A | B | |
|---|---|---|
| 0 | 2.0 | 1.0 |
| 1 | 5.0 | NaN |
| 2 | 6.0 | 1.0 |
例4、计算每行累积和
import numpy as np
import pandas as pddf = pd.DataFrame([[2.0, 1.0, 3.0], [3.0, np.nan, 5.0], [1.0, 1.0, 1.0], [1.0, 0.0, 2.0]],columns=list("ABC"),
)df.cumsum(axis=1)
| A | B | C | |
|---|---|---|---|
| 0 | 2.0 | 3.0 | 6.0 |
| 1 | 3.0 | NaN | 8.0 |
| 2 | 1.0 | 2.0 | 3.0 |
| 3 | 1.0 | 1.0 | 3.0 |
例5、默认会跳过缺失值,以缺失值上面的最近有效值,进行后面的计算
import numpy as np
import pandas as pddf = pd.DataFrame([[2.0, 1.0],[3.0, np.nan],[1.0, 1.0],[1.0, 0.0]],columns=list('AB'))df.cumsum()
| A | B | |
|---|---|---|
| 0 | 2.0 | 1.0 |
| 1 | 5.0 | NaN |
| 2 | 6.0 | 2.0 |
| 3 | 7.0 | 2.0 |
例6、如果不忽略缺失值,后面所有的结果,将都是缺失值。
import numpy as np
import pandas as pddf = pd.DataFrame([[2.0, 1.0],[3.0, np.nan],[1.0, 1.0],[1.0, 0.0]],columns=list('AB'))df.cumsum(skipna=False)
| A | B | |
|---|---|---|
| 0 | 2.0 | 1.0 |
| 1 | 5.0 | NaN |
| 2 | 6.0 | NaN |
| 3 | 7.0 | NaN |