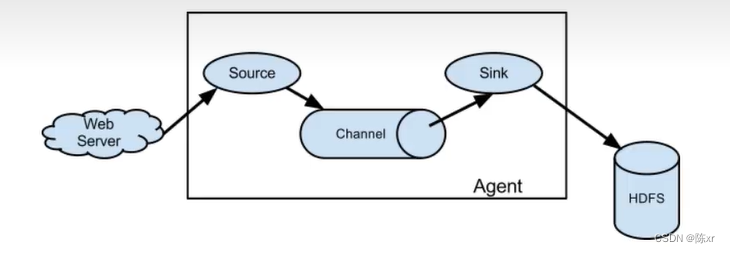
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink的设计目标是在所有常见的集群环境中运行,并以内存执行速度和任意规模来执行计算。它支持高吞吐、低延迟、高性能的流处理,并且是一个面向流处理和批处理的分布式计算框架,将批处理看作一种特殊的有界流。
Flink的主要特点包括:
- 事件驱动型:Flink是一个事件驱动型的应用,可以从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
- 支持有状态计算:Flink提供了Extactor-once语义及checkpoint机制,支持带有事件操作的流处理和窗口处理,以及灵活的窗口处理(如时间窗口、大小窗口等)。
- 轻量级容错处理:Flink使用savepoint进行错误恢复,可以在出现故障时快速恢复任务。
- 高吞吐、低延迟、高性能:Flink的设计目标是在保证数据处理稳定性的同时,实现高吞吐、低延迟、高性能的流处理。
- 支持大规模集群模式:Flink支持在yarn、Mesos、k8s等大规模集群环境中运行。
- 支持多种编程语言:Flink对java、scala、python都提供支持,但最适合使用java进行开发。
Flink的应用场景非常广泛,可以用于实时流数据的分析计算、实时数据与维表数据关联计算、实时数仓建设、ETL(提取-转换-加载)多存储系统之间进行数据转化和迁移等场景。同时,Flink也适用于事件驱动型应用场景,如以kafka为代表的消息队列等。
1.Winows系统安装Flink
下载地址:Downloads | Apache Flink

选择 Apache Flink 1.16.0 - 2022-10-28 (Binaries)
下载 flink-1.16.0-bin-scala_2.12.tgz
使用CMD窗口,在Flink安装路径/bin目录下启动start-cluster.bat
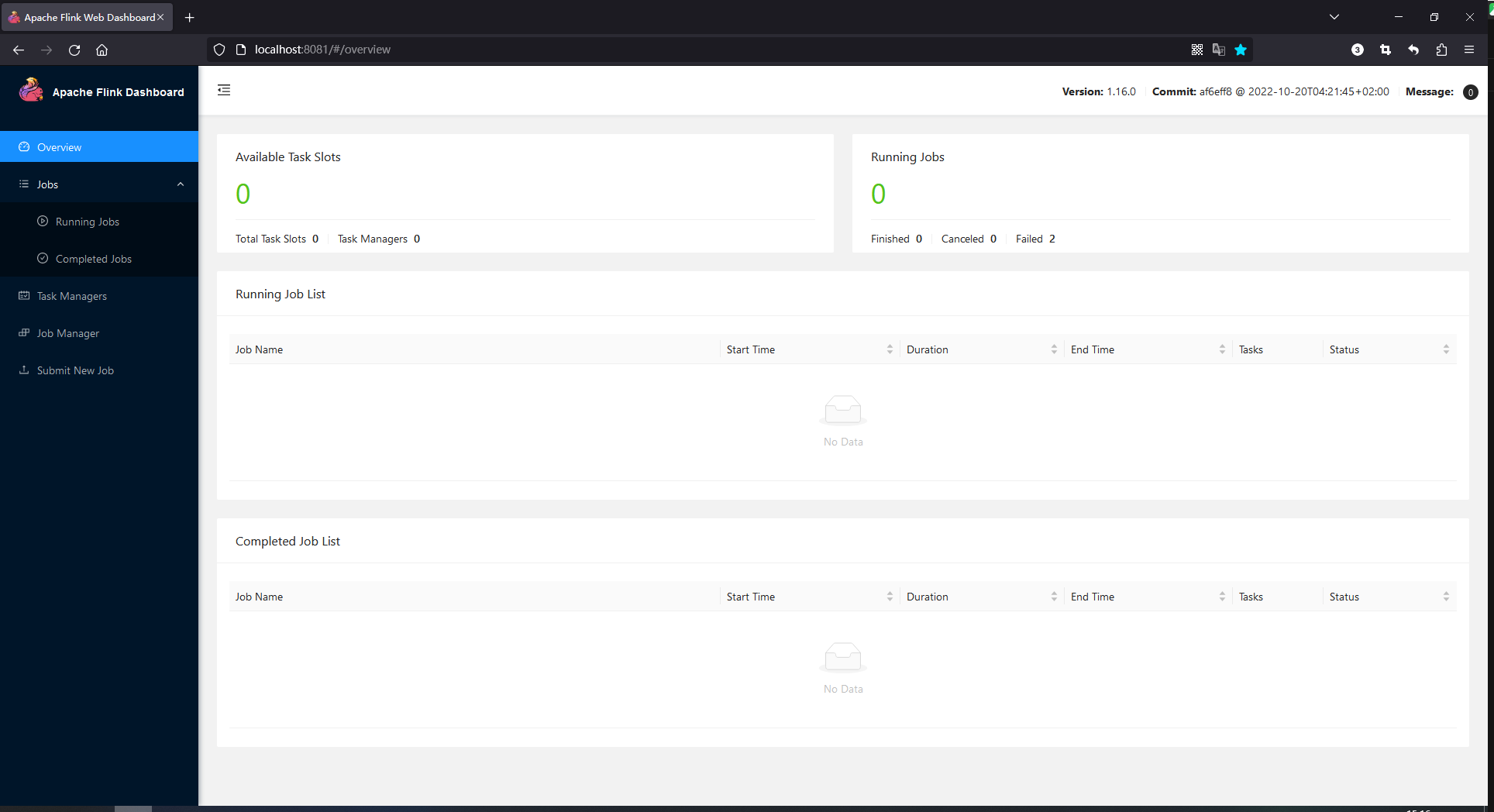
访问http://localhost:8081,界面如下:
2.使用Flink实现MySQL数据库之间数据同步(JAVA)
<flink.version>1.16.0</flink.version> <flink-cdc.version>2.3.0</flink-cdc.version>
1.创建Flink流处理运行环境。
2.设置流处理并发数。
3.设置Flink存档间隔时间,单位为ms,当同步发生异常时会恢复最近的checkpoint继续同步。
4.在Flink中创建中间同步数据库。
5.在Flink中创建中间表flink_source,来源于MySQL表source,(注意connector为mysql-cdc)。
6.在Flink中创建中间表flink_sink,来源于MySQL表sink。
7.将Flink中间表来源表数据写入flink_sink表,Flink会根据MySQL binlog中source表变化,动态更新flink_sink表,同时会将flink_sink表数据写入MySQL sink表,实现MySQL数据持续同步。
package com.demo.flink;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;public class FlinkCdcMySql {public static void main(String[] args) {System.out.println("==========start run FlinkCdcMySql#main.");// 创建Flink流处理运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("127.0.0.1", 8081);// 设置流处理并发数env.setParallelism(3);// 设置Flink存档间隔时间,单位为ms,当同步发生异常时会恢复最近的checkpoint继续同步env.enableCheckpointing(5000);final StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);// 在Flink中创建中间同步数据库tEnv.executeSql("CREATE DATABASE IF NOT EXISTS flink_test");// 在Flink中创建中间表flink_source,来源于MySQL表source// 注意connector为mysql-cdctEnv.executeSql("CREATE TABLE flink_test.flink_source (\n" +" id int,\n" +" name varchar(255),\n" +" create_time TIMESTAMP\n," + // Flink不支持datetime格式" PRIMARY KEY (id) NOT ENFORCED" + //主键必须标明NOT ENFORCED") WITH (\n" +" 'connector' = 'mysql-cdc',\n" +" 'hostname' = '127.0.0.1',\n" +" 'database-name' = 'flink-source',\n" +" 'table-name' = 'source',\n" +" 'username' = 'root',\n" +" 'password' = 'root'\n" +")");// 在Flink中创建中间表flink_sink,来源于MySQL表sinktEnv.executeSql("CREATE TABLE flink_test.flink_sink (\n" +" id int,\n" +" name varchar(255),\n" +" create_time TIMESTAMP\n," +" PRIMARY KEY (id) NOT ENFORCED" +") WITH (\n" +" 'connector' = 'jdbc',\n" +" 'url' = 'jdbc:mysql://127.0.0.1:3306/flink-sink',\n" +" 'table-name' = 'sink',\n" +" 'driver' = 'com.mysql.jdbc.Driver',\n" +" 'username' = 'root',\n" +" 'password' = 'root'\n" +")");// Table transactions = tEnv.from("flink_source");
// transactions.executeInsert("flink_sink");System.out.println("==========begin Mysql data cdc.");// 将Flink中间表来源表数据写入flink_sink表// Flink会根据MySQL binlog中source表变化,动态更新flink_sink表,同时会将flink_sink表数据写入MySQL sink表,实现MySQL数据持续同步tEnv.executeSql("INSERT INTO flink_test.flink_sink(id, name, create_time)\n" +"select id, name, create_time\n" +"from flink_test.flink_source\n");System.out.println("==========continue Mysql data cdc.");}}
git代码地址:
flink-cdc-MySQL: FlinkCDC实现MySQL之间数据同步