2023愚人杯
1. 阿尼亚哇库哇库
压缩包里两个文件: 阿尼亚哇库哇库!.doc 和 HINT.png
先看HINT.png,图片打不开
使用01打开:
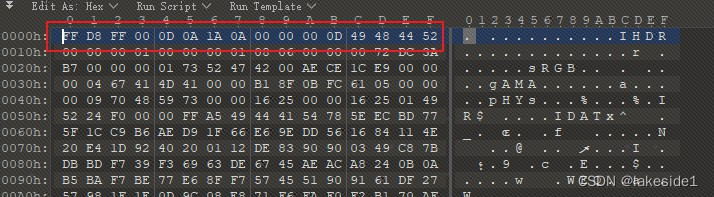
发现文件头有问题,前几位修改为89 50 4E 47后,图片打开依然不正常。发现长高尺寸不对。用脚本根据CRC值,爆破得长高值,填入后,打开正常。
爆破脚本:
import zlib
import struct#根据png的CRC校验值,爆破png图片的宽w高h
filename = 'HINT1.png'
with open(filename, 'rb') as f:all_b = f.read()crc32key = int(all_b[29:33].hex(), 16)data = bytearray(all_b[12:29])n = 4095 # 理论上0xffffffff,但考虑到屏幕实际/cpu,0x0fff就差不多了for w in range(n): # 高和宽一起爆破width = bytearray(struct.pack('>i', w)) # q为8字节,i为4字节,h为2字节for h in range(n):height = bytearray(struct.pack('>i', h))for x in range(4):data[x + 4] = width[x]data[x + 8] = height[x]crc32result = zlib.crc32(data)if crc32result == crc32key:# 2021.7.20,有时候显示的宽高依然看不出具体的值,干脆输出data部分print(data.hex())print("宽为:", end="")print(width)print("高为:", end="")print(height)exit(0)
修补后打开:

除了GB2312,冒失没啥提示信息
把 阿尼亚哇库哇库!.doc中的内容转存为一个文本文件waku.txt

使用脚本,提取文件中的。?!,转存为.?!,然后解码得ctfshow{4niya_KaWa1i!}
f1 = open("./waku.txt", "r", encoding='utf-8')
f2 = open("./waku1.txt", 'w', encoding='utf-8')
text = f1.readlines()
text = list(text)
ls = []
for i in text:print(i[-2])if i[-2] =='。':f2.write('.')elif i[-2] =='?':f2.write('?')elif i[-2] == '!':f2.write('!')
f1.close()
f2.close()

2. 琴柳感
打开压缩包里的qlg.txt,发现主要是四句话的重复:
'你有没有感受到城市在分崩离析?','你不曾注意阴谋得逞者在狞笑。','你有没有听见孩子们的悲鸣?,'你是否想过......朋友不再是朋友,家园不再是家园。'
猜测对应0,1,2,3.可能是base4编码。但不知是怎么对应,因此在脚本里爆破。ctfshow{xingbucengxing_yibuzaiyi_zaikelianyilianba}
####base4解码脚本base4.py
#base4编码:把每个字节八位二进制值切成4个2位,分别用0,1,2,3表示。
def b4decode(b4str):if len(b4str) % 4 != 0:print('必须是4的倍数')return ''res = [ chr( (int(b4str[i])<<6) + (int(b4str[i+1])<<4) + (int(b4str[i+2])<<2) + int(b4str[i+3]) )for i in range(0,len(b4str),4)]return ''.join(res)####爆破脚本
import base4,itertoolsstrs = [['你有没有感受到城市在分崩离析?','0'],['你不曾注意阴谋得逞者在狞笑。','1'],['你有没有听见孩子们的悲鸣?','2'],['你是否想过......朋友不再是朋友,家园不再是家园。','3'] ]def decode(text,strs):str1 = ''while True:pos,val,length = 99999,None,Nonenofound = 0for i in range(4):try:pos1 = text.index(strs[i][0])#print(pos1)if pos > pos1:pos = pos1val = strs[i][1]length = len(strs[i][0])except:nofound += 1if nofound >= 4:return str1str1 += valtext = text[pos+length:]#print(text[0:100])#input()with open('qlg.txt','r',encoding='gbk') as f:text = f.read()#遍历每种对应的值
count = 0
for i in itertools.permutations('0123'):strs[0][1] = i[0]strs[1][1] = i[1]strs[2][1] = i[2]strs[3][1] = i[3]print('\n%d-------------------------------'%count)count += 1#print(strs)b4str = decode(text,strs)print(b4str)res = base4.b4decode(b4str)print(res)if 'ctfshow{' in res:exit()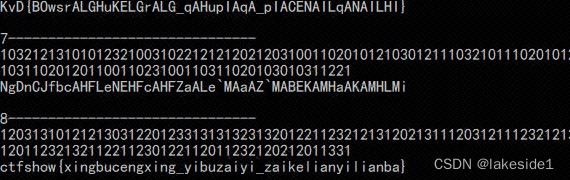
3.低端的base64
发现flag.txt中的字符串非常象base64编码,但是没有大写字母。猜测所有大写字母都转成了小写。所以按4个字符一组,爆破所有字母。
import base64,itertoolswith open("./flag.txt","r") as f:text = f.read()for i in range(0, len(text), 4):item = text[i:i+4]itemlist = []for ch in item:if ch.isalpha():itemlist.append([ch,ch.upper()])else:itemlist.append([ch])for random_list in itertools.product(itemlist[0],itemlist[1],itemlist[2],itemlist[3]):s = ''.join(random_list)try:res = base64.b64decode(s).decode()if res.isprintable():print(res,end=' ')except:passprint('')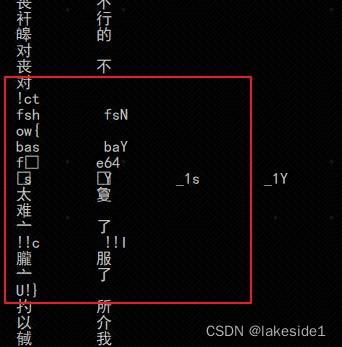
ctfshow{base64_1s太难了!!I服了U!}