作为病理图像分析的基础,细胞核检测可为细胞形态、纹理等多种相关分析提供支持,对于临床诊断具有重要意义。但是细胞核的人工识别过程十分费时费力,并且不同医生之间存在主观标注差异。因此,利用计算机技术进行自动检测能够更为客观地实现细胞核定位,并使得检测结果具有可重复性。然而自动化的细胞核检测技术目前仍存在一些问题。首先,受不同病理中心制作流程不一的影响,病理图像常常会存在染色深浅不一致以及伪影、模糊等人为干扰现象,为细胞核检测任务带来强烈的背景噪声。其次,在病理图像中细胞尺寸变化不一,形态差异悬殊,且不同细胞之间存在粘连或重叠等现象,为细胞核检测任务带来更多挑战。
随着近年来以深度学习为代表的人工智能技术的高速发展,出现了许多基于深度学习的细胞核检测方法研宄,其可以充分发挥在大数据样本上的优势,在细胞核检测任务上取得了巨大的成功。但是目前基于深度学习的方法在训练过程中往往需要大量的标注数据,而医学图像的标注依赖具有专业知识的医生,标注成本极其昂贵。尤其在细胞核检测领域中,每张图像具有成千上万的细胞核,标注散布在图像上的每个细胞需要耗费大量时间和人力成本。在实际应用中,相比有标注数据而言,无标注数据的获取代价极低。因此,如何在使用少量有标注数据的情况下,通过进一步利用无标注数据提高模型的预测性能己成为细胞核检测领域的研究热点。
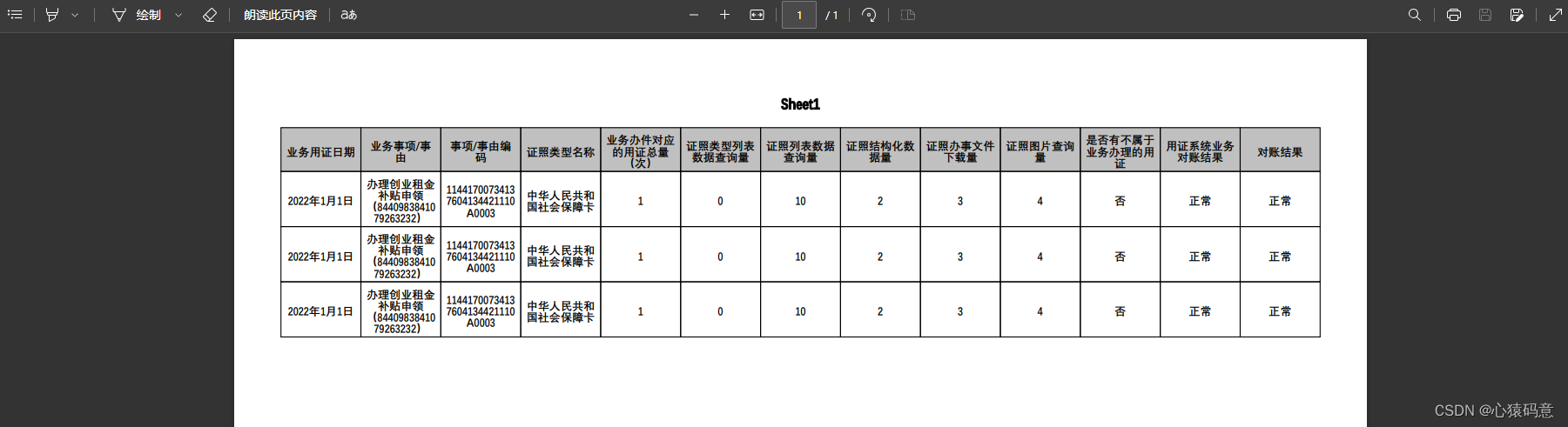
鉴于此,提出一种MATLAB环境下基于高斯滤波器-广义拉普拉斯算子的细胞核自动检测方法,算法运行环境为MAYLAB R2018A,压缩包=数据+代码+参考文献。
部分代码如下:
clc;clear all
addpath(genpath([pwd '\GeneralLoG']));IMData4SymmetricVoting_1={'8913.tif'};
%IMData4SymmetricVoting_1={'117_H&E_07_7.tif'};for i=1:length(IMData4SymmetricVoting_1)curIMName=IMData4SymmetricVoting_1{i};curIM=imread(curIMName);curIMsize=size(curIM);[curIM_norm] = normalizeStaining(curIM);curIM_normRed=curIM_norm(:,:,1);%% using general LoG,%%% initial segmentationR=curIM_normRed; I=curIM;ac=5; % remove isolated pixels(non-nuclei pixels)[Nmask,cs,rs,A3]=XNucleiSeg_GL_Thresholding(R,ac,I,1); %% thresholding based binarization
% show(Nmask); LshowBWonIM(Nmask,I);%%% gLoG seeds detectionlargeSigma=16;smallSigma=12; % Sigma valuens=XNucleiCenD_Clustering(R,Nmask,largeSigma,smallSigma); %% To detect nuclei clumpsfigure(1),imshow(I);hold on,plot(ns(2,:),ns(1,:),'y+');hold on,plot(cs,rs,'g*');
end出图如下:


工学博士,担任《Mechanical System and Signal Processing》审稿专家,担任
《中国电机工程学报》优秀审稿专家,《控制与决策》,《系统工程与电子技术》,《电力系统保护与控制》,《宇航学报》等EI期刊审稿专家。
擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。