引言
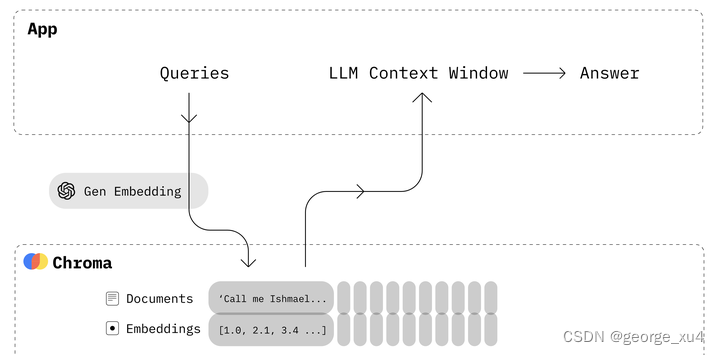
随着大模型的崛起,数据的海洋愈发浩渺无垠。受限于token的数量,无数的开发者们如同勇敢的航海家,开始在茫茫数据之海中探寻新的路径。他们选择了将浩如烟海的知识、新闻、文献、语料等,通过嵌入算法(embedding)的神秘力量,转化为向量数据,存储在神秘的Chroma向量数据库中。每当用户在大模型的界面上输入一个问题,这个问题也会如同被施了魔法一般,被转化为向量,然后在向量数据库中寻找与之最匹配的相关知识。这些知识如同宝藏一般,被精心组合成大模型的上下文,为其提供了丰富的思考背景。这种方式不仅削减了大模型的计算负担,提高了响应的速度,还大大降低了成本。更令人惊叹的是,它巧妙地绕过了大模型的token限制,成为了一种既简单又高效的处理手段。而向量数据库,在大模型的记忆存储等领域中,发挥着无可替代的作用。它的存在,如同一位守护者,默默地守护着大模型的智慧与记忆,让其在知识的海洋中畅游无阻。
由于大模型的火热,现在市面上的向量数据库众多,主流的向量数据库对比如下所示:
| 向量数据库 | URL | GitHub Star | Language |
|---|---|---|---|
| chroma | https://github.com/chroma-core/chroma | 7.4K | Python |
| milvus | https://github.com/milvus-io/milvus | 21.5K | Go/Python/C++ |
| pinecone | https://www.pinecone.io/ | ❌ | ❌ |
| qdrant | https://github.com/qdrant/qdrant | 11.8K | Rust |
| typesense | https://github.com/typesense/typesense | 12.9K | C++ |
| weaviate | https://github.com/weaviate/weaviate | 6.9K | Go |
表格引用自:向量数据库|一文全面了解向量数据库的基本概念、原理、算法、选型-腾讯云开发者社区-腾讯云
本文重点围绕向量数据库Chroma的使用和实战,主要包括以下内容:
- Chroma设计理念
- Chroma常见概念(数据集,文档,存储,查询,条件过滤)
- Chroma快速上手
- Chroma支持的Embeddings算法
- 实战:在Langchain中使用Chroma对中国古典四大名著进行相似性查询
Chroma快速上手
设计理念
Chroma的目标是帮助用户更加便捷地构建大模型应用,更加轻松的将知识(knowledge)、事实(facts)和技能(skills)等我们现实世界中的文档整合进大模型中。
Chroma提供的工具:
- 存储文档数据和它们的元数据:store embeddings and their metadata
- 嵌入:embed documents and queries
- 搜索: search embeddings
Chroma的设计优先考虑:
- 足够简单并且提升开发者效率:simplicity and developer productivity
- 搜索之上再分析:analysis on top of search
- 追求快(性能): it also happens to be very quick
目前官方提供了Python和JavaScript版本,也有其他语言的社区版本支持。
实现Demo
首先需要Python环境(Chroma官方原生支持Python和JavaScript,本文用Python做示例)
pip install chromadb直接运行如下代码,便是一个完整的Demo:
import chromadb
chroma_client = chromadb.Client()collection = chroma_client.create_collection(name="my_collection")collection.add(documents=["This is a document about engineer", "This is a document about steak"],metadatas=[{"source": "doc1"}, {"source": "doc2"}],ids=["id1", "id2"]
)results = collection.query(query_texts=["Which food is the best?"],n_results=2
)print(results)上面的代码中,我们向Chroma提交了两个文档(简单起见,是两个字符串),一个是This is a document about engineer,一个是This is a document about steak。若在add方法没有传入embedding参数,则会使用Chroma默认的all-MiniLM-L6-v2 方式进行embedding。随后,我们对数据集进行query,要求返回两个最相关的结果。提问内容为:Which food is the best?
返回结果:
{'ids': [['id2', 'id1']],'distances': [[1.5835548639297485, 2.1740970611572266]],'metadatas': [[{'source': 'doc2'}, {'source': 'doc1'}]],'embeddings': None,'documents': [['This is a document about steak', 'This is a document about engineer']]
}结果显示,两个文档都被正确返回,且id2由于是steak(牛排),相关性与我们的提问更大,排在了首位。还打印了distances。
数据持久化
Chroma一般是直接作为内存数据库使用,但是也可以进行持久化存储。
在初始化Chroma Client时,使用PersistentClient:
client = chromadb.PersistentClient(path="/Users/yourname/xxxx")这样在运行代码后,在你指定的位置会新建一个chroma.sql