十四、端到端结节分析,以及接下来的步骤
本章内容包括
-
连接分割和分类模型
-
为新任务微调网络
-
将直方图和其他指标类型添加到 TensorBoard
-
从过拟合到泛化
在过去的几章中,我们已经构建了许多对我们的项目至关重要的系统。我们开始加载数据,构建和改进结节候选的分类器,训练分割模型以找到这些候选,处理训练和评估这些模型所需的支持基础设施,并开始将我们的训练结果保存到磁盘。现在是时候将我们拥有的组件统一起来,以便实现我们项目的完整目标:是时候自动检测癌症了。
14.1 迈向终点
通过查看图 14.1 我们可以得到剩余工作的一些线索。在第 3 步(分组)中,我们看到我们仍需要建立第十三章的分割模型和第十二章的分类器之间的桥梁,以确定分割网络找到的是否确实是结节。右侧是第 5 步(结节分析和诊断),整体目标的最后一步:查看结节是否为癌症。这是另一个分类任务;但为了在过程中学到一些东西,我们将通过借鉴我们已有的结节分类器来采取新的方法。
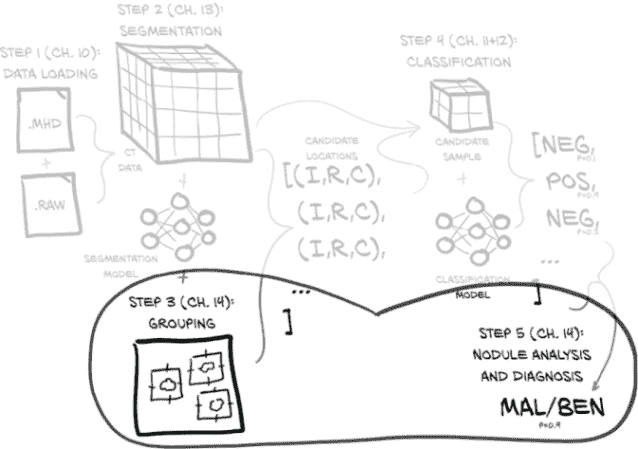
图 14.1 我们的端到端肺癌检测项目,重点关注本章的主题:第 3 步和第 5 步,分组和结节分析
当然,这些简短的描述及其在图 14.1 中的简化描述遗漏了很多细节。让我们通过图 14.2 放大一下,看看我们还有哪些任务要完成。
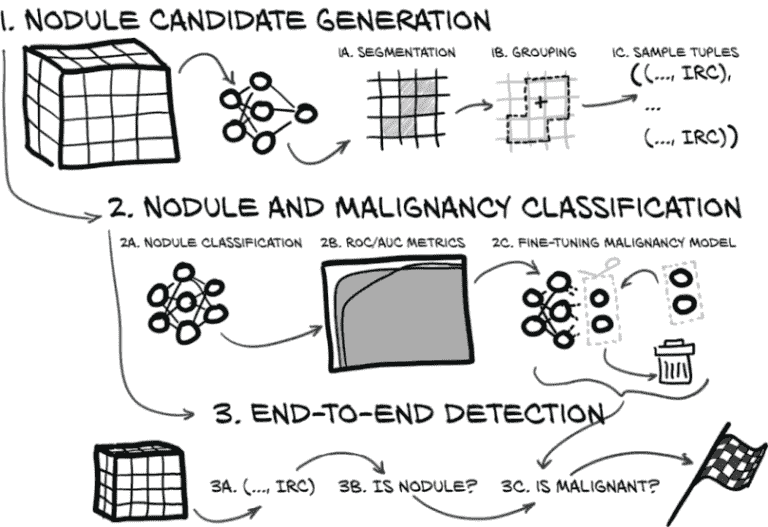
图 14.2 一个关于我们端到端项目剩余工作的详细查看
正如您所看到的,还有三项重要任务。以下列表中的每一项对应于图 14.2 的一个主要项目:
-
生成结节候选。这是整个项目的第 3 步。这一步骤包括三项任务:
-
分割 --第十三章的分割模型将预测给定像素是否感兴趣:如果我们怀疑它是结节的一部分。这将在每个 2D 切片上完成,并且每个 2D 结果将被堆叠以形成包含结节候选预测的体素的 3D 数组。
-
分组 --我们将通过将预测应用于阈值来将体素分组为结节候选,然后将连接区域的标记体素分组。
-
构建样本元组 --每个识别的结节候选将用于构建一个用于分类的样本元组。特别是,我们需要生成该结节中心的坐标(索引、行、列)。
-
一旦实现了这一点,我们将拥有一个应用程序,该应用程序接收患者的原始 CT 扫描并生成检测到的结节候选列表。生成这样的列表是 LUNA 挑战的任务。如果这个项目被临床使用(我们再次强调我们的项目不应该被使用!),这个结节列表将适合由医生进行更仔细的检查。
-
对结节和恶性进行分类。我们将取出我们刚刚产生的结节候选并将其传递到我们在第十二章实现的候选分类步骤,然后对被标记为结节的候选进行恶性检测:
-
结节分类 --从分割和分组中得到的每个结节候选将被分类为结节或非结节。这样做将允许我们筛选出被我们的分割过程标记为许多正常解剖结构。
-
ROC/AUC 指标 --在我们开始最后的分类步骤之前,我们将定义一些用于检查分类模型性能的新指标,并建立一个基准指标,以便与我们的恶性分类器进行比较。
-
微调恶性模型 --一旦我们的新指标就位,我们将定义一个专门用于分类良性和恶性结节的模型,对其进行训练,并查看其表现。我们将通过微调进行训练:这个过程会剔除现有模型的一些权重,并用新值替换它们,然后我们将这些值调整到我们的新任务中。
-
到那时,我们将离我们的最终目标不远了:将结节分类为良性和恶性类别,然后从 CT 中得出诊断。再次强调,在现实世界中诊断肺癌远不止盯着 CT 扫描,因此我们进行这种诊断更多是为了看看我们能够使用深度学习和成像数据单独走多远。
-
端到端检测。最后,我们将把所有这些组合起来,达到终点,将组件组合成一个端到端的解决方案,可以查看 CT 并回答问题“肺部是否存在恶性结节?”
-
IRC --我们将对我们的 CT 进行分割,以获取结节候选样本进行分类。
-
确定结节 --我们将对候选进行结节分类,以确定是否应将其输入恶性分类器。
-
*确定恶性程度 --*我们将对通过结节分类器的结节进行恶性分类,以确定患者是否患癌症。
-
我们有很多事情要做。冲刺终点!
注意 正如前一章中所述,我们将在文本中详细讨论关键概念,并略过重复、繁琐或显而易见的代码部分。完整的细节可以在书籍的代码存储库中找到。
14.2 验证集的独立性
我们面临着一个微妙但关键的错误的危险,我们需要讨论并避免:我们有一个潜在的从训练集到验证集的泄漏!对于分割和分类模型的每一个,我们都小心地将数据分割成一个训练集和一个独立的验证集,通过将每十个示例用于验证,其余用于训练。
然而,分类模型的分割是在结节列表上进行的,分割模型的分割是在 CT 扫描列表上进行的。这意味着我们很可能在分类模型的训练集中有来自分割验证集的结节,反之亦然。我们必须避免这种情况!如果不加以修正,这种情况可能导致性能指标人为地高于我们在独立数据集上获得的性能。这被称为泄漏,它将使我们的验证失效。
为了纠正这种潜在的数据泄漏,我们需要重新设计分类数据集,以便像我们在第十三章中为分割任务所做的那样也在 CT 扫描级别上工作。然后我们需要用这个新数据集重新训练分类模型。好消息是,我们之前没有保存我们的分类模型,所以我们无论如何都需要重新训练。
你应该从中得到的启示是在定义验证集时要注意整个端到端的过程。可能最简单的方法(也是对大多数重要数据集采用的方法)是尽可能明确地进行验证分割–例如,通过为训练和验证分别设置两个目录–然后在整个项目中坚持这种分割。当您需要重新分割时(例如,当您需要按某些标准对数据集进行分层时),您需要使用新分割的数据集重新训练所有模型。
我们为您做的是从第 10-12 章的LunaDataset中复制候选列表,并从第十三章的Luna2dSegmentationDataset中将其分割为测试和验证数据集。由于这是非常机械的,并且没有太多细节可供学习(您现在已经是数据集专家了),我们不会详细展示代码。
我们将通过重新运行分类器的训练来重新训练我们的分类模型:¹
$ python3 -m p2ch14.training --num-workers=4 --epochs 100 nodule-nonnodule
经过 100 个周期,我们对正样本的准确率达到约 95%,对负样本达到 99%。由于验证损失没有再次上升的趋势,我们可以继续训练模型以查看是否会继续改善。
经过 90 个周期,我们达到了最大的 F1 分数,并且在验证准确率方面达到了 99.2%,尽管在实际结节上只有 92.8%。我们将采用这个模型,尽管我们可能也会尝试在恶性结节的准确率上稍微牺牲一些总体准确率(在此期间,模型在实际结节上的准确率为 95.4%,总准确率为 98.9%)。这对我们来说已经足够了,我们准备连接这些模型。
14.3 连接 CT 分割和结节候选分类
现在我们已经从第十三章保存了一个分割模型,并且在上一节刚刚训练了一个分类模型,图 14.3 的步骤 1a、1b 和 1c 显示我们已经准备好开始编写代码,将我们的分割输出转换为样本元组。我们正在进行分组:在图 14.3 的步骤 1b 的高亮周围找到虚线轮廓。我们的输入是分割:由第 1a 中的分割模型标记的体素。我们想要找到 1c,即每个“块”中心的质心坐标:我们需要在样本元组列表中提供的是 1b 加号标记的索引、行和列。
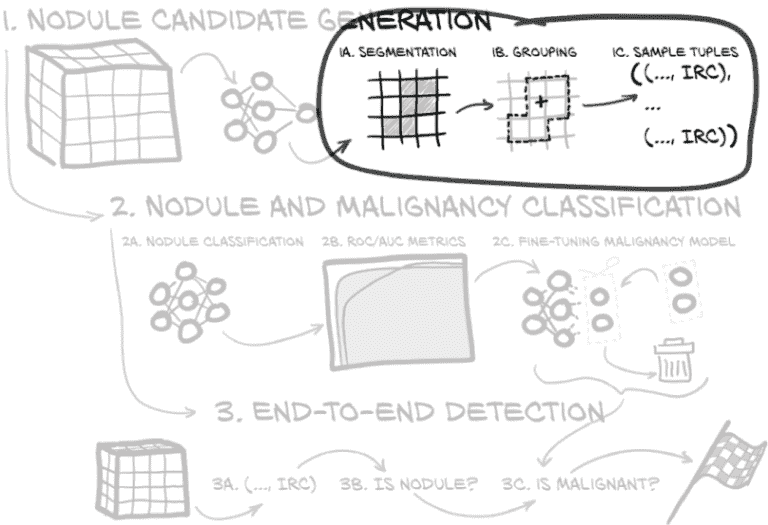
图 14.3 我们本章的计划,重点是将分割的体素分组为结节候选
运行模型时,其处理方式与我们在训练和验证(尤其是验证)期间处理它们的方式非常相似。这里的区别在于对 CT 进行循环。对于每个 CT,我们会分割每个切片,然后将所有分割输出作为分组的输入。分组的输出将被馈送到结节分类器中,通过该分类器幸存下来的结节将被馈送到恶性分类器中。
这是对 CT 的外部循环,对每个 CT 进行分割、分组、分类候选,并提供分类以进行进一步处理。
列表 14.1 nodule_analysis.py:324,NoduleAnalysisApp.main
for _, series_uid in series_iter: # ❶ct = getCt(series_uid) # ❷mask_a = self.segmentCt(ct, series_uid) # ❸candidateInfo_list = self.groupSegmentationOutput( # ❹series_uid, ct, mask_a)classifications_list = self.classifyCandidates( # ❺ct, candidateInfo_list)
❶ 循环遍历系列 UID
❷ 获取 CT(大图中的步骤 1)
❸ 在其上运行我们的分割模型(步骤 2)
❹ 对输出中的标记体素进行分组(步骤 3)
❺ 在它们上运行我们的结节分类器(步骤 4)
我们将在以下部分详细介绍segmentCt、groupSegmentationOutput和classifyCandidates方法。
14.3.1 分割
首先,我们将对整个 CT 扫描的每个切片执行分割。由于我们需要逐个患者的 CT 逐个切片进行处理,我们构建一个Dataset,加载具有单个series_uid的 CT 并返回每个切片,每次调用__getitem__。
注意 特别是在 CPU 上执行时,分割步骤可能需要相当长的时间。尽管我们在这里只是简单提及,但代码将在可用时使用 GPU。
除了更广泛的输入之外,主要区别在于我们如何处理输出。回想一下,输出是每个像素的概率数组(即在 0…1 范围内),表示给定像素是否属于结节。在遍历切片时,我们在一个与我们的 CT 输入形状相同的掩模数组中收集切片预测。之后,我们对预测进行阈值处理以获得二进制数组。我们将使用 0.5 的阈值,但如果需要,我们可以尝试不同的阈值来在增加假阳性的情况下获得更多真阳性。
我们还包括一个使用 scipy.ndimage.morphology 中的腐蚀操作进行小的清理步骤。它删除一个边缘体素层,仅保留内部体素——那些所有八个相邻体素在轴方向上也被标记的体素。这使得标记区域变小,并导致非常小的组件(小于 3 × 3 × 3 体素)消失。结合数据加载器的循环,我们指示它向我们提供来自单个 CT 的所有切片,我们有以下内容。
列表 14.2 nodule_analysis.py:384, .segmentCt
def segmentCt(self, ct, series_uid):with torch.no_grad(): # ❶output_a = np.zeros_like(ct.hu_a, dtype=np.float32) # ❷seg_dl = self.initSegmentationDl(series_uid) # # ❸for input_t, _, _, slice_ndx_list in seg_dl:input_g = input_t.to(self.device) # ❹prediction_g = self.seg_model(input_g) # ❺for i, slice_ndx in enumerate(slice_ndx_list): # ❻output_a[slice_ndx] = prediction_g[i].cpu().numpy()mask_a = output_a > 0.5 # ❼mask_a = morphology.binary_erosion(mask_a, iterations=1)return mask_a
❶ 我们这里不需要梯度,所以我们不构建图。
❷ 这个数组将保存我们的输出:一个概率注释的浮点数组。
❸ 我们获得一个数据加载器,让我们可以按批次循环遍历我们的 CT。
❹ 将输入移动到 GPU 后…
❺ … 我们运行分割模型 …
❻ … 并将每个元素复制到输出数组中。
❼ 将概率输出阈值化以获得二进制输出,然后应用二进制腐蚀进行清理
这已经足够简单了,但现在我们需要发明分组。
14.3.2 将体素分组为结节候选
我们将使用一个简单的连通分量算法将我们怀疑的结节体素分组成块以输入分类。这种分组方法标记连接的组件,我们将使用 scipy.ndimage.measurements.label 完成。label 函数将获取所有与另一个非零像素共享边缘的非零像素,并将它们标记为属于同一组。由于我们从分割模型输出的大部分都是高度相邻像素的块,这种方法很好地匹配了我们的数据。
列表 14.3 nodule_analysis.py:401
def groupSegmentationOutput(self, series_uid, ct, clean_a):candidateLabel_a, candidate_count = measurements.label(clean_a) # ❶centerIrc_list = measurements.center_of_mass( # ❷ct.hu_a.clip(-1000, 1000) + 1001,labels=candidateLabel_a,index=np.arange(1, candidate_count+1),)
❶ 为每个体素分配所属组的标签
❷ 获取每个组的质心作为索引、行、列坐标
输出数组 candidateLabel_a 与我们用于输入的 clean_a 具有相同的形状,但在背景体素处为 0,并且递增的整数标签 1、2、…,每个连接的体素块组成一个结节候选。请注意,这里的标签 不 是分类意义上的标签!这只是在说“这个体素块是体素块 1,这边的体素块是体素块 2,依此类推”。
SciPy 还提供了一个函数来获取结节候选的质心:scipy.ndimage.measurements.center_of_mass。它接受一个每个体素密度的数组,刚刚调用的 label 函数返回的整数标签,以及需要计算质心的这些标签的列表。为了匹配函数期望的质量为非负数,我们将(截取的)ct.hu_a 偏移了 1,001。请注意,这导致所有标记的体素都携带一些权重,因为我们将最低的空气值在本机 CT 单位中夹紧到 -1,000 HU。
列表 14.4 nodule_analysis.py:409
candidateInfo_list = []
for i, center_irc in enumerate(centerIrc_list):center_xyz = irc2xyz( # ❶center_irc,ct.origin_xyz,ct.vxSize_xyz,ct.direction_a,)candidateInfo_tup = \CandidateInfoTuple(False, False, False, 0.0, series_uid, center_xyz) # ❷candidateInfo_list.append(candidateInfo_tup)return candidateInfo_list
❶ 将体素坐标转换为真实患者坐标
❷ 构建我们的候选信息元组并将其附加到检测列表中
作为输出,我们得到一个包含三个数组的列表(分别为索引、行和列),与我们的 candidate_count 长度相同。我们可以使用这些数据来填充一个 candidateInfo_tup 实例的列表;我们已经对这种小数据结构产生了依恋,所以我们将结果放入自从第十章以来一直在使用的相同类型的列表中。由于我们实际上没有适合的数据来填充前四个值(isNodule_bool、hasAnnotation_bool、isMal_bool 和 diameter_mm),我们插入了适当类型的占位符值。然后我们在循环中将我们的坐标从体素转换为物理坐标,创建列表。将我们的坐标从基于数组的索引、行和列移开可能看起来有点愚蠢,但所有消耗 candidateInfo_tup 实例的代码都期望 center_xyz,而不是 center_irc。如果我们尝试互换一个和另一个,我们将得到极其错误的结果!
耶–我们征服了第 3 步,从体素级别的检测中获取结节位置!现在我们可以裁剪出疑似结节,并将它们馈送给我们的分类器,以进一步消除一些假阳性。
14.3.3 我们找到了结节吗?分类以减少假阳性
当我们开始本书的第 2 部分时,我们描述了放射科医生查看 CT 扫描以寻找癌症迹象的工作如下:
目前,审查数据的工作必须由经过高度训练的专家执行,需要对细节进行仔细的注意,主要是在不存在癌症的情况下。
做好这项工作就像被放在 100 堆草垛前,并被告知:“确定这些草垛中是否有针。”
我们已经花费了时间和精力讨论谚语中的针;让我们通过查看图 14.4 来讨论一下草垛。我们的工作,可以说,就是尽可能多地从我们那位眼睛发直的放射科医生面前的草垛中分离出来,这样他们就可以重新聚焦他们经过高度训练的注意力,以便发挥最大的作用。
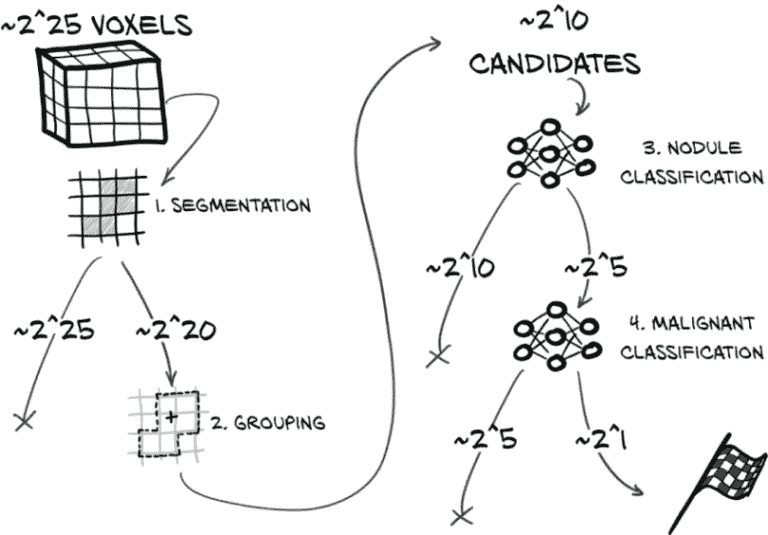
图 14.4 我们端到端检测项目的步骤,以及每个步骤删除的数据的数量级。
让我们看看在执行端到端诊断时每个步骤丢弃了多少数据。图 14.4 中的箭头显示了数据从原始 CT 体素流经我们的项目到最终恶性确定的过程。以 X 结尾的每个箭头表示上一步丢弃的一部分数据;指向下一步的箭头代表经过筛选幸存下来的数据。请注意,这里的数字是非常近似的。
让我们更详细地看一下图 14.4 中的步骤:
-
分割 --分割从整个 CT 开始:数百张切片,或大约 3300 万(225)体素(加减很多)。大约有 220 个体素被标记为感兴趣的;这比总输入要小几个数量级,这意味着我们要丢弃 97%的体素(这是左边导致 X 的 225)。
-
分组。虽然分组并没有明确删除任何内容,但它确实减少了我们考虑的项目数量,因为我们将体素合并为结节候选者。分组从 100 万体素中产生了大约 1000 个候选者(210)。一个 16×16×2 体素的结节将有总共 210 个体素。²
-
结节分类。这个过程丢弃了剩下的大多数~210 个项目。从我们成千上万的结节候选者中,我们剩下了数十个结节:大约 25 个。
-
恶性分类。最后,恶性分类器会取出数十个结节(25 个),找出其中一个或两个(21 个)是癌症的。
沿途的每一步都允许我们丢弃大量数据,我们的模型确信这些数据与我们的癌症检测目标无关。我们从数百万数据点到少数肿瘤。
完全自动化与辅助系统
完全自动化系统和旨在增强人类能力的系统之间存在差异。对于我们的自动化系统,一旦一条数据被标记为无关紧要,它就永远消失了。然而,当向人类呈现数据供其消化时,我们应该允许他们剥开一些层次,查看近似情况,并用一定的信心程度注释我们的发现。如果我们设计一个用于临床使用的系统,我们需要仔细考虑我们确切的预期用途,并确保我们的系统设计能够很好地支持这些用例。由于我们的项目是完全自动化的,我们可以继续前进,而不必考虑如何最好地展示近似情况和不确定的答案。
现在我们已经确定了图像中我们的分割模型认为是潜在候选的区域,我们需要从 CT 中裁剪这些候选并将它们馈送到分类模块中。幸运的是,我们有前一节的 candidateInfo_list,所以我们只需要从中创建一个 DataSet,将其放入 DataLoader,并对其进行迭代。概率预测的第一列是预测的这是一个结节的概率,这是我们想要保留的。就像以前一样,我们收集整个循环的输出。
列表 14.5 结节分析.py:357,.classifyCandidates
def classifyCandidates(self, ct, candidateInfo_list):cls_dl = self.initClassificationDl(candidateInfo_list) # ❶classifications_list = []for batch_ndx, batch_tup in enumerate(cls_dl):input_t, _, _, series_list, center_list = batch_tupinput_g = input_t.to(self.device) # ❷with torch.no_grad():_, probability_nodule_g = self.cls_model(input_g) # ❸if self.malignancy_model is not None: # ❹_, probability_mal_g = self.malignancy_model(input_g)else:probability_mal_g = torch.zeros_like(probability_nodule_g)zip_iter = zip(center_list,probability_nodule_g[:,1].tolist(),probability_mal_g[:,1].tolist())for center_irc, prob_nodule, prob_mal in zip_iter: # ❺center_xyz = irc2xyz(center_irc,direction_a=ct.direction_a,origin_xyz=ct.origin_xyz,vxSize_xyz=ct.vxSize_xyz,)cls_tup = (prob_nodule, prob_mal, center_xyz, center_irc)classifications_list.append(cls_tup)return classifications_list
❶ 再次,我们获得一个数据加载器来循环遍历,这次是基于我们的候选列表。
❷ 将输入发送到设备
❸ 将输入通过结节与非结节网络运行
❹ 如果我们有一个恶性模型,我们也运行它。
❺ 进行我们的簿记,构建我们结果的列表
这太棒了!我们现在可以将输出概率阈值化,得到我们的模型认为是实际结节的列表。在实际设置中,我们可能希望将它们输出供放射科医生检查。同样,我们可能希望调整阈值以更安全地出错一点:也就是说,如果我们的阈值是 0.3 而不是 0.5,我们将呈现更多的候选,结果证明不是结节,同时减少错过实际结节的风险。
列表 14.6 结节分析.py:333,NoduleAnalysisApp.main
if not self.cli_args.run_validation: # ❶print(f"found nodule candidates in {series_uid}:")for prob, prob_mal, center_xyz, center_irc in classifications_list:if prob > 0.5: # ❷s = f"nodule prob {prob:.3f}, "if self.malignancy_model:s += f"malignancy prob {prob_mal:.3f}, "s += f"center xyz {center_xyz}"print(s)if series_uid in candidateInfo_dict: # ❸one_confusion = match_and_score(classifications_list, candidateInfo_dict[series_uid])all_confusion += one_confusionprint_confusion(series_uid, one_confusion, self.malignancy_model is not None)print_confusion("Total", all_confusion, self.malignancy_model is not None
)
❶ 如果我们不通过运行验证,我们打印单独的信息…
❷ … 对于分割找到的所有候选,其中分类器分配的结节概率为 50% 或更高。
❸ 如果我们有真实数据,我们计算并打印混淆矩阵,并将当前结果添加到总数中。
让我们针对验证集中的给定 CT 运行这个:³
$ python3.6 -m p2ch14.nodule_analysis 1.3.6.1.4.1.14519.5.2.1.6279.6001.592821488053137951302246128864
...
found nodule candidates in 1.3.6.1.4.1.14519.5.2.1.6279.6001.592821488053137951302246128864:
nodule prob 0.533, malignancy prob 0.030, center xyz XyzTuple # ❶(x=-128.857421875, y=-80.349609375, z=-31.300007820129395)
nodule prob 0.754, malignancy prob 0.446, center xyz XyzTuple(x=-116.396484375, y=-168.142578125, z=-238.30000233650208)
...
nodule prob 0.974, malignancy prob 0.427, center xyz XyzTuple # ❷(x=121.494140625, y=-45.798828125, z=-211.3000030517578)
nodule prob 0.700, malignancy prob 0.310, center xyz XyzTuple(x=123.759765625, y=-44.666015625, z=-211.3000030517578)
...
❶ 这个候选被分配了 53% 的恶性概率,所以它勉强达到了 50% 的概率阈值。恶性分类分配了一个非常低(3%)的概率。
❷ 被检测为结节,具有非常高的置信度,并被分配了 42% 的恶性概率
脚本总共找到了 16 个结节候选。由于我们正在使用验证集,我们对每个 CT 都有完整的注释和恶性信息,我们可以使用这些信息创建一个混淆矩阵来展示我们的结果。行是真相(由注释定义),列显示我们的项目如何处理每种情况:
1.3.6.1.4.1.14519.5.2.1.6279.6001.592821488053137951302246128864 # ❶| Complete Miss | Filtered Out | Pred. Nodule # ❷Non-Nodules | | 1088 | 15 # ❸Benign | 1 | 0 | 0Malignant | 0 | 0 | 1
❶ 扫描 ID
❷ 预后:完全未检出表示分割未找到结节,被过滤掉是分类器的工作,预测结节是它标记为结节的。
❸ 行包含了真相。
完全未检出列是当我们的分割器根本没有标记结节时。由于分割器并不试图标记非结节,我们将该单元格留空。我们的分割器经过训练具有很高的召回率,因此有大量的非结节,但我们的结节分类器很擅长筛选它们。
所以我们在这个扫描中找到了 1 个恶性结节,但漏掉了第 17 个良性结节。此外,有 15 个误报的非结节通过了结节分类器。分类器的过滤将误报降至 1,000 多个!正如我们之前看到的,1,088 大约是 O(210),所以这符合我们的预期。同样,15 大约是 O(24),这与我们估计的 O(25) 差不多。
很棒!但更大的画面是什么?
14.4 定量验证
现在我们有了一些个案证据表明我们建立的东西可能在一个案例上起作用,让我们看看我们的模型在整个验证集上的表现。这样做很简单:我们将我们的验证集通过之前的预测运行,检查我们得到了多少结节,漏掉了多少,以及多少候选被错误地识别为结节。
我们运行以下内容,如果在 GPU 上运行,应该需要半小时到一个小时。喝完咖啡(或者睡个好觉)后,这是我们得到的结果:
$ python3 -m p2ch14.nodule_analysis --run-validation...
Total| Complete Miss | Filtered Out | Pred. NoduleNon-Nodules | | 164893 | 2156Benign | 12 | 3 | 87Malignant | 1 | 6 | 45
我们检测到了 154 个结节中的 132 个,或者 85%。我们错过的 22 个中,有 13 个未被分割认为是候选结节,因此这将是改进的明显起点。
大约 95%的检测到的结节是假阳性。这当然不是很好;另一方面,这并不是很关键–不得不查看 20 个结节候选才能找到一个结节要比查看整个 CT 要容易得多。我们将在第 14.7.2 节中更详细地讨论这一点,但我们要强调的是,与其将这些错误视为黑匣子,不如调查被错误分类的情况并看看它们是否有共同点。有什么特征可以将它们与被正确分类的样本区分开吗?我们能找到什么可以用来改善我们表现的东西吗?
目前,我们将接受我们的数字如此:不错,但并非完美。当您运行自己训练的模型时,确切的数字可能会有所不同。在本章末尾,我们将提供一些指向可以帮助改善这些数字的论文和技术。通过灵感和一些实验,我们确信您可以获得比我们在这里展示的更好的分数。
14.5 预测恶性
现在我们已经实现了 LUNA 挑战的结节检测任务,并可以生成自己的结节预测,我们问自己一个逻辑上的下一个问题:我们能区分恶性结节和良性结节吗?我们应该说,即使有一个好的系统,诊断恶性可能需要更全面地查看患者,额外的非 CT 背景信息,最终可能需要活检,而不仅仅是孤立地查看 CT 扫描中的单个结节。因此,这似乎是一个可能由医生执行的任务,未来可能会有一段时间。
14.5.1 获取恶性信息
LUNA 挑战专注于结节检测,并不包含恶性信息。LIDC-IDRI 数据集(mng.bz/4A4R)包含了用于 LUNA 数据集的 CT 扫描的超集,并包括有关已识别肿瘤恶性程度的额外信息。方便地,有一个可以轻松安装的 PyLIDC 库,如下所示:
$ pip3 install pylidc
pylicd库为我们提供了我们想要的额外恶性信息的便捷访问。就像我们在第 10 章中所做的那样,将 LIDC 的注释与 LUNA 候选者的坐标匹配,我们需要将 LIDC 的注释信息与 LUNA 候选者的坐标关联起来。
在 LIDC 注释中,恶性信息按照每个结节和诊断放射科医师(最多四位医师查看同一结节)使用从 1(高度不可能)到适度不可能、不确定、适度可疑,最后是 5(高度可疑)的有序五值量表进行编码。这些注释基于图像本身,并受到关于患者的假设的影响。为了将数字列表转换为单个布尔值是/否,我们将考虑当至少有两位放射科医师将该结节评为“适度可疑”或更高时,结节被认为是恶性的。请注意,这个标准有些是任意的;事实上,文献中有许多不同的处理这些数据的方法,包括预测五个步骤,使用平均值,或者从数据集中删除放射科医师评级不确定或不一致的结节。
结合数据的技术方面与第十章相同,因此我们跳过在此处显示代码(代码存储库中有此章节的代码),并将使用扩展的 CSV 文件。我们将以与我们为结节分类器所做的非常相似的方式使用数据集,只是现在我们只需要处理实际结节,并使用给定结节是否为恶性作为要预测的标签。这在结构上与我们在第十二章中使用的平衡非常相似,但我们不是从pos_list和neg_list中抽样,而是从mal_list和ben_list中抽样。就像我们为结节分类器所做的那样,我们希望保持训练数据平衡。我们将这些放入MalignancyLunaDataset类中,该类是LunaDataset的子类,但在其他方面非常相似。
为了方便起见,我们在 training.py 中创建了一个dataset命令行参数,并动态使用命令行指定的数据集类。我们通过使用 Python 的getattr函数来实现这一点。例如,如果self.cli_args.dataset是字符串MalignancyLunaDataset,它将获取p2ch14.dsets.MalignancyLunaDataset并将此类型分配给ds_cls,我们可以在这里看到。
列表 14.7 training.py:154,.initTrainDl
ds_cls = getattr(p2ch14.dsets, self.cli_args.dataset) # ❶train_ds = ds_cls(val_stride=10,isValSet_bool=False,ratio_int=1, # ❷
)
❶ 动态类名查找
❷ 请记住,这是训练数据之间的一对一平衡,这里是良性和恶性之间的平衡。
14.5.2 曲线下面积基线:按直径分类
有一个基线总是好的,可以看到什么性能比没有好。我们可以追求比随机更好,但在这里我们可以使用直径作为恶性的预测因子–更大的结节更有可能是恶性的。图 14.5 的第 2b 步提示了一个我们可以用来比较分类器的新度量标准。
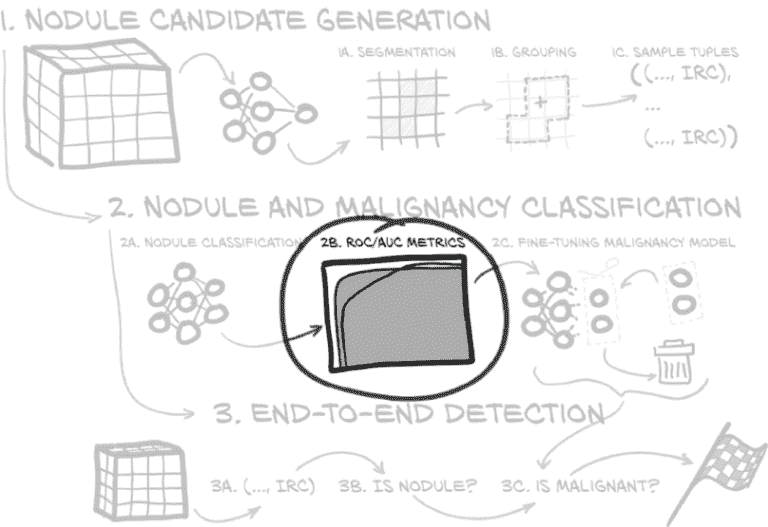
图 14.5 我们在本章中实施的端到端项目,重点是 ROC 图
我们可以将结节直径作为假设分类器预测结节是否为恶性的唯一输入。这不会是一个很好的分类器,但事实证明,说“一切大于这个阈值 X 的东西都是恶性的”比我们预期的更好地预测了恶性。当然,选择正确的阈值是关键–有一个甜蜜点,可以获取所有巨大的肿瘤,而没有任何微小的斑点,并且大致分割了那个不确定区域,其中有一堆较大的良性结节和较小的恶性结节。
正如我们可能从第十二章中记得的那样,我们的真正阳性、假正性、真正性和假负性计数会根据我们选择的阈值值而改变。当我们降低我们预测结节为恶性的阈值时,我们将增加真正阳性的数量,但也会增加假正性的数量。假正率(FPR)是 FP /(FP + TN),而真正率(TPR)是 TP /(TP + FN),您可能还记得这是从第十二章中的召回中得到的。
测量假阳性没有一种真正的方法:精度与假阳性率
这里的 FPR 和第十二章中的精度是(介于 0 和 1 之间的)率,用于衡量不完全相反的事物。正如我们讨论过的,精度是 TP /(TP + FP),用于衡量预测为阳性的样本中有多少实际上是阳性的。FPR 是 FP /(FP + TN),用于衡量实际上为负的样本中有多少被预测为阳性。对于极度不平衡的数据集(如结节与非结节分类),我们的模型可能会实现非常好的 FPR(这与交叉熵标准作为损失密切相关),而精度–因此 F1 分数–仍然非常差。低 FPR 意味着我们正在淘汰我们不感兴趣的很多内容,但如果我们正在寻找那根传说中的针,我们仍然主要是干草。
让我们为我们的阈值设定一个范围。下限将是使得所有样本都被分类为阳性的值,上限将是相反的情况,即所有样本都被分类为阴性。在一个极端情况下,我们的 FPR 和 TPR 都将为零,因为不会有任何阳性;在另一个极端情况下,两者都将为一,因为不会有 TN 和 FN(一切都是阳性!)。
对于我们的结节数据,直径范围从 3.25 毫米(最小结节)到 22.78 毫米(最大结节)。如果我们选择一个介于这两个值之间的阈值,然后可以计算 FPR(阈值)和 TPR(阈值)。如果我们将 FPR 值设为X,TPR 设为Y,我们可以绘制代表该阈值的点;如果我们反而绘制每个可能阈值的 FPR 对 TPR,我们得到一个名为受试者工作特征(ROC)的图表,如图 14.6 所示。阴影区域是ROC 曲线下的面积,或者 AUC。它的取值范围在 0 到 1 之间,数值越高越好。⁵

图 14.6 我们基线的受试者工作特征(ROC)曲线
在这里,我们还指出了两个特定的阈值:直径为 5.42 毫米和 10.55 毫米。我们选择这两个值,因为它们为我们可能考虑的阈值范围提供了相对合理的端点,如果我们需要选择一个单一的阈值。小于 5.42 毫米,我们只会降低我们的 TPR。大于 10.55 毫米,我们只会将恶性结节标记为良性而没有任何收益。这个分类器的最佳阈值可能会在中间某处。
我们实际上是如何计算这里显示的数值的呢?我们首先获取候选信息列表,过滤出已注释的结节,并获取恶性标签和直径。为了方便起见,我们还获取了良性和恶性结节的数量。
列表 14.8 p2ch14_malben_baseline.ipynb
# In[2]:
ds = p2ch14.dsets.MalignantLunaDataset(val_stride=10, isValSet_bool=True) # ❶
nodules = ds.ben_list + ds.mal_list
is_mal = torch.tensor([n.isMal_bool for n in nodules]) # ❷
diam = torch.tensor([n.diameter_mm for n in nodules])
num_mal = is_mal.sum() # ❸
num_ben = len(is_mal) - num_mal
❶ 获取常规数据集,特别是良性和恶性结节的列表
❷ 获取恶性状态和直径的列表
❸ 为了对 TPR 和 FPR 进行归一化,我们获取了恶性和良性结节的数量。
要计算 ROC 曲线,我们需要一个可能阈值的数组。我们从 torch.linspace 获取这个数组,它取两个边界元素。我们希望从零预测的阳性开始,所以我们从最大阈值到最小阈值。这就是我们已经提到的 3.25 到 22.78:
# In[3]:
threshold = torch.linspace(diam.max(), diam.min())
然后我们构建一个二维张量,其中行是每个阈值,列是每个样本信息,值是该样本是否被预测为阳性。然后根据样本的标签(恶性或良性)对此布尔张量进行过滤。我们对行求和以计算True条目的数量。除以恶性或良性结节的数量给出了 TPR 和 FPR–ROC 曲线的两个坐标:
# In[4]:
predictions = (diam[None] >= threshold[:, None]) # ❶
tp_diam = (predictions & is_mal[None]).sum(1).float() / num_mal # ❷
fp_diam = (predictions & ~is_mal[None]).sum(1).float() / num_ben
❶ 通过 None 索引添加了一个大小为 1 的维度,就像 .unsqueeze(ndx) 一样。这使我们得到一个 2D 张量,其中给定结节(在列中)是否被分类为恶性,直径(在行中)。
❷ 使用预测矩阵,我们可以通过对列求和来计算每个直径的 TPR 和 FPR。
要计算这条曲线下的面积,我们使用梯形法进行数值积分(en.wikipedia.org/wiki/Trapezoidal_rule),其中我们将两点之间的平均 TPR(Y 轴上)乘以两个 FPR 之间的差值(X 轴上)–图表中两点之间梯形的面积。然后我们将梯形的面积相加:
# In[5]:
fp_diam_diff = fp_diam[1:] - fp_diam[:-1]
tp_diam_avg = (tp_diam[1:] + tp_diam[:-1])/2
auc_diam = (fp_diam_diff * tp_diam_avg).sum()
现在,如果我们运行pyplot.plot(fp_diam, tp_diam, label=f"diameter baseline, AUC={auc_diam:.3f}")(以及我们在第 8 单元中看到的适当图表设置),我们将得到图 14.6 中看到的图表。
14.5.3 重复使用预先存在的权重:微调
一种快速获得结果的方法(通常也可以用更少的数据完成)是不从随机初始化开始,而是从在某个具有相关数据的任务上训练过的网络开始。这被称为迁移学习或者,当仅训练最后几层时,称为微调。从图 14.7 中突出显示的部分可以看出,在步骤 2c 中,我们将剪掉模型的最后一部分,并用新的东西替换它。
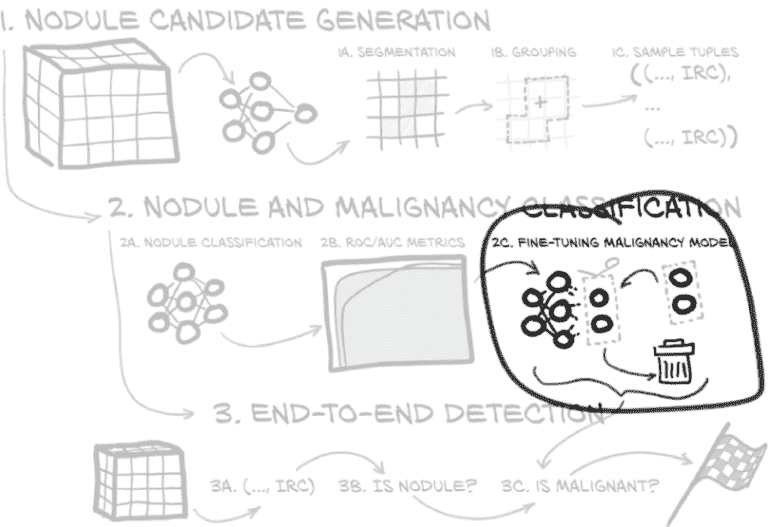
图 14.7 我们在本章中实施的端到端项目,重点是微调
回想一下第八章,我们可以将中间值解释为从图像中提取的特征–特征可以是模型检测到的边缘或角落,或者任何模式的指示。在深度学习之前,很常见使用手工制作的特征,类似于我们在卷积开始时简要尝试的内容。深度学习使网络从数据中提取对当前任务有用的特征,例如区分类别。现在,微调让我们混合使用古老的方法(将近十年前!)使用预先存在的特征和使用学习特征的新方法。我们将网络的一部分(通常是大部分)视为固定的特征提取器,只训练其上的相对较小的部分。
这通常效果非常好。像我们在第二章中看到的在 ImageNet 上训练的预训练网络对处理自然图像的许多任务非常有用–有时它们也对完全不同的输入效果惊人,从绘画或风格转移中的仿制品到音频频谱图。有些情况下,这种策略效果不佳。例如,在训练在 ImageNet 上的模型时,常见的数据增强策略之一是随机翻转图像–一个向右看的狗与向左看的狗属于同一类。因此,翻转图像之间的特征非常相似。但是如果我们现在尝试使用预训练模型进行一个左右有关的任务,我们可能会遇到准确性问题。如果我们想要识别交通标志,这里左转与这里右转是完全不同的;但是基于 ImageNet 特征构建的网络可能会在这两个类之间产生许多错误的分配。
在我们的情况下,我们有一个在类似数据上训练过的网络:结节分类网络。让我们尝试使用它。
为了说明,我们在微调方法中保持非常基本。在图 14.8 中的模型架构中,两个特别感兴趣的部分被突出显示:最后的卷积块和head_linear模块。最简单的微调是剪掉head_linear部分–事实上,我们只是保留了随机初始化。在尝试了这个之后,我们还将探索一种重新训练head_linear和最后一个卷积块的变体。

图 14.8 章节 11 中的模型架构,突出显示了深度-1 和深度-2 的权重
我们需要做以下事情:
-
加载我们希望从中开始的模型的权重,除了最后的线性层,我们希望保留初始化。
-
对于我们不想训练的参数禁用梯度(除了以
head开头的参数)。
当我们在超过head_linear上进行微调训练时,我们仍然只将head_linear重置为随机值,因为我们认为先前的特征提取层可能不太适合我们的问题,但我们期望它们是一个合理的起点。这很简单:我们在模型设置中添加一些加载代码。
列表 14.9 training.py:124,.initModel
d = torch.load(self.cli_args.finetune, map_location='cpu')
model_blocks = [n for n, subm in model.named_children()if len(list(subm.parameters())) > 0 # ❶
]
finetune_blocks = model_blocks[-self.cli_args.finetune_depth:] # ❷
model.load_state_dict({k: v for k,v in d['model_state'].items()if k.split('.')[0] not in model_blocks[-1] # ❸},strict=False, # ❹
)
for n, p in model.named_parameters():if n.split('.')[0] not in finetune_blocks: # ❺p.requires_grad_(False)
❶ 过滤掉具有参数的顶层模块(而不是最终激活)
❷ 获取最后的 finetune_depth 块。默认值(如果进行微调)为 1。
❸ 过滤掉最后一个块(最后的线性部分)并且不加载它。从一个完全初始化的模型开始将使我们从(几乎)所有结节被标记为恶性的状态开始,因为在我们开始的分类器中,该输出表示“结节”。
❹ 通过 strict=False 参数,我们可以仅加载模块的一些权重(其中过滤的权重缺失)。
❺ 对于除 finetune_blocks 之外的所有部分,我们不希望梯度。
我们准备好了!我们可以通过运行以下命令来仅训练头部:
python3 -m p2ch14.training \--malignant \--dataset MalignantLunaDataset \--finetune data/part2/models/cls_2020-02-06_14.16.55_final-nodule-nonnodule.best.state \--epochs 40 \malben-finetune
让我们在验证集上运行我们的模型并获得 ROC 曲线,如图 14.9 所示。这比随机要好得多,但考虑到我们没有超越基线,我们需要看看是什么阻碍了我们。

图 14.9 我们重新训练最后一个线性层的微调模型的 ROC 曲线。不算太糟糕,但也不如基线那么好。
图 14.10 显示了我们训练的 TensorBoard 图表。观察验证损失,我们可以看到虽然 AUC 缓慢增加,损失减少,但即使训练损失似乎在一个相对较高的水平(比如 0.3)上趋于平稳,而不是朝向零。我们可以进行更长时间的训练来检查是否只是非常缓慢;但将这与第五章讨论的损失进展进行比较–特别是图 5.14–我们可以看到我们的损失值并没有像图中的 A 案那样完全平稳,但我们的损失停滞问题在质量上是相似的。当时,A 案表明我们的容量不足,因此我们应考虑以下三种可能的原因:
-
通过在结节与非结节分类上训练网络获得的特征(最后一个卷积的输出)对恶性检测并不有用。
-
头部的容量–我们唯一训练的部分–并不够大。
-
整体网络的容量可能太小了。

图 14.10 最后一个线性层微调的 AUC(左)和损失(右)
如果仅对全连接部分进行微调训练不够,下一步尝试的是将最后一个卷积块包括在微调训练中。幸运的是,我们引入了一个参数,所以我们可以将block4部分包含在我们的训练中:
python3 -m p2ch14.training \--malignant \--dataset MalignantLunaDataset \--finetune data/part2/models/cls_2020-02-06_14.16.55_final-nodule-nonnodule.best.state \--finetune-depth 2 \ # ❶--epochs 10 \malben-finetune-twolayer
❶ 这个 CLI 参数是新的。
完成后,我们可以将我们的新最佳模型与基线进行比较。图 14.11 看起来更合理!我们几乎没有误报,就能标记出约 75%的恶性结节。这显然比直径基线的 65%要好。当我们试图超过 75%时,我们的模型性能会回到基线。当我们回到分类问题时,我们将希望在 ROC 曲线上选择一个平衡真阳性与假阳性的点。

图 14.11 我们修改后模型的 ROC 曲线。现在我们离基线非常接近。
我们大致与基线持平,我们会对此感到满意。在第 14.7 节中,我们暗示了许多可以探索以改善这些结果的方法,但这些内容没有包含在本书中。
从图 14.12 中观察损失曲线,我们可以看到我们的模型现在很早就开始过拟合;因此下一步将是进一步检查正则化方法。我们将留给您处理。
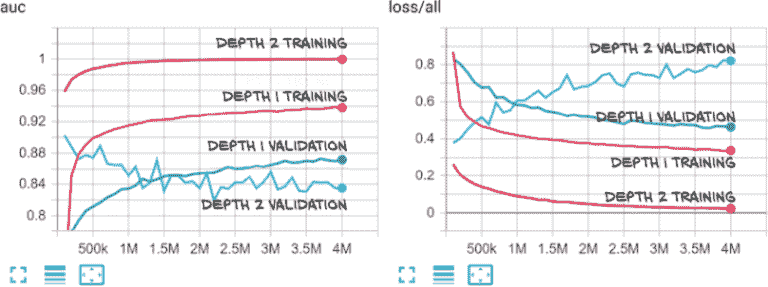
图 14.12 最后一个卷积块和全连接层微调的 AUC(左)和损失(右)
有更精细的微调方法。有些人主张逐渐解冻层,从顶部开始。其他人建议用通常的学习率训练后面的层,并为较低的层使用较小的学习率。PyTorch 本身支持使用不同的优化参数,如学习率、权重衰减和动量,通过将它们分开在几个参数组中,这些参数组只是那样:具有单独超参数的参数列表(pytorch.org/docs/stable/optim.html#per-parameter-options)。
14.5.4 TensorBoard 中的更多输出
当我们重新训练模型时,值得看一看我们可以添加到 TensorBoard 中的一些额外输出,以查看我们的表现如何。对于直方图,TensorBoard 有一个预制的记录功能。对于 ROC 曲线,它没有,因此我们有机会满足 Matplotlib 接口。
直方图
我们可以获取恶性的预测概率并制作一个直方图。实际上,我们制作了两个:一个是(根据地面实况)良性的,一个是恶性结节的。这些直方图让我们深入了解模型的输出,并让我们看到是否有完全错误的大集群输出概率。
注意 一般来说,塑造您显示的数据是从数据中获取高质量信息的重要部分。如果您有许多非常自信的正确分类,您可能希望排除最左边的箱子。将正确的内容显示在屏幕上通常需要一些仔细思考和实验的迭代。不要犹豫调整您显示的内容,但也要注意记住,如果您更改了特定指标的定义而没有更改名称,将很容易将苹果与橙子进行比较。除非您在命名方案或删除现在无效的数据运行时有纪律地更改。
我们首先在保存我们的数据的张量metrics_t中创建一些空间。回想一下,我们在某处定义了索引。
列表 14.10 training.py:31
METRICS_LABEL_NDX=0
METRICS_PRED_NDX=1
METRICS_PRED_P_NDX=2 # ❶
METRICS_LOSS_NDX=3
METRICS_SIZE = 4
❶ 我们的新指数,携带着预测概率(而不是经过阈值处理的预测)
一旦完成这一步,我们可以调用writer.add_histogram,传入一个标签、数据以及设置为我们呈现的训练样本数的global_step计数器;这类似于之前的标量调用。我们还传入bins设置为一个固定的尺度。
列表 14.11 training.py:496,.logMetrics
bins = np.linspace(0, 1)writer.add_histogram('label_neg',metrics_t[METRICS_PRED_P_NDX, negLabel_mask],self.totalTrainingSamples_count,bins=bins
)
writer.add_histogram('label_pos',metrics_t[METRICS_PRED_P_NDX, posLabel_mask],self.totalTrainingSamples_count,bins=bins
)
现在我们可以看一看我们对良性样本的预测分布以及它在每个时期如何演变。我们想要检查图 14.13 中直方图的两个主要特征。正如我们所期望的,如果我们的网络正在学习任何东西,在良性样本和非结节的顶行中,左侧有一个山峰,表示网络非常确信它所看到的不是恶性的。同样,在恶性样本中右侧也有一个山峰。
但仔细观察,我们看到了仅微调一个层的容量问题。专注于左上角的直方图系列,我们看到左侧的质量有些分散,并且似乎没有减少太多。甚至在 1.0 附近有一个小峰值,而且相当多的概率质量分布在整个范围内。这反映了损失不愿意降到 0.3 以下。

图 14.13 TensorBoard 直方图显示仅微调头部
鉴于对训练损失的观察,我们不必再深入研究,但让我们假装一下。在右侧的验证结果中,似乎在顶部右侧图表中,远离“正确”一侧的概率质量对于非恶性样本比底部右侧图表中的恶性样本更大。因此,网络更经常将非恶性样本错误分类为恶性样本。这可能会让我们考虑重新平衡数据以展示更多的非恶性样本。但再次强调,这是当我们假装左侧的训练没有任何问题时。我们通常希望先修复训练!
为了比较,让我们看看我们深度为 2 的微调相同图表(图 14.14)。在训练方面(左侧两个图表),我们在正确答案处有非常尖锐的峰值,其他内容不多。这反映了训练效果很好。

图 14.14 TensorBoard 直方图显示,深度为 2 的微调
在验证方面,我们现在看到最明显的问题是底部右侧直方图中预测概率为 0 的小峰值。因此,我们的系统性问题是将恶性样本误分类为非恶性。这与我们之前看到的两层微调过拟合相反!可能最好查看一些这种类型的图像,看看发生了什么。
TensorBoard 中的 ROC 和其他曲线
正如前面提到的,TensorBoard 本身不支持绘制 ROC 曲线。但是,我们可以利用 Matplotlib 导出任何图形的功能。数据准备看起来就像第 14.5.2 节中的一样:我们使用了在直方图中绘制的数据来计算 TPR 和 FPR–分别是tpr和fpr。我们再次绘制我们的数据,但这次我们跟踪pyplot.figure并将其传递给SummaryWriter方法add_figure。
列表 14.12 training.py:482,.logMetrics
fig = pyplot.figure() # ❶
pyplot.plot(fpr, tpr) # ❷
writer.add_figure('roc', fig, self.totalTrainingSamples_count) # ❸
❶ 设置一个新的 Matplotlib 图。通常我们不需要它,因为 Matplotlib 会隐式完成,但在这里我们需要。
❷ 使用任意 pyplot 函数
❸ 将我们的图表添加到 TensorBoard
因为这是作为图像提供给 TensorBoard 的,所以它出现在该标题下。我们没有绘制比较曲线或其他任何内容,以免让您分心,但我们可以在这里使用任何 Matplotlib 工具。在图 14.15 中,我们再次看到深度为 2 的微调(左侧)过拟合,而仅对头部进行微调(右侧)则没有。

图 14.15 在 TensorBoard 中训练 ROC 曲线。滑块让我们浏览迭代。
14.6 当我们进行诊断时看到的情况
沿着图 14.16 中的步骤 3a、3b 和 3c,我们现在需要运行从左侧的步骤 3a 分割到右侧的步骤 3c 恶性模型的完整流程。好消息是,我们几乎所有的代码都已经就位!我们只需要将它们组合起来:现在是时候实际编写并运行我们的端到端诊断脚本了。
我们在第 14.3.3 节的代码中首次看到了处理恶性模型的线索。如果我们向nodule_analysis调用传递一个参数--malignancy-path,它将运行在此路径找到的恶性模型并输出信息。这适用于单个扫描和--run-validation变体。
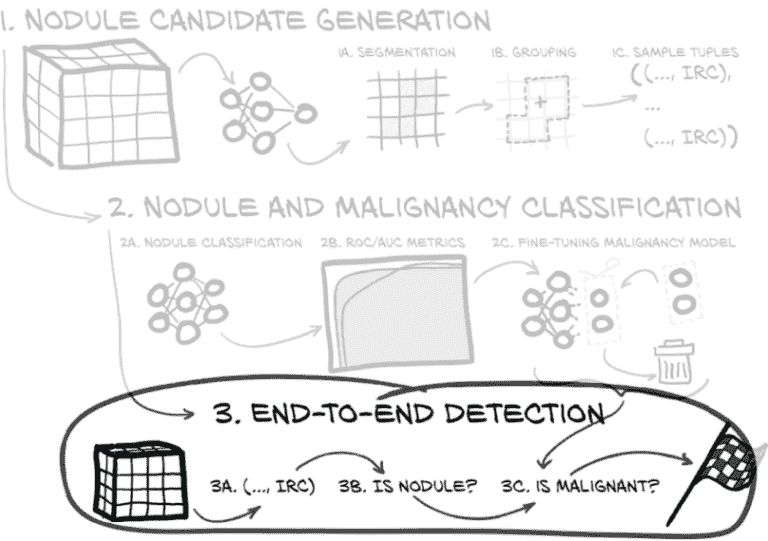
图 14.16 我们在本章实施的端到端项目,重点是端到端检测
请注意,脚本可能需要一段时间才能完成;即使只有验证集中的 89 个 CT 花费了大约 25 分钟。⁷
让我们看看我们得到了什么:
Total| Complete Miss | Filtered Out | Pred. Benign | Pred. MalignantNon-Nodules | | 164893 | 1593 | 563Benign | 12 | 3 | 70 | 17Malignant | 1 | 6 | 9 | 36
不算太糟糕!我们检测到大约 85%的结节,并正确标记了约 70%的恶性结节,从头到尾。⁸ 虽然我们有很多假阳性,但似乎每个真结节有 16 个假阳性减少了需要查看的内容(好吧,如果没有 30%的假阴性的话)。正如我们在第九章中已经警告过的那样,这还不到你可以为你的医疗人工智能初创公司筹集数百万资金的水平,⁹ 但这是一个相当合理的起点。总的来说,我们应该对我们得到的明显有意义的结果感到满意;当然,我们真正的目标一直是在学习深度学习的过程中。
接下来,我们可能会选择查看实际被错误分类的结节。请记住,对于我们手头的任务,即使标注数据集的放射科医生们在看法上也存在差异。我们可能会根据他们清晰地将结节识别为恶性的程度来分层我们的验证集。
14.6.1 训练、验证和测试集
我们必须提到一个警告。虽然我们没有明确地在验证集上训练我们的模型,尽管我们在本章的开头冒了这个风险,但我们确实选择了基于模型在验证集上的表现来使用的训练时期。这也是一种数据泄漏。事实上,我们应该预期我们的实际性能会略逊色于这个,因为最好的模型在我们的验证集上表现得很好,不太可能在每个其他未见过的数据集上表现得同样出色(至少平均而言)。
由于这个原因,实践者经常将数据分为三组:
-
一个训练集,就像我们在这里所做的一样
-
一个验证集,用于确定模型演化的哪个时期被认为是“最佳”
-
一个测试集,用于实际预测模型的性能(由验证集选择)在未见过的真实世界数据上
添加第三组将导致我们再次拉取我们的训练数据的另一个非常重要的部分,考虑到我们已经不得不为了对抗过拟合而努力。这也会使呈现变得更加复杂,所以我们故意将其排除在外。如果这是一个有资源获取更多数据并迫切需要构建在野外使用的最佳系统的项目,我们将不得不在这里做出不同的决定,并积极寻找更多数据用作独立的测试集。
总的来说,偏见潜入我们的模型的方式是微妙的。我们应该特别小心地控制信息泄漏的每一步,并尽可能使用独立数据验证其不存在。采取捷径的代价是在后期惨败,而这种情况发生的时间是最糟糕的:当我们接近生产时。
14.7 接下来呢?灵感(和数据)的额外来源
在这一点上,进一步的改进将很难衡量。我们的分类验证集包含 154 个结节,我们的结节分类模型通常至少有 150 个正确,大部分的变化来自每个时期的训练变化。即使我们对模型进行了显著改进,我们的验证集中也没有足够的准确性来确定这种改变是否肯定是改进!这在良性与恶性分类中也非常明显,验证损失经常曲折。如果我们将验证步幅从 10 减少到 5,我们的验证集的大小将翻倍,代价是我们训练数据的九分之一。如果我们想尝试其他改进,这可能是值得的。当然,我们还需要解决测试集的问题,这将减少我们已经有限的训练数据。
我们还希望仔细研究网络表现不如我们期望的情况,看看是否能够识别出任何模式。但除此之外,让我们简要谈谈一些通用的方法,我们可以改进我们的项目。在某种程度上,这一部分就像第八章中的第 8.5 节。我们将努力为您提供尝试的想法;如果您不详细了解每个想法也不要担心。
14.7.1 防止过拟合:更好的正则化
回顾第 2 部分我们所做的事情,在三个问题中–第十一章和第 14.5 节中的分类器,以及第十三章中的分割–我们都有过拟合模型。在第一种情况下,过拟合是灾难性的;我们通过在第十二章中平衡数据和增强来处理它。这种数据平衡以防止过拟合也是训练 U-Net 在结节和候选者周围的裁剪而不是完整切片的主要动机。对于剩余的过拟合,我们选择了退出,当过拟合开始影响我们的验证结果时提前停止训练。这意味着预防或减少过拟合将是改善我们结果的好方法。
这种模式–获得一个过拟合的模型,然后努力减少过拟合–实际上可以看作是一个配方。因此,当我们想要改进我们现在所取得的状态时,应该使用这种两步方法。
经典正则化和增强
您可能已经注意到,我们甚至没有使用第八章中的所有正则化技术。例如,辍学将是一个容易尝试的事情。
虽然我们已经进行了一些增强,但我们可以走得更远。我们没有尝试使用的一个相对强大的增强方法是弹性变形,其中我们将“数字皱褶”放入输入中。这比仅仅旋转和翻转产生了更多的变化,似乎也适用于我们的任务。
更抽象的增强
到目前为止,我们的增强受到几何启发–我们将输入转换为更或多或少看起来像我们可能看到的合理东西。事实证明,我们不必局限于这种类型的增强。
回顾第八章,从数学上讲,我们一直在使用的交叉熵损失是预测和将所有概率质量放在标签上的分布之间的差异度量,可以用标签的独热向量表示。如果我们的网络存在过度自信的问题,我们可以尝试的一个简单方法是不使用独热分布,而是在“错误”类别上放置一小部分概率质量。这被称为标签平滑。
我们还可以同时处理输入和标签。一个非常通用且易于应用的增强技术被提出,名为mixup:作者建议随机插值输入和标签。有趣的是,在对损失进行线性假设(这由二元交叉熵满足)的情况下,这等效于仅使用从适当调整的分布中绘制的权重来操作输入。显然,在处理真实数据时,我们不希望出现混合输入,但似乎这种混合鼓励预测的稳定性并且非常有效。
超越单一最佳模型:集成
我们对过拟合问题的一个观点是,如果我们知道正确的参数,我们的模型可以按照我们想要的方式工作,但我们实际上并不知道这些参数。如果我们遵循这种直觉,我们可能会尝试提出几组参数(也就是几个模型),希望每个模型的弱点可以互相补偿。这种评估几个模型并组合输出的技术称为集成。简而言之,我们训练几个模型,然后为了预测,运行它们所有并平均预测。当每个单独模型过拟合时(或者我们在开始看到过拟合之前拍摄了模型的快照),似乎这些模型可能开始对不同的输入做出错误预测,而不总是首先过拟合相同的样本。
在集成中,我们通常使用完全独立的训练运行或者不同的模型结构。但如果我们想要简化,我们可以从单次训练运行中获取几个模型的快照–最好是在结束前不久或者在开始观察到过拟合之前。我们可以尝试构建这些快照的集成,但由于它们仍然相互接近,我们可以选择对它们进行平均。这就是随机权重平均的核心思想。我们在这样做时需要一些小心:例如,当我们的模型使用批量归一化时,我们可能需要调整统计数据,但即使没有这样做,我们也可能获得一些小的准确度提升。
概括我们要求网络学习的内容
我们还可以看看多任务学习,在这里我们要求模型学习除了我们将要评估的输出之外的额外输出,这已经被证明可以改善结果。我们可以尝试同时训练结节与非结节以及良性与恶性。实际上,恶性数据的数据源提供了我们可以用作额外任务的额外标签;请参见下一节。这个想法与我们之前看到的迁移学习概念密切相关,但在这里我们通常会同时训练两个任务,而不是先完成一个再尝试转移到下一个。
如果我们没有额外的任务,而是有一堆额外的未标记数据,我们可以研究半监督学习。最近提出的一个看起来非常有效的方法是无监督数据增强。在这里,我们像往常一样在数据上训练我们的模型。在未标记数据上,我们对未增强的样本进行预测。然后我们将该预测作为该样本的目标,并训练模型在增强样本上也预测该目标。换句话说,我们不知道预测是否正确,但我们要求网络无论增强与否都产生一致的输出。
当我们没有更多感兴趣的任务但又没有额外数据时,我们可能会考虑捏造数据。捏造数据有些困难(尽管有时人们会使用类似第二章中简要介绍的 GANs,取得一定成功),因此我们选择捏造任务。这时我们进入了自监督学习的领域;这些任务通常被称为借口任务。一个非常流行的借口任务系列是对一些输入进行某种形式的破坏。然后我们可以训练一个网络来重建原始数据(例如,使用类似 U-Net 结构)或者训练一个分类器来检测真实数据和破坏数据,同时共享模型的大部分部分(例如卷积层)。
这仍然取决于我们想出一种损坏输入的方法。如果我们没有这样的方法并且没有得到想要的结果,还有其他方法可以进行自监督学习。一个非常通用的任务是,如果模型学习的特征足够好,可以让模型区分数据集的不同样本。这被称为对比学习。
为了使事情更具体,考虑以下情况:我们从当前图像中提取的特征以及另外 K 张图像的特征。这是我们的关键特征集。现在我们设置一个分类前提任务如下:给定当前图像的特征,即查询,它属于 K + 1 个关键特征中的哪一个?这乍一看可能很琐碎,但即使对于正确类别的查询特征和关键特征之间存在完美一致,训练这个任务也鼓励查询特征在分类器输出中被分配低概率时与 K 其他图像的特征最大程度地不同。当然,还有许多细节需要填充;我们建议(有些是任意的)查看动量对比。²⁰
14.7.2 优化的训练数据
我们可以通过几种方式改进我们的训练数据。我们之前提到恶性分类实际上是基于几位放射科医生更细致的分类。通过将我们丢弃的数据转化为“恶性或非恶性?”的二分法,一个简单的方法是使用这五类。然后,放射科医生的评估可以用作平滑标签:我们可以对每个评估进行独热编码,然后对给定结节的评估进行平均。因此,如果四位放射科医生观察一个结节,其中两位称其为“不确定”,一位将同一结节称为“中度可疑”,第四位将其标记为“高度可疑”,我们将根据模型输出和目标概率分布之间的交叉熵进行训练,给定向量0 0 0.5 0.25 0.25。这类似于我们之前提到的标签平滑,但以更智能、问题特定的方式。然而,我们必须找到一种新的评估这些模型的方法,因为我们失去了在二元分类中简单的准确性、ROC 和 AUC 的概念。
利用多个评估的另一种方法是训练多个模型而不是一个,每个模型都是根据单个放射科医生给出的注释进行训练的。在推断时,我们可以通过例如平均它们的输出概率来集成模型。
在之前提到的多任务方向上,我们可以再次回到 PyLIDC 提供的注释数据,其中为每个注释提供了其他分类(微妙性、内部结构、钙化、球形度、边缘定义性、分叶、刺状和纹理 (pylidc.github.io/annotation.html))。不过,首先我们可能需要更多地了解结节。
在分割中,我们可以尝试看看 PyLIDC 提供的掩模是否比我们自己生成的掩模效果更好。由于 LIDC 数据具有多位放射科医生的注释,可以将结节分组为“高一致性”和“低一致性”组。看看这是否对应于“易”和“难”分类的结节,即看看我们的分类器是否几乎完全正确地处理所有易处理的结节,只在那些对人类专家更模糊的结节上遇到困难。或者我们可以从另一方面解决问题,通过定义结节在我们的模型性能方面的检测难度:将其分为“易”(经过一两个训练周期后正确分类)、“中”(最终正确分类)和“难”(持续错误分类)三个桶。
除了现成的数据,一个可能有意义的事情是进一步按恶性类型对结节进行分区。让专业人士更详细地检查我们的训练数据,并为每个结节标记一个癌症类型,然后强制模型报告该类型,可能会导致更有效的训练。外包这项工作的成本对于业余项目来说是高昂的,但在商业环境中支付可能是合理的。
尤其困难的情况也可能会受到人类专家的有限重复审查,以检查错误。同样,这将需要预算,但对于认真的努力来说绝对是合理的。
14.7.3 比赛结果和研究论文
我们在第 2 部分的目标是呈现从问题到解决方案的自包含路径,我们做到了。但是寻找和分类肺结节的特定问题以前已经有人研究过;因此,如果您想深入了解,您也可以看看其他人做了什么。
Data Science Bowl 2017
尽管我们将第 2 部分的范围限定在 LUNA 数据集中的 CT 扫描上,但在 Data Science Bowl 2017(www.kaggle .com/c/data-science-bowl-2017)中也有大量信息可供参考,该比赛由 Kaggle(www.kaggle.com)主办。数据本身已不再可用,但有许多人描述了对他们有效和无效的方法。例如,一些 Data Science Bowl(DSB)的决赛选手报告说,来自 LIDC 的详细恶性程度(1…5)信息在训练过程中很有用。
您可以查看的两个亮点是这些:²¹
-
第二名解决方案的撰写:Daniel Hammack 和 Julian de Wit
mng.bz/Md48 -
第九名解决方案的撰写:Team Deep Breath
mng.bz/aRAX
注意 我们之前暗示的许多新技术对 DSB 参与者尚不可用。2017 年 DSB 和本书印刷之间的三年在深度学习领域是一个漫长的时间!
一个更合理的测试集的一个想法是使用 DSB 数据集而不是重复使用我们的验证集。不幸的是,DSB 停止分享原始数据,所以除非您碰巧有旧版本的副本,否则您需要另一个数据来源。
LUNA 论文
LUNA Grand Challenge 已经收集了一些结果(luna16.grand-challenge.org/Results),显示出相当大的潜力。虽然并非所有提供的论文都包含足够的细节来重现结果,但许多论文确实包含了足够的信息来改进我们的项目。您可以查阅一些论文,并尝试复制看起来有趣的方法。
14.8 结论
本章结束了第 2 部分,并实现了我们在第九章中承诺的承诺:我们现在有一个可以尝试从 CT 扫描中诊断肺癌的工作端到端系统。回顾我们的起点,我们已经走了很长的路,希望也学到了很多。我们使用公开可用的数据训练了一个能够做出有趣且困难的事情的模型。关键问题是,“这对现实世界有好处吗?”随之而来的问题是,“这准备好投入生产了吗?”生产的定义关键取决于预期用途,因此,如果我们想知道我们的算法是否可以取代专业放射科医师,那肯定不是这种情况。我们认为这可以代表未来支持放射科医师在临床例行工作中的工具的 0.1 版本:例如,通过提供对可能被忽视的事项的第二意见。
这样的工具需要通过监管机构(如美国食品药品监督管理局)的批准,以便在研究环境之外使用。我们肯定会缺少一个广泛的、经过精心策划的数据集来进一步训练,甚至更重要的是验证我们的工作。个别案例需要在研究协议的背景下由多位专家评估;而对于各种情况的适当表达,从常见病例到边缘情况,都是必不可少的。
所有这些情况,从纯研究用途到临床验证再到临床使用,都需要我们在一个适合扩展的环境中执行我们的模型。不用说,这带来了一系列挑战,无论是技术上还是流程上。我们将在第十五章讨论一些技术挑战。
14.8.1 幕后花絮
当我们结束第二部分的建模时,我们想拉开幕布,让你一窥在深度学习项目中工作的真相。从根本上说,这本书呈现了一种偏颇的看法:一系列经过策划的障碍和机会;一个经过精心呵护的花园小径,穿过深度学习的更广阔领域。我们认为这种半有机的挑战系列(尤其是第二部分)会使这本书更好,也希望会有更好的学习体验。然而,这并不意味着会有一个更真实的体验。
很可能,你的大部分实验都不会成功。并非每个想法都会成为一个发现,也不是每个改变都会是一个突破。深度学习是棘手的。深度学习是善变的。请记住,深度学习实际上是在推动人类知识的前沿;这是我们每天都在探索和拓展的领域,就在此刻。现在是从事这个领域的激动人心的时刻,但就像大多数野外工作一样,你的靴子上总会沾上一些泥巴。
符合透明度精神,这里有一些我们尝试过的、我们遇到困难的、不起作用的,或者至少不够好以至于不值得保留的事情:
-
在分类网络中使用
HardTanh而不是Softmax(这样更容易解释,但实际上效果并不好)。 -
试图通过使分类网络更复杂(跳跃连接等)来解决
HardTanh引起的问题。 -
不良的权重初始化导致训练不稳定,特别是对于分割。
-
对完整的 CT 切片进行分割训练。
-
使用 SGD 进行分割的损失加权。这并没有起作用,需要使用 Adam 才能使其有用。
-
CT 扫描的真正三维分割。对我们来说不起作用,但 DeepMind 后来还是做到了。这是在我们转向裁剪到结节之前,我们的内存用完了,所以你可以根据当前的设置再试一次。
-
误解 LUNA 数据中
class列的含义,导致在撰写本书的过程中进行了一些重写。 -
无意中留下一个“我想快速获得结果”的技巧,导致分割模块找到的候选结节中有 80%被丢弃,直到我们弄清楚问题所在(这花了整个周末!)。
-
一系列不同的优化器、损失函数和模型架构。
-
以各种方式平衡训练数据。
我们肯定还忘记了更多。很多事情在变得正确之前都出了错!请从我们的错误中学习。
我们可能还要补充一点,对于这篇文章中的许多内容,我们只是选择了一种方法;我们强调并不意味着其他方法不如(其中许多可能更好!)。此外,编码风格和项目设计在人们之间通常有很大的不同。在机器学习中,人们经常在 Jupyter 笔记本中进行大量编程。笔记本是一个快速尝试事物的好工具,但它们也有自己的注意事项:例如,如何跟踪你所做的事情。最后,与我们之前使用的prepcache缓存机制不同,我们可以有一个单独的预处理步骤,将数据写出为序列化张量。这些方法中的每一种似乎都是一种品味;即使在三位作者中,我们中的任何一位都会略有不同地做事情。尝试事物并找出哪种方法最适合你,同时在与同事合作时保持灵活性是很好的。
14.9 练习
-
为分类实现一个测试集,或者重用第十三章练习中的测试集。在训练时使用验证集选择最佳时期,但在最终项目评估时使用测试集。验证集上的性能与测试集上的性能如何相匹配?
-
你能训练一个能够在一次传递中进行三路分类,区分非结节、良性结节和恶性结节的单一模型吗?
-
什么类平衡分割对训练效果最好?
-
与我们在书中使用的两遍方法相比,这种单遍模型的表现如何?
-
-
我们在注释上训练了我们的分类器,但期望它在我们分割的输出上表现。使用分割模型构建一个非结节的列表,用于训练,而不是提供的非结节。
-
当在这个新集合上训练时,分类模型的性能是否有所提高?
-
你能描述哪种结节候选者在新训练的模型中看到了最大的变化吗?
-
-
我们使用的填充卷积导致图像边缘附近的上下文不足。计算 CT 扫描切片边缘附近分割像素的损失,与内部的损失相比。这两者之间是否有可测量的差异?
-
尝试使用重叠的 32×48×48 块在整个 CT 上运行分类器。这与分割方法相比如何?
14.10 总结
-
训练集和验证(以及测试)集之间的明确分割至关重要。在这里,按病人分割要比其他方式更不容易出错。当您的管道中有几个模型时,这一点更为真实。
-
从像素标记到结节的转换可以通过非常传统的图像处理实现。我们不想看不起经典,但重视这些工具,并在适当的地方使用它们。
-
我们的诊断脚本同时执行分割和分类。这使我们能够诊断我们以前没有见过的 CT,尽管我们当前的
Dataset实现未配置为接受来自 LUNA 以外来源的series_uid。 -
微调是在使用最少的训练数据的情况下拟合模型的好方法。确保预训练模型具有与您的任务相关的特征,并确保重新训练具有足够容量的网络的一部分。
-
TensorBoard 允许我们编写许多不同类型的图表,帮助我们确定发生了什么。但这并不是查看我们的模型在哪些数据上表现特别糟糕的替代品。
-
成功的训练似乎在某个阶段涉及过拟合网络,然后我们对其进行正则化。我们可能也可以将其视为一种配方;我们可能应该更多地了解正则化。
-
训练神经网络是尝试事物,看看出了什么问题,然后改进它。通常没有什么灵丹妙药。
-
Kaggle 是深度学习项目创意的绝佳来源。许多新数据集为表现最佳者提供现金奖励,而旧的比赛则有可用作进一步实验起点的示例。
¹ 你也可以使用 p2_run_everything 笔记本。
² 任何给定结节的大小显然是高度可变的。
³ 我们特意选择了这个系列,因为它有一个很好的结果混合。
⁴ 查看 PyLIDC 文档以获取完整详情:mng.bz/Qyv6。
⁵ 请注意,在平衡数据集上的随机预测将导致 AUC 为 0.5,因此这为我们的分类器必须有多好提供了一个下限。
⁶ 你可以尝试使用受人尊敬的德国交通标志识别基准数据集,网址为 mng.bz/XPZ9。
⁷ 大部分延迟来自于 SciPy 对连接组件的处理。在撰写本文时,我们还不知道有加速实现。
⁸ 请记住,我们之前的“几乎没有假阳性的 75%” ROC 数字是针对恶性分类的孤立情况。在我们甚至进入恶性分类器之前,我们已经过滤掉了七个恶性结节。
⁹ 如果是这样的话,我们会选择这样做而不是写这本书!
¹⁰ 至少有一位作者很愿意在本节涉及的主题上写一本完整的书。
¹¹ 另请参阅 Andrej Karparthy 的博客文章“A Recipe for Training Neural Networks”,网址为karpathy.github .io/2019/04/25/recipe以获取更详细的配方。
¹² 你可以在mng.bz/Md5Q找到一个配方(尽管是针对 TensorFlow 的)。
¹³ 你可以使用nn.KLDivLoss损失函数。
¹⁴Hongyi Zhang 等人,“mixup:超越经验风险最小化”,arxiv.org/abs/1710.09412。
¹⁵ 请参阅 Ferenc Huszár 在mng.bz/aRJj/发布的文章;他还提供了 PyTorch 代码。
¹⁶ 我们可能会将其扩展为纯贝叶斯,但我们只会使用这一点直觉。
¹⁷Pavel Izmailov 和 Andrew Gordon Wilson 在mng.bz/gywe提供了一个 PyTorch 代码的介绍。
¹⁸ 请参阅 Sebastian Ruder,“深度神经网络中多任务学习概述”,arxiv.org/ abs/1706.05098;但这也是许多领域的关键思想。
¹⁹Q. Xie 等人,“无监督数据增强用于一致性训练”,arxiv.org/abs/ 1904.12848。
²⁰K. He 等人,“动量对比用于无监督视觉表示学习”,arxiv.org/ abs/1911.05722。
²¹ 感谢互联网档案馆将它们从重新设计中保存下来。
²²Stanislav Nikolov 等人,“用于放射治疗头颈解剖学临床适用分割的深度学习”,arxiv.org/pdf/1809.04430.pdf
²³ 哦,我们进行过的讨论!
第三部分:部署
*在第三部分中,我们将看看如何使我们的模型达到可以使用的程度。我们在前几部分中看到了如何构建模型:第一部分介绍了模型的构建和训练,第二部分从头到尾详细介绍了一个示例,所以辛苦的工作已经完成了。
但是在你真正能够使用模型之前,没有任何模型是有用的。因此,现在我们需要将模型投入使用,并将其应用于它们设计解决的任务。这部分在精神上更接近第一部分,因为它介绍了许多 PyTorch 组件。与以往一样,我们将专注于我们希望解决的应用和任务,而不仅仅是为了看 PyTorch 本身。
在第三部分的单一章节中,我们将了解 2020 年初的 PyTorch 部署情况。我们将了解并使用 PyTorch 即时编译器(JIT)将模型导出以供第三方应用程序使用,以及用于移动支持的 C++ API。
十五、部署到生产环境
本章涵盖内容
-
部署 PyTorch 模型的选项
-
使用 PyTorch JIT
-
部署模型服务器和导出模型
-
在 C++中运行导出和本地实现的模型
-
在移动设备上运行模型
在本书的第一部分,我们学到了很多关于模型的知识;第二部分为我们提供了创建特定问题的好模型的详细路径。现在我们有了这些优秀的模型,我们需要将它们带到可以发挥作用的地方。在规模化执行深度学习模型推理的基础设施维护方面,从架构和成本的角度来看都具有影响力。虽然 PyTorch 最初是一个专注于研究的框架,但从 1.0 版本开始,添加了一组面向生产的功能,使 PyTorch 成为从研究到大规模生产的理想端到端平台。
部署到生产环境意味着会根据用例而有所不同:
-
我们在第二部分开发的模型可能最自然的部署方式是建立一个网络服务,提供对我们模型的访问。我们将使用轻量级的 Python Web 框架来实现这一点:Flask (
flask.pocoo.org) 和 Sanic (sanicframework.org)。前者可以说是这些框架中最受欢迎的之一,后者在精神上类似,但利用了 Python 的新的异步操作支持 async/await 来提高效率。 -
我们可以将我们的模型导出为一个标准化的格式,允许我们使用优化的模型处理器、专门的硬件或云服务进行部署。对于 PyTorch 模型,Open Neural Network Exchange (ONNX)格式起到了这样的作用。
-
我们可能希望将我们的模型集成到更大的应用程序中。为此,如果我们不受 Python 的限制将会很方便。因此,我们将探讨使用 PyTorch 模型从 C++中使用的想法,这也是通往任何语言的一个过渡。
-
最后,对于一些像我们在第二章中看到的图像斑马化这样的事情,可能很好地在移动设备上运行我们的模型。虽然你不太可能在手机上有一个 CT 模块,但其他医疗应用程序如自助皮肤检查可能更自然,用户可能更喜欢在设备上运行而不是将他们的皮肤发送到云服务。幸运的是,PyTorch 最近增加了移动支持,我们将探索这一点。
当我们学习如何实现这些用例时,我们将以第十四章的分类器作为我们提供服务的第一个示例,然后切换到斑马化模型处理其他部署的内容。
15.1 提供 PyTorch 模型
我们将从将模型放在服务器上需要做什么开始。忠于我们的实践方法,我们将从最简单的服务器开始。一旦我们有了基本的工作内容,我们将看看它的不足之处,并尝试解决。最后,我们将看看在撰写本文时的未来。让我们创建一个监听网络的东西。¹
15.1.1 我们的模型在 Flask 服务器后面
Flask 是最广泛使用的 Python 模块之一。可以使用pip进行安装:²
pip install Flask
API 可以通过装饰函数创建。
列表 15.1 flask_hello_world.py:1
from flask import Flask
app = Flask(__name__)@app.route("/hello")
def hello():return "Hello World!"if __name__ == '__main__':app.run(host='0.0.0.0', port=8000)
应用程序启动后将在端口 8000 上运行,并公开一个路由/hello,返回“Hello World”字符串。此时,我们可以通过加载先前保存的模型并通过POST路由公开它来增强我们的 Flask 服务器。我们将以第十四章的模块分类器为例。
我们将使用 Flask 的(有点奇怪地导入的)request来获取我们的数据。更准确地说,request.files 包含一个按字段名称索引的文件对象字典。我们将使用 JSON 来解析输入,并使用 flask 的jsonify助手返回一个 JSON 字符串。
现在,我们将暴露一个/predict 路由,该路由接受一个二进制块(系列的像素内容)和相关的元数据(包含一个以shape为键的字典的 JSON 对象)作为POST请求提供的输入文件,并返回一个 JSON 响应,其中包含预测的诊断。更确切地说,我们的服务器接受一个样本(而不是一批),并返回它是恶性的概率。
为了获取数据,我们首先需要将 JSON 解码为二进制,然后使用numpy.frombuffer将其解码为一维数组。我们将使用torch.from_numpy将其转换为张量,并查看其实际形状。
模型的实际处理方式就像第十四章中一样:我们将从第十四章实例化LunaModel,加载我们从训练中得到的权重,并将模型置于eval模式。由于我们不进行训练任何东西,我们会在with torch.no_grad()块中告诉 PyTorch 在运行模型时不需要梯度。
列表 15.2 flask_server.py:1
import numpy as np
import sys
import os
import torch
from flask import Flask, request, jsonify
import jsonfrom p2ch13.model_cls import LunaModelapp = Flask(__name__)model = LunaModel() # ❶
model.load_state_dict(torch.load(sys.argv[1],map_location='cpu')['model_state'])
model.eval()def run_inference(in_tensor):with torch.no_grad(): # ❷# LunaModel takes a batch and outputs a tuple (scores, probs)out_tensor = model(in_tensor.unsqueeze(0))[1].squeeze(0)probs = out_tensor.tolist()out = {'prob_malignant': probs[1]}return out@app.route("/predict", methods=["POST"]) # ❸
def predict():meta = json.load(request.files['meta']) # ❹blob = request.files['blob'].read()in_tensor = torch.from_numpy(np.frombuffer(blob, dtype=np.float32)) # ❺in_tensor = in_tensor.view(*meta['shape'])out = run_inference(in_tensor)return jsonify(out) # ❻if __name__ == '__main__':app.run(host='0.0.0.0', port=8000)print (sys.argv[1])
❶ 设置我们的模型,加载权重,并转换为评估模式
❷ 对我们来说没有自动求导。
❸ 我们期望在“/predict”端点进行表单提交(HTTP POST)。
❹ 我们的请求将有一个名为 meta 的文件。
❺ 将我们的数据从二进制块转换为 torch
❻ 将我们的响应内容编码为 JSON
运行服务器的方法如下:
python3 -m p3ch15.flask_server data/part2/models/cls_2019-10-19_15.48.24_final_cls.best.state
我们在 cls_client.py 中准备了一个简单的客户端,发送一个示例。从代码目录中,您可以运行它如下:
python3 p3ch15/cls_client.py
它应该告诉您结节极不可能是恶性的。显然,我们的服务器接受输入,通过我们的模型运行它们,并返回输出。那我们完成了吗?还不完全。让我们看看下一节中可以改进的地方。
15.1.2 部署的期望
让我们收集一些为提供模型服务而期望的事情。首先,我们希望支持现代协议及其特性。老式的 HTTP 是深度串行的,这意味着当客户端想要在同一连接中发送多个请求时,下一个请求只会在前一个请求得到回答后才会发送。如果您想发送一批东西,这并不是很有效。我们在这里部分交付–我们升级到 Sanic 肯定会使我们转向一个有雄心成为非常高效的框架。
在使用 GPU 时,批量请求通常比逐个处理或并行处理更有效。因此,接下来,我们的任务是从几个连接收集请求,将它们组装成一个批次在 GPU 上运行,然后将结果返回给各自的请求者。这听起来很复杂,(再次,当我们编写这篇文章时)似乎在简单的教程中并不经常做。这足以让我们在这里正确地做。但请注意,直到由模型运行持续时间引起的延迟成为问题(在等待我们自己的运行时是可以的;但在请求到达时等待正在运行的批次完成,然后等待我们的运行给出结果是禁止的),在给定时间内在一个 GPU 上运行多个批次没有太多理由。增加最大批量大小通常更有效。
我们希望并行提供几件事情。即使使用异步提供服务,我们也需要我们的模型在第二个线程上高效运行–这意味着我们希望通过我们的模型摆脱(臭名昭著的)Python 全局解释器锁(GIL)。
我们还希望尽量减少复制。无论从内存消耗还是时间的角度来看,反复复制东西都是不好的。许多 HTTP 事物都是以 Base64 编码(一种将二进制编码为更多或更少字母数字字符串的格式,每字节限制为 6 位)的形式编码的,比如,对于图像,将其解码为二进制,然后再转换为张量,然后再转换为批处理显然是相对昂贵的。我们将部分实现这一点——我们将使用流式PUT请求来避免分配 Base64 字符串,并避免通过逐渐追加到字符串来增长字符串(对于字符串和张量来说,这对性能非常糟糕)。我们说我们没有完全实现,因为我们并没有真正最小化复制。
为了提供服务,最后一个理想的事情是安全性。理想情况下,我们希望有安全的解码。我们希望防止溢出和资源耗尽。一旦我们有了固定大小的输入张量,我们应该大部分都没问题,因为从固定大小的输入开始很难使 PyTorch 崩溃。为了达到这个目标,解码图像等工作可能更令人头疼,我们不做任何保证。互联网安全是一个足够庞大的领域,我们将完全不涉及它。我们应该注意到神经网络容易受到输入操纵以生成期望但错误或意想不到的输出(称为对抗性示例),但这与我们的应用并不是非常相关,所以我们会在这里跳过它。
言归正传。让我们改进一下我们的服务器。
15.1.3 请求批处理
我们的第二个示例服务器将使用 Sanic 框架(通过同名的 Python 包安装)。这将使我们能够使用异步处理来并行处理许多请求,因此我们将在列表中勾选它。顺便说一句,我们还将实现请求批处理。
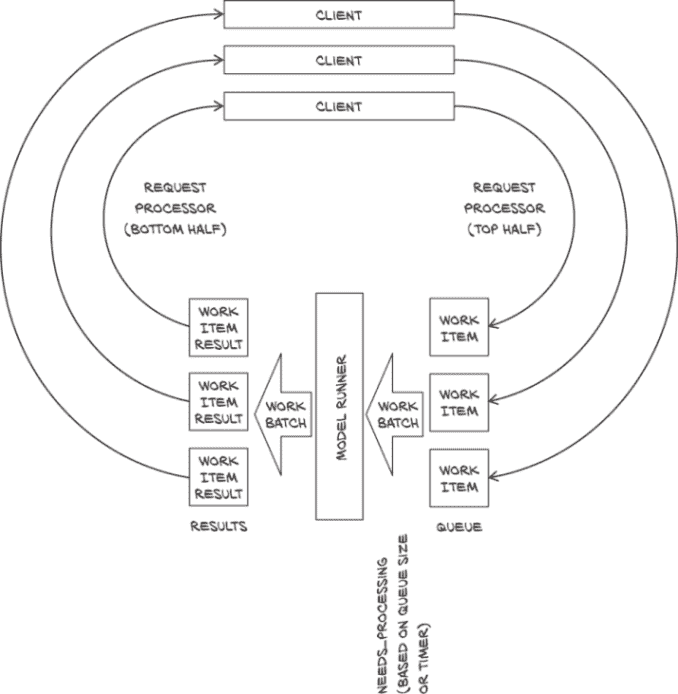
图 15.1 请求批处理的数据流
异步编程听起来可能很可怕,并且通常伴随着大量术语。但我们在这里所做的只是允许函数非阻塞地等待计算或事件的结果。
为了进行请求批处理,我们必须将请求处理与运行模型分离。图 15.1 显示了数据的流动。
在图 15.1 的顶部是客户端,发出请求。这些一个接一个地通过请求处理器的上半部分。它们导致工作项与请求信息一起入队。当已经排队了一个完整的批次或最老的请求等待了指定的最长时间时,模型运行器会从队列中取出一批,处理它,并将结果附加到工作项上。然后这些工作项一个接一个地由请求处理器的下半部分处理。
实现
我们通过编写两个函数来实现这一点。模型运行函数从头开始运行并永远运行。每当需要运行模型时,它会组装一批输入,在第二个线程中运行模型(以便其他事情可以发生),然后返回结果。
请求处理器然后解码请求,将输入加入队列,等待处理完成,并返回带有结果的输出。为了理解这里异步的含义,可以将模型运行器视为废纸篓。我们为本章所涂鸦的所有图纸都可以快速地放在桌子右侧的垃圾桶里处理掉。但是偶尔——无论是因为篮子已满还是因为到了晚上清理的时候——我们需要将所有收集的纸张拿出去扔到垃圾桶里。类似地,我们将新请求加入队列,如果需要则触发处理,并在发送结果作为请求答复之前等待结果。图 15.2 展示了我们在执行的两个函数块之前无间断执行的情况。
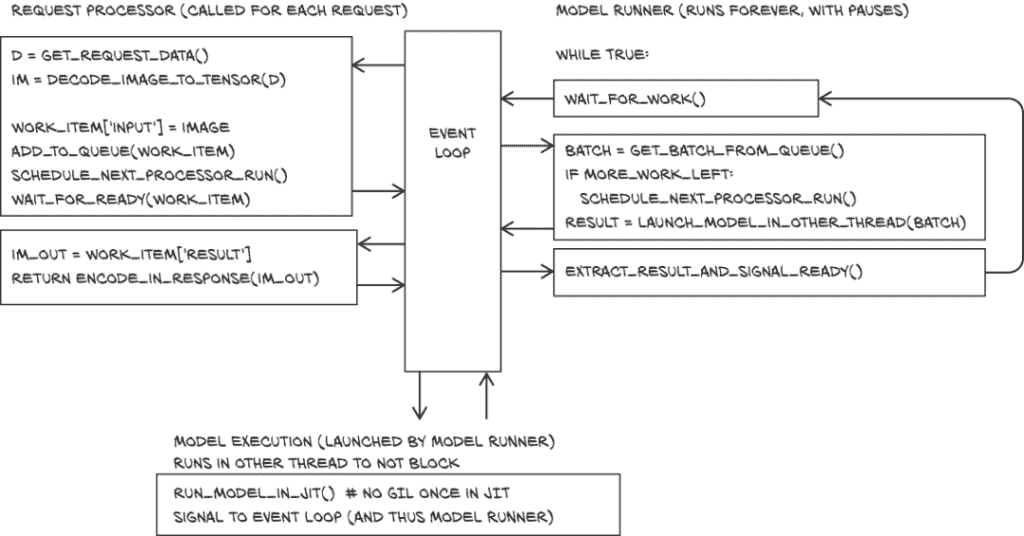
图 15.2 我们的异步服务器由三个模块组成:请求处理器、模型运行器和模型执行。这些模块有点像函数,但前两个在中间会让出事件循环。
相对于这个图片,一个轻微的复杂性是我们有两个需要处理事件的场合:如果我们积累了一个完整的批次,我们立即开始;当最老的请求达到最大等待时间时,我们也想运行。我们通过为后者设置一个定时器来解决这个问题。⁵
所有我们感兴趣的代码都在一个ModelRunner类中,如下列表所示。
列表 15.3 request_batching_server.py:32, ModelRunner
class ModelRunner:def __init__(self, model_name):self.model_name = model_nameself.queue = [] # ❶self.queue_lock = None # ❷self.model = get_pretrained_model(self.model_name,map_location=device) # ❸self.needs_processing = None # ❹self.needs_processing_timer = None # ❺
❶ 队列
❷ 这将成为我们的锁。
❸ 加载并实例化模型。这是我们将需要更改以切换到 JIT 的(唯一)事情。目前,我们从 p3ch15/cyclegan.py 导入 CycleGAN(稍微修改为标准化为 0…1 的输入和输出)。
❹ 我们运行模型的信号
❺ 最后,定时器
ModelRunner 首先加载我们的模型并处理一些管理事务。除了模型,我们还需要一些其他要素。我们将请求输入到一个queue中。这只是一个 Python 列表,我们在后面添加工作项,然后在前面删除它们。
当我们修改queue时,我们希望防止其他任务在我们下面更改队列。为此,我们引入了一个queue_lock,它将是由asyncio模块提供的asyncio.Lock。由于我们在这里使用的所有asyncio对象都需要知道事件循环,而事件循环只有在我们初始化应用程序后才可用,因此我们在实例化时将其临时设置为None。尽管像这样锁定可能并不是绝对必要的,因为我们的方法在持有锁时不会返回事件循环,并且由于 GIL 的原因,对队列的操作是原子的,但它确实明确地编码了我们的基本假设。如果我们有多个工作进程,我们需要考虑加锁。一个警告:Python 的异步锁不是线程安全的。(叹气。)
ModelRunner 在没有任务时等待。我们需要从RequestProcessor向其发出信号,告诉它停止偷懒,开始工作。这通过名为needs_processing的asyncio.Event完成。ModelRunner使用wait()方法等待needs_processing事件。然后,RequestProcessor使用set()来发出信号,ModelRunner会被唤醒并清除事件。
最后,我们需要一个定时器来保证最大等待时间。当我们需要时,通过使用app.loop.call_at来创建此定时器。它设置needs_processing事件;我们现在只是保留一个插槽。因此,实际上,有时事件将直接被设置,因为一个批次已经完成,或者当定时器到期时。当我们在定时器到期之前处理一个批次时,我们将清除它,以便不做太多的工作。
从请求到队列
接下来,我们需要能够将请求加入队列,这是图 15.2 中RequestProcessor的第一部分的核心(不包括解码和重新编码)。我们在我们的第一个async方法process_input中完成这个操作。
列表 15.4 request_batching_server.py:54
async def process_input(self, input):our_task = {"done_event": asyncio.Event(loop=app.loop), # ❶"input": input,"time": app.loop.time()}async with self.queue_lock: # ❷if len(self.queue) >= MAX_QUEUE_SIZE:raise HandlingError("I'm too busy", code=503)self.queue.append(our_task)self.schedule_processing_if_needed() # ❸await our_task["done_event"].wait() # ❹return our_task["output"]
❶ 设置任务数据
❷ 使用锁,我们添加我们的任务和…
❸ …安排处理。处理将设置needs_processing,如果我们有一个完整的批次。如果我们没有,并且没有设置定时器,它将在最大等待时间到达时设置一个定时器。
❹ 等待(并使用 await 将控制权交还给循环)处理完成。
我们设置一个小的 Python 字典来保存我们任务的信息:当然是input,任务被排队的time,以及在任务被处理后将被设置的done_event。处理会添加一个output。
持有队列锁(方便地在async with块中完成),我们将我们的任务添加到队列中,并在需要时安排处理。作为预防措施,如果队列变得太大,我们会报错。然后,我们只需等待我们的任务被处理,并返回它。
注意 使用循环时间(通常是单调时钟)非常重要,这可能与time.time()不同。否则,我们可能会在排队之前为处理安排事件,或者根本不进行处理。
这就是我们处理请求所需的一切(除了解码和编码)。
从队列中运行批处理
接下来,让我们看一下图 15.2 右侧的model_runner函数,它执行模型调用。
列表 15.5 request_batching_server.py:71,.run_model
async def model_runner(self):self.queue_lock = asyncio.Lock(loop=app.loop)self.needs_processing = asyncio.Event(loop=app.loop)while True:await self.needs_processing.wait() # ❶self.needs_processing.clear()if self.needs_processing_timer is not None: # ❷self.needs_processing_timer.cancel()self.needs_processing_timer = Noneasync with self.queue_lock:# ... line 87to_process = self.queue[:MAX_BATCH_SIZE] # ❸del self.queue[:len(to_process)]self.schedule_processing_if_needed()batch = torch.stack([t["input"] for t in to_process], dim=0)# we could delete inputs here...result = await app.loop.run_in_executor(None, functools.partial(self.run_model, batch) # ❹)for t, r in zip(to_process, result): # ❺t["output"] = rt["done_event"].set()del to_process
❶ 等待有事情要做
❷ 如果设置了定时器,则取消定时器
❸ 获取一个批次并安排下一个批次的运行(如果需要)
❹ 在单独的线程中运行模型,将数据移动到设备,然后交给模型处理。处理完成后我们继续进行处理。
❺ 将结果添加到工作项中并设置准备事件
如图 15.2 所示,model_runner进行一些设置,然后无限循环(但在之间让出事件循环)。它在应用程序实例化时被调用,因此它可以设置我们之前讨论过的queue_lock和needs_processing事件。然后它进入循环,等待needs_processing事件。
当事件发生时,首先我们检查是否设置了时间,如果设置了,就清除它,因为我们现在要处理事情了。然后model_runner从队列中获取一个批次,如果需要的话,安排下一个批次的处理。它从各个任务中组装批次,并启动一个使用asyncio的app.loop.run_in_executor评估模型的新线程。最后,它将输出添加到任务中并设置done_event。
基本上就是这样。Web 框架–大致看起来像是带有async和await的 Flask–需要一个小包装器。我们需要在事件循环中启动model_runner函数。正如之前提到的,如果我们没有多个运行程序从队列中取出并可能相互中断,那么锁定队列就不是必要的,但是考虑到我们的代码将被适应到其他项目,我们选择保守一点,以免丢失请求。
我们通过以下方式启动我们的服务器
python3 -m p3ch15.request_batching_server data/p1ch2/horse2zebra_0.4.0.pth
现在我们可以通过上传图像数据/p1ch2/horse.jpg 进行测试并保存结果:
curl -T data/p1ch2/horse.jpg http://localhost:8000/image --output /tmp/res.jpg
请注意,这个服务器确实做了一些正确的事情–它为 GPU 批处理请求并异步运行–但我们仍然使用 Python 模式,因此 GIL 阻碍了我们在主线程中并行运行模型以响应请求。在潜在的敌对环境(如互联网)中,这是不安全的。特别是,请求数据的解码似乎既不是速度最优也不是完全安全的。
一般来说,如果我们可以进行解码,那将会更好,我们将请求流传递给一个函数,同时传递一个预分配的内存块,函数将从流中为我们解码图像。但我们不知道有哪个库是这样做的。
15.2 导出模型
到目前为止,我们已经从 Python 解释器中使用了 PyTorch。但这并不总是理想的:GIL 仍然可能阻塞我们改进的 Web 服务器。或者我们可能希望在 Python 过于昂贵或不可用的嵌入式系统上运行。这就是我们导出模型的时候。我们可以以几种方式进行操作。我们可能完全放弃 PyTorch 转向更专业的框架。或者我们可能留在 PyTorch 生态系统内部并使用 JIT,这是 PyTorch 专用 Python 子集的即时编译器。即使我们在 Python 中运行 JIT 模型,我们可能也追求其中的两个优势:有时 JIT 可以实现巧妙的优化,或者–就像我们的 Web 服务器一样–我们只是想摆脱 GIL,而 JIT 模型可以做到。最后(但我们需要一些时间才能到达那里),我们可能在libtorch下运行我们的模型,这是 PyTorch 提供的 C++ 库,或者使用衍生的 Torch Mobile。
15.2.1 与 ONNX 一起实现跨 PyTorch 的互操作性
有时,我们希望带着手头的模型离开 PyTorch 生态系统–例如,为了在具有专门模型部署流程的嵌入式硬件上运行。为此,Open Neural Network Exchange 提供了一个用于神经网络和机器学习模型的互操作格式(onnx.ai)。一旦导出,模型可以使用任何兼容 ONNX 的运行时执行,例如 ONNX Runtime,⁶前提是我们模型中使用的操作得到 ONNX 标准和目标运行时的支持。例如,在树莓派上比直接运行 PyTorch 要快得多。除了传统硬件外,许多专门的 AI 加速器硬件都支持 ONNX(onnx.ai/supported-tools .html#deployModel)。
从某种意义上说,深度学习模型是一个具有非常特定指令集的程序,由矩阵乘法、卷积、relu、tanh等粒度操作组成。因此,如果我们可以序列化计算,我们可以在另一个理解其低级操作的运行时中重新执行它。ONNX 是描述这些操作及其参数的格式的标准化。
大多数现代深度学习框架支持将它们的计算序列化为 ONNX,其中一些可以加载 ONNX 文件并执行它(尽管 PyTorch 不支持)。一些低占用量(“边缘”)设备接受 ONNX 文件作为输入,并为特定设备生成低级指令。一些云计算提供商现在可以上传 ONNX 文件并通过 REST 端点查看其暴露。
要将模型导出到 ONNX,我们需要使用虚拟输入运行模型:输入张量的值并不重要;重要的是它们具有正确的形状和类型。通过调用torch.onnx.export函数,PyTorch 将跟踪模型执行的计算,并将其序列化为一个带有提供的名称的 ONNX 文件:
torch.onnx.export(seg_model, dummy_input, "seg_model.onnx")
生成的 ONNX 文件现在可以在运行时运行,编译到边缘设备,或上传到云服务。在安装onnxruntime或onnxruntime-gpu并将batch作为 NumPy 数组获取后,可以从 Python 中使用它。
代码清单 15.6 onnx_example.py
import onnxruntimesess = onnxruntime.InferenceSession("seg_model.onnx") # ❶
input_name = sess.get_inputs()[0].name
pred_onnx, = sess.run(None, {input_name: batch})
❶ ONNX 运行时 API 使用会话来定义模型,然后使用一组命名输入调用运行方法。这在处理静态图中定义的计算时是一种典型的设置。
并非所有 TorchScript 运算符都可以表示为标准化的 ONNX 运算符。如果导出与 ONNX 不兼容的操作,当我们尝试使用运行时时,将会出现有关未知aten运算符的错误。
15.2.2 PyTorch 自己的导出:跟踪
当互操作性不是关键,但我们需要摆脱 Python GIL 或以其他方式导出我们的网络时,我们可以使用 PyTorch 自己的表示,称为TorchScript 图。我们将在下一节中看到这是什么,以及生成它的 JIT 如何工作。但现在就让我们试一试。
制作 TorchScript 模型的最简单方法是对其进行跟踪。这看起来与 ONNX 导出完全相同。这并不奇怪,因为在幕后 ONNX 模型也使用了这种方法。在这里,我们只需使用torch.jit.trace函数将虚拟输入馈送到模型中。我们从第十三章导入UNetWrapper,加载训练参数,并将模型置于评估模式。
在我们追踪模型之前,有一个额外的注意事项:任何参数都不应该需要梯度,因为使用torch.no_grad()上下文管理器严格来说是一个运行时开关。即使我们在no_grad内部追踪模型,然后在外部运行,PyTorch 仍会记录梯度。如果我们提前看一眼图 15.4,我们就会明白为什么:在模型被追踪之后,我们要求 PyTorch 执行它。但是在执行记录的操作时,追踪的模型将需要梯度的参数,并且会使所有内容都需要梯度。为了避免这种情况,我们必须在torch.no_grad上下文中运行追踪的模型。为了避免这种情况–根据经验,很容易忘记然后对性能的缺乏感到惊讶–我们循环遍历模型参数并将它们全部设置为不需要梯度。
但我们只需要调用torch.jit.trace。
列出 15.7 trace_example.py
import torch
from p2ch13.model_seg import UNetWrapperseg_dict = torch.load('data-unversioned/part2/models/p2ch13/seg_2019-10-20_15.57.21_none.best.state', map_location='cpu')
seg_model = UNetWrapper(in_channels=8, n_classes=1, depth=4, wf=3, padding=True, batch_norm=True, up_mode='upconv')
seg_model.load_state_dict(seg_dict['model_state'])
seg_model.eval()
for p in seg_model.parameters(): # ❶p.requires_grad_(False)dummy_input = torch.randn(1, 8, 512, 512)
traced_seg_model = torch.jit.trace(seg_model, dummy_input) # ❷
❶ 将参数设置为不需要梯度
❷ 追踪
追踪给我们一个警告:
TracerWarning: Converting a tensor to a Python index might cause the trace
to be incorrect. We can't record the data flow of Python values, so this
value will be treated as a constant in the future. This means the trace
might not generalize to other inputs!return layer[:, :, diff_y:(diff_y + target_size[0]), diff_x:(diff_x + target_size[1])]
这源自我们在 U-Net 中进行的裁剪,但只要我们计划将大小为 512 × 512 的图像馈送到模型中,我们就没问题。在下一节中,我们将更仔细地看看是什么导致了警告,以及如何避开它突出的限制(如果需要的话)。当我们想要将比卷积网络和 U-Net 更复杂的模型转换为 TorchScript 时,这也将很重要。
我们可以保存追踪的模型
torch.jit.save(traced_seg_model, 'traced_seg_model.pt')
然后加载回来而不需要任何东西,然后我们可以调用它:
loaded_model = torch.jit.load('traced_seg_model.pt')
prediction = loaded_model(batch)
PyTorch JIT 将保留我们保存模型时的状态:我们已经将其置于评估模式,并且我们的参数不需要梯度。如果我们之前没有注意到这一点,我们将需要在执行中使用with torch.no_grad():。
提示 您可以运行 JIT 编译并导出的 PyTorch 模型而不保留源代码。但是,我们总是希望建立一个工作流程,自动从源模型转换为已安装的 JIT 模型以进行部署。如果不这样做,我们将发现自己处于这样一种情况:我们想要调整模型的某些内容,但已经失去了修改和重新生成的能力。永远保留源代码,卢克!
15.2.3 带有追踪模型的服务器
现在是时候将我们的网络服务器迭代到这种情况下的最终版本了。我们可以将追踪的 CycleGAN 模型导出如下:
python3 p3ch15/cyclegan.py data/p1ch2/horse2zebra_0.4.0.pth data/p3ch15/traced_zebra_model.pt
现在我们只需要在服务器中用torch.jit.load替换对get_pretrained_model的调用(并删除现在不再需要的import get_pretrained_model)。这也意味着我们的模型独立于 GIL 运行–这正是我们希望我们的服务器在这里实现的。为了您的方便,我们已经将小的修改放在 request_batching_jit_server.py 中。我们可以用追踪的模型文件路径作为命令行参数来运行它。
现在我们已经尝试了 JIT 对我们有什么帮助,让我们深入了解细节吧!
15.3 与 PyTorch JIT 交互
在 PyTorch 1.0 中首次亮相,PyTorch JIT 处于围绕 PyTorch 的许多最新创新的中心,其中之一是提供丰富的部署选项。
15.3.1 超越经典 Python/PyTorch 时可以期待什么
经常有人说 Python 缺乏速度。虽然这有一定道理,但我们在 PyTorch 中使用的张量操作通常本身足够大,以至于它们之间的 Python 速度慢并不是一个大问题。对于像智能手机这样的小设备,Python 带来的内存开销可能更重要。因此,请记住,通常通过将 Python 排除在计算之外来加快速度的提升是 10% 或更少。
另一个不在 Python 中运行模型的即时加速仅在多线程环境中出现,但这时它可能是显著的:因为中间结果不是 Python 对象,计算不受所有 Python 并行化的威胁,即 GIL。这是我们之前考虑到的,并且当我们在服务器上使用跟踪模型时实现了这一点。
从经典的 PyTorch 执行一项操作后再查看下一项的方式转变过来,确实让 PyTorch 能够全面考虑计算:也就是说,它可以将计算作为一个整体来考虑。这为关键的优化和更高级别的转换打开了大门。其中一些主要适用于推断,而其他一些也可以在训练中提供显著的加速。
让我们通过一个快速示例来让你体会一下为什么一次查看多个操作会有益。当 PyTorch 在 GPU 上运行一系列操作时,它为每个操作调用一个子程序(在 CUDA 术语中称为内核)。每个内核从 GPU 内存中读取输入,计算结果,然后存储结果。因此,大部分时间通常不是用于计算,而是用于读取和写入内存。这可以通过仅读取一次,计算多个操作,然后在最后写入来改进。这正是 PyTorch JIT 融合器所做的。为了让你了解这是如何工作的,图 15.3 展示了长短期记忆(LSTM;en.wikipedia.org/wiki/ Long_short-term_memory)单元中进行的逐点计算,这是递归网络的流行构建块。
图 15.3 的细节对我们来说并不重要,但顶部有 5 个输入,底部有 2 个输出,中间有 7 个圆角指数表示的中间结果。通过在一个单独的 CUDA 函数中一次性计算所有这些,并将中间结果保留在寄存器中,JIT 将内存读取次数从 12 降低到 5,写入次数从 9 降低到 2。这就是 JIT 带来的巨大收益;它可以将训练 LSTM 网络的时间缩短四倍。这看似简单的技巧使得 PyTorch 能够显著缩小 LSTM 和在 PyTorch 中灵活定义的通用 LSTM 单元与像 cuDNN 这样提供的高度优化 LSTM 实现之间速度差距。
总之,使用 JIT 来避免 Python 的加速并不像我们可能天真地期望的那样大,因为我们被告知 Python 非常慢,但避免 GIL 对于多线程应用程序来说是一个重大胜利。JIT 模型的大幅加速来自 JIT 可以实现的特殊优化,但这些优化比仅仅避免 Python 开销更为复杂。

图 15.3 LSTM 单元逐点操作。从顶部的五个输入,该块计算出底部的两个输出。中间的方框是中间结果,普通的 PyTorch 会将其存储在内存中,但 JIT 融合器只会保留在寄存器中。
15.3.2 PyTorch 作为接口和后端的双重性质
要理解如何摆脱 Python 的工作原理,有益的是在头脑中将 PyTorch 分为几个部分。我们在第 1.4 节中初步看到了这一点。我们的 PyTorch torch.nn 模块–我们在第六章首次看到它们,自那以后一直是我们建模的主要工具–保存网络的参数,并使用功能接口实现:接受和返回张量的函数。这些被实现为 C++ 扩展,交给了 C++ 级别的自动求导启用层。 (然后将实际计算交给一个名为 ATen 的内部库,执行计算或依赖后端来执行,但这不重要。)
鉴于 C++ 函数已经存在,PyTorch 开发人员将它们制作成了官方 API。这就是 LibTorch 的核心,它允许我们编写几乎与其 Python 对应物相似的 C++ 张量操作。由于torch.nn模块本质上只能在 Python 中使用,C++ API 在一个名为torch::nn的命名空间中镜像它们,设计上看起来很像 Python 部分,但是独立的。
这将使我们能够在 C++ 中重新做我们在 Python 中做的事情。但这不是我们想要的:我们想要导出模型。幸运的是,PyTorch 还提供了另一个接口来访问相同的函数:PyTorch JIT。PyTorch JIT 提供了计算的“符号”表示。这个表示是TorchScript 中间表示(TorchScript IR,有时只是 TorchScript)。我们在第 15.2.2 节讨论延迟计算时提到了 TorchScript。在接下来的章节中,我们将看到如何获取我们 Python 模型的这种表示以及如何保存、加载和执行它们。与我们讨论常规 PyTorch API 时所述类似,PyTorch JIT 函数用于加载、检查和执行 TorchScript 模块也可以从 Python 和 C++ 中访问。
总结一下,我们有四种调用 PyTorch 函数的方式,如图 15.4 所示:从 C++ 和 Python 中,我们可以直接调用函数,也可以让 JIT 充当中介。所有这些最终都会调用 C++ 的 LibTorch 函数,从那里进入 ATen 和计算后端。
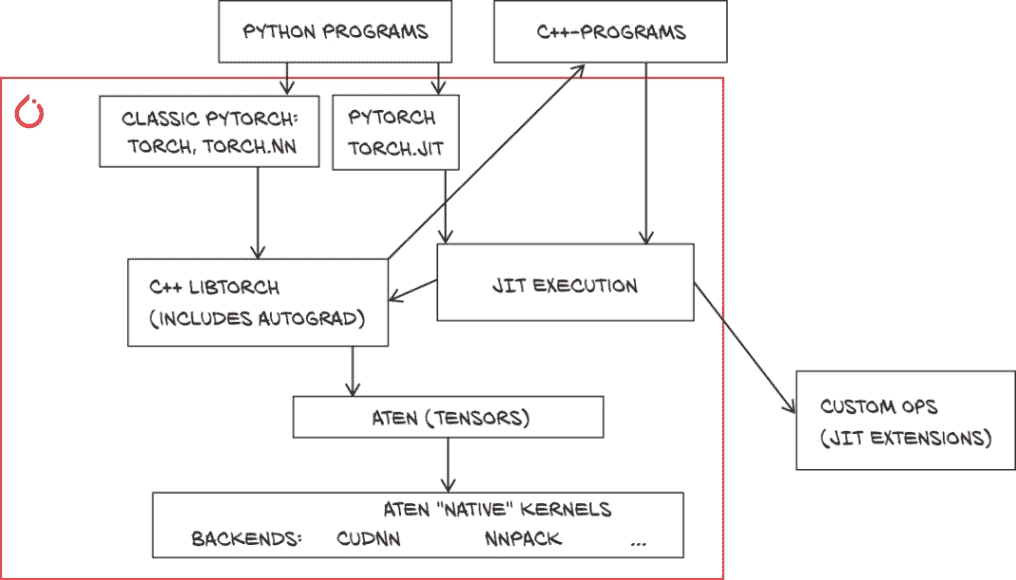
图 15.4 调用 PyTorch 的多种方式
15.3.3 TorchScript
TorchScript 是 PyTorch 设想的部署选项的核心。因此,值得仔细研究它的工作原理。
创建 TorchScript 模型有两种简单直接的方式:追踪和脚本化。我们将在接下来的章节中分别介绍它们。在非常高的层面上,这两种方式的工作原理如下:
在追踪中,我们在第 15.2.2 节中使用过,使用样本(随机)输入执行我们通常的 PyTorch 模型。PyTorch JIT 对每个函数都有钩子(在 C++ autograd 接口中),允许它记录计算过程。在某种程度上,这就像在说“看我如何计算输出–现在你也可以这样做。”鉴于 JIT 仅在调用 PyTorch 函数(以及nn.Module)时才起作用,你可以在追踪时运行任何 Python 代码,但 JIT 只会注意到那些部分(尤其是对控制流一无所知)。当我们使用张量形状–通常是整数元组–时,JIT 会尝试跟踪发生的情况,但可能不得不放弃。这就是在追踪 U-Net 时给我们警告的原因。
在脚本化中,PyTorch JIT 查看我们计算的实际 Python 代码,并将其编译成 TorchScript IR。这意味着,虽然我们可以确保 JIT 捕获了程序的每个方面,但我们受限于编译器理解的部分。这就像在说“我告诉你如何做–现在你也这样做。”听起来真的像编程。
我们不是来讨论理论的,所以让我们尝试使用一个非常简单的函数进行追踪和脚本化,该函数在第一维上进行低效的加法:
# In[2]:
def myfn(x):y = x[0]for i in range(1, x.size(0)):y = y + x[i]return y
我们可以追踪它:
# In[3]:
inp = torch.randn(5,5)
traced_fn = torch.jit.trace(myfn, inp)
print(traced_fn.code)# Out[3]:
def myfn(x: Tensor) -> Tensor:y = torch.select(x, 0, 0) # ❶y0 = torch.add(y, torch.select(x, 0, 1), alpha=1) # ❷y1 = torch.add(y0, torch.select(x, 0, 2), alpha=1)y2 = torch.add(y1, torch.select(x, 0, 3), alpha=1)_0 = torch.add(y2, torch.select(x, 0, 4), alpha=1)return _0TracerWarning: Converting a tensor to a Python index might cause the trace # ❸
to be incorrect. We can't record the data flow of Python values, so this
value will be treated as a constant in the future. This means the
trace might not generalize to other inputs!
❶ 在我们函数的第一行中进行索引
❷ 我们的循环–但完全展开并固定为 1…4,不管 x 的大小如何
❸ 令人害怕,但却如此真实!
我们看到了一个重要的警告–实际上,这段代码已经为五行修复了索引和添加,但对于四行或六行的情况并不会按预期处理。
这就是脚本化的用处所在:
# In[4]:
scripted_fn = torch.jit.script(myfn)
print(scripted_fn.code)# Out[4]:
def myfn(x: Tensor) -> Tensor:y = torch.select(x, 0, 0)_0 = torch.__range_length(1, torch.size(x, 0), 1) # ❶y0 = yfor _1 in range(_0): # ❷i = torch.__derive_index(_1, 1, 1)y0 = torch.add(y0, torch.select(x, 0, i), alpha=1) # ❸return y0
❶ PyTorch 从张量大小构建范围长度。
❷ 我们的 for 循环–即使我们必须采取看起来有点奇怪的下一行来获取我们的索引 i
❸ 我们的循环体,稍微冗长一点
我们还可以打印脚本化的图,这更接近 TorchScript 的内部表示:
# In[5]:
xprint(scripted_fn.graph)
# end::cell_5_code[]# tag::cell_5_output[]
# Out[5]:
graph(%x.1 : Tensor):%10 : bool = prim::Constant[value=1]() # ❶%2 : int = prim::Constant[value=0]()%5 : int = prim::Constant[value=1]()%y.1 : Tensor = aten::select(%x.1, %2, %2) # ❷%7 : int = aten::size(%x.1, %2)%9 : int = aten::__range_length(%5, %7, %5) # ❸%y : Tensor = prim::Loop(%9, %10, %y.1) # ❹block0(%11 : int, %y.6 : Tensor):%i.1 : int = aten::__derive_index(%11, %5, %5)%18 : Tensor = aten::select(%x.1, %2, %i.1) # ❺%y.3 : Tensor = aten::add(%y.6, %18, %5)-> (%10, %y.3)return (%y)
❶ 看起来比我们需要的要冗长得多
❷ y 的第一个赋值
❸ 在看到代码后,我们可以识别出构建范围的方法。
❹ 我们的 for 循环返回它计算的值(y)。
❺ for 循环的主体:选择一个切片,并将其添加到 y 中
在实践中,您最常使用torch.jit.script作为装饰器的形式:
@torch.jit.script
def myfn(x):...
您也可以使用自定义的trace装饰器来处理输入,但这并没有流行起来。
尽管 TorchScript(语言)看起来像 Python 的一个子集,但存在根本性差异。如果我们仔细观察,我们会发现 PyTorch 已经向代码添加了类型规范。这暗示了一个重要的区别:TorchScript 是静态类型的–程序中的每个值(变量)都有且只有一个类型。此外,这些类型限于 TorchScript IR 具有表示的类型。在程序内部,JIT 通常会自动推断类型,但我们需要用它们的类型注释脚本化函数的任何非张量参数。这与 Python 形成鲜明对比,Python 中我们可以将任何内容分配给任何变量。
到目前为止,我们已经追踪函数以获取脚本化函数。但是我们很久以前就从仅在第五章中使用函数转向使用模块了。当然,我们也可以追踪或脚本化模型。然后,这些模型将大致表现得像我们熟悉和喜爱的模块。对于追踪和脚本化,我们分别将Module的实例传递给torch.jit.trace(带有示例输入)或torch.jit.script(不带示例输入)。这将给我们带来我们习惯的forward方法。如果我们想要暴露其他方法(这仅适用于脚本化)以便从外部调用,我们在类定义中用@torch.jit.export装饰它们。
当我们说 JIT 模块的工作方式与 Python 中的工作方式相同时,这包括我们也可以用它们进行训练。另一方面,这意味着我们需要为推断设置它们(例如,使用torch.no_grad()上下文),就像我们传统的模型一样,以使它们做正确的事情。
对于算法相对简单的模型–如 CycleGAN、分类模型和基于 U-Net 的分割–我们可以像之前一样追踪模型。对于更复杂的模型,一个巧妙的特性是我们可以在构建和追踪或脚本化模块时使用来自其他脚本化或追踪代码的脚本化或追踪函数,并且我们可以在调用nn.Models时追踪函数,但是我们需要将所有参数设置为不需要梯度,因为这些参数将成为追踪模型的常数。
由于我们已经看到了追踪,让我们更详细地看一个脚本化的实际示例。
15.3.4 脚本化追踪的间隙
在更复杂的模型中,例如用于检测的 Fast R-CNN 系列或用于自然语言处理的循环网络,像for循环这样的控制流位需要进行脚本化。同样,如果我们需要灵活性,我们会找到追踪器警告的代码片段。
代码清单 15.8 来自 utils/unet.py
class UNetUpBlock(nn.Module):...def center_crop(self, layer, target_size):_, _, layer_height, layer_width = layer.size()diff_y = (layer_height - target_size[0]) // 2diff_x = (layer_width - target_size[1]) // 2return layer[:, :, diff_y:(diff_y + target_size[0]), diff_x:(diff_x + target_size[1])] # ❶def forward(self, x, bridge):...crop1 = self.center_crop(bridge, up.shape[2:])...
❶ 追踪器在这里发出警告。
发生的情况是,JIT 神奇地用包含相同信息的 1D 整数张量替换了形状元组up.shape。现在切片[2:]和计算diff_x和diff_y都是可追踪的张量操作。然而,这并不能拯救我们,因为切片然后需要 Python int;在那里,JIT 的作用范围结束,给我们警告。
但是我们可以通过一种简单直接的方式解决这个问题:我们对center_crop进行脚本化。我们通过将up传递给脚本化的center_crop并在那里提取大小来略微更改调用者和被调用者之间的切割。除此之外,我们所需的只是添加@torch.jit.script装饰器。结果是以下代码,使 U-Net 模型可以无警告地进行追踪。
代码清单 15.9 从 utils/unet.py 重写的节选
@torch.jit.script
def center_crop(layer, target): # ❶_, _, layer_height, layer_width = layer.size()_, _, target_height, target_width = target.size() # ❷diff_y = (layer_height - target_height) // 2diff_x = (layer_width - target_width]) // 2return layer[:, :, diff_y:(diff_y + target_height), diff_x:(diff_x + target_width)] # ❸class UNetUpBlock(nn.Module):...def forward(self, x, bridge):...crop1 = center_crop(bridge, up) # ❹...
❶ 更改签名,接受目标而不是目标大小
❷ 在脚本化部分内获取大小
❸ 索引使用我们得到的大小值。
❹ 我们调整我们的调用以传递上而不是大小。
我们可以选择的另一个选项–但我们这里不会使用–是将不可脚本化的内容移入在 C++ 中实现的自定义运算符中。TorchVision 库为 Mask R-CNN 模型中的一些特殊操作执行此操作。
15.4 LibTorch:在 C++ 中使用 PyTorch
我们已经看到了各种导出模型的方式,但到目前为止,我们使用了 Python。现在我们将看看如何放弃 Python 直接使用 C++。
让我们回到从马到斑马的 CycleGAN 示例。我们现在将从第 15.2.3 节中获取 JITed 模型,并在 C++ 程序中运行它。
15.4.1 从 C++ 运行 JITed 模型
在 C++ 中部署 PyTorch 视觉模型最困难的部分是选择一个图像库来选择数据。⁸ 在这里,我们选择了非常轻量级的库 CImg (cimg.eu)。如果你非常熟悉 OpenCV,你可以调整代码以使用它;我们只是觉得 CImg 对我们的阐述最容易。
运行 JITed 模型非常简单。我们首先展示图像处理;这并不是我们真正想要的,所以我们会很快地完成这部分。⁹
代码清单 15.10 cyclegan_jit.cpp
#include "torch/script.h" # ❶
#define cimg_use_jpeg
#include "CImg.h"
using namespace cimg_library;
int main(int argc, char **argv) {CImg<float> image(argv[2]); # ❷image = image.resize(227, 227); # ❸// ...here we need to produce an output tensor from inputCImg<float> out_img(output.data_ptr<float>(), output.size(2), # ❹output.size(3), 1, output.size(1));out_img.save(argv[3]); # ❺return 0;
}
❶ 包括 PyTorch 脚本头文件和具有本地 JPEG 支持的 CImg
❷ 将图像加载并解码为浮点数组
❸ 调整为较小的尺寸
❹ 方法 data_ptr() 给我们一个指向张量存储的指针。有了它和形状信息,我们可以构建输出图像。
❺ 保存图像
对于 PyTorch 部分,我们包含了一个 C++ 头文件 torch/script.h。然后我们需要设置并包含 CImg 库。在 main 函数中,我们从命令行中加载一个文件中的图像并调整大小(在 CImg 中)。所以现在我们有一个 CImg<float> 变量 image 中的 227 × 227 图像。在程序的末尾,我们将从我们的形状为 (1, 3, 277, 277) 的张量创建一个相同类型的 out_img 并保存它。
不要担心这些细节。它们不是我们想要学习的 PyTorch C++,所以我们可以直接接受它们。
实际的计算也很简单。我们需要从图像创建一个输入张量,加载我们的模型,并将输入张量通过它运行。
代码清单 15.11 cyclegan_jit.cpp
auto input_ = torch::tensor(torch::ArrayRef<float>(image.data(), image.size())); # ❶auto input = input_.reshape({1, 3, image.height(),image.width()}).div_(255); # ❷auto module = torch::jit::load(argv[1]); # ❸std::vector<torch::jit::IValue> inputs; # ❹inputs.push_back(input);auto output_ = module.forward(inputs).toTensor(); # ❺auto output = output_.contiguous().mul_(255); # ❻
❶ 将图像数据放入张量中
❷ 重新调整和重新缩放以从 CImg 约定转换为 PyTorch 的
❸ 从文件加载 JITed 模型或函数
❹ 将输入打包成一个(单元素)IValues 向量
❺ 调用模块并提取结果张量。为了效率,所有权被移动,所以如果我们保留了 IValue,之后它将为空。
❻ 确保我们的结果是连续的
从第三章中回想起,PyTorch 将张量的值保存在特定顺序的大块内存中。CImg 也是如此,我们可以使用 image.data() 获取指向此内存块的指针(作为 float 数组),并使用 image.size() 获取元素的数量。有了这两个,我们可以创建一个稍微更智能的引用:一个 torch::ArrayRef(这只是指针加大小的简写;PyTorch 在 C++ 级别用于数据但也用于返回大小而不复制)。然后我们可以将其解析到 torch::tensor 构造函数中,就像我们对列表做的那样。
提示 有时候你可能想要使用类似工作的 torch::from_blob 而不是 torch::tensor。区别在于 tensor 会复制数据。如果你不想复制,可以使用 from_blob,但是你需要确保在张量的生命周期内底层内存是可用的。
我们的张量只有 1D,所以我们需要重新调整它。方便的是,CImg 使用与 PyTorch 相同的顺序(通道、行、列)。如果不是这样,我们需要调整重新调整并排列轴,就像我们在第四章中所做的那样。由于 CImg 使用 0…255 的范围,而我们使我们的模型使用 0…1,所以我们在这里除以后面再乘以。当然,这可以被吸收到模型中,但我们想重用我们的跟踪模型。
避免的一个常见陷阱:预处理和后处理
当从一个库切换到另一个库时,很容易忘记检查转换步骤是否兼容。除非我们查看 PyTorch 和我们使用的图像处理库的内存布局和缩放约定,否则它们是不明显的。如果我们忘记了,我们将因为没有得到预期的结果而感到失望。
在这里,模型会变得疯狂,因为它接收到非常大的输入。然而,最终,我们模型的输出约定是在 0 到 1 的范围内给出 RGB 值。如果我们直接将其与 CImg 一起使用,结果看起来会全是黑色。
其他框架有其他约定:例如 OpenCV 喜欢将图像存储为 BGR 而不是 RGB,需要我们翻转通道维度。我们始终要确保在部署中向模型提供的输入与我们在 Python 中输入的相同。
使用 torch::jit::load 加载跟踪模型非常简单。接下来,我们必须处理 PyTorch 引入的一个在 Python 和 C++ 之间桥接的抽象:我们需要将我们的输入包装在一个 IValue(或多个 IValue)中,这是任何值的通用数据类型。 JIT 中的一个函数接收一个 IValue 向量,所以我们声明这个向量,然后 push_back 我们的输入张量。这将自动将我们的张量包装成一个 IValue。我们将这个 IValue 向量传递给前向并得到一个返回的单个 IValue。然后我们可以使用 .toTensor 解包结果 IValue 中的张量。
这里我们了解一下 IValue:它们有一个类型(这里是 Tensor),但它们也可以持有 int64_t 或 double 或一组张量。例如,如果我们有多个输出,我们将得到一个持有张量列表的 IValue,这最终源自于 Python 的调用约定。当我们使用 .toTensor 从 IValue 中解包张量时,IValue 将转移所有权(变为无效)。但让我们不要担心这个;我们得到了一个张量。因为有时模型可能返回非连续数据(从第三章的存储中存在间隙),但 CImg 合理地要求我们提供一个连续的块,我们调用 contiguous。重要的是,我们将这个连续的张量分配给一个在使用底层内存时处于作用域内的变量。就像在 Python 中一样,如果 PyTorch 发现没有张量在使用内存,它将释放内存。
所以让我们编译这个!在 Debian 或 Ubuntu 上,你需要安装 cimg-dev、libjpeg-dev 和 libx11-dev 来使用 CImg。
你可以从 PyTorch 页面下载一个 PyTorch 的 C++ 库。但考虑到我们已经安装了 PyTorch,¹⁰我们可能会选择使用它;它已经包含了我们在 C++ 中所需的一切。我们需要知道我们的 PyTorch 安装位置在哪里,所以打开 Python 并检查 torch.__file__,它可能会显示 /usr/local/lib/python3.7/dist-packages/ torch/init.py。这意味着我们需要的 CMake 文件在 /usr/local/lib/python3.7/dist-packages/torch/share/cmake/ 中。
尽管对于一个单个源文件项目来说使用 CMake 似乎有点大材小用,但链接到 PyTorch 有点复杂;因此我们只需使用以下内容作为一个样板 CMake 文件。¹¹
列表 15.12 CMakeLists.txt
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(cyclegan-jit) # ❶find_package(Torch REQUIRED) # ❷
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")add_executable(cyclegan-jit cyclegan_jit.cpp) # ❸
target_link_libraries(cyclegan-jit pthread jpeg X11) # ❹
target_link_libraries(cyclegan-jit "${TORCH_LIBRARIES}")
set_property(TARGET cyclegan-jit PROPERTY CXX_STANDARD 14)
❶ 项目名称。用你自己的项目名称替换这里和其他行。
❷ 我们需要 Torch。
❸ 我们想要从 cyclegan_jit.cpp 源文件编译一个名为 cyclegan-jit 的可执行文件。
❹ 链接到 CImg 所需的部分。CImg 本身是全包含的,所以这里不会出现。
最好在源代码所在的子目录中创建一个构建目录,然后在其中运行 CMake,如¹² CMAKE_PREFIX_PATH=/usr/local/lib/python3.7/ dist-packages/torch/share/cmake/ cmake ..,最后 make。这将构建 cyclegan-jit 程序,然后我们可以运行如下:
./cyclegan-jit ../traced_zebra_model.pt ../../data/p1ch2/horse.jpg /tmp/z.jpg
我们刚刚在没有 Python 的情况下运行了我们的 PyTorch 模型。太棒了!如果你想发布你的应用程序,你可能想将 /usr/local/lib/python3.7/dist-packages/torch/lib 中的库复制到可执行文件所在的位置,这样它们就会始终被找到。
15.4.2 从头开始的 C++:C++ API
C++ 模块化 API 旨在感觉很像 Python 的 API。为了体验一下,我们将把 CycleGAN 生成器翻译成在 C++ 中本地定义的模型,但没有 JIT。但是,我们需要预训练的权重,因此我们将保存模型的跟踪版本(在这里重要的是跟踪模型而不是函数)。
我们将从一些行政细节开始:包括和命名空间。
列表 15.13 cyclegan_cpp_api.cpp
#include <torch/torch.h> # ❶
#define cimg_use_jpeg
#include <CImg.h>
using torch::Tensor; # ❷
❶ 导入一站式 torch/torch.h 头文件和 CImg
❷ 拼写torch::Tensor可能很繁琐,因此我们将名称导入主命名空间。
当我们查看文件中的源代码时,我们发现ConvTransposed2d是临时定义的,理想情况下应该从标准库中获取。问题在于 C++ 模块化 API 仍在开发中;并且在 PyTorch 1.4 中,预制的ConvTranspose2d模块无法在Sequential中使用,因为它需要一个可选的第二个参数。通常我们可以像我们为 Python 所做的那样留下Sequential,但我们希望我们的模型具有与第二章 Python CycleGAN 生成器相同的结构。
接下来,让我们看看残差块。
列表 15.14 cyclegan_cpp_api.cpp 中的残差块
struct ResNetBlock : torch::nn::Module {torch::nn::Sequential conv_block;ResNetBlock(int64_t dim): conv_block( # ❶torch::nn::ReflectionPad2d(1),torch::nn::Conv2d(torch::nn::Conv2dOptions(dim, dim, 3)),torch::nn::InstanceNorm2d(torch::nn::InstanceNorm2dOptions(dim)),torch::nn::ReLU(/*inplace=*/true),torch::nn::ReflectionPad2d(1),torch::nn::Conv2d(torch::nn::Conv2dOptions(dim, dim, 3)),torch::nn::InstanceNorm2d(torch::nn::InstanceNorm2dOptions(dim))) {register_module("conv_block", conv_block); # ❷}Tensor forward(const Tensor &inp) {return inp + conv_block->forward(inp); # ❸}
};.
❶ 初始化 Sequential,包括其子模块
❷ 始终记得注册您分配的模块,否则会发生糟糕的事情!
❸ 正如我们所预期的那样,我们的前向函数非常简单。
就像我们在 Python 中所做的那样,我们注册torch::nn::Module的子类。我们的残差块有一个顺序的conv_block子模块。
就像我们在 Python 中所做的那样,我们需要初始化我们的子模块,特别是Sequential。我们使用 C++ 初始化语句来做到这一点。这类似于我们在 Python 中在__init__构造函数中构造子模块的方式。与 Python 不同,C++ 没有启发式和挂钩功能,使得将__setattr__重定向以结合对成员的赋值和注册成为可能。
由于缺乏关键字参数使得带有默认参数的参数规范变得笨拙,模块(如张量工厂函数)通常需要一个options参数。Python 中的可选关键字参数对应于我们可以链接的选项对象的方法。例如,我们需要转换的 Python 模块nn.Conv2d(in_channels, out_channels, kernel_size, stride=2, padding=1)对应于torch::nn::Conv2d(torch::nn::Conv2dOptions (in_channels, out_channels, kernel_size).stride(2).padding(1))。这有点繁琐,但您正在阅读这篇文章是因为您热爱 C++,并且不会被它让您跳过的环节吓倒。
我们应始终确保注册和分配给成员的同步,否则事情将不会按预期进行:例如,在训练期间加载和更新参数将发生在注册的模块上,但实际被调用的模块是一个成员。这种同步在 Python 的 nn.Module 类后台完成,但在 C++ 中不是自动的。未能这样做将给我们带来许多头痛。
与我们在 Python 中所做的(应该!)相反,我们需要为我们的模块调用m->forward(...)。一些模块也可以直接调用,但对于Sequential,目前不是这种情况。
最后关于调用约定的评论是:根据您是否修改传递给函数的张量,张量参数应始终作为const Tensor&传递,对于不会更改的张量,或者如果它们被更改,则传递Tensor。应返回张量作为Tensor。错误的参数类型,如非 const 引用(Tensor&),将导致无法解析的编译器错误。
在主生成器类中,我们将更加密切地遵循 C++ API 中的典型模式,通过将我们的类命名为 ResNetGeneratorImpl 并使用 TORCH_MODULE 宏将其提升为 torch 模块 ResNetGenerator。背景是我们希望大部分处理模块作为引用或共享指针。包装类实现了这一点。
列表 15.15 cyclegan_cpp_api.cpp 中的 ResNetGenerator
struct ResNetGeneratorImpl : torch::nn::Module {torch::nn::Sequential model;ResNetGeneratorImpl(int64_t input_nc = 3, int64_t output_nc = 3,int64_t ngf = 64, int64_t n_blocks = 9) {TORCH_CHECK(n_blocks >= 0);model->push_back(torch::nn::ReflectionPad2d(3)); # ❶... # ❷model->push_back(torch::nn::Conv2d(torch::nn::Conv2dOptions(ngf * mult, ngf * mult * 2, 3).stride(2).padding(1))); # ❸...register_module("model", model);}Tensor forward(const Tensor &inp) { return model->forward(inp); }
};TORCH_MODULE(ResNetGenerator); # ❹
❶ 在构造函数中向 Sequential 容器添加模块。这使我们能够在 for 循环中添加可变数量的模块。
❷ 使我们免于重复一些繁琐的事情
❸ Options 的一个示例
❹ 在我们的 ResNetGeneratorImpl 类周围创建一个包装器 ResNetGenerator。尽管看起来有些过时,但匹配的名称在这里很重要。
就是这样–我们定义了 Python ResNetGenerator 模型的完美 C++ 对应物。现在我们只需要一个 main 函数来加载参数并运行我们的模型。加载图像使用 CImg 并将图像转换为张量,再将张量转换回图像与上一节中相同。为了增加一些变化,我们将显示图像而不是将其写入磁盘。
列表 15.16 cyclegan_cpp_api.cpp main
ResNetGenerator model; # ❶...torch::load(model, argv[1]); # ❷...cimg_library::CImg<float> image(argv[2]);image.resize(400, 400);auto input_ =torch::tensor(torch::ArrayRef<float>(image.data(), image.size()));auto input = input_.reshape({1, 3, image.height(), image.width()});torch::NoGradGuard no_grad; # ❸model->eval(); # ❹auto output = model->forward(input); # ❺...cimg_library::CImg<float> out_img(output.data_ptr<float>(),output.size(3), output.size(2),1, output.size(1));cimg_library::CImgDisplay disp(out_img, "See a C++ API zebra!"); # ❻while (!disp.is_closed()) {disp.wait();}
❶ 实例化我们的模型
❷ 加载参数
❸ 声明一个守卫变量相当于 torch.no_grad() 上下文。如果需要限制关闭梯度的时间,可以将其放在 { … } 块中。
❹ 就像在 Python 中一样,打开 eval 模式(对于我们的模型来说可能并不严格相关)。
❺ 再次调用 forward 而不是 model。
❻ 显示图像时,我们需要等待按键而不是立即退出程序。
有趣的变化在于我们如何创建和运行模型。正如预期的那样,我们通过声明模型类型的变量来实例化模型。我们使用 torch::load 加载模型(这里重要的是我们包装了模型)。虽然这看起来对于 PyTorch 从业者来说非常熟悉,但请注意它将在 JIT 保存的文件上工作,而不是 Python 序列化的状态字典。
运行模型时,我们需要相当于 with torch.no_grad(): 的功能。这是通过实例化一个类型为 NoGradGuard 的变量并在我们不希望梯度时保持其范围来实现的。就像在 Python 中一样,我们调用 model->eval() 将模型设置为评估模式。这一次,我们调用 model->forward 传入我们的输入张量并得到一个张量作为结果–不涉及 JIT,因此我们不需要 IValue 的打包和解包。
哎呀。对于我们这些 Python 粉丝来说,在 C++ 中编写这个是很费力的。我们很高兴我们只承诺在这里进行推理,但当然 LibTorch 也提供了优化器、数据加载器等等。使用 API 的主要原因当然是当你想要创建模型而 JIT 和 Python 都不合适时。
为了您的方便,CMakeLists.txt 中还包含了构建 cyclegan-cpp-api 的说明,因此构建就像在上一节中一样简单。
我们可以运行程序如下
./cyclegan_cpp_api ../traced_zebra_model.pt ../../data/p1ch2/horse.jpg
但我们知道模型会做什么,不是吗?
15.5 走向移动
作为部署模型的最后一个变体,我们将考虑部署到移动设备。当我们想要将我们的模型带到移动设备时,通常会考虑 Android 和/或 iOS。在这里,我们将专注于 Android。
PyTorch 的 C++ 部分–LibTorch–可以编译为 Android,并且我们可以通过使用 Android Java Native Interface (JNI) 编写的应用程序从 Java 中访问它。但实际上我们只需要从 PyTorch 中使用少量函数–加载 JIT 模型,将输入转换为张量和 IValue,通过模型运行它们,并将结果返回。为了避免使用 JNI 的麻烦,PyTorch 开发人员将这些函数封装到一个名为 PyTorch Mobile 的小型库中。
在 Android 中开发应用程序的标准方式是使用 Android Studio IDE,我们也将使用它。但这意味着有几十个管理文件–这些文件也会随着 Android 版本的更改而改变。因此,我们专注于将 Android Studio 模板(具有空活动的 Java 应用程序)转换为一个拍照、通过我们的斑马 CycleGAN 运行图片并显示结果的应用程序的部分。遵循本书的主题,我们将在示例应用程序中高效处理 Android 部分(与编写 PyTorch 代码相比可能会更痛苦)。
要使模板生动起来,我们需要做三件事。首先,我们需要定义一个用户界面。为了尽可能简单,我们有两个元素:一个名为headline的TextView,我们可以点击以拍摄和转换图片;以及一个用于显示我们图片的ImageView,我们称之为image_view。我们将把拍照留给相机应用程序(在应用程序中可能会避免这样做以获得更流畅的用户体验),因为直接处理相机会模糊我们专注于部署 PyTorch 模型的焦点。
然后,我们需要将 PyTorch 作为依赖项包含进来。这是通过编辑我们应用程序的 build.gradle 文件并添加pytorch_android和pytorch_android_torchvision来完成的。
15.17 build.gradle 的添加部分
dependencies { # ❶...implementation 'org.pytorch:pytorch_android:1.4.0' # ❷implementation 'org.pytorch:pytorch_android_torchvision:1.4.0' # ❸
}
❶ 依赖部分很可能已经存在。如果没有,请在底部添加。
❷ pytorch_android 库获取了文本中提到的核心内容。
❸ 辅助库 pytorch_android_torchvision–与其更大的 TorchVision 兄弟相比可能有点自负地命名–包含一些将位图对象转换为张量的实用程序,但在撰写本文时没有更多内容。
我们需要将我们的跟踪模型添加为资产。
最后,我们可以进入我们闪亮应用的核心部分:从活动派生的 Java 类,其中包含我们的主要代码。我们这里只讨论一个摘录。它以导入和模型设置开始。
15.18 MainActivity.java 第 1 部分
...
import org.pytorch.IValue; # ❶
import org.pytorch.Module;
import org.pytorch.Tensor;
import org.pytorch.torchvision.TensorImageUtils;
...
public class MainActivity extends AppCompatActivity {private org.pytorch.Module model; # ❷@Overrideprotected void onCreate(Bundle savedInstanceState) {...try { # ❸model = Module.load(assetFilePath(this, "traced_zebra_model.pt")); # ❹} catch (IOException e) {Log.e("Zebraify", "Error reading assets", e);finish();}...}...
}
❶ 你喜欢导入吗?
❷ 包含我们的 JIT 模型
❸ 在 Java 中我们必须捕获异常。
❹ 从文件加载模块
我们需要从org.pytorch命名空间导入一些内容。在 Java 的典型风格中,我们导入IValue、Module和Tensor,它们的功能符合我们的预期;以及org.pytorch.torchvision.TensorImageUtils类,其中包含在张量和图像之间转换的实用函数。
首先,当然,我们需要声明一个变量来保存我们的模型。然后,在我们的应用启动时–在我们的活动的onCreate中–我们将使用Model.load方法从给定的位置加载模块。然而,有一个小复杂之处:应用程序的数据是由供应商提供的资产,这些资产不容易从文件系统中访问。因此,一个名为assetFilePath的实用方法(取自 PyTorch Android 示例)将资产复制到文件系统中的一个位置。最后,在 Java 中,我们需要捕获代码抛出的异常,除非我们想要(并且能够)依次声明我们编写的方法抛出异常。
当我们使用 Android 的Intent机制从相机应用程序获取图像时,我们需要运行它通过我们的模型并显示它。这发生在onActivityResult事件处理程序中。
15.19 MainActivity.java,第 2 部分
@Override
protected void onActivityResult(int requestCode, int resultCode,Intent data) {if (requestCode == REQUEST_IMAGE_CAPTURE &&resultCode == RESULT_OK) { # ❶Bitmap bitmap = (Bitmap) data.getExtras().get("data");final float[] means = {0.0f, 0.0f, 0.0f}; # ❷final float[] stds = {1.0f, 1.0f, 1.0f};final Tensor inputTensor = TensorImageUtils.bitmapToFloat32Tensor( # ❸bitmap, means, stds);final Tensor outputTensor = model.forward( # ❹IValue.from(inputTensor)).toTensor();Bitmap output_bitmap = tensorToBitmap(outputTensor, means, stds,Bitmap.Config.RGB_565); # ❺image_view.setImageBitmap(output_bitmap);}
}
❶ 当相机应用程序拍照时执行此操作。
❷ 执行归一化,但默认情况下图像范围为 0…1,因此我们不需要转换:即具有 0 偏移和 1 的缩放除数。
❸ 从位图获取张量,结合 TorchVision 的 ToTensor 步骤(将其转换为介于 0 和 1 之间的浮点张量)和 Normalize
❹ 这看起来几乎和我们在 C++中做的一样。
❺ tensorToBitmap 是我们自己的创造。
将从 Android 获取的位图转换为张量由TensorImageUtils.bitmapToFloat32Tensor函数(静态方法)处理,该函数除了bitmap之外还需要两个浮点数组means和stds。在这里,我们指定输入数据(集)的均值和标准差,然后将其映射为具有零均值和单位标准差的数据,就像 TorchVision 的Normalize变换一样。Android 已经将图像给我们提供在 0…1 范围内,我们需要将其馈送到我们的模型中,因此我们指定均值为 0,标准差为 1,以防止归一化改变我们的图像。
在实际调用model.forward时,我们执行与在 C++中使用 JIT 时相同的IValue包装和解包操作,只是我们的forward接受一个IValue而不是一个向量。最后,我们需要回到位图。在这里,PyTorch 不会帮助我们,因此我们需要定义自己的tensorToBitmap(并向 PyTorch 提交拉取请求)。我们在这里不详细介绍,因为这些细节很繁琐且充满复制(从张量到float[]数组到包含 ARGB 值的int[]数组到位图),但事实就是如此。它被设计为bitmapToFloat32Tensor的逆过程。

图 15.5 我们的 CycleGAN 斑马应用
这就是我们需要做的一切,就可以将 PyTorch 引入 Android。使用我们在这里留下的最小代码补充来请求一张图片,我们就有了一个看起来像图 15.5 中所见的Zebraify Android 应用程序。干得好!¹⁶
我们应该注意到,我们在 Android 上使用了 PyTorch 的完整版本,其中包含所有操作。一般来说,这也会包括您在特定任务中不需要的操作,这就引出了一个问题,即我们是否可以通过将它们排除在外来节省一些空间。事实证明,从 PyTorch 1.4 开始,您可以构建一个定制版本的 PyTorch 库,其中只包括您需要的操作(参见pytorch.org/mobile/android/#custom-build)。
15.5.1 提高效率:模型设计和量化
如果我们想更详细地探索移动端,我们的下一步是尝试使我们的模型更快。当我们希望减少模型的内存和计算占用空间时,首先要看的是简化模型本身:也就是说,使用更少的参数和操作计算相同或非常相似的输入到输出的映射。这通常被称为蒸馏。蒸馏的细节各不相同–有时我们尝试通过消除小或无关的权重来缩小每个权重;在其他示例中,我们将网络的几层合并为一层(DistilBERT),甚至训练一个完全不同、更简单的模型来复制较大模型的输出(OpenNMT 的原始 CTranslate)。我们提到这一点是因为这些修改很可能是使模型运行更快的第一步。
另一种方法是减少每个参数和操作的占用空间:我们将模型转换为使用整数(典型选择是 8 位)而不是以浮点数的形式花费通常的 32 位每个参数。这就是量化。¹⁸
PyTorch 确实为此目的提供了量化张量。它们被公开为一组类似于torch.float、torch.double和torch.long的标量类型(请参阅第 3.5 节)。最常见的量化张量标量类型是torch.quint8和torch.qint8,分别表示无符号和有符号的 8 位整数。PyTorch 在这里使用单独的标量类型,以便使用我们在第 3.11 节简要介绍的分派机制。
使用 8 位整数而不是 32 位浮点数似乎能够正常工作可能会让人感到惊讶;通常结果会有轻微的降级,但不会太多。有两个因素似乎起到作用:如果我们将舍入误差视为基本上是随机的,并且将卷积和线性层视为加权平均,我们可能期望舍入误差通常会抵消。¹⁹ 这允许将相对精度从 32 位浮点数的 20 多位减少到有符号整数提供的 7 位。量化的另一件事(与使用 16 位浮点数进行训练相反)是从浮点数转换为固定精度(每个张量或通道)。这意味着最大值被解析为 7 位精度,而是最大值的八分之一的值仅为 7 - 3 = 4 位。但如果像 L1 正则化(在第八章中简要提到)这样的事情起作用,我们可能希望类似的效果使我们在量化时能够为权重中的较小值提供更少的精度。在许多情况下,确实如此。
量化功能于 PyTorch 1.3 首次亮相,但在 PyTorch 1.4 中在支持的操作方面仍有些粗糙。不过,它正在迅速成熟,我们建议如果您真的关心计算效率的部署,不妨试试看。
15.6 新兴技术:企业 PyTorch 模型服务
我们可能会问自己,迄今为止讨论的所有部署方面是否都需要像它们现在这样涉及大量编码。当然,有人编写所有这些代码是很常见的。截至 2020 年初,当我们忙于为这本书做最后的润色时,我们对不久的将来寄予厚望;但与此同时,我们感觉到部署领域将在夏季发生重大变化。
目前,RedisAI(github.com/RedisAI/redisai-py)中的一位作者正在等待将 Redis 的优势应用到我们的模型中。PyTorch 刚刚实验性发布了 TorchServe(在这本书完成后,请查看pytorch.org/ blog/pytorch-library-updates-new-model-serving-library/#torchserve-experimental)。
同样,MLflow(mlflow.org)正在不断扩展更多支持,而 Cortex(cortex.dev)希望我们使用它来部署模型。对于更具体的信息检索任务,还有 EuclidesDB(euclidesdb.readthedocs.io/ en/latest)来执行基于 AI 的特征数据库。
令人兴奋的时刻,但不幸的是,它们与我们的写作计划不同步。我们希望在第二版(或第二本书)中有更多内容可以告诉您!
15.7 结论
这结束了我们如何将我们的模型部署到我们想要应用它们的地方的简短介绍。虽然现成的 Torch 服务在我们撰写本文时还不够完善,但当它到来时,您可能会希望通过 JIT 导出您的模型–所以您会很高兴我们在这里经历了这一过程。与此同时,您现在知道如何将您的模型部署到网络服务、C++ 应用程序或移动设备上。我们期待看到您将会构建什么!
希望我们也实现了这本书的承诺:对深度学习基础知识有所了解,并对 PyTorch 库感到舒适。我们希望您阅读的过程和我们写作的过程一样愉快。²⁰
15.8 练习
当我们结束 使用 PyTorch 进行深度学习 时,我们为您准备了最后一个练习:
- 选择一个让您感到兴奋的项目。Kaggle 是一个很好的开始地方。开始吧。
您已经掌握了成功所需的技能并学会了必要的工具。我们迫不及待想知道接下来您会做什么;在书的论坛上给我们留言,让我们知道!
15.9 总结
-
我们可以通过将 PyTorch 模型包装在 Python Web 服务器框架(如 Flask)中来提供 PyTorch 模型的服务。
-
通过使用 JIT 模型,我们可以避免即使从 Python 调用它们时也避免 GIL,这对于服务是一个好主意。
-
请求批处理和异步处理有助于有效利用资源,特别是在 GPU 上进行推理时。
-
要将模型导出到 PyTorch 之外,ONNX 是一个很好的格式。ONNX Runtime 为许多目的提供后端支持,包括树莓派。
-
JIT 允许您轻松导出和运行任意 PyTorch 代码在 C++中或在移动设备上。
-
追踪是获得 JIT 模型的最简单方法;对于一些特别动态的部分,您可能需要使用脚本。
-
对于运行 JIT 和本地模型,C++(以及越来越多的其他语言)也有很好的支持。
-
PyTorch Mobile 让我们可以轻松地将 JIT 模型集成到 Android 或 iOS 应用程序中。
-
对于移动部署,我们希望简化模型架构并在可能的情况下对模型进行量化。
-
几个部署框架正在兴起,但标准尚不太明显。
¹ 为了安全起见,请勿在不受信任的网络上执行此操作。
² 或者对于 Python3 使用pip3。您可能还希望从 Python 虚拟环境中运行它。
³ 早期公开讨论 Flask 为 PyTorch 模型提供服务的不足之处之一是 Christian Perone 的“PyTorch under the Hood”,mng.bz/xWdW。
⁴ 高级人士将这些异步函数称为生成器,有时更宽松地称为协程: en.wikipedia.org/wiki/Coroutine。
⁵ 另一种选择可能是放弃计时器,只有在队列不为空时才运行。这可能会运行较小的“第一”批次,但对于大多数应用程序来说,整体性能影响可能不会太大。
⁶ 代码位于github.com/microsoft/onnxruntime,但请务必阅读隐私声明!目前,自行构建 ONNX Runtime 将为您提供一个不会向母公司发送信息的软件包。
⁷ 严格来说,这将模型追踪为一个函数。最近,PyTorch 获得了使用torch.jit.trace_module保留更多模块结构的能力,但对我们来说,简单的追踪就足够了。
⁸ 但 TorchVision 可能会开发一个方便的函数来加载图像。
⁹ 该代码适用于 PyTorch 1.4 及以上版本。在 PyTorch 1.3 之前的版本中,您需要使用data代替data_ptr。
¹⁰ 我们希望您一直在尝试阅读的内容。
¹¹ 代码目录有一个稍长版本,以解决 Windows 问题。
¹² 您可能需要将路径替换为您的 PyTorch 或 LibTorch 安装位置。请注意,与 Python 相比,C++库在兼容性方面可能更挑剔:如果您使用的是支持 CUDA 的库,则需要安装匹配的 CUDA 头文件。如果您收到关于“Caffe2 使用 CUDA”的神秘错误消息,则需要安装一个仅支持 CPU 的库版本,但 CMake 找到了一个支持 CUDA 的库。
¹³ 这是对 PyTorch 1.3 的巨大改进,我们需要为 ReLU、ÌnstanceNorm2d和其他模块实现自定义模块。
¹⁴ 这有点模糊,因为你可以创建一个与输入共享内存并就地修改的新张量,但最好尽量避免这样做。
¹⁵ 我们对这个主题隐喻感到非常自豪。
¹⁶ 撰写时,PyTorch Mobile 仍然相对年轻,您可能会遇到一些问题。在 Pytorch 1.3 上,实际的 32 位 ARM 手机在模拟器中工作时颜色不正确。原因很可能是 ARM 上仅在使用的计算后端函数中存在错误。使用 PyTorch 1.4 和更新的手机(64 位 ARM)似乎效果更好。
¹⁷ 示例包括彩票假设和 WaveRNN。
¹⁸ 与量化相比,(部分)转向 16 位浮点数进行训练通常被称为减少或(如果某些位保持 32 位)混合精度训练。
¹⁹ 时髦的人们可能会在这里提到中心极限定理。确实,我们必须注意保持舍入误差的独立性(在统计意义上)。例如,我们通常希望零(ReLU 的一个显著输出)能够被精确表示。否则,所有的零将会在舍入中被完全相同的数量改变,导致误差累积而不是抵消。
²⁰ 实际上更多;写书真的很难!




![练习 9 Web [SUCTF 2019]CheckIn (未拿到flag)](https://img-blog.csdnimg.cn/direct/ce6fbec3c49342ce90021571deaa6860.png)