利用excel文件增量同步一个库的数据并自动校正两端数据库条数不一致
现在有sqlserver和mysql两个库上的表在进行同步,sqlserver上的是源表,mysql上是目标表。
我们就把sqlserver上的数据同步到mysql上
mysql 是没有数据的。
sqlserver的三个表只是创建了表,没有数据的
1. 获取excel需要同步的表名(读取excel文件)
先创建一个excel内容格式如下:
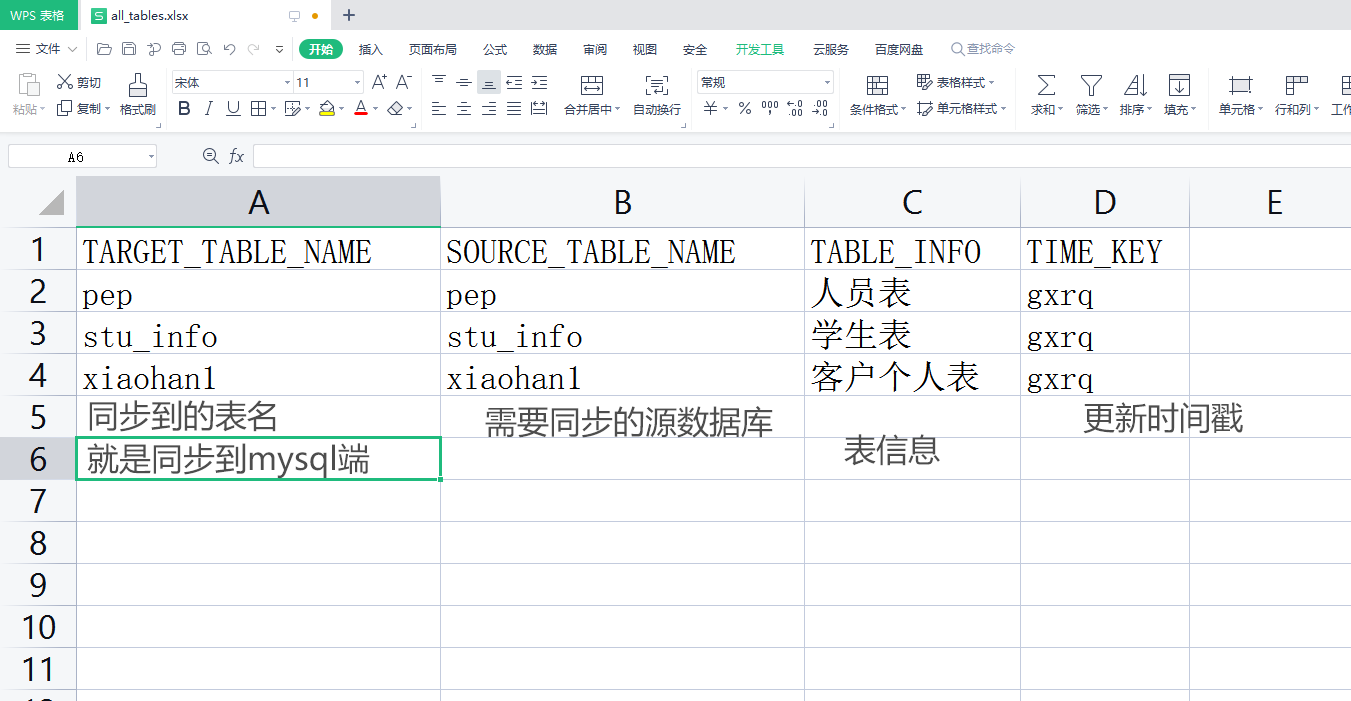
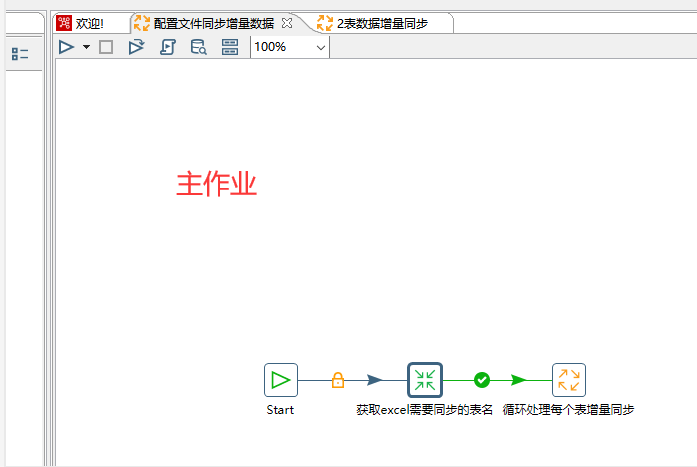
保存好后,新建一个作业文件命名为"配置文件同步增量数据",在这个作业文件里创建一个转换控件命名为"获取excel里需要同步的表名",用来获取excel里需要同步的表信息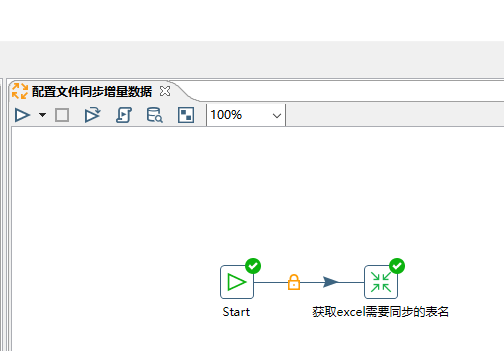
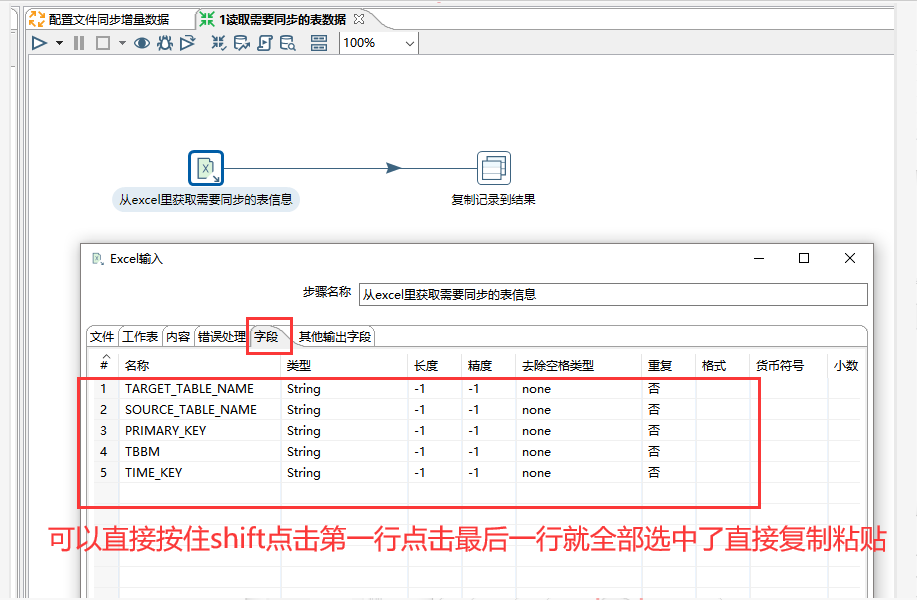
接着创建一个转换文件命名为"1.读取需要同步的表数据",在这个转换文件里创建一个Excel输入控件和一个 复制记录到结果 控件 。excel输入的表格类型选择"Excel 2007 XLSX (Apache POI)"
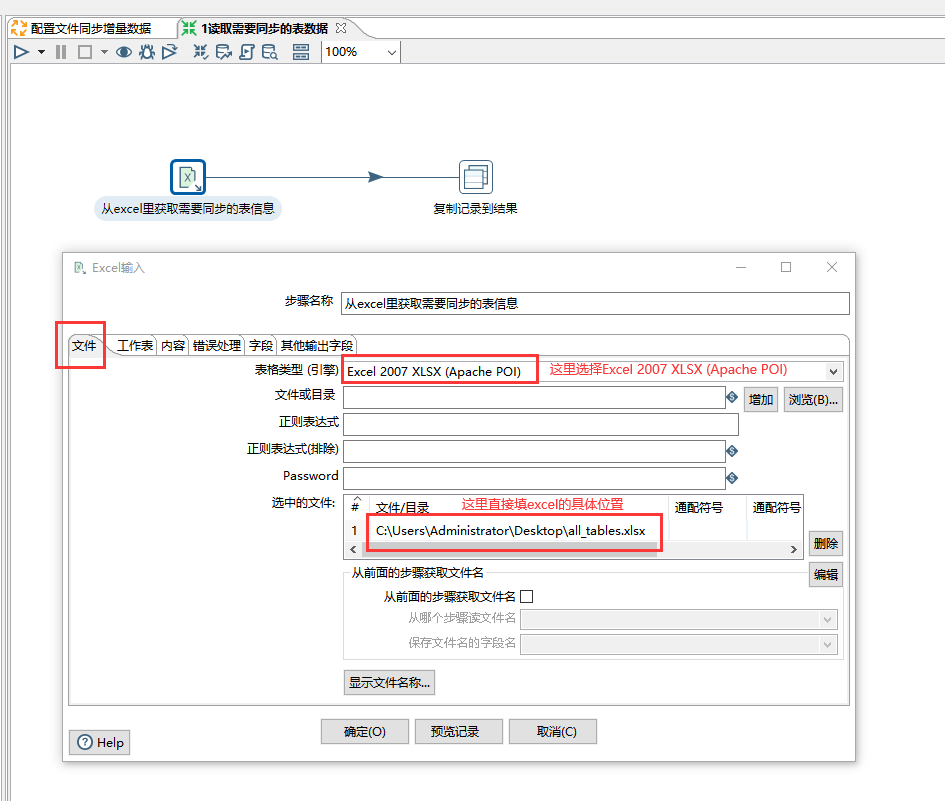
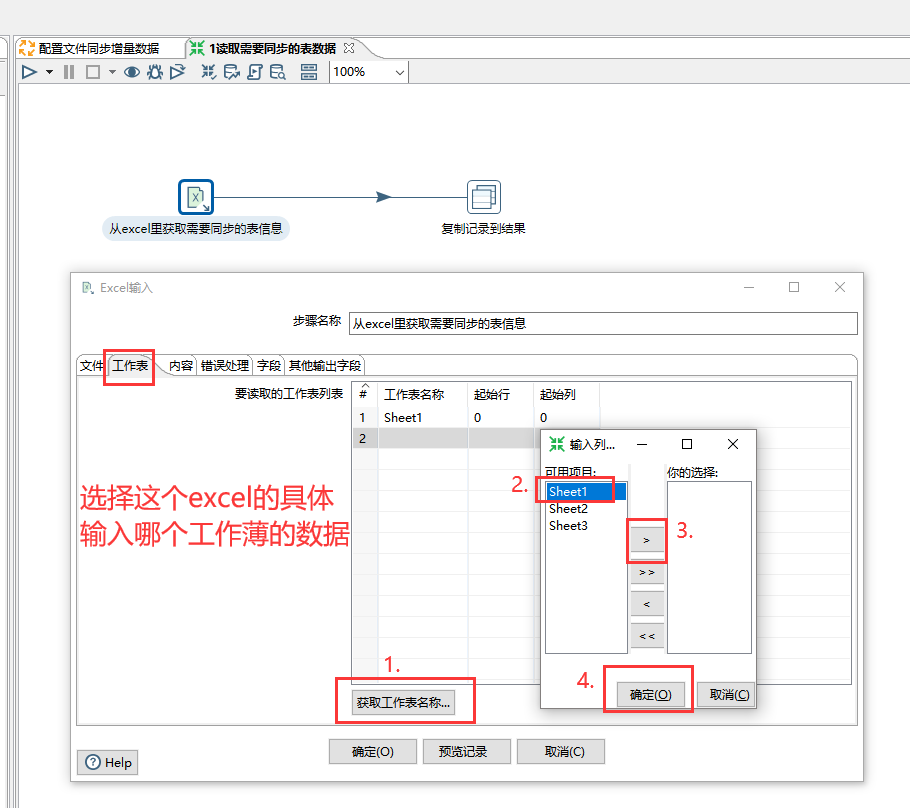
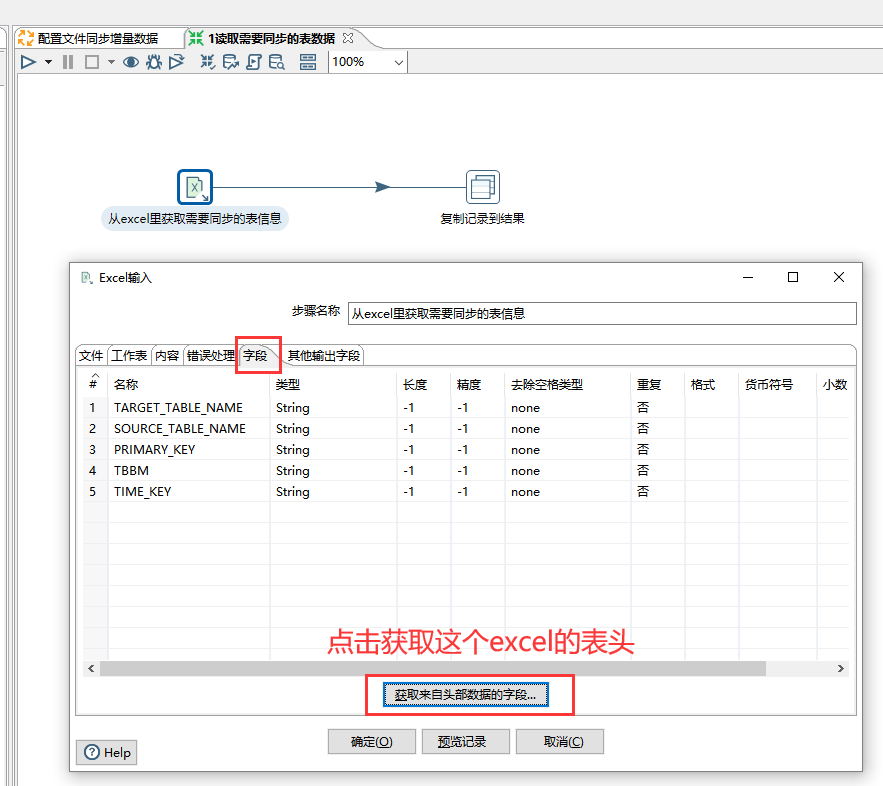
将名为"1.读取需要同步的表数据"的转换文件保存后,回到名为"配置文件同步增量数据"的作业文件里选择名为"获取excel里需要同步的表名"的转换控件的具体路径
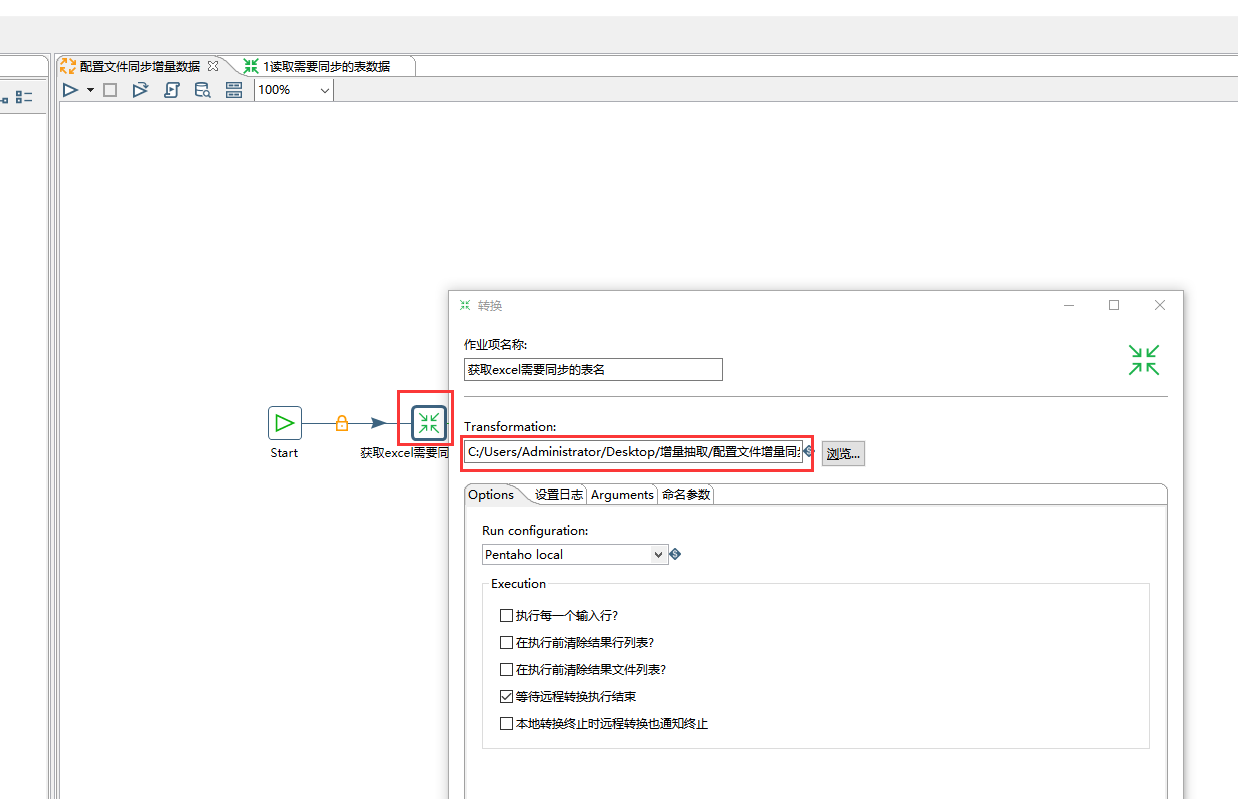
2. 循环处理每个表的增量数据同步
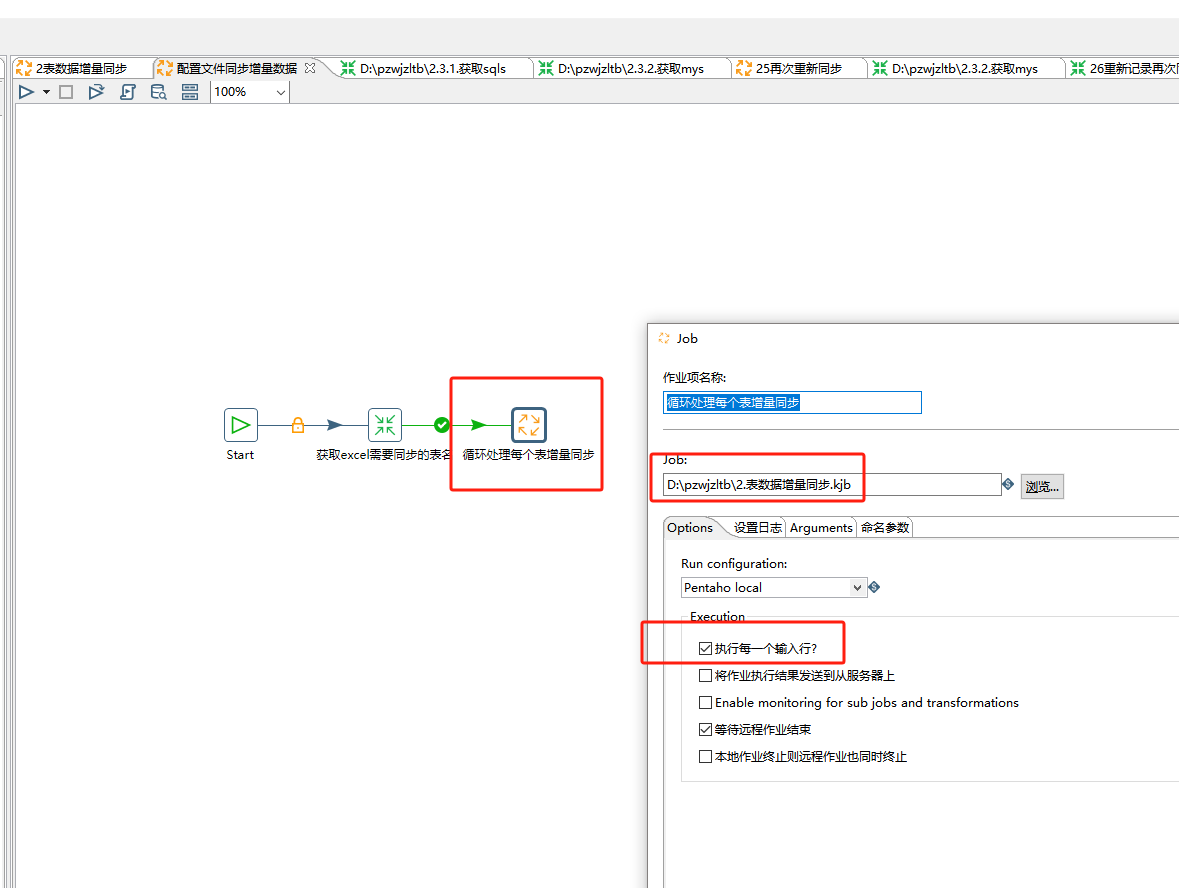
在名为"配置文件同步增量数据"的作业文件里再创建一个作业控件命名为"循环处理每个表增量同步"
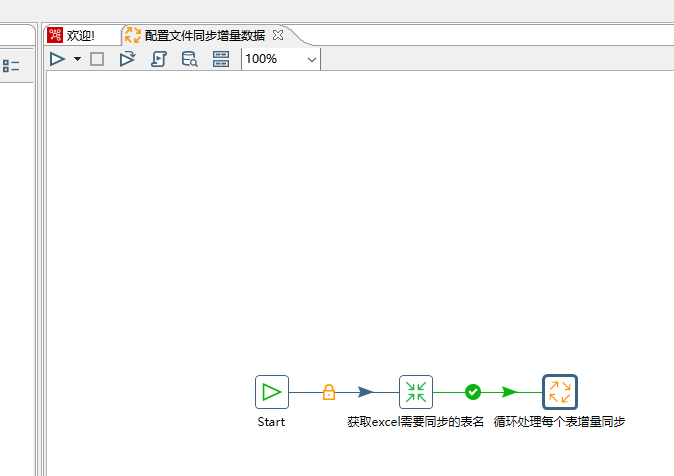
然后我们就需要新建一个作业文件了,因为一个转换控件对应一个转换文件,一个作业控件对应一个作业文件。
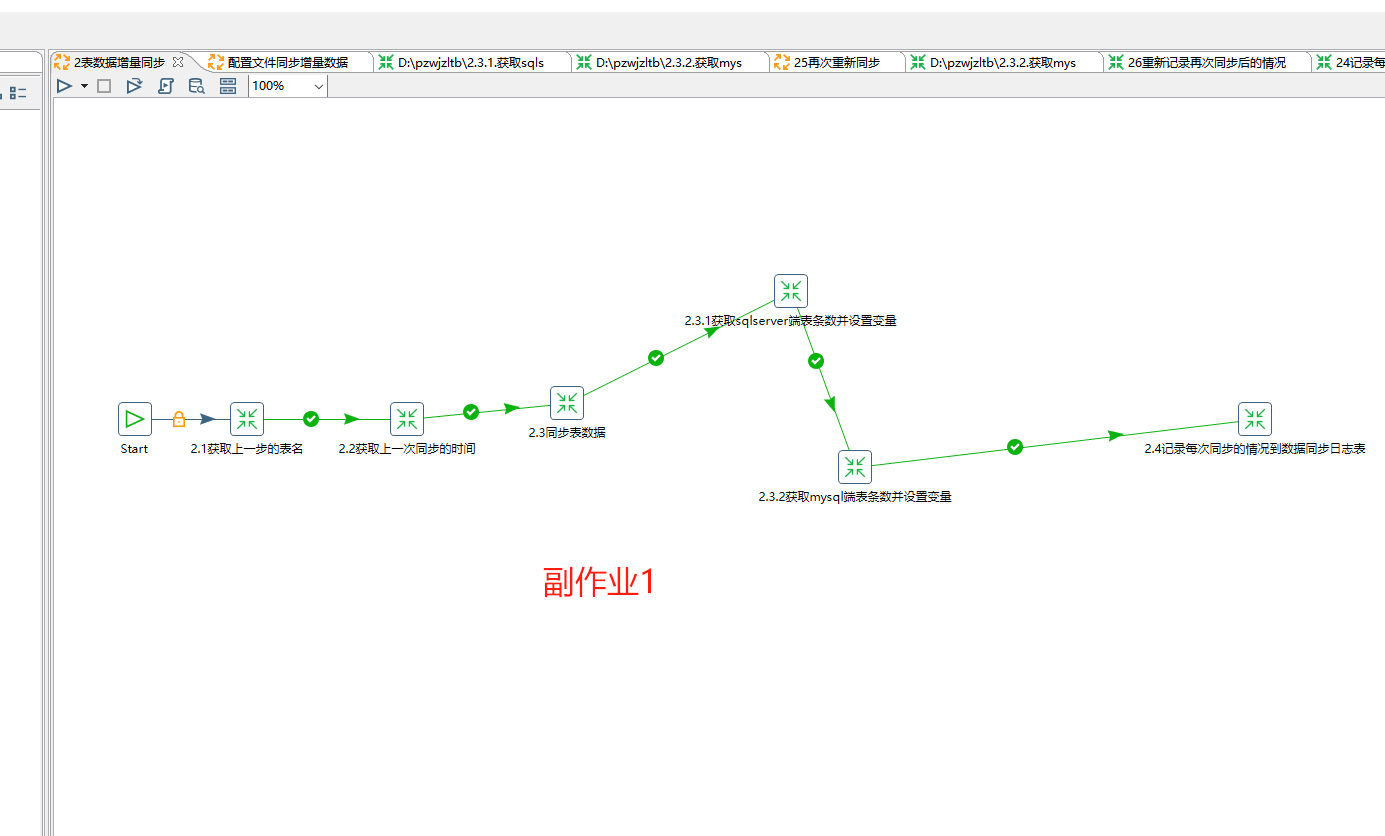
这个作业控件我们可以命名为 “2.表数据增量同步”,内容如下6个步骤:
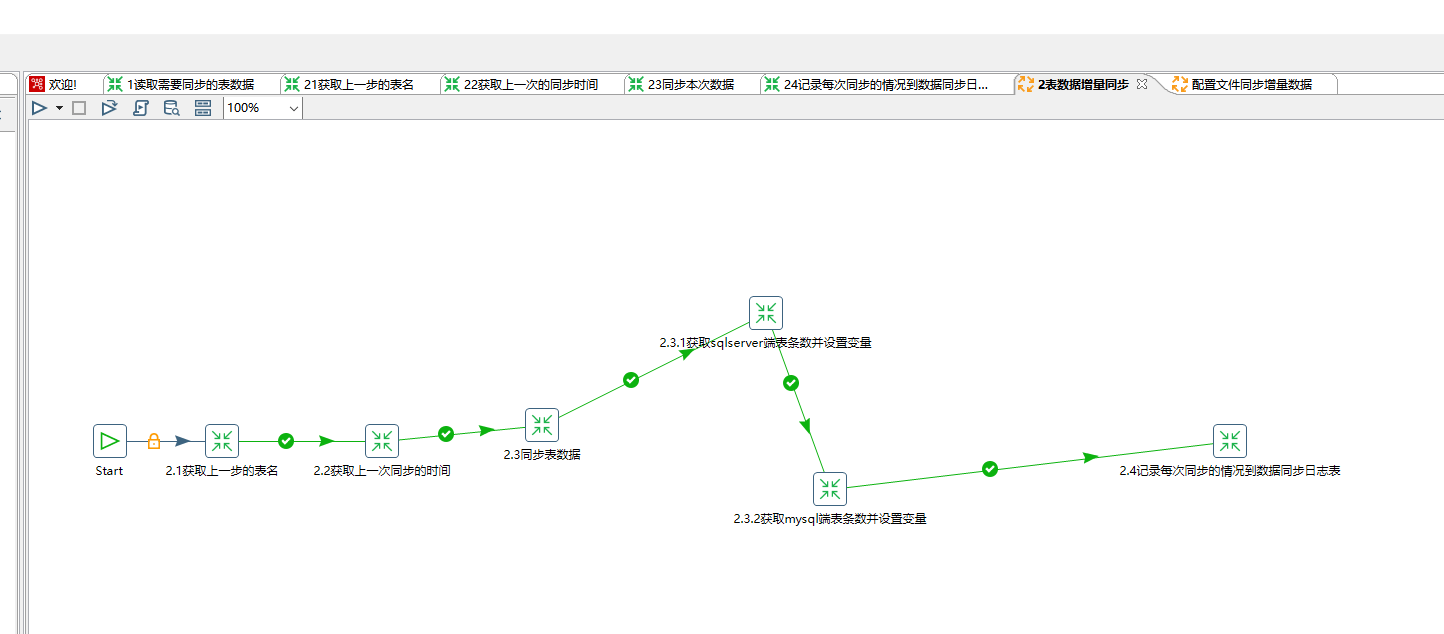
在2.1获取上一步的表名这个对应的文件里:
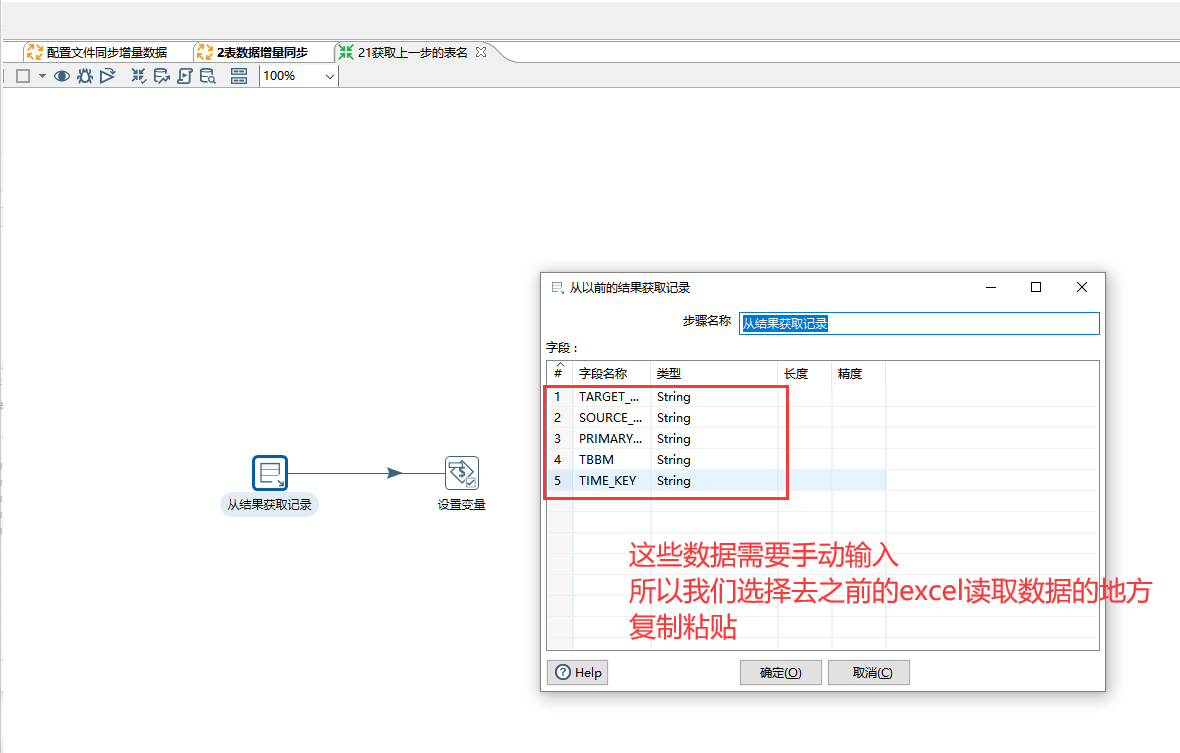
这个从结果获取记录需要我们去之前的excel输入控件里去复制粘贴,
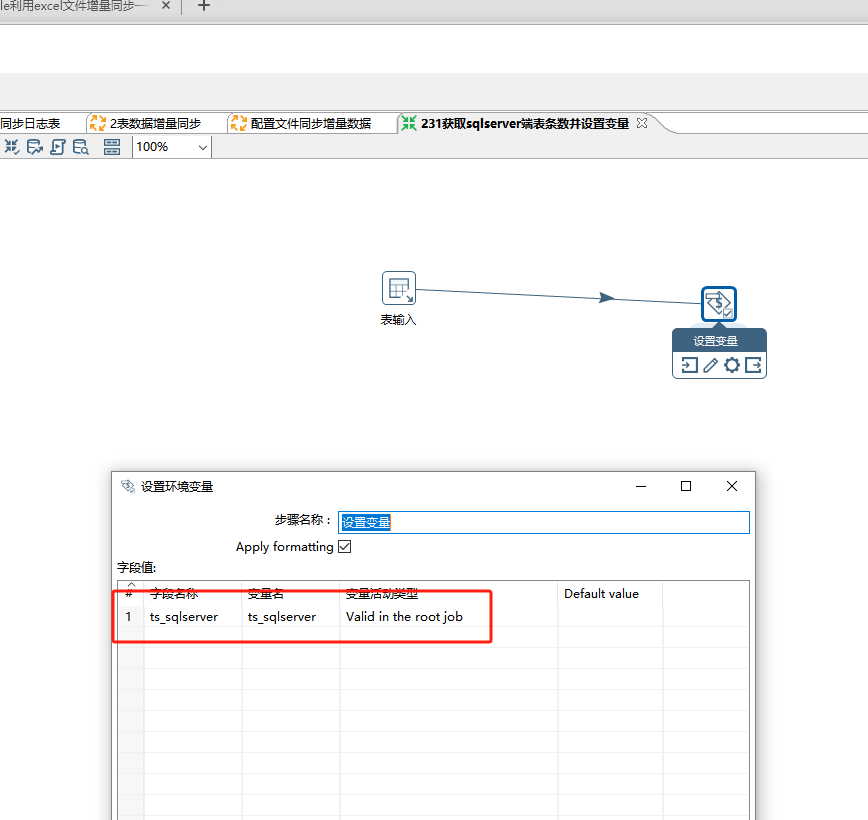
这个设置变量可以直接点获取字段
在2.2获取上一次同步的时间这个对应的文件里:
---查询目标库上对应表在数据同步记录这张表上的最近一次同步日期
---这里是mysql的写法,其他数据库的写法照着改
---之前从excel输入控件里读取后就把记录复制到结果里了,excel的表头就成为了变量
SELECT IFNULL(MAX(TBSJ),'1990-01-01') AS TBSJ FROM SYSTEM_SJTBJL A
WHERE TABLE_NAME='${TARGET_TABLE_NAME}' AND BCSLSFYZ='Y'
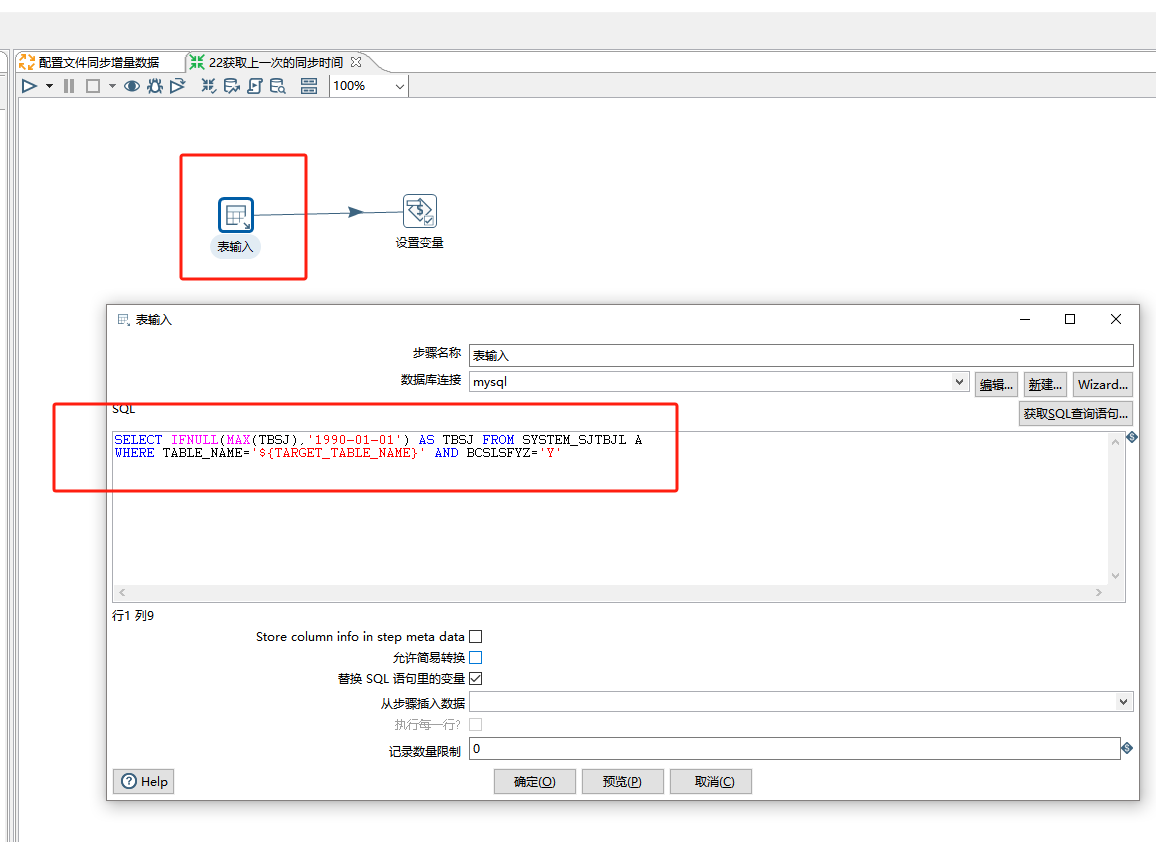
然后把查出来的每个表的对应的最新同步时间设置为变量。
在2.3同步表数据这个对应的文件里:
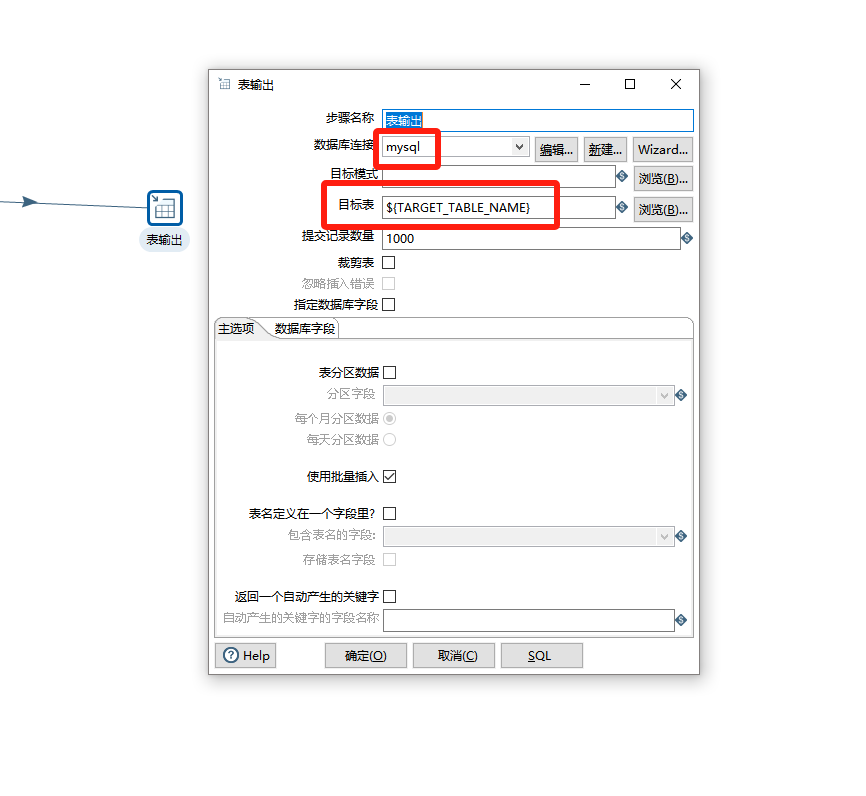
有一个表输入和表输出,我们不用更新插入的方式。因为更新插入的方式需要获取具体的表字段写死,每个表都不一样,所以我们使用表输入和表输出来同步。
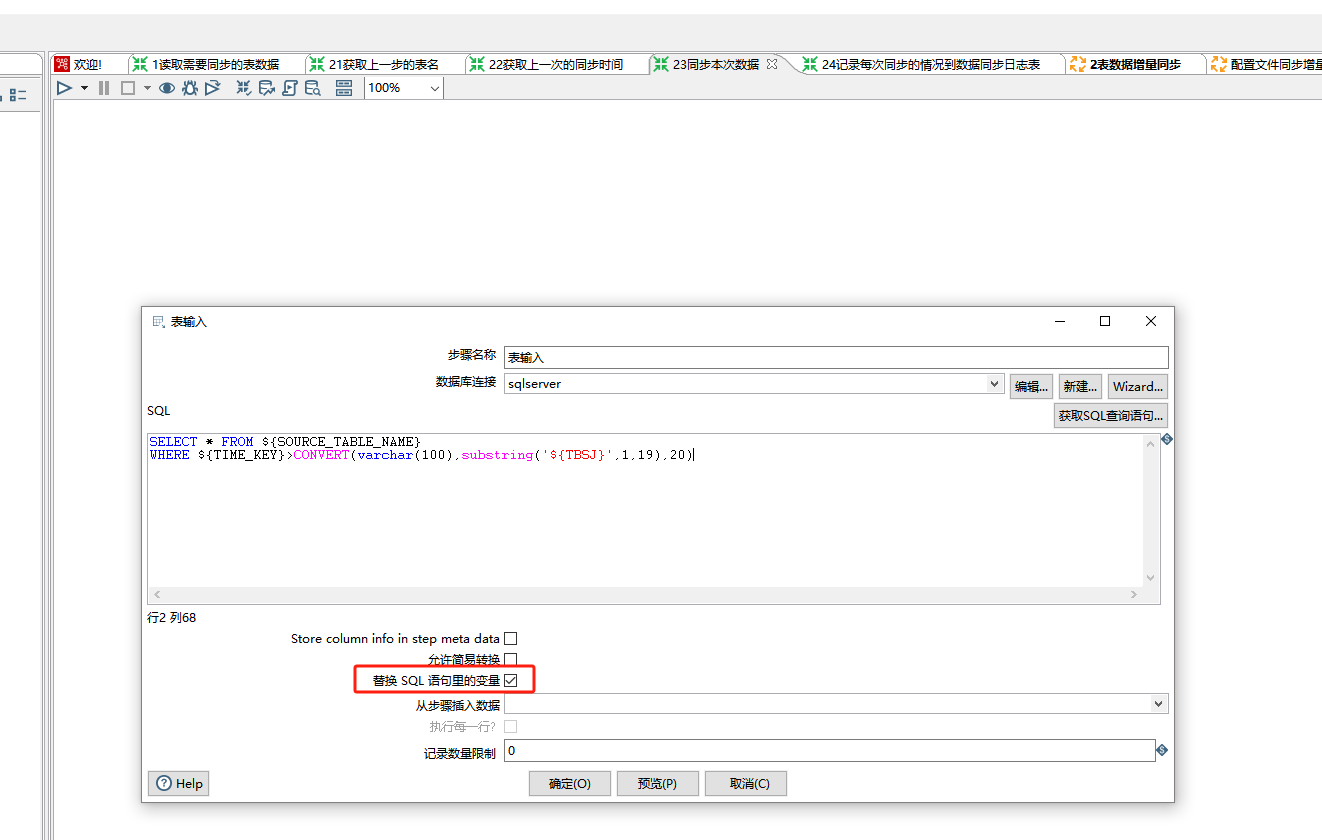
---表输入:(这是sqlserver的语法)
---查出源表里更新日期大于目标表的最新一次同步时间的数据
SELECT * FROM ${SOURCE_TABLE_NAME}
WHERE ${TIME_KEY}>CONVERT(varchar(100),substring('${TBSJ}',1,19),20)
在2.3.1获取sqlserver端表条数并设置变量里
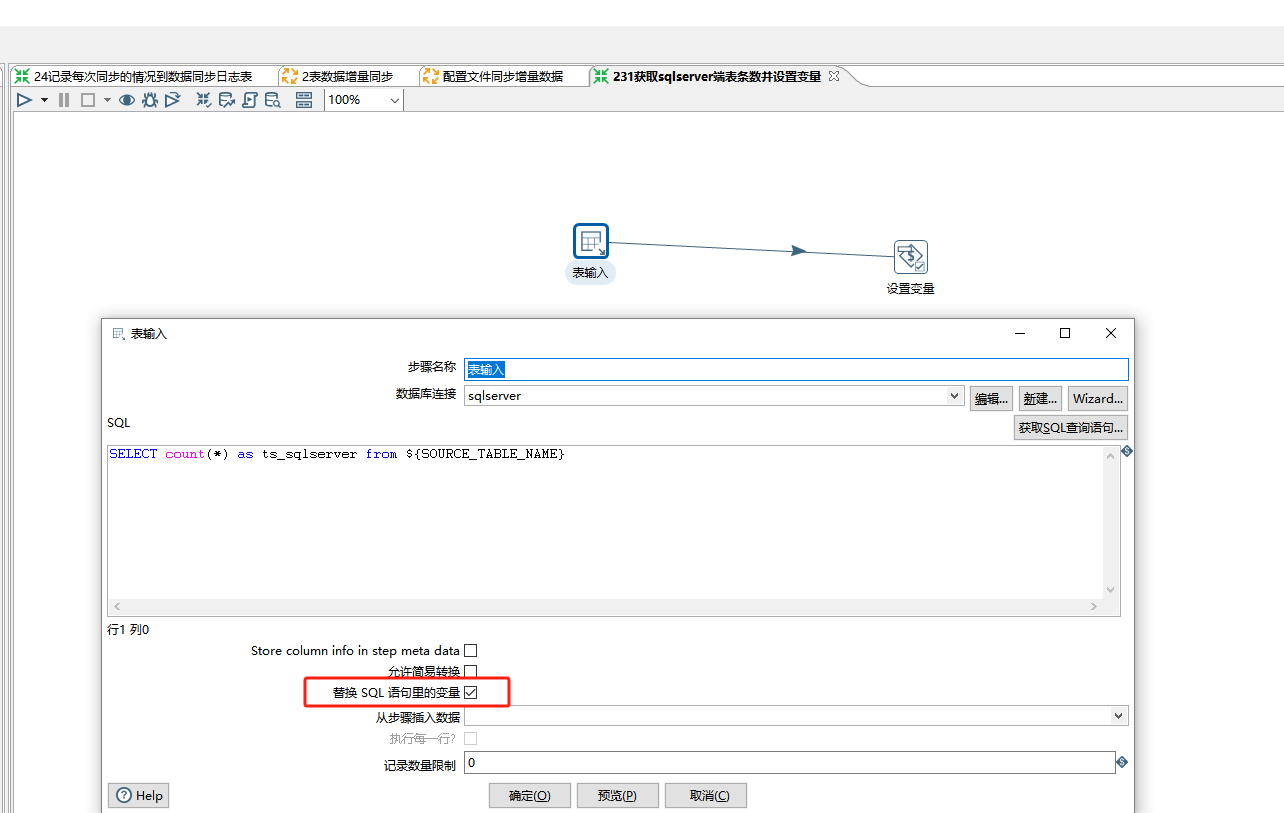
count下sqlserver对应的表的条数设置变量
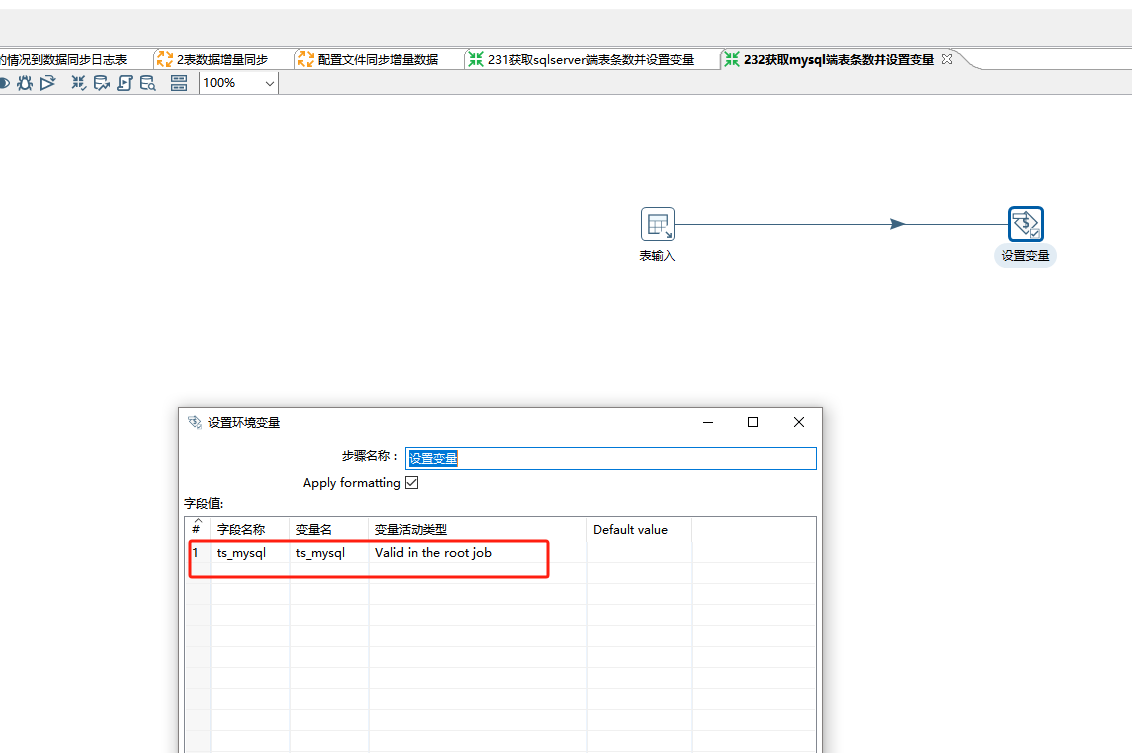
在2.3.2.获取mysql端表条数并设置变量里
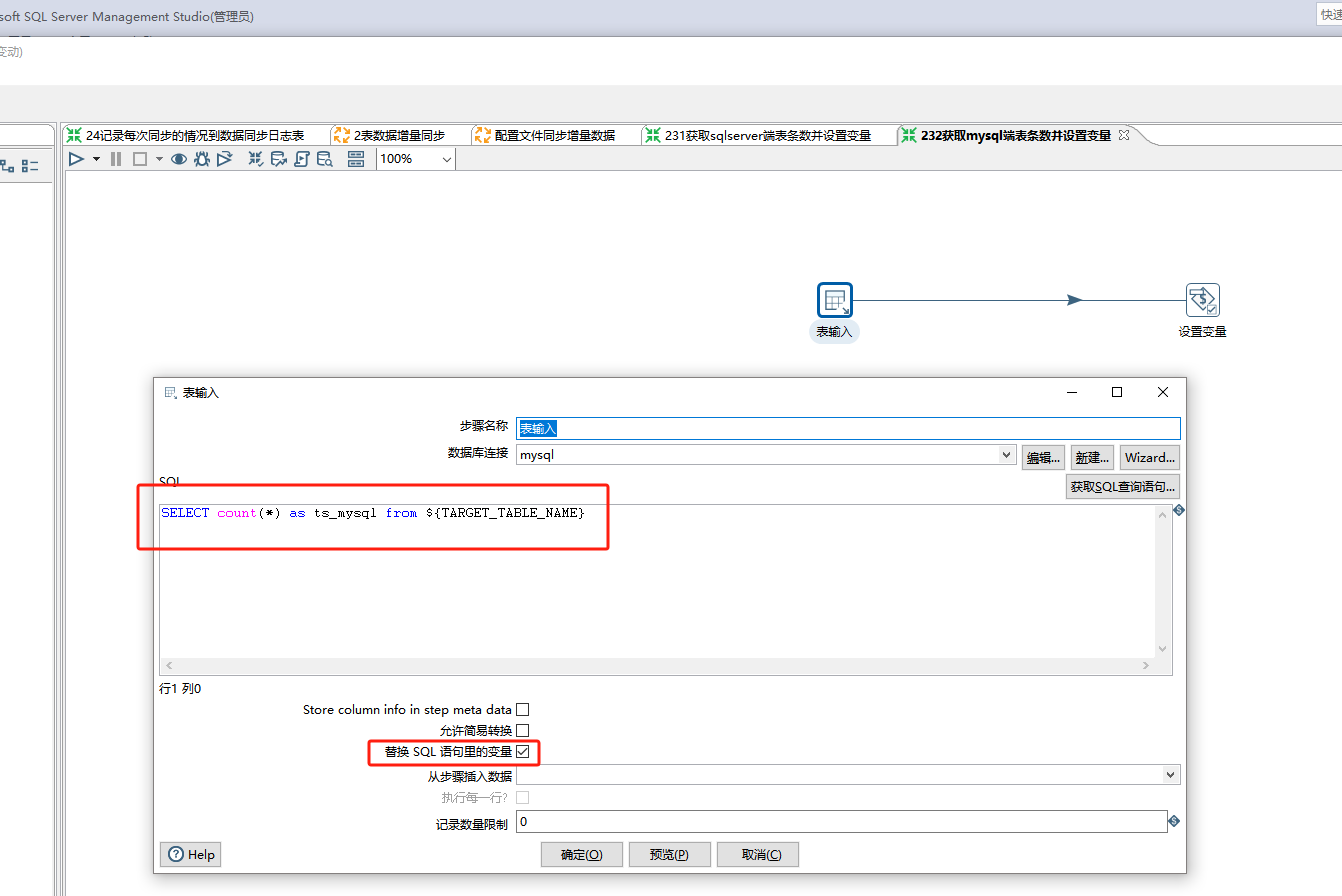
count下mysql同步后对应的表的条数设置变量
在2.4记录每次同步的情况到数据同步日志表 这个对应的文件里:
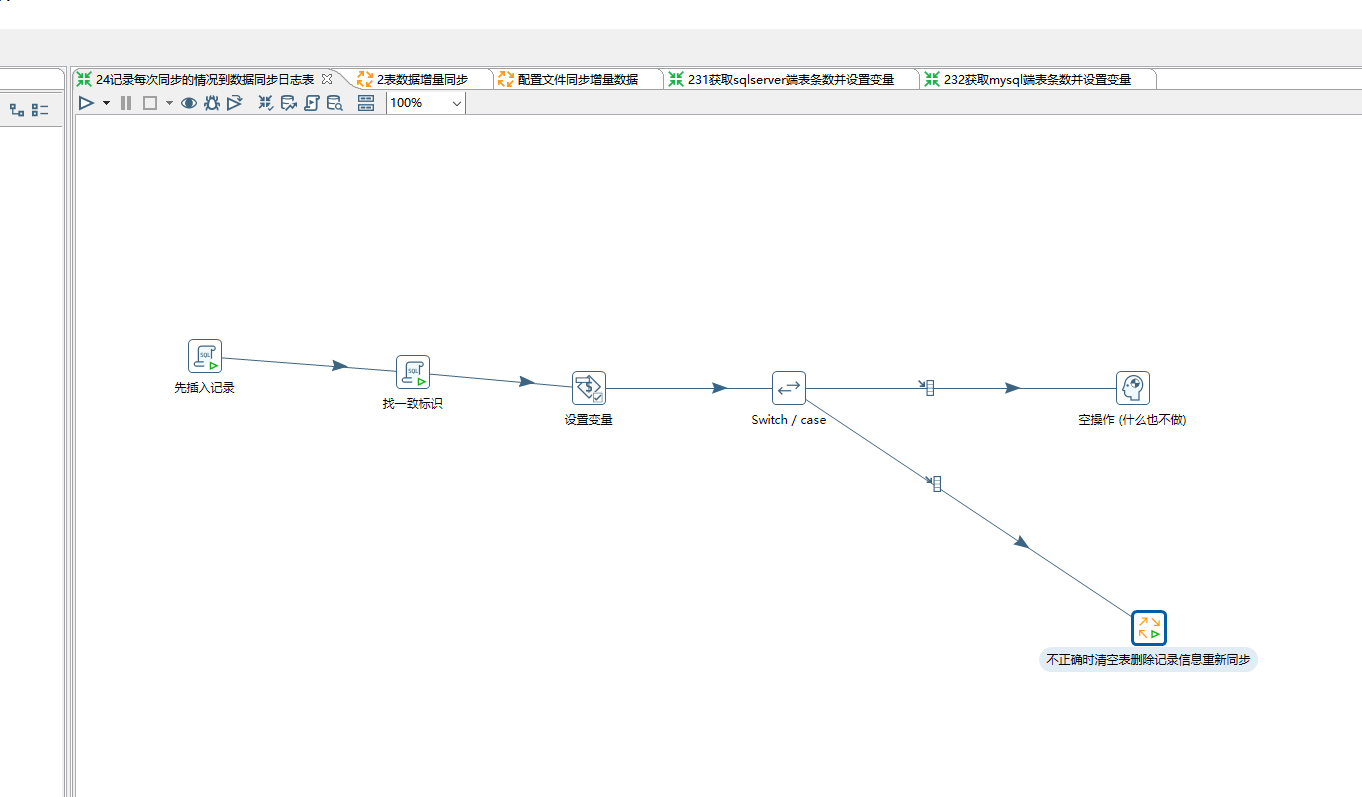
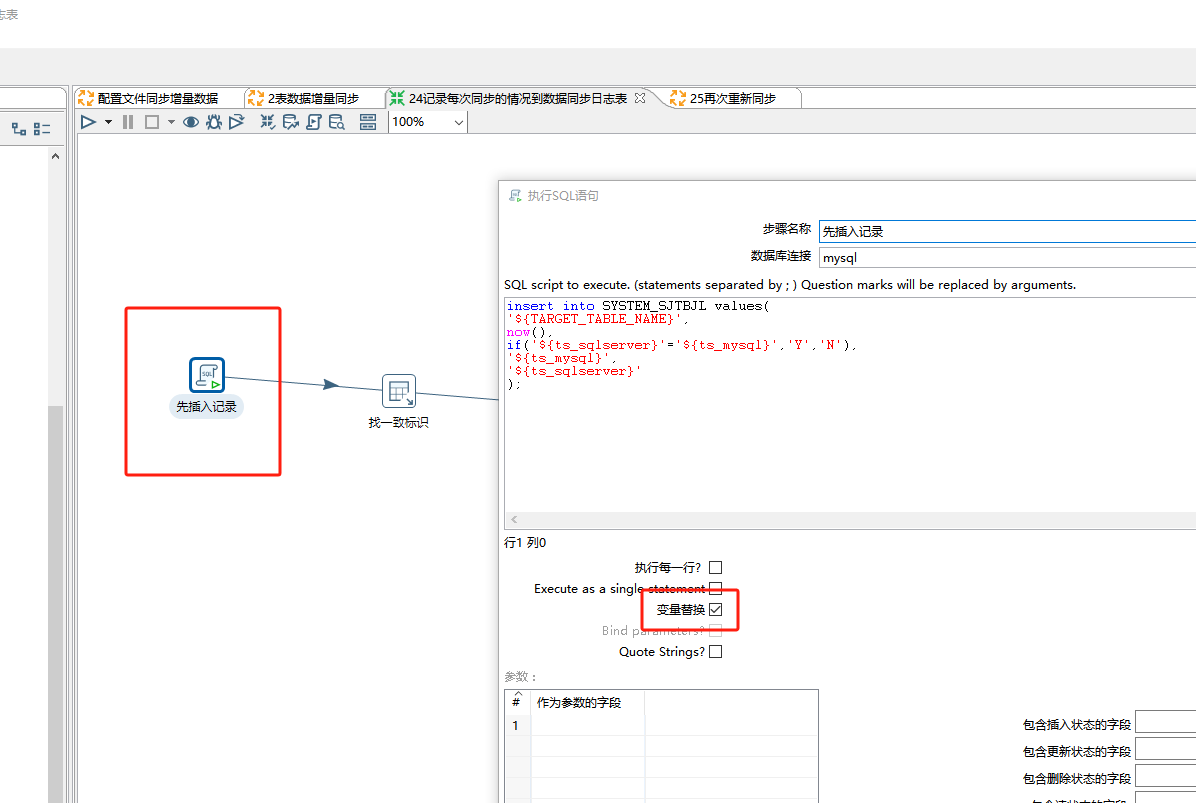
这个转换里我们先把刚同步的记录写进SYSTEM_SJTBJL里,两端的数据表条数一不一致都不重要,我们只需要记录刚才同步表时的信息,一致为Y,不一致为N:
insert into SYSTEM_SJTBJL values(
'${TARGET_TABLE_NAME}',
now(),
if('${ts_sqlserver}'='${ts_mysql}','Y','N'),
'${ts_mysql}',
'${ts_sqlserver}'
);
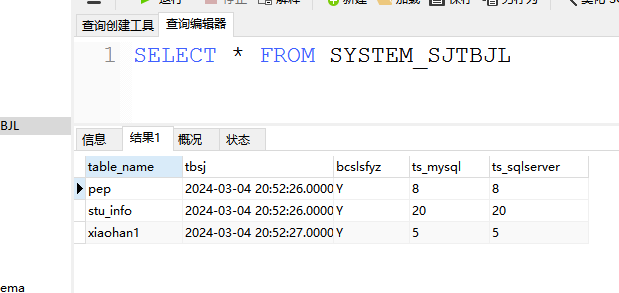
插入了同步信息日志后,我们进到SYSTEM_SJTBJL里找此次同步表的最新一条同步记录的同步时间对应的bcslsfyz本次数量是否一致 的内容:
with t1 as(
select max(tbsj) sj
from SYSTEM_SJTBJL where table_name='${TARGET_TABLE_NAME}')select bcslsfyz from SYSTEM_SJTBJL a,t1 b
where table_name='${TARGET_TABLE_NAME}' and a.tbsj=b.sj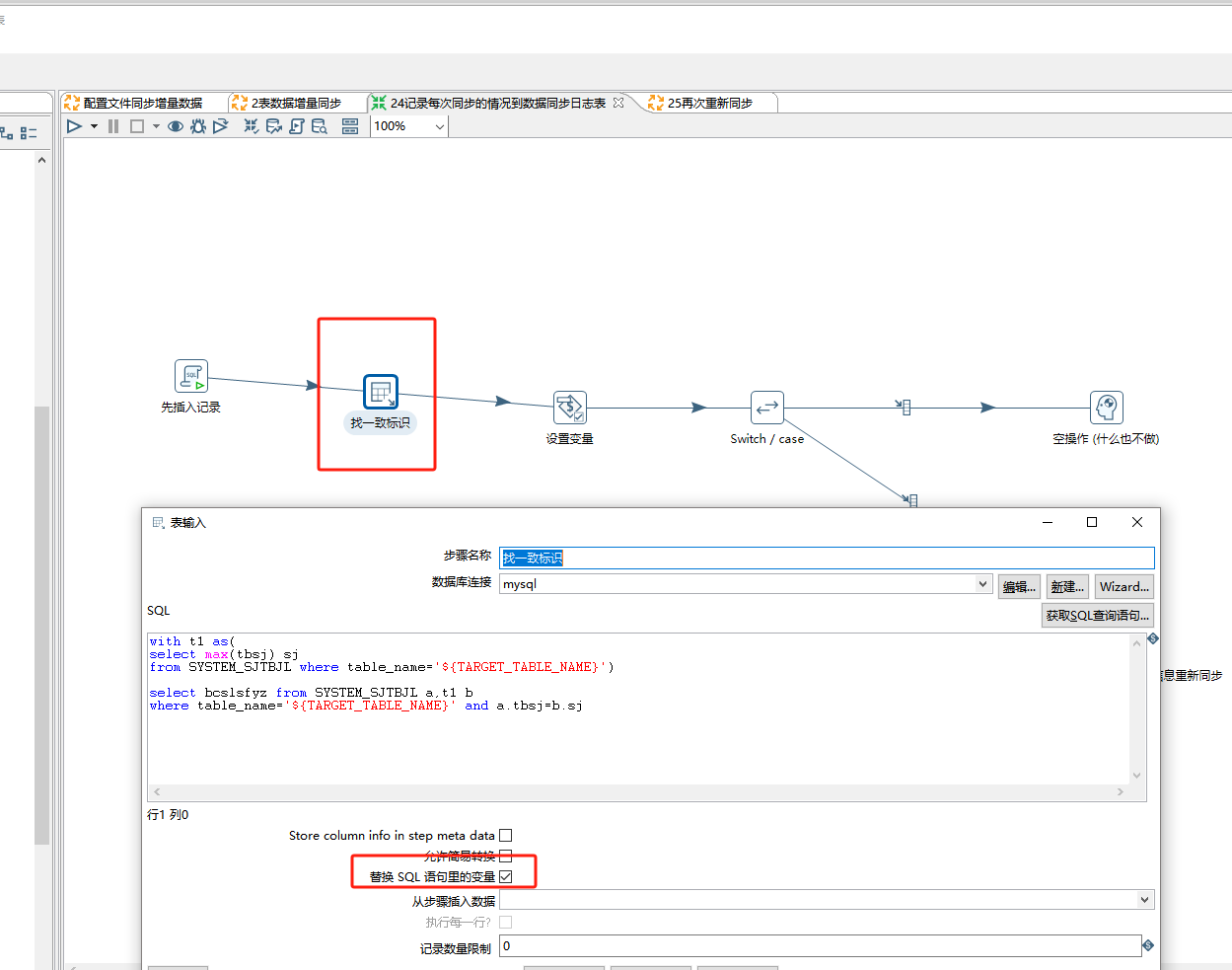
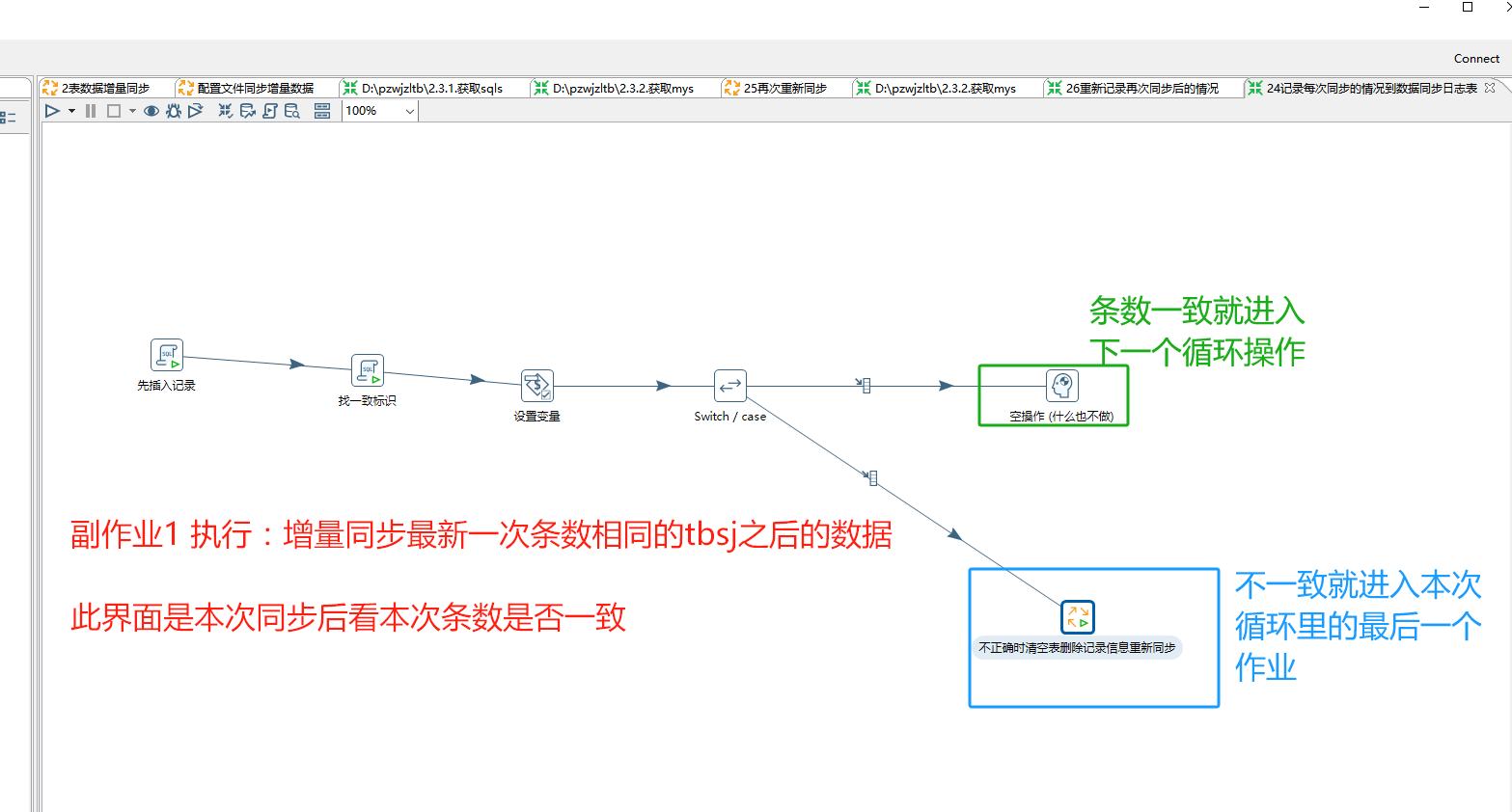
接下来找到后我们把它bcslsfyz设置成一个变量,让它bcslsfyz可以被switch控件使用:
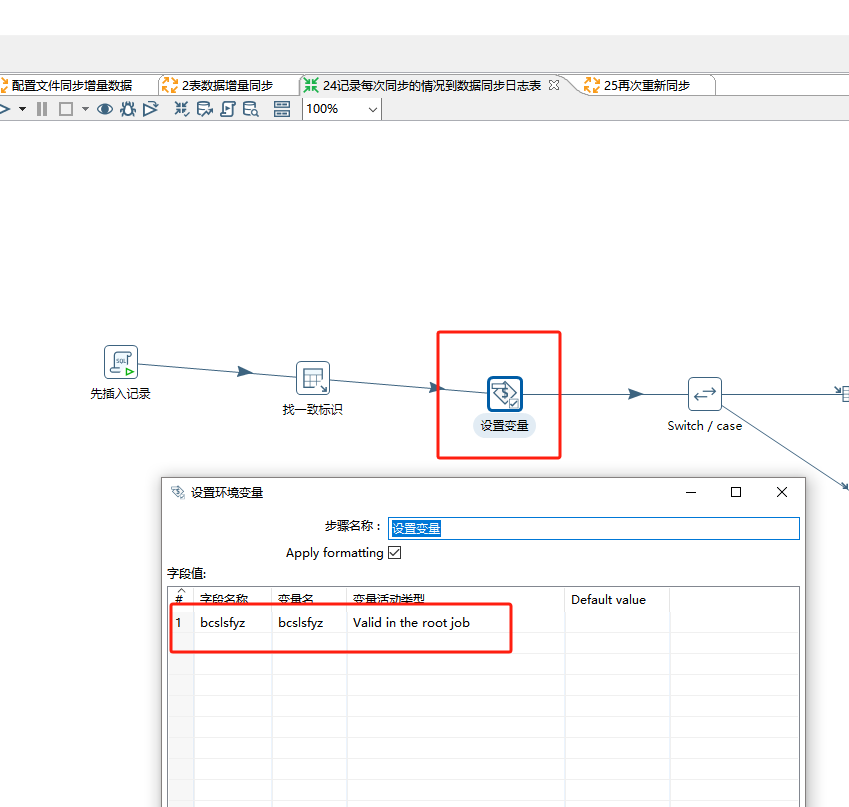
在switch控件里:
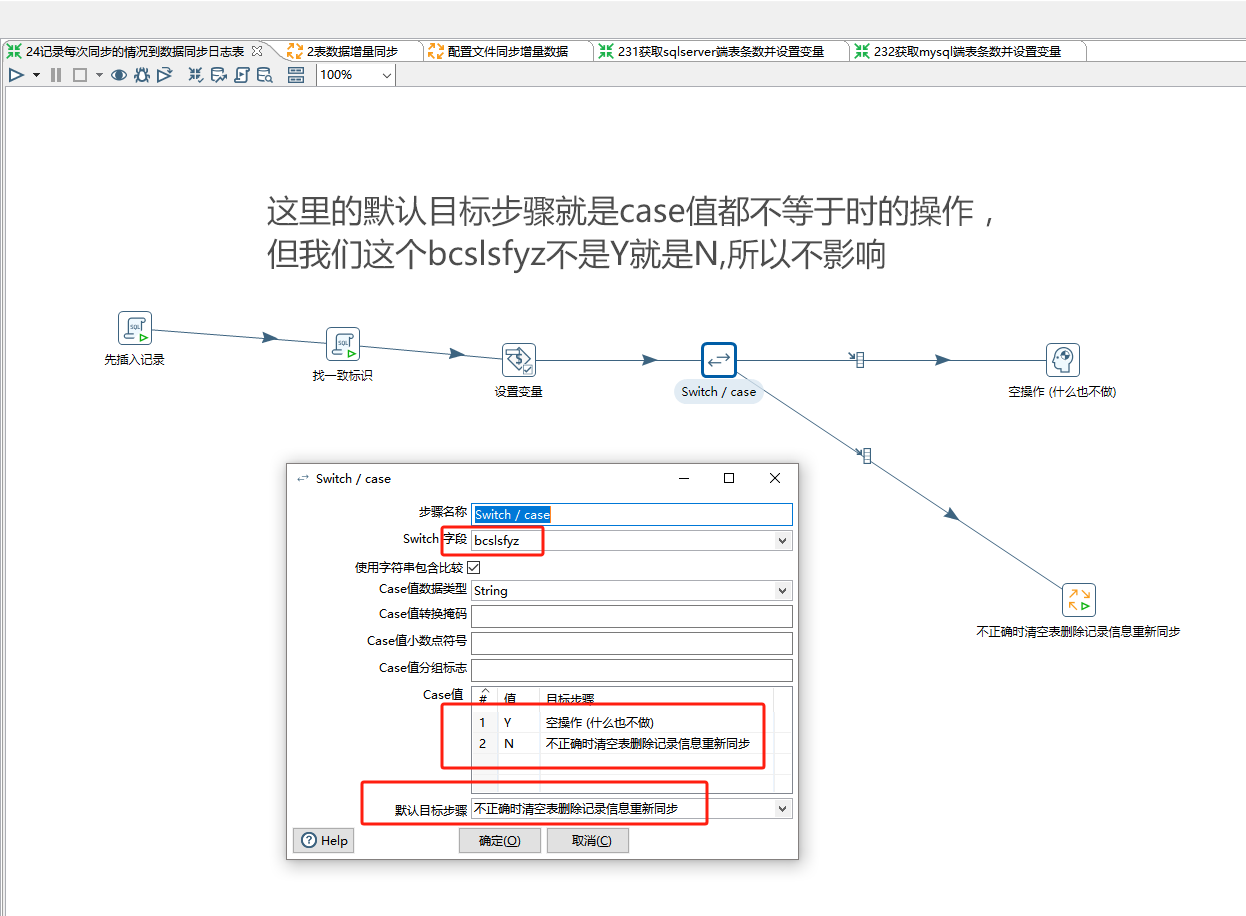
不正确时清空表删除记录信息重新同步
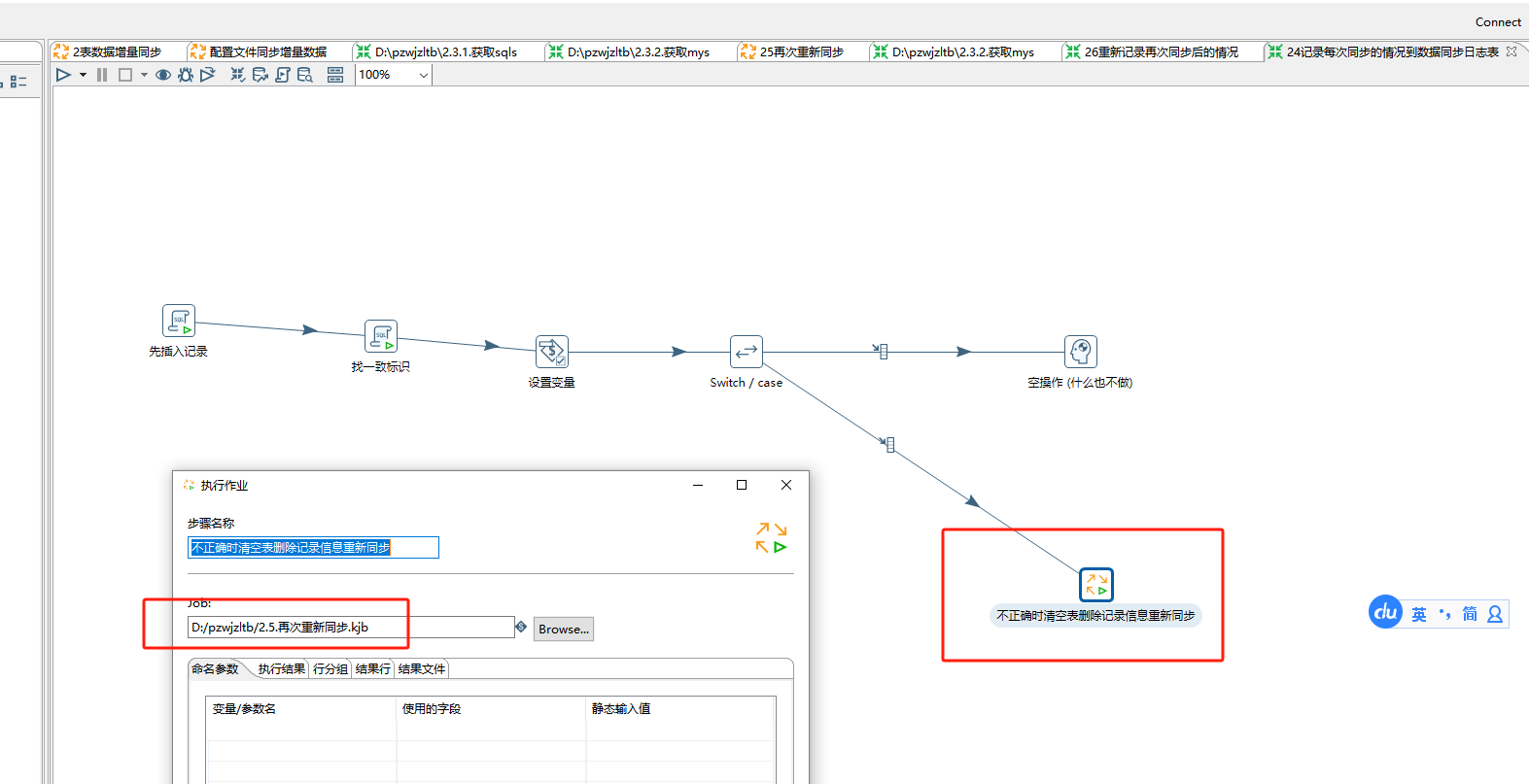
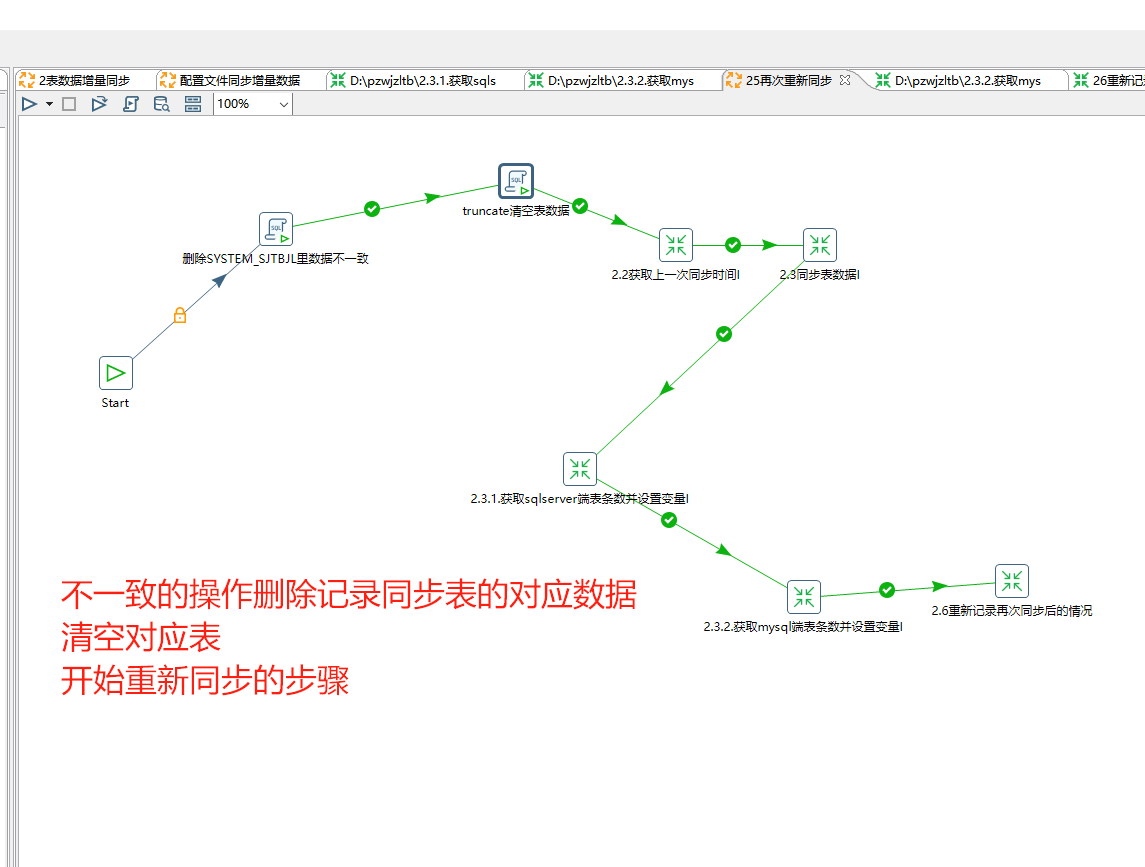
在上面不正确时的操作接下来需要清空表 删除记录 然后重新同步:
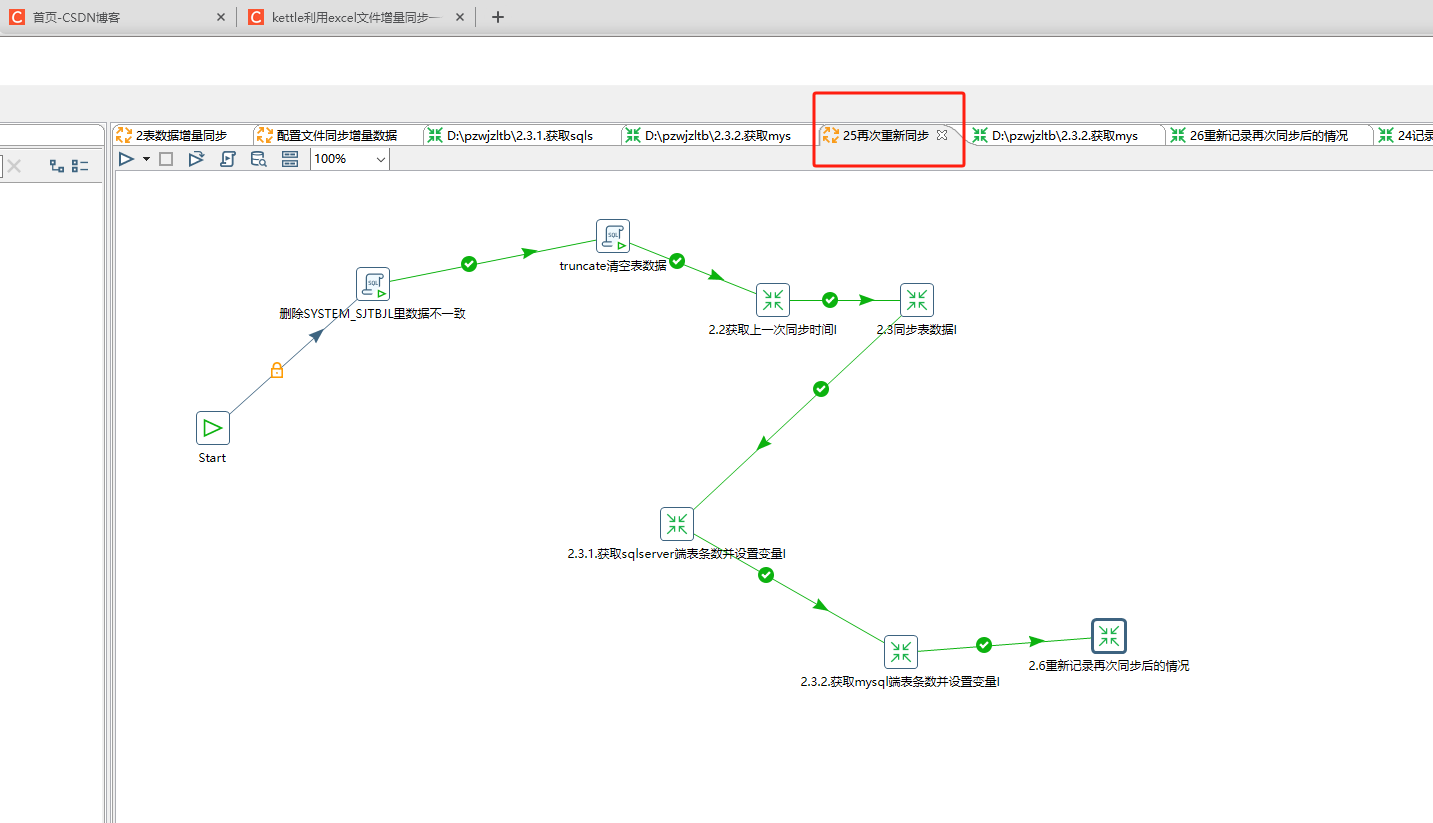
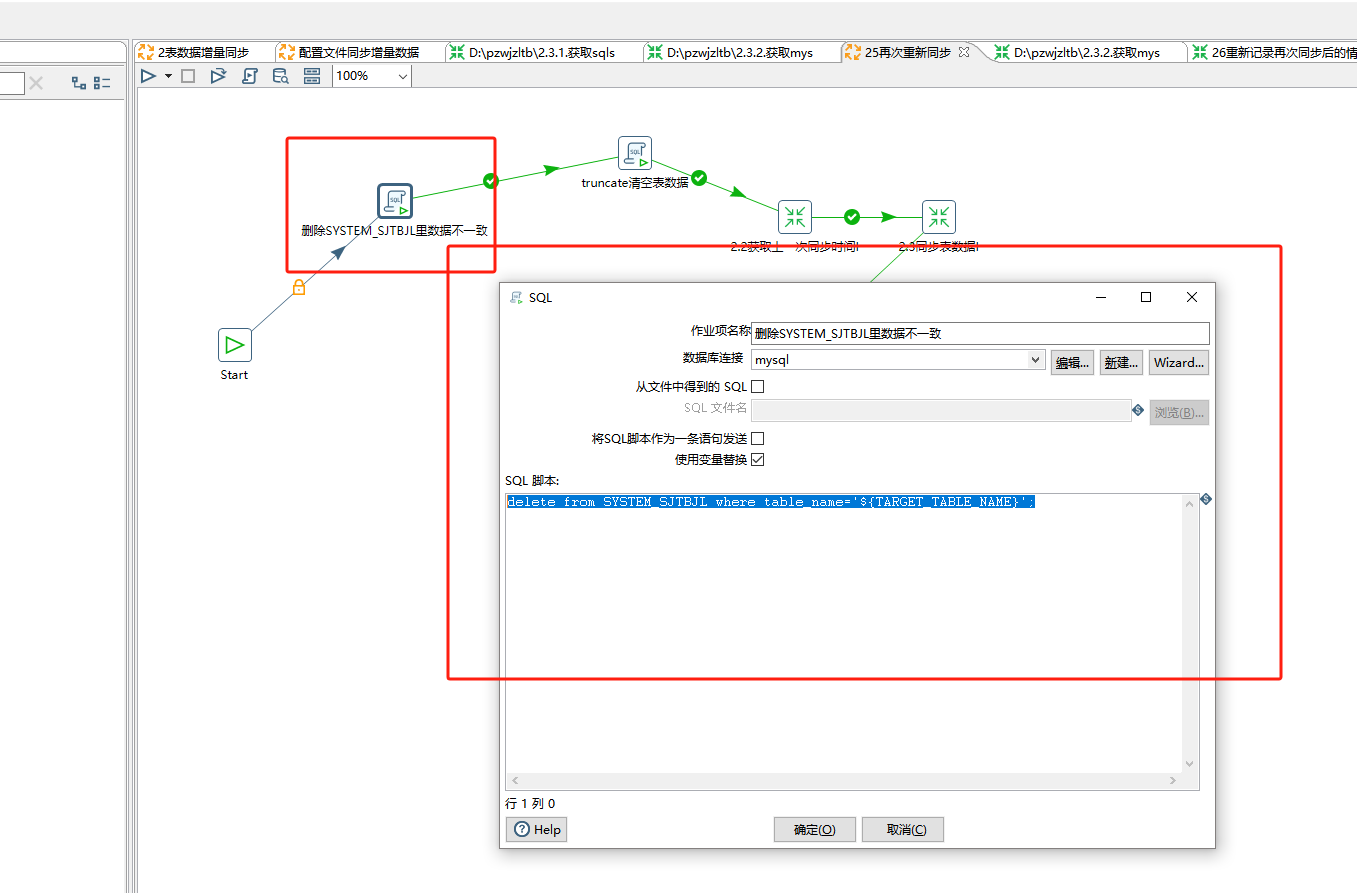
删除SYSTEM_SJTBJL里数据不一致:
delete from SYSTEM_SJTBJL where table_name='${TARGET_TABLE_NAME}';
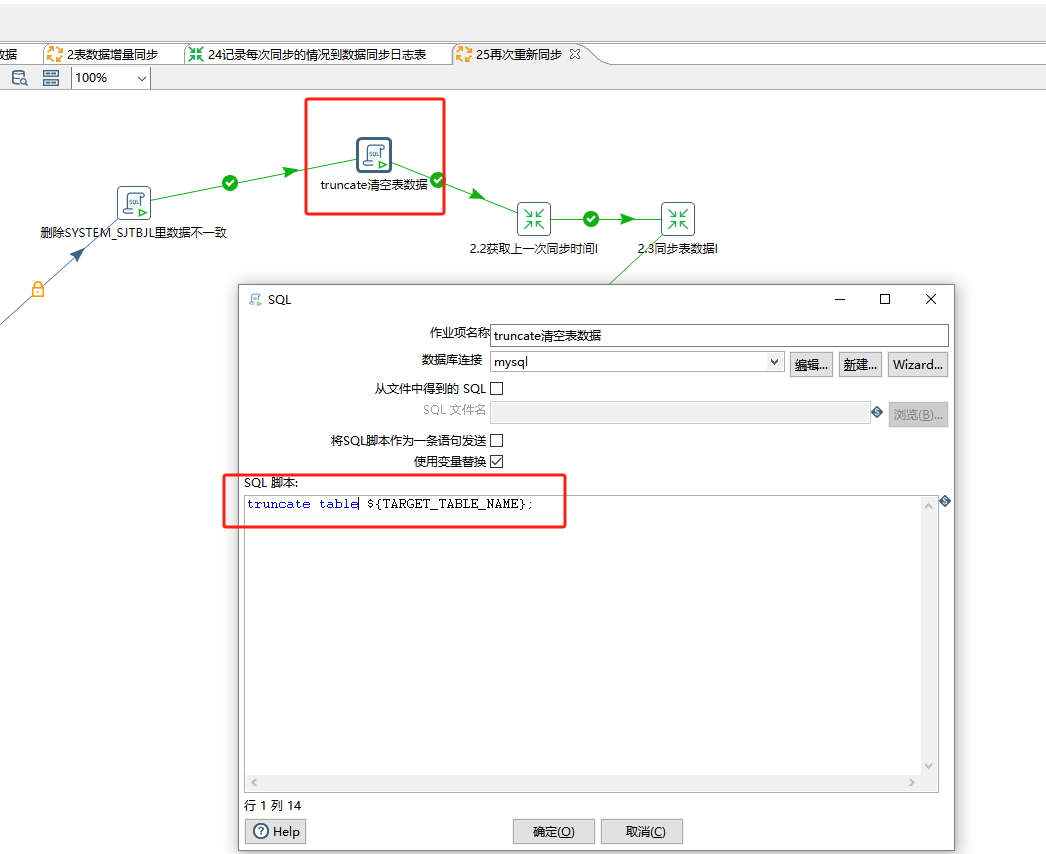
truncate清空表数据:
truncate table ${TARGET_TABLE_NAME};
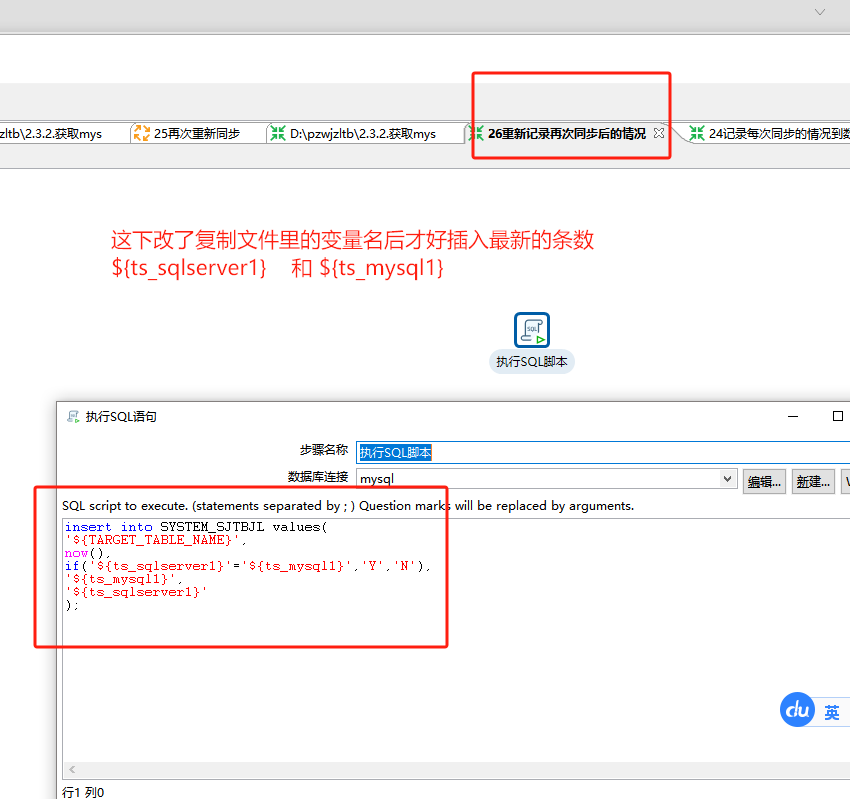
2.6重新记录再次同步后的情况 这个文件里就只需要执行一个sql脚本
insert into SYSTEM_SJTBJL values(
'${TARGET_TABLE_NAME}',
now(),
if('${ts_sqlserver1}'='${ts_mysql1}','Y','N'),
'${ts_mysql1}',
'${ts_sqlserver1}'
);
最后
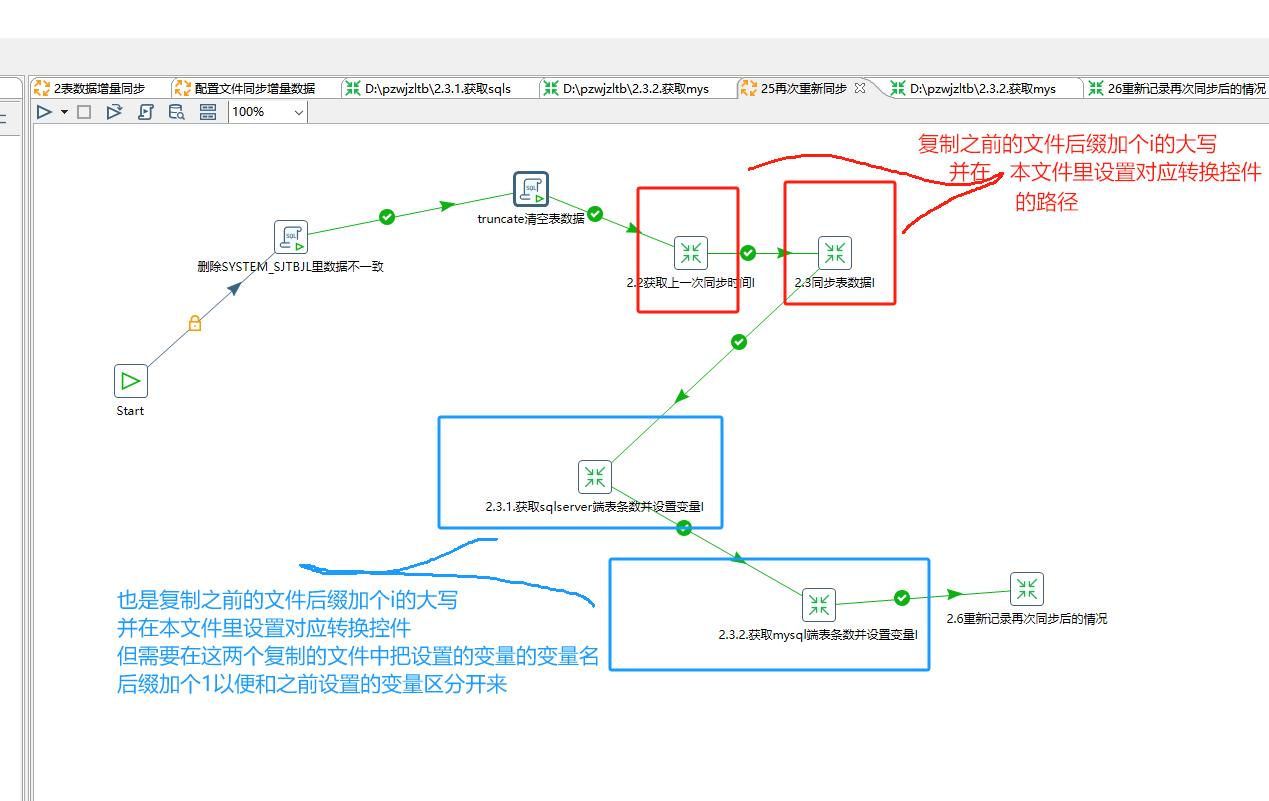
记得检查转换控件和作业控件的文件位置对不对,只有循环处理每个表增量同步这个作业控件要勾选"执行每一个输入行",因为每个表在excel里是一行一行保存读取的,所以这个相当是个循环处理,这也是为什么我们在循环处理每个表增量同步这个作业里写的都是变量来代替表名和字段名的。而获取excel需要同步的表名时不需要勾选,循环处理每个表增量同步这个作业控件对应的作业文件底下的转换控件也不用勾选。
所有都保存了后
我们执行主作业后
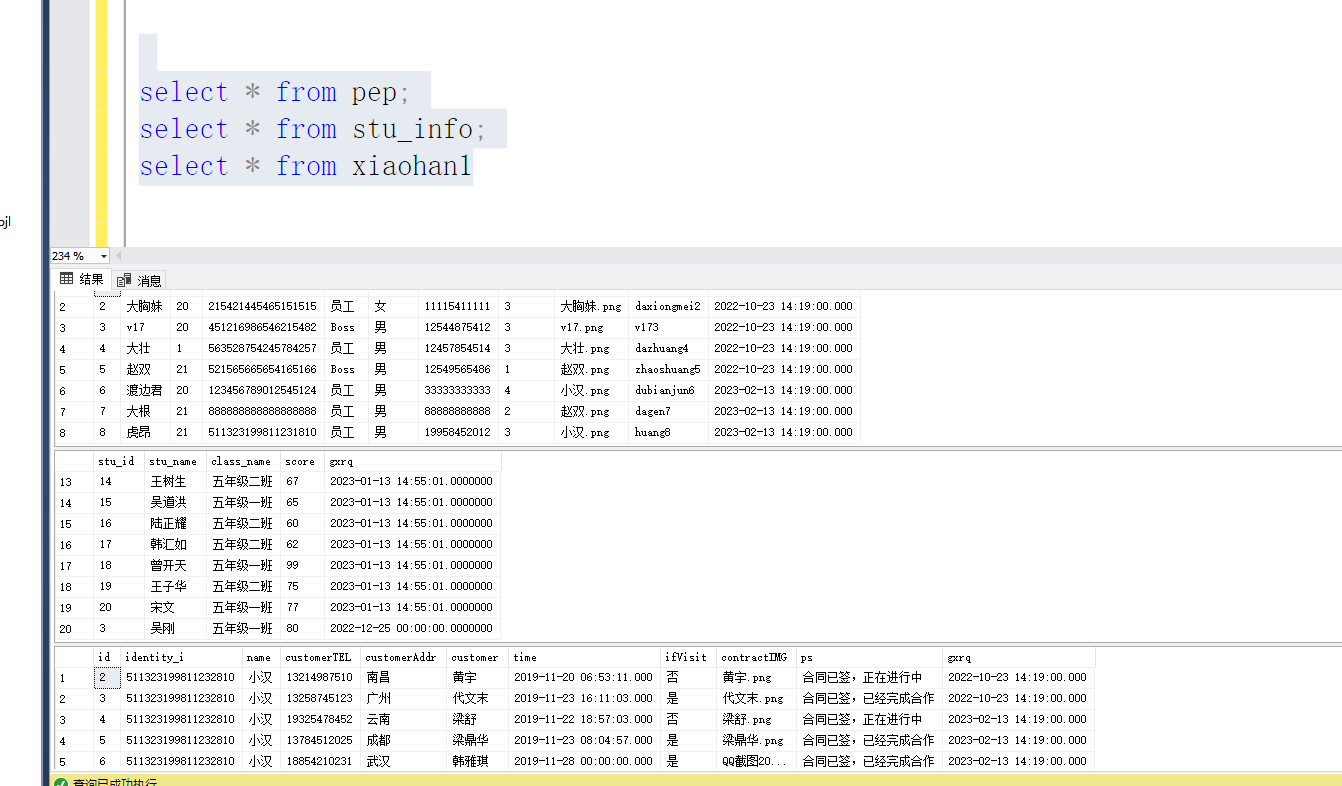
数据都有了 然后我们看到同步后的pep:
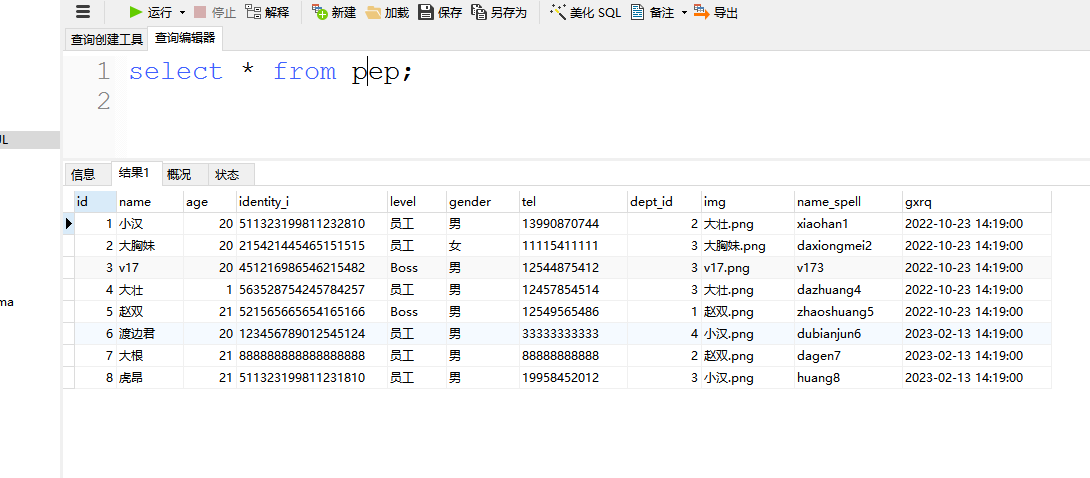
我们增加一条数据:
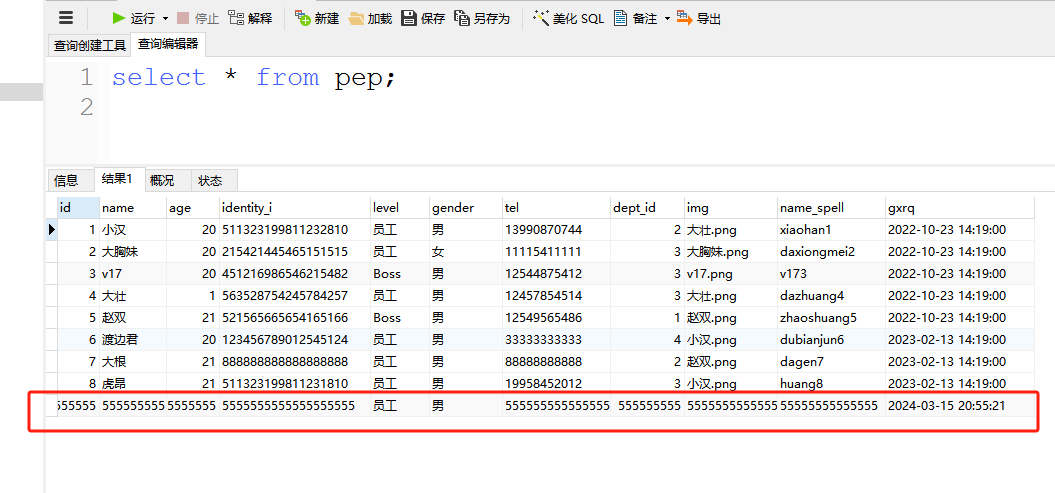
并把SYSTEM_SJTBJL里的pep数据改成N,条数也改成不一致:
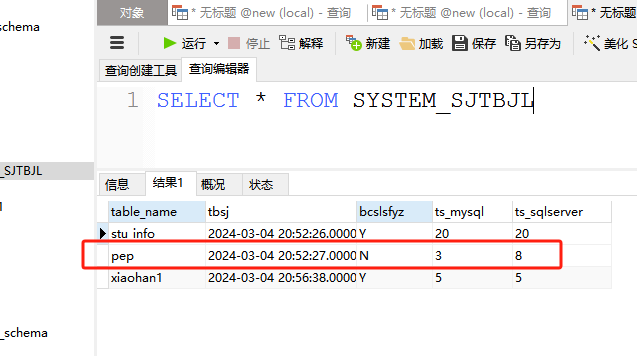
此时kettle再获取时就会进入到不一致的流程删除所有关于这个表的数据,清空表再重新同步全量数据:
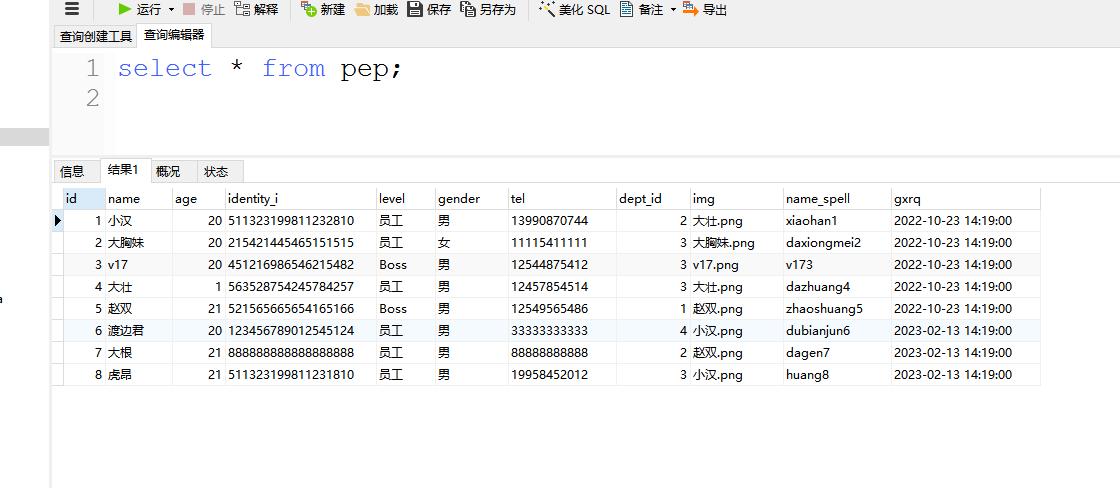
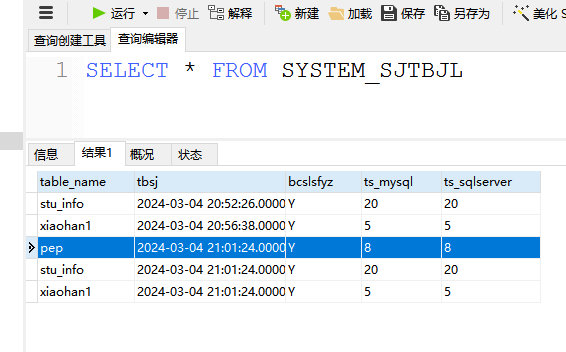
就可以看到执行了两次,一次是空表同步,然后增加了表数据使两端条数不一致,并模拟是正常不一致导致的使SYSTEM_SJTBJL的为N(手动修改模拟)。然后再执行同步程序,之后数据量就正常,且刚才被模拟的表数据记录同步的就只有一条,其他正常同步没有不一致条数的就都有两条。说明这个方案是可行的。