源 | 量子位
编 | 泽南
ChatGPT的热度稍有平息,蛰伏已久的Meta就迅速放出“大招”:
一次性发布四种尺寸的大语言模型LLaMA:7B、13B、33B和65B,用小杯、中杯、大杯和超大杯来解释很形象了有木有(Doge)。
还声称,效果好过GPT,偏向性更低,更重要的是所有尺寸均开源,甚至13B的LLaMA在单个GPU上就能运行。
消息一出,直接在网上掀起一阵热度,不到一天时间,相关推文的浏览量就已经快破百万。

同在Meta的LeCun当然也得为这次大模型的热度“添油加柴”,LLaMA直接给他写了段“AI”Rap:
We gotta think about the future, it’s gonna be here soon
Maybe we can even put some AI in the moon
Think about the children, think about the next generation
Let’s make sure we put the right systems in their foundation
(不得不说效果不错,还双押了,skr~)

不过话说回来,这次Meta的LLaMA模型到底如何?
一起来一探究竟。
数学编程写求职信统统都能拿下
Meta发布的LLaMA是通用大语言模型,原理就不多赘述,和以往的大语言模型一样:
将一系列单词作为输入,并预测下一个单词以递归生成文本。
这次,Meta之所以一次给出不同大小的LLaMA模型,论文中给出了这样的解释:
近来的研究表明,对于给定的计算预算,最佳性能不是由最大的模型实现的,而是由基于更多数据训练的更小的模型实现的。

也就是说,较小的模型规模加上比较大的数据集,获得的性能可能会比更大规模模型的要好很多。
一方面,小规模模型需要的计算能力和资源相对来说都会少很多,另一方面,它还能基于更多数据集训练更多token,更容易针对特定的潜在产品用例进行重新训练和微调。
除了一把给出四种尺寸的LLaMA,Meta这次还直接开源了这个大语言模型。
更重要的是,Meta为了让自己的工作与开源兼容,使用的都是公开的数据。

而这把开源,也不只利好开发人员,同样也利好Meta。
LLaMA模型也有着其他大语言模型的通病:会产生偏见性、有毒或者虚假的内容。开源吸引来的更多的研究可以帮助解决这个问题。
不过讲了这么多,Meta的这个LLaMA模型到底能做啥?
扎克伯格直接在Facebook放出豪言,这是AI大语言模型里的新SOTA:
生成文本、进行对话、总结书面材料以及解决数学定理或预测蛋白质结构等它都能干。

论文的最后也给出了一些栗子 :
:
比如说,给出几个数字,它直接就能找出其中的规律并续写,还balabala解释了一大通。

ChatGPT之前擅长写的求职信LLaMA也能轻松拿下。

编程、写小说也是分分钟的事儿:


效果超越GPT-3
当然按照惯例,在最后LLaMA还是得和其他大模型做做比较(是骡子是马,咱得拉出来遛遛)。
其中,大家比较熟悉的就是GPT-3,直接看看它们俩之间的效果比较:
相较于有1750亿参数的GPT-3,最多只有650亿参数LLaMA赢麻了:它在大多数基准上都要优于GPT-3。
比如说常识推理:

或者说一些基础问题的解决:

又比如说阅读理解:

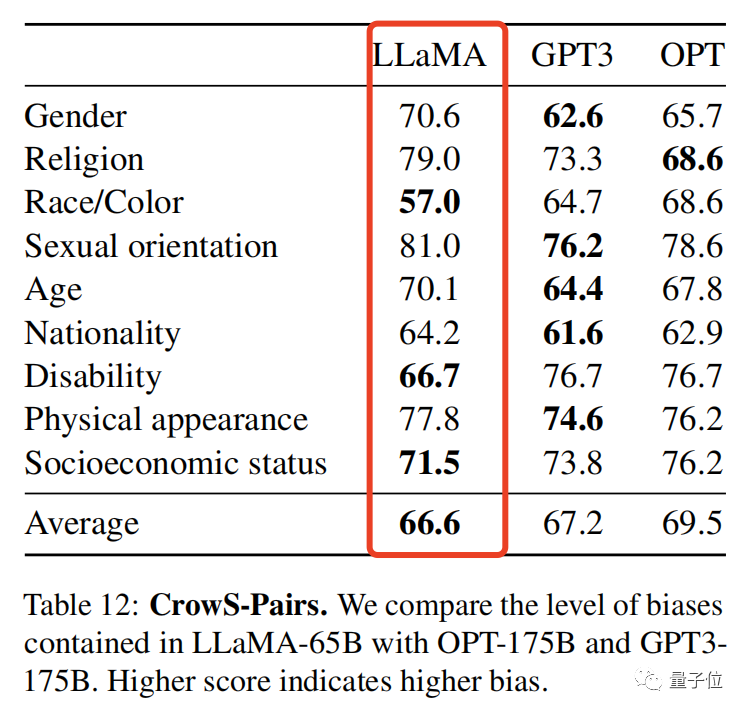
甚至,研究人员还提供了一组评估模型偏见性和毒性的基准,得分越高,偏见就越大:
LLaMA以66.6分险胜,偏见性略低于GPT-3。
你对Meta这次的LLaMA怎么看呢?如果还想了解更多可以戳文末链接~
论文地址:
https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
参考链接:
[1] https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
[2] https://twitter.com/GuillaumeLample/status/1629151231800115202
[3] https://twitter.com/ylecun/status/1629243179068268548