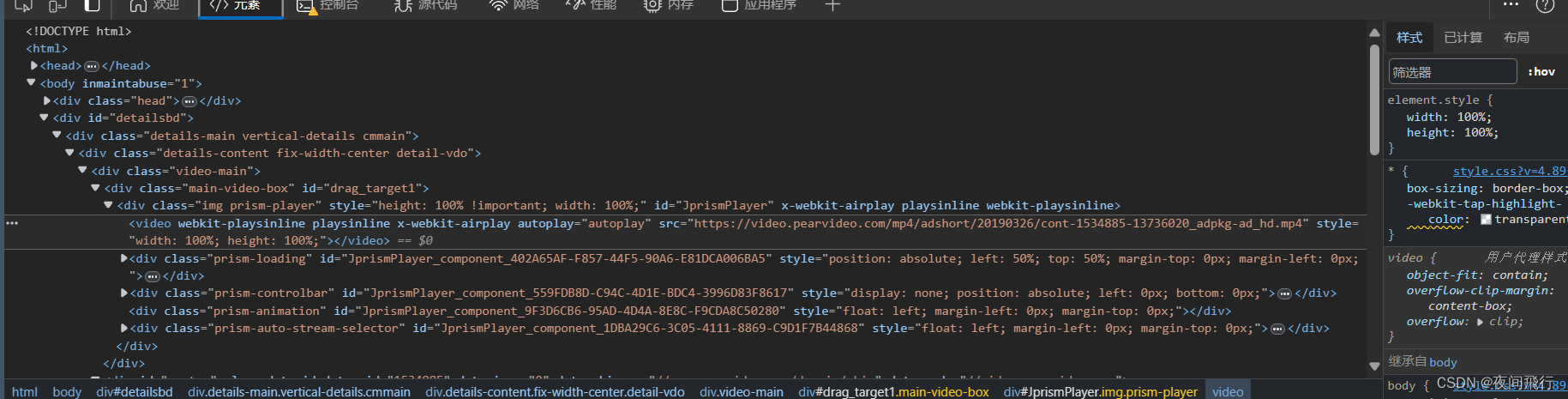
思路:
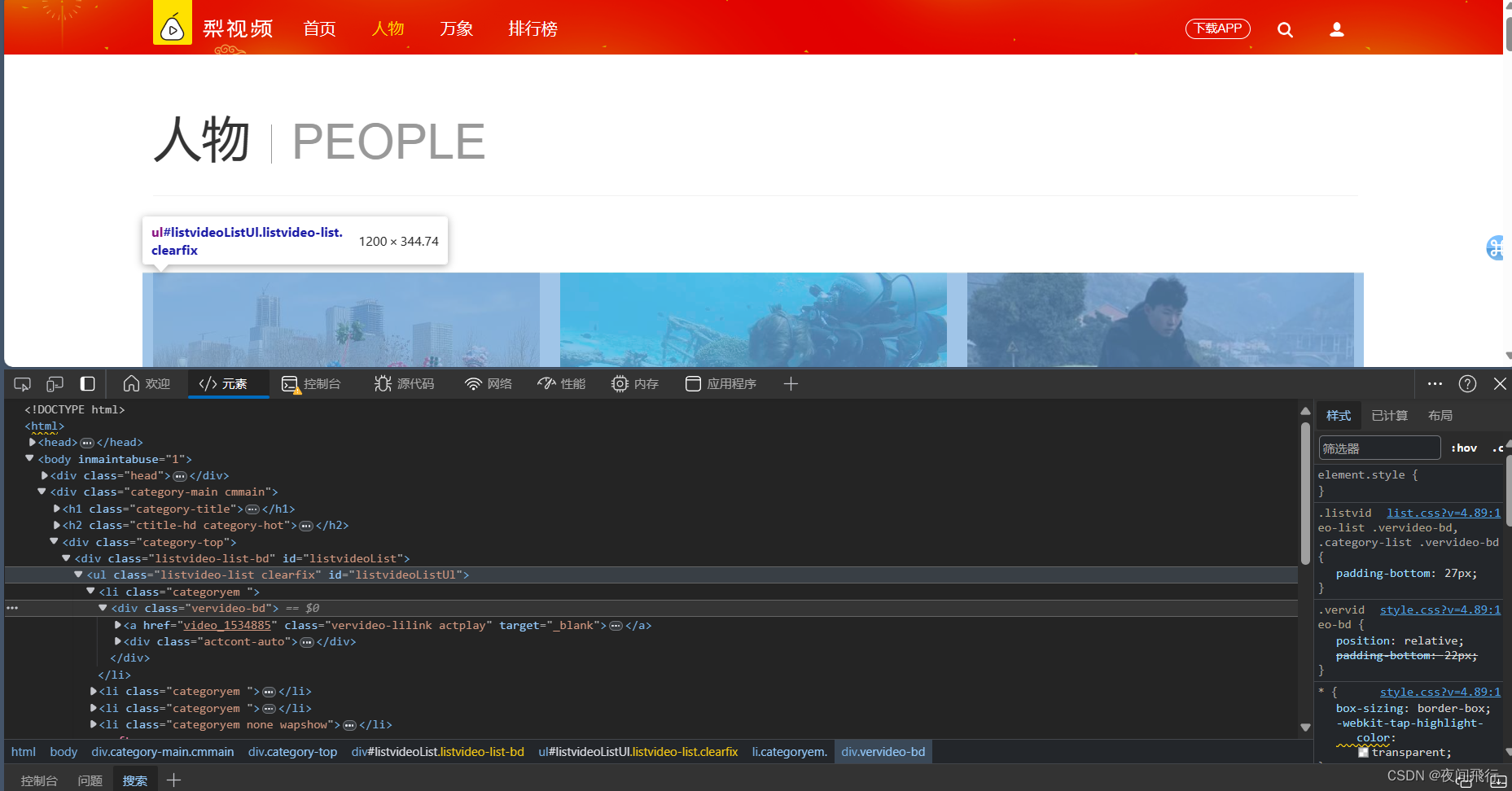
在界面找到视频对应的html元素位置,观察发现视频的url为https://www.pearvideo.com/video_+视频的id,而这个id在html中的href中,所以第一步需要通过xpath捕获到所需要的id
在https://www.pearvideo.com/video_+id的页面,通过控制台查看返回的响应消息,发现没有视频数据,说明视频是进入页面后由其他请求发起获得
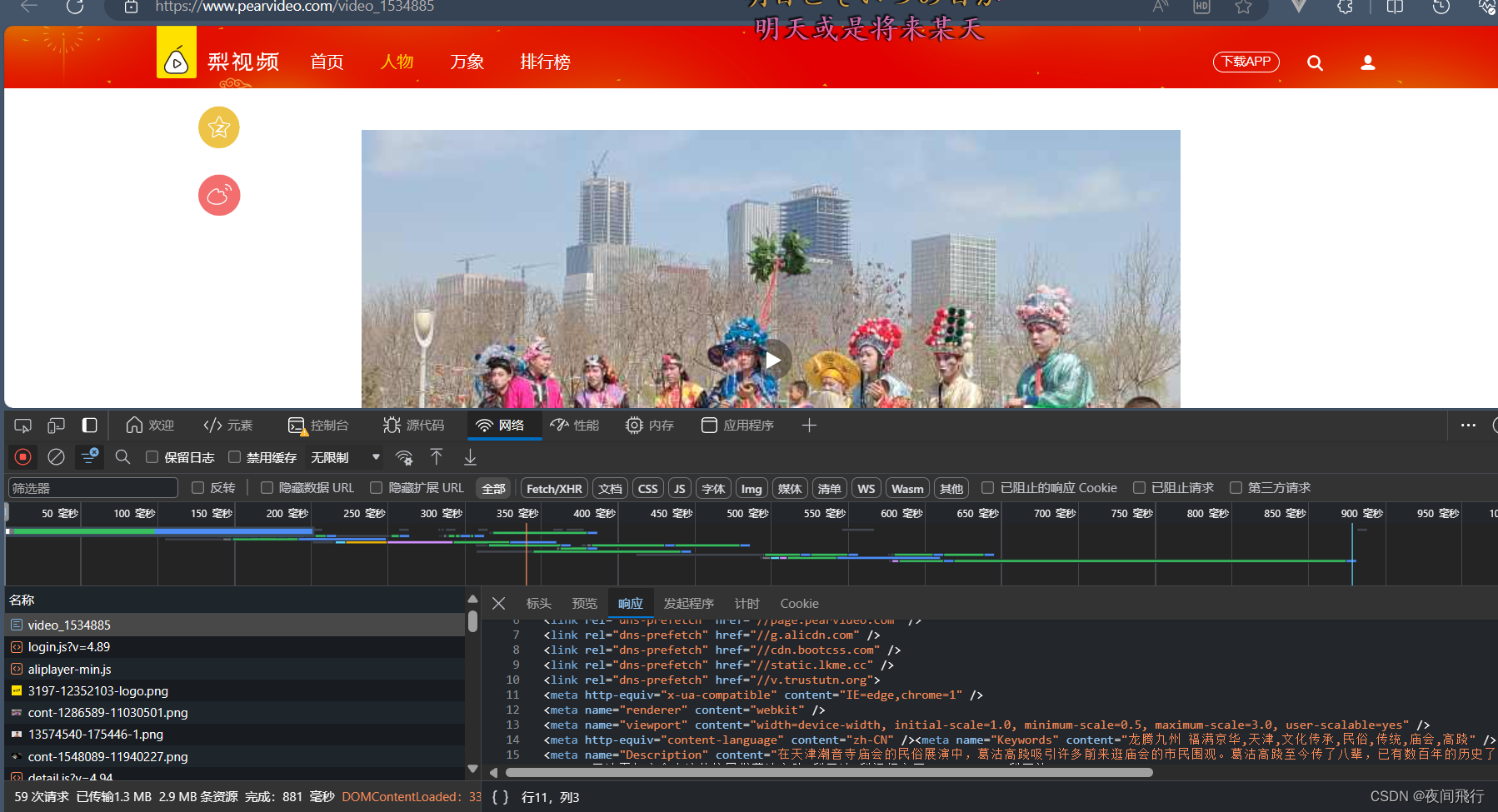
在搜索框中搜索mp4,发现视频文件对应的请求,观察请求的url与负载,发现负载1为视频的id另一个为随机生成的数字。方法为get
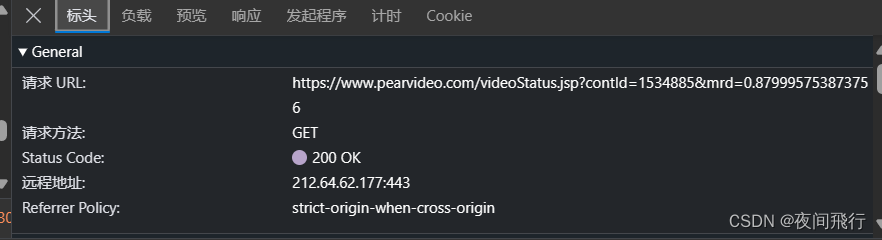
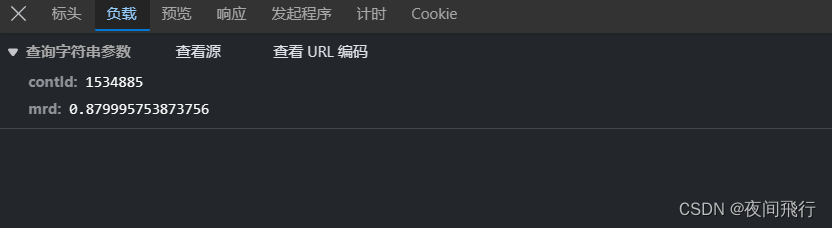
由其返回的视频url与元素中的url进行对比发现是用cont-id替换了一段数字。这一段的url就为视频的url
代码实现:
代码:
import os
from lxml import etree
import requests
import time
from fake_useragent import UserAgent
# UA绕过
ua = UserAgent()
headers = {'User-Agent': ua.random
}def deal_video(id):time.sleep(1)url = "https://www.pearvideo.com/video_" + idurl1 = "https://www.pearvideo.com/videoStatus.jsp?contId=" + idnew_headers = headersnew_headers["Referer"] = urlpage_json = requests.get(url=url1, headers=new_headers).json()video_src = page_json["videoInfo"]["videos"]["srcUrl"]key = "cont-"+url1.split("=")[1]return video_src.replace(video_src.split('/')[6].split('-')[0], key)def save_video(video_src,name):time.sleep(1)print("正在下载"+name)videoData = requests.get(url=video_src, headers=headers).contentif not os.path.exists("./videoLibs"):os.mkdir("./videoLibs")with open("./videoLibs/"+name+".mp4",'wb') as fp:fp.write(videoData)print(dic['name']+" 下载完成")post_url = 'https://www.pearvideo.com/category_1'
# 发出请求
page_text = requests.get(url=post_url, headers=headers).text
# 数据处理
urls = []
tree = etree.HTML(page_text)
videos = tree.xpath('//a[@class="vervideo-lilink actplay"]')
for video in videos:time.sleep(0.5)name = video.xpath('./@href')[0]information_url = "https://www.pearvideo.com/" + nameh = headersid = name.split("_")[1]#从函数中获取到视频的资源位置video_url=deal_video(id)dic = {'name': name,'url': video_url}save_video(video_url,name)urls.append(dic)
解析:
获取主页的text,然后通过xpath找到所以的视频<a>标签,for循环标签,获得href中的id。存储url与名字。通过视频id进入deal_video函数

在url后动态添加视频id,一个作为访问源url,表示从这个页面向url1发起请求,请求头需要携带Referer。通过字典查找获得srcUrl中的视频链接,并将其数字部分替换为cont-id(KEY)。返回视频的url。
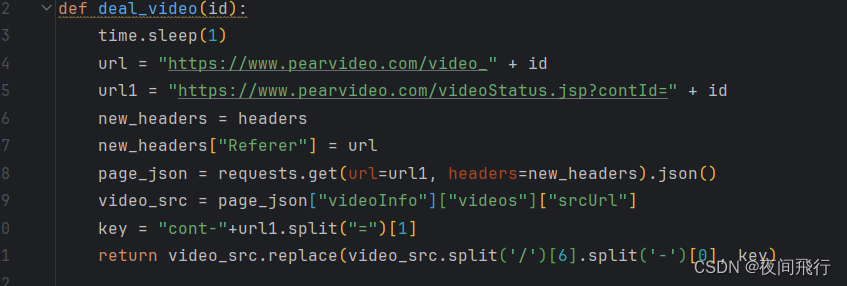
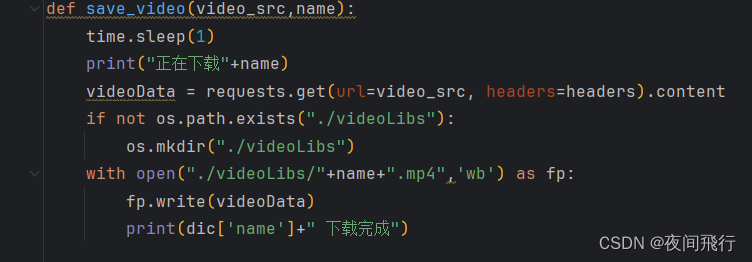
获取视频链接后进入保存函数。
向视频链接发起请求保存到文件夹中




![BUUCTF------[HCTF 2018]WarmUp](https://img-blog.csdnimg.cn/direct/91f9012498db4f7e977d01db2e669644.png)