文章目录
- 🐒个人主页
- 🏅JavaEE系列专栏
- 📖前言:
- 🎀你为什么要学习JVM?
- 🎀JVM的作用
- 🎀JVM的构成(5大类)
- 🏨1.类加载系统
- 🐕类什么时候会被加载?
- 🐕类加载器的分类(具体加载类的执行者)
- 🐕双亲委派机制
- 🪀如何打破双亲委派机制呢?
- 🏨2.运行时数据区
- 🐕程序计数器
- 🐕虚拟机栈
- 🐕本地方法栈
- 🐕堆 (存储空间)
- 🧸堆为什么要进行区域划分?(新生代、老年代)
- 🧸对不同区域垃圾回收的称呼
- 🧸(堆空间参数设置)jvm调优
- 🐕方法区
- 🏨3.本地方法接口
- 🏨4.执行引擎
- 🏨5.垃圾回收
- 🐕Stop the world
- 🐕垃圾回收的相关算法
- 🪀垃圾标记阶段
- 🪀垃圾回收阶段
- 🐕finalize()方法
- 🐕垃圾回收器
- 🪀垃圾回收器的分类
- 🪀CMS垃圾回收器 ( Concurrent Mark Sweep 并发标记清除 )
- 🪀G1垃圾回收器(Garbage First)
- 🐒持续更新...
🐒个人主页
🏅JavaEE系列专栏
📖前言:
本篇博客主要以总结面试中对JVM知识的考察点
🎀你为什么要学习JVM?
通过学习jvm,对程序的运行过程更加的了解,提高自己对编码的认识,扩展自己的知识储备,以提高编码规范。它也是中高级程序员必备的知识技能(项目管理、性能调优),先入门为以后铺路。
🎀JVM的作用
1.将.class字节码文件加载到内存中,负责存储数据
2.将字节码解释/编译成计算机能识别的机器码
3.垃圾回收
🎀JVM的构成(5大类)
- 类加载系统(将字节码文件加载到JVM中)
- 运行时数据区(虚拟机栈、堆、方法区、本地方法栈、程序计数器)
- 本地方法接口(负责调用操作系统提供的本地方法)
- 执行引擎(将字节码 解释/编译成机器码)
- 垃圾回收 (回收垃圾数据,释放内存空间)
🏨1.类加载系统
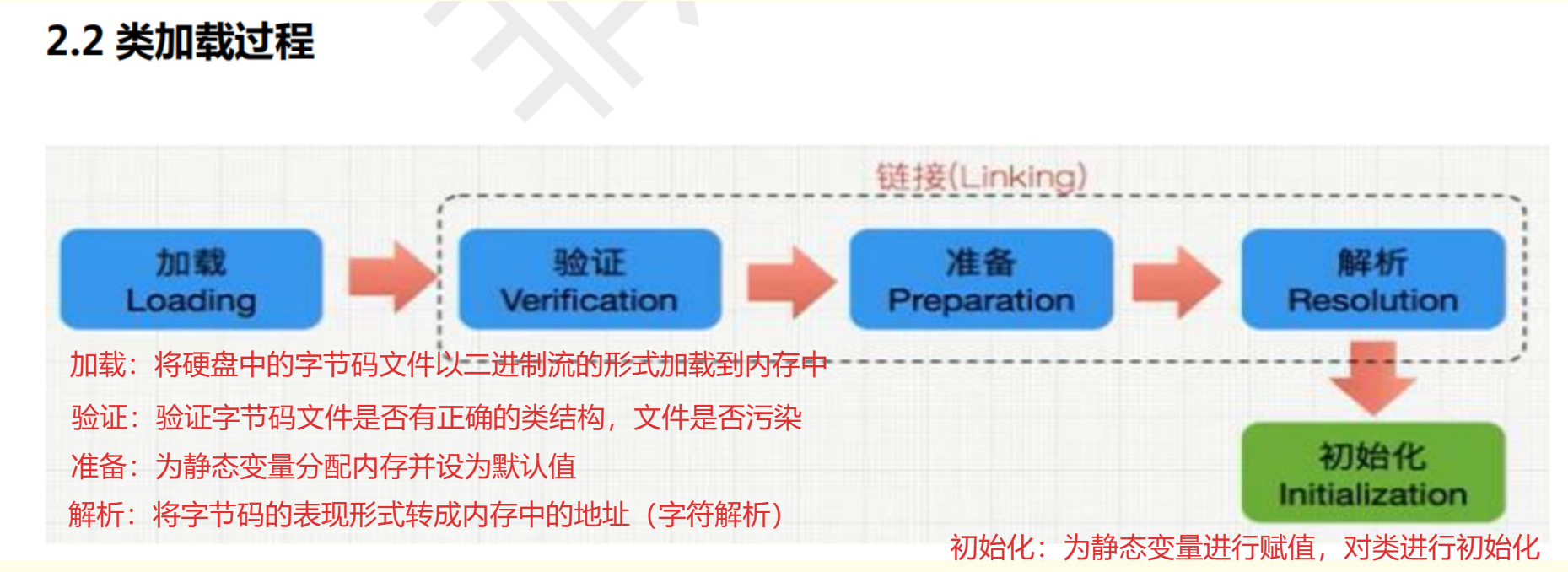
验证:不包含以final修饰的静态变量,因为会把它视为静态常量
🐕类什么时候会被加载?
- 在类中运行main()时
- 创建对象时
- 使用类中的静态变量
- 反射class.forName(“类地址”)
- 初始化子类。导致父类被加载
【注意:final修饰的是常量不会被加载】【 Car[] cars=new Car[10]; 这种情况也不会被加载 】
🐕类加载器的分类(具体加载类的执行者)
大致分为两大类:引导类加载器、其他类加载器(扩展类加载器、应用程序类加载器、用户自定义类加载器)
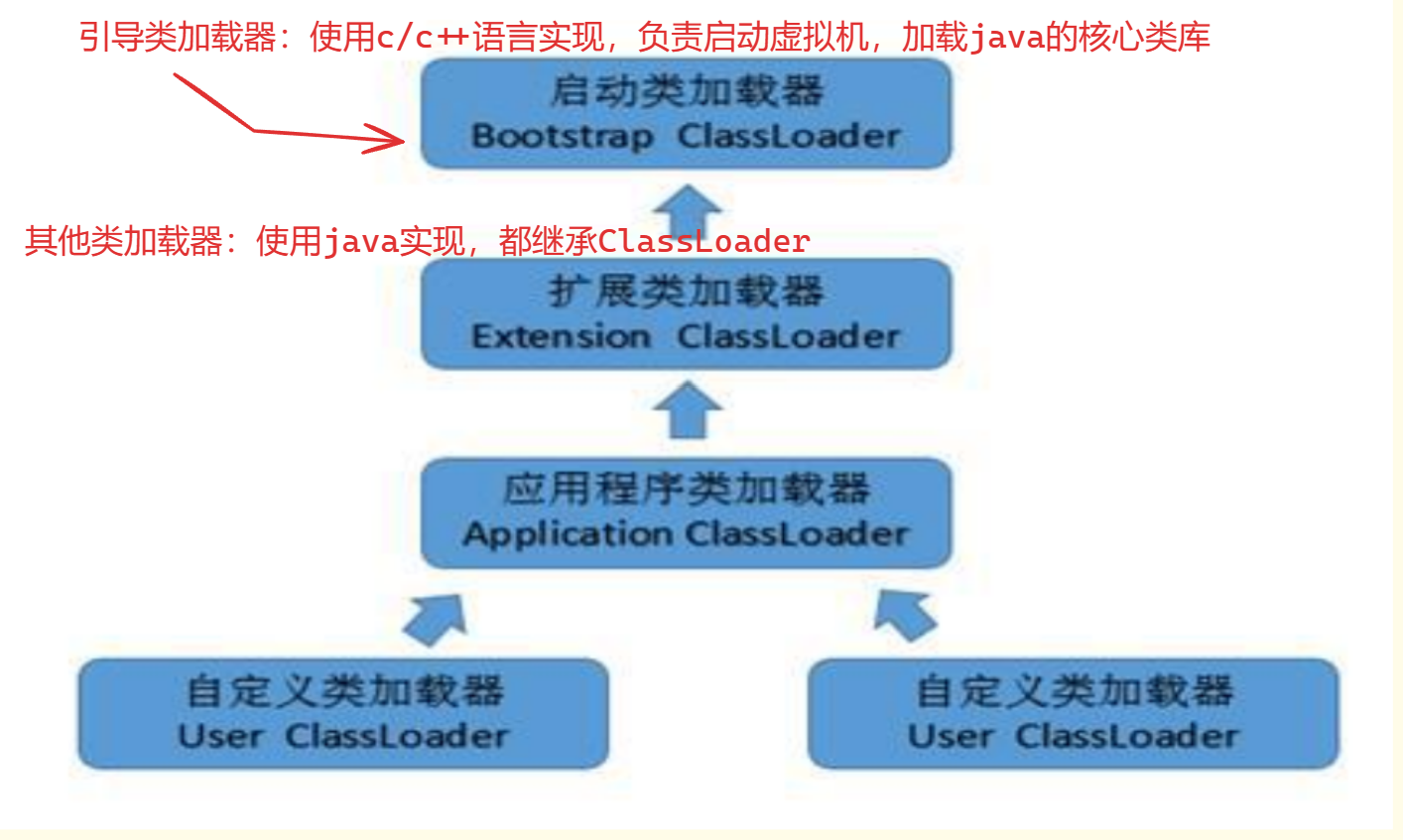
🐕双亲委派机制
当加载一个类的时候,会先让上一级类加载器去加载,直到找到引导类加载器,再向下到扩展类加载器中寻找是否可以加载此类,如果不可以,就再向下到应用程序类加载器中找,如果都找不到,就报异常
【好处】:避免了我们自己定义的子类覆盖了系统中的类,双亲委派机制会确保优先调用系统中的类。 eg: (自己定义一个String类,但仍然会调用系统中的String类,而不会调用自己定义的)
🪀如何打破双亲委派机制呢?
可以通过继承ClassLoader类,重写ClassLoader类中的findClass方法,实现自定义类加载。
也可以重写 loadClass 方法(是实现双亲委派逻辑的地方,修改他会破坏双亲委派机制, 不推荐)
eg: Tomcat服务器自定义类加载规则
🏨2.运行时数据区

🐕程序计数器
特点:内存空间小,jvm中运行速度最快的区域,线程私有的(生命周期同线程一样),不会有内存溢出问题,不会有垃圾回收。
作用:记录此线程正在执行的位置,以便线程切换后继续执行
🐕虚拟机栈
特点:线程私有的,存在内存溢出问题,不会有垃圾回收,用来执行方法,栈的基本单位是栈帧(一个栈帧就是一个方法)
栈帧的结构:(局部变量表、操作数栈、返回方法调用地址…)
🐕本地方法栈
特点:也是线程私有的,存在内存溢出问题,不会有垃圾回收,用来执行本地方法(就是操作系统提供的方法),修饰的关键字是 native,没有方法体。它使用C语言写的。
eg:
Object类中的hashCode() 、clone() 、getClass() 、notify() 、notifyAll()、wait() ;
Thread.start()中有一个start0()本地方法、
FileInputStream的read()方法中调用了read0()本地方法
🐕堆 (存储空间)
存放程序中产生的对象,线程共享,存在堆溢出,是垃圾回收的重点区域。
堆的大小可以调节。
堆区域划分:
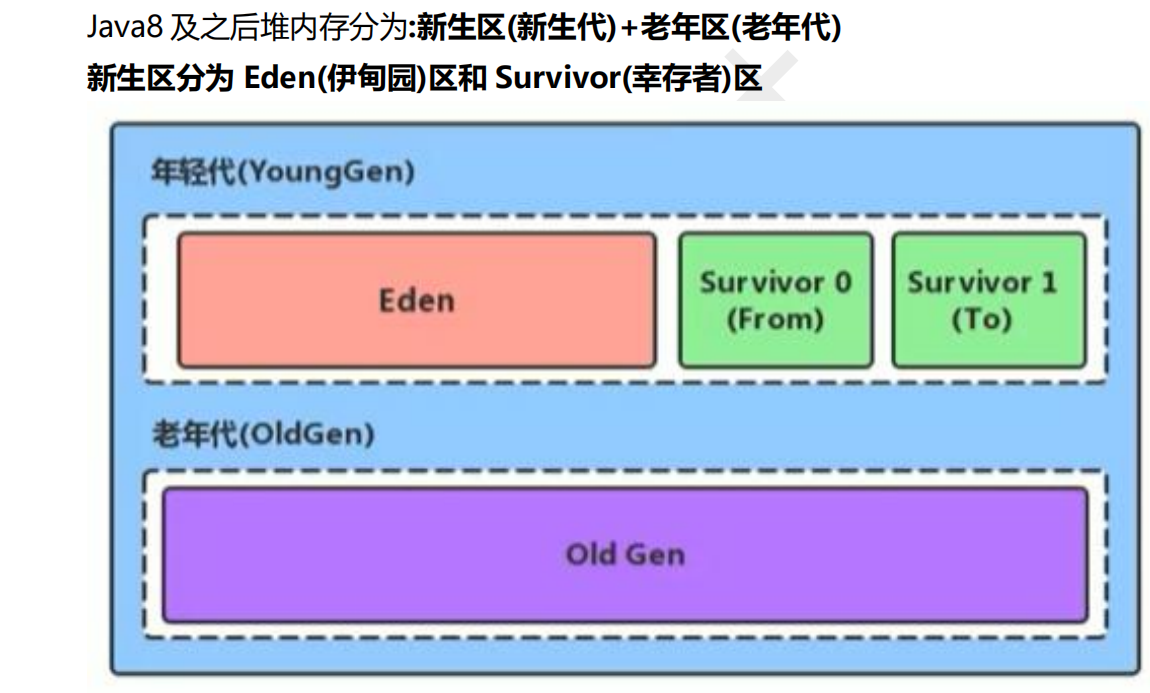
新生代:
🍓伊甸园区:存放刚刚创建的对象
🍓幸存者1区:进行一次GC,存放伊甸园区以及另一个幸存者区存活的对象,清空这两个区域的垃圾
🍓幸存者2区:进行一次GC,存放伊甸园区以及另一个幸存者区存活的对象,清空这两个区域的垃圾
老年代:
存放超过进行15次垃圾回收仍然存活的对象或 大对象(list中有元素,List就是大对象),垃圾回收频率比新生代慢。(默认是15次,最大也是15次,在对象头中分代年龄占4个比特位,可以自己调节参数)
比例关系:【新生代 : 老年代=2 : 1】【伊甸园 : 幸存者1 : 幸存者2= 8 : 1 : 1】
🧸堆为什么要进行区域划分?(新生代、老年代)
根据对象存活的生命周期进行分区,调整不同区域垃圾回收频率,从而提高垃圾回收效率。还可以对不同区域采用不同的垃圾回收器、垃圾回收算法,对算法扬长避短。
🧸对不同区域垃圾回收的称呼
Minor GC :新生代垃圾回收
Major GC :老年代垃圾回收
Full GC :整堆收集(触发条件:老年区满了 或 方法区满了)
🧸(堆空间参数设置)jvm调优
没有调过,它是根据程序运行的实际需要来进行参数设置,来调整各个区间的比例大小
🐕方法区
存储加载到虚拟机的类信息,方法区的大小可以调整参数,
方法区是线程共享的,会存在内存溢出,可以进行垃圾回收,但是条件非常苛刻: 1.该类实例全部回收 2.该类的类加载器已经回收 3.该类没有在任何地方被引用
🏨3.本地方法接口
本地方法是非java方法,是java调用外部环境的方法,
java提供一个接口,让java可以与其他应用进行交互。
🏨4.执行引擎
是jvm中将字节码 解释/编译为机器码的区域模块。
辨析:
前端编译: 将.java文件经过JDK中的javac编译成.class文件
后端编译:将.class文件经过JVM中的执行引擎编译成机器码
解释器:一行一行的执行代码。(效率低,但省去了编译时间) eg: 脚本语言html、python…
JIT编译器: (just in time)(及时编译器)将一段代码作为整体进行编译,将结果缓存起来,直接引用。(编译需要花费时间,执行效率高,适合“热点代码段”)
java采用的是半解释半编译的方式,可以先逐行解释执行,到“热点代码”时再对此编译执行并将结果缓存起来,两者结合使用,提高运行效率。
🏨5.垃圾回收
(【垃圾】没有被任何引用指向的对象成为“垃圾”,它们会占据内存空间)
(【内存溢出】内存满了,空间不足)
(【内存泄漏】我们已经不用的对象无法被垃圾回收,仍然占据着内存,导致内存空间越来越小,严重时可引发“内存溢出”)
🐕Stop the world
简称STW,指GC事件发生的过程中,会产生程序的停顿。(停顿产生时,整个应用程序都会暂停,像拍快照)。原因是GC需要先标记垃圾,为了保证数据一致性,以防出现错标、漏标垃圾的情况。
🐕垃圾回收的相关算法
🪀垃圾标记阶段
主要标记哪些对象是垃圾。
引用计数算法:统计每个对象被引用的次数,从而判断此对象是否是垃圾对象。(没有被使用)
(🎀缺点:
1.需要计数,增加空间开销 2.每次需要更新,增加时间开销。
3.无法处理循环引用问题(P->A->B->C->A,此时只有P是已知的,如果把P断开,ABC就形成了一个孤岛,导致“内存泄漏”)
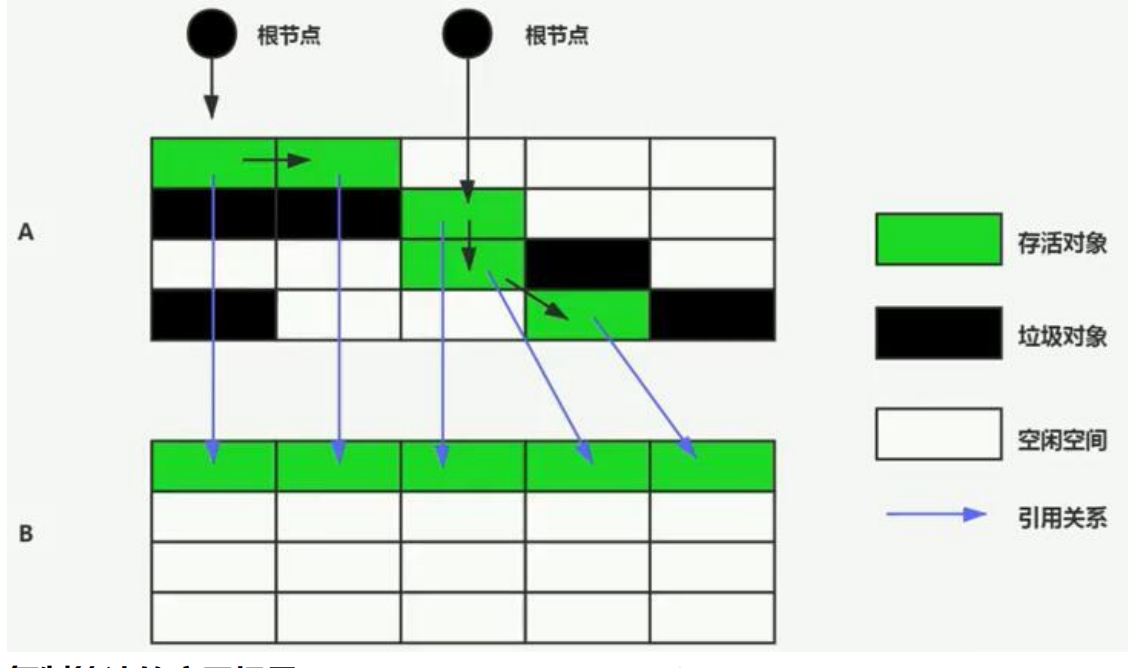
可达性分析算法:(根搜索算法),有一组“根”对象为起始点,看其他对象是否可达,若不可达则被认为是垃圾对象。
🎀名词解释:
根:虚拟机栈中的引用对象、方法区中的静态变量、所有被synchronized持有的锁对象、java系统中的类
引用链:搜索的路径
🪀垃圾回收阶段
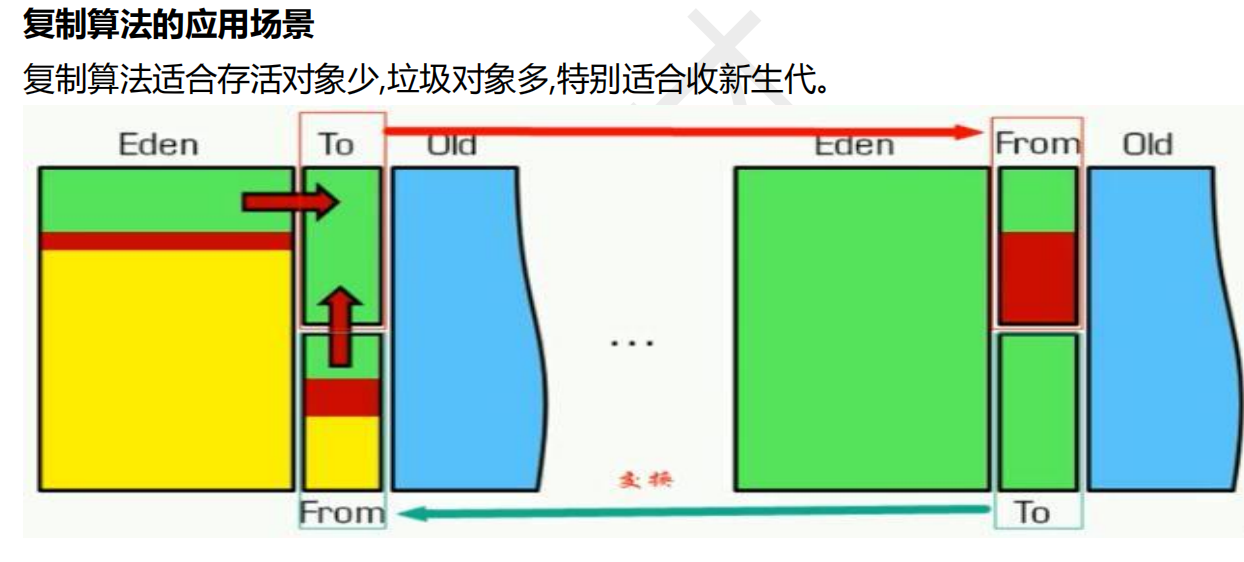
回收阶段目前在JVM中三种常见的算法:复制、清除、压缩
复制算法: 类比两块幸存者区,其中一块B是空的,将另一块A的存活的对象复制到B,把A清空,循环往复,内存碎片少
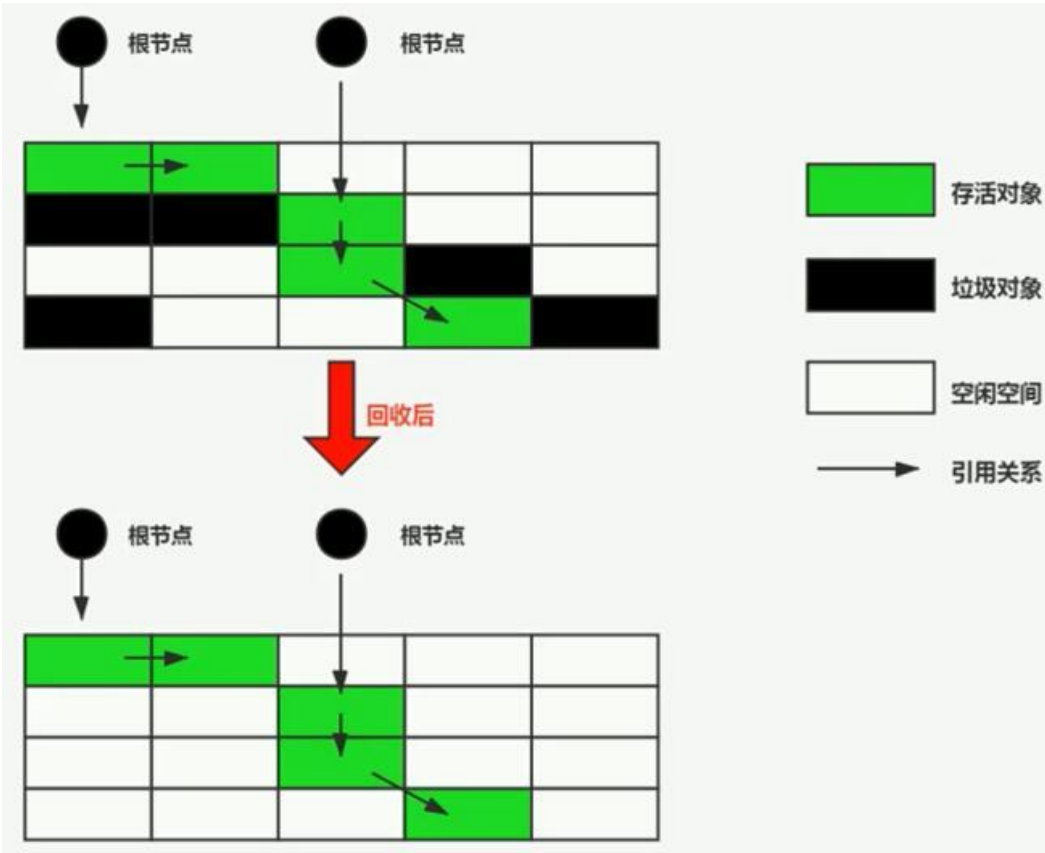
清除算法: 存活对象位置不变,用列表记录一下垃圾对象的位置,不会把它们清除掉,下次需要使用此内存空间时,直接覆盖掉。适用于老年区,但因为不移动对象,会产生内存碎片。
压缩算法: 将存活的对象重新排列到一端,将剩余区域直接清理。无内存碎片。效率低,适合老年区。
🐕finalize()方法
是Object类中提供的方法,对象垃圾回收前会自动调用此方法,并且finalize()方法只会被调用一次,重写finalize()可能复活对象(相当于复活甲),第二次被回收时不会调用finalize(),直接被回收。
为此定义虚拟机中对象三种状态:
可触及的 :就是可达的,有引用指向的
可复活的 :对象所有引用被释放,但是对象可能在finalize()中复活
不可触及的:对象的finalize()被调用,并没有复活
🐕垃圾回收器
真正进行垃圾回收的执行者。
🪀垃圾回收器的分类
按线程数分类:
🎇单线程: 适用于简单小型场景,只有一个线程进行垃圾回收,GC时,其他应用程序停止工作(STW)
🎇多线程:有多个线程进行垃圾回收
按工作模式分类:
🎇独占式:就是STW,当GC工作时,其他线程停止工作
🎇并发式:GC线程可以和其他用户线程同时工作
按年龄分代分类:
🎇新生代:
🎇老年代:
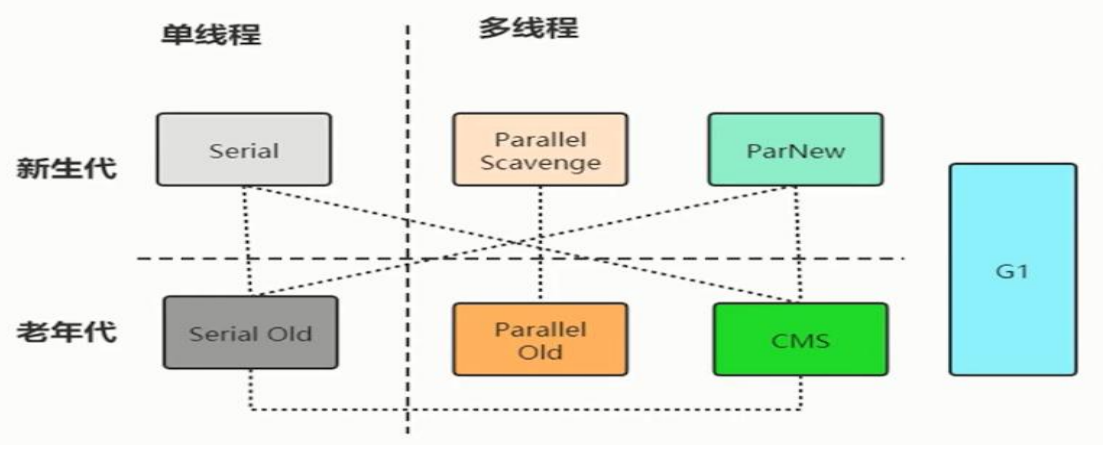
🪀CMS垃圾回收器 ( Concurrent Mark Sweep 并发标记清除 )
目标:追求低停顿 (首个实现垃圾回收线程与其他用户线程同时工作,但不是所有的都是并发执行的,也会有独占执行的时候)
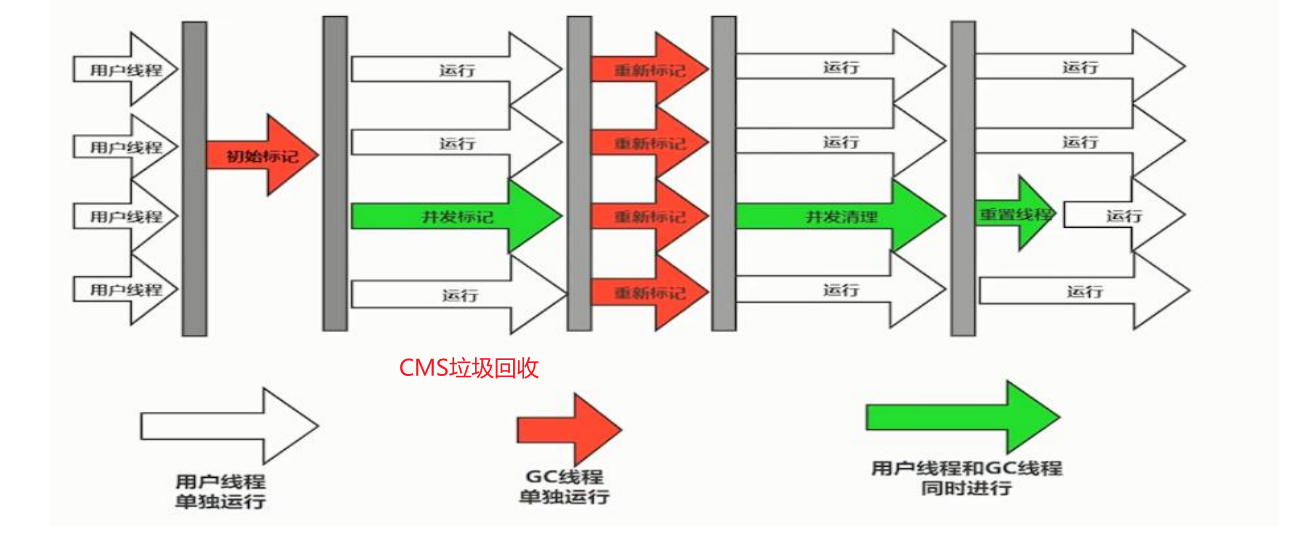
CMS垃圾回收过程:
1.初始标记:STW 独占 会暂停其他用户线程
2.并发标记: 并发 会与其他用户线程同时工作
3.重新标记:STW 独占 会暂停其他用户线程
4.并发清除: 并发 会与其他用户线程同时工作
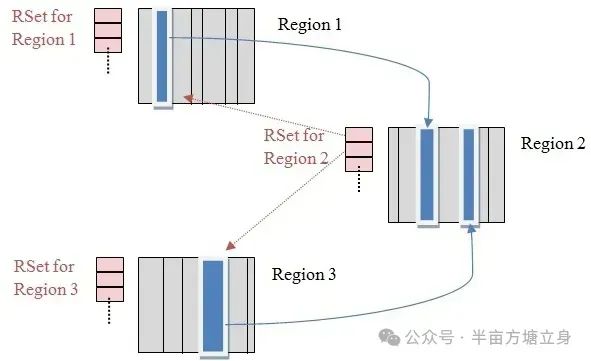
🪀G1垃圾回收器(Garbage First)
适合多核CPU、大内存大型项目 ,它将每个区域(伊甸园、幸存者1、…)又划分成了更小的区域,哪一个区域垃圾数量多,就优先回收哪一个区域,它可以做到整堆收集管理。当然它也可以做到并发执行。