本文系个人知乎专栏文章迁移
VALL-E 网络是GPT-SOVITS很重要的参考
知乎专栏地址:
语音生成专栏
相关文章链接:
【VALL-E-01】环境搭建
【VALL-E-02】核心原理
【参考】
【1】Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
【2】https://www.shili8.cn/article/detail_20001089545.html
【3】https://zhuanlan.zhihu.com/p/647390304?utm_id=0
【4】https://github.com/facebookresearch/encodec
【5】https://www.bilibili.com/video/BV1zo4y1K7oK/?spm_id_from=333.337.search-card.all.click&vd_source=030dfdbeaef00211755804fc3102911e
【6】https://www.doc88.com/p-78547750936802.html
1、前置知识点:Encodec
Vall-E 是基于 Encodec 来完成语音编码的生成。
1.1、向量量化编码
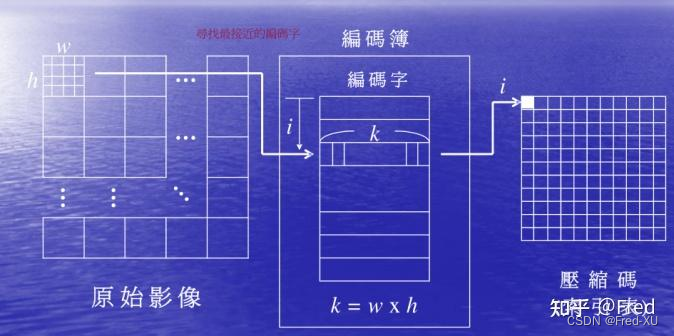
- 向量量化压缩把原始信息以字典表的形式做进一步压缩
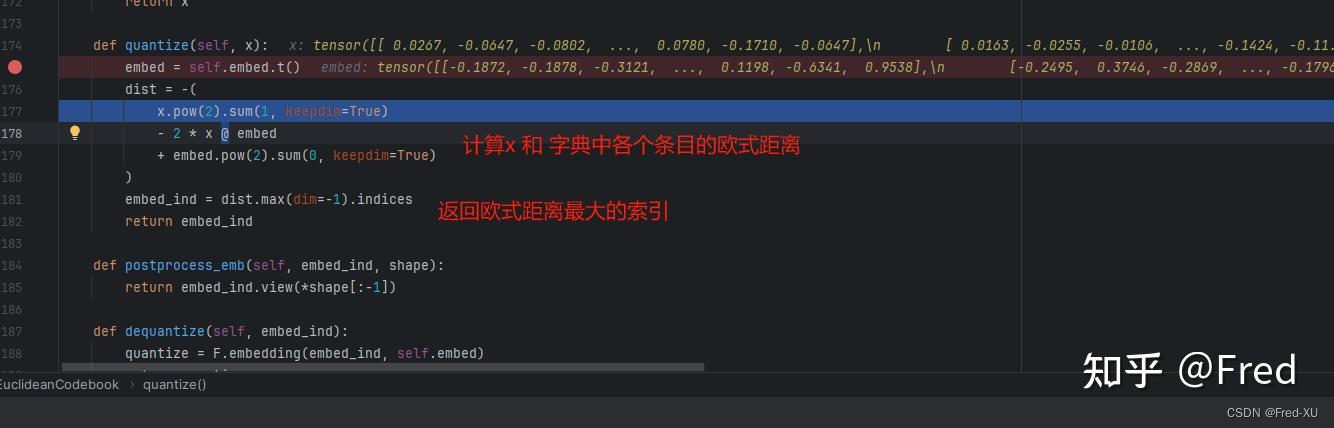
- 在 vall-e 的源码中采用 EuclideanCodebook,每个EuclideanCodebook 默认大小是 1024*128
- 每次输入待编码的帧也是128,通过计算欧式距离的最大值,并返回最大值的索引(0~1024之间)
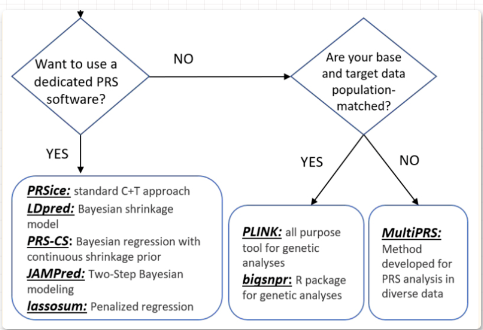
1.2、总体结构
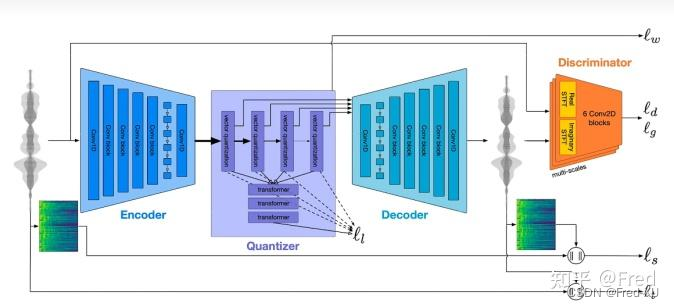
- encodec 是一个encoder 和 decoder 结构,分别利用卷积和反卷积进行压缩和解压缩
- 中间的残差量化层 Quantier 是对 encoder 压缩完的结构进行进一步压缩
- 所谓的残差量化,是在每一层的量化后,所形成与输入的差会进行再一次量化,形成一个量化的结果组
- 由于是残差的,也可知其第一个量化结果能表征最粗粒度的信息,因此在VALL-E中被特殊处理
- 源码如下图所示,有 nq 的量化器,每次返回其字典中欧式距离最大的索引,最终形成一个 8 维度的向量

1.3、代码举例
from encodec import EncodecModel
from encodec.utils import convert_audioimport torchaudio
import torchmodel = EncodecModel.encodec_model_24khz()# 当设置带宽为 6.0 时,采用 nq=8 的编码字典
model.set_target_bandwidth(6.0)wav, sr = torchaudio.load("shantianfang.wav")
wav = convert_audio(wav, sr, model.sample_rate, model.channels)
wav = wav.unsqueeze(0)with torch.no_grad():encoded_frames = model.encode(wav)
codes = torch.cat([encoded[0] for encoded in encoded_frames], dim=-1)
print(codes)
print(codes.shape) # ([1, 8, 725]) 1 段音频,总共 725 帧,每帧的字典索引大小为 8(对应编码字典的 nq)
在 VALL-E 的源码中其设置的带宽也是 6.0,因此与论文中 C 的维度是 8 一致,如下
class AudioTokenizer:"""EnCodec audio."""def __init__(self,device: Any = None,) -> None:# Instantiate a pretrained EnCodec modelmodel = EncodecModel.encodec_model_24khz()model.set_target_bandwidth(6.0)remove_encodec_weight_norm(model)
2、VALL-E 总体结构
Vall-E 论文中将 TTS 问题定义为一个条件编解语言模型,具体如下:
2.1、数据集
考虑一个数据集 D = { x i , y i } D= \{x_i, y_i\} D={xi,yi} ,其中 y 是音频样本 x = { x 0 , x 1 , . . . . , x L } x = \{x_0, x_1, ...., x_L\} x={x0,x1,....,xL} 是 音频 y 对应的【文本音素】序列
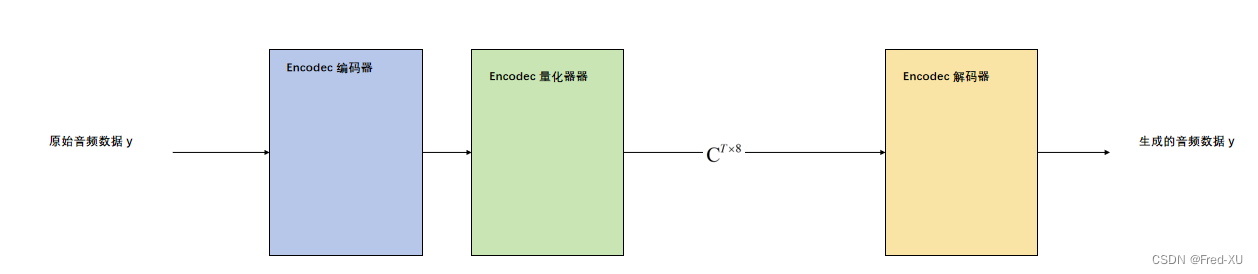
2.2、Encodec编解码器
利用一个预训练模型将原始音频数据进行处理,用Encodec的【编码器】:
E n c o d e c ( y ) = C T × 8 Encodec(y) = C^{T \times 8} Encodec(y)=CT×8 编解码后的结果如上式可知是一个二维矩阵,其中长度 T 是原始音频的降采样后的长度(如分为30帧),8 是每一帧的特征长度。
同样用Encodec【解码器】具备相反的能力,定义如下: D e c o d e c ( C ) ≈ y ^ Decodec(C) \approx \hat{y} Decodec(C)≈y^
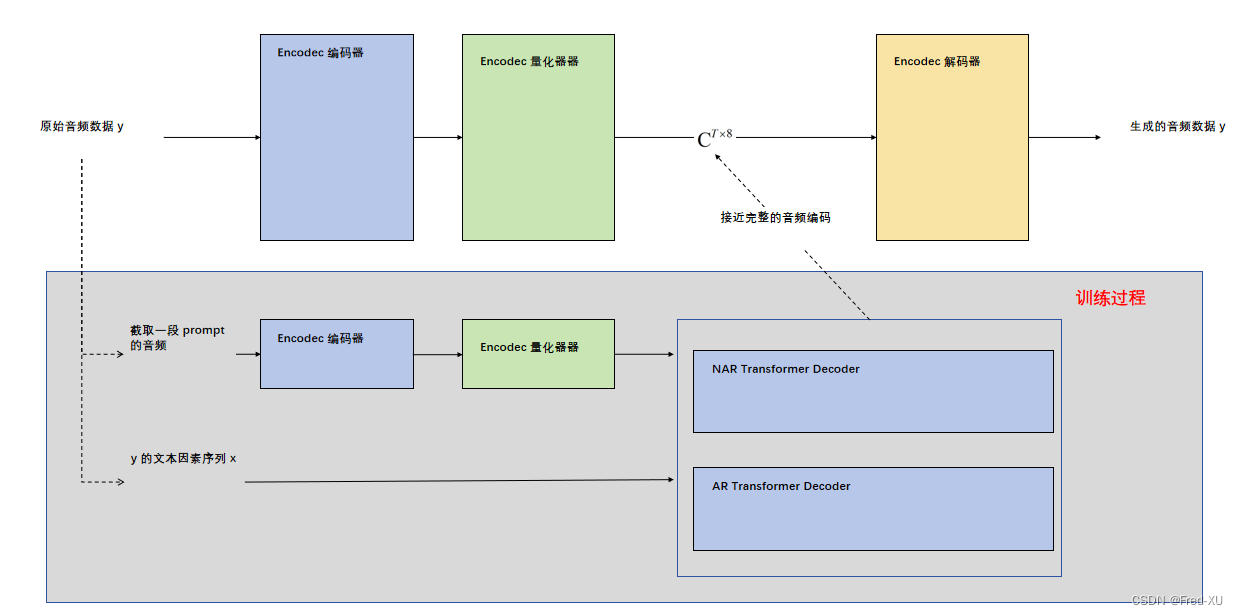
2.3、零样本训练
这里训练的目的最大化 p ( C ∣ x , C ^ ) p(C|x,\hat{C}) p(C∣x,C^),定义如下:
C ^ = C ^ T ‘ × 8 \hat{C} = \hat{C}^{T‘ \times 8} C^=C^T‘×8 是一段语音提示(prompt)对应的编码结果,如上文 b 所示。— 提示语音特征
x 是某个音频数据 y 的【文本因素】的序列,如上文 a 所示 – 目标文本特征
C 是某个音频数据 y 的编码结果,如 上文 b 所示 – 目标语音特征
于是,在训练时,我们的目标是训练一个模型,可以通过一个 【提示语音编码】+【目标文本特征】转换为【目标语音编码】。这个目标语音特征是可以利用 Decodec 转换为最终音频文件。
训练时,【提示语音编码】和【目标语音编码】应该为同一个人,而推理时,将目标说话人一个较短的音频文件生成【提示语音特征】,最终即可构建符合目标人语音效果的【新的目标语音编码】
理解:
1、在 encodec 的编码量化结果中本质上包含了文本要素(说什么),以及语音要素(如音色等)
2、在 vall-e 的模型中量化结果不需要完整的音频信息,而是从 prompt 的量化结果中提取语音要素 加上 文本要素 后生成一个完整的语音编码量化结果,这个结果被用来生成最终语音
3、VALL-E 核心设计
3.1、自回归模型AR
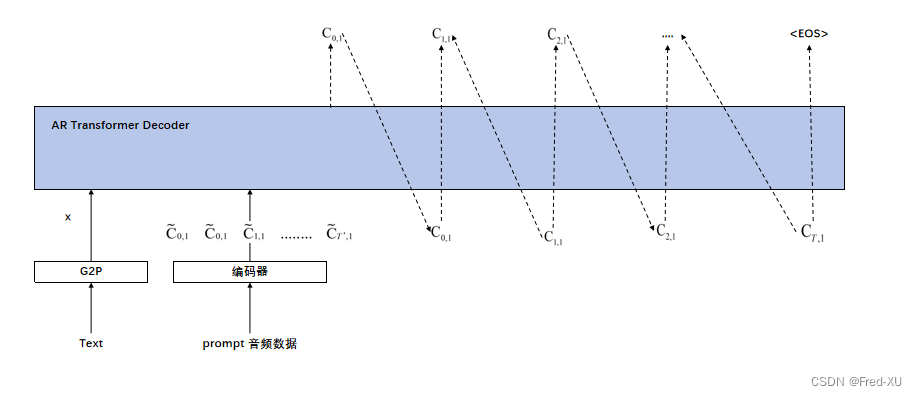
自回归模型使用特征中的第一个维度,即 prompt 的 C ^ : 1 \hat{C}_{:1} C^:1 和原始音频对应编码的 C : 1 C_{:1} C:1
该模型是自回归,同时给出 prompt 的全部对应编码特征,然后依次推到知道终结符EOS(类似经典transformer的解码器)
3.2、非自回归模型NAR
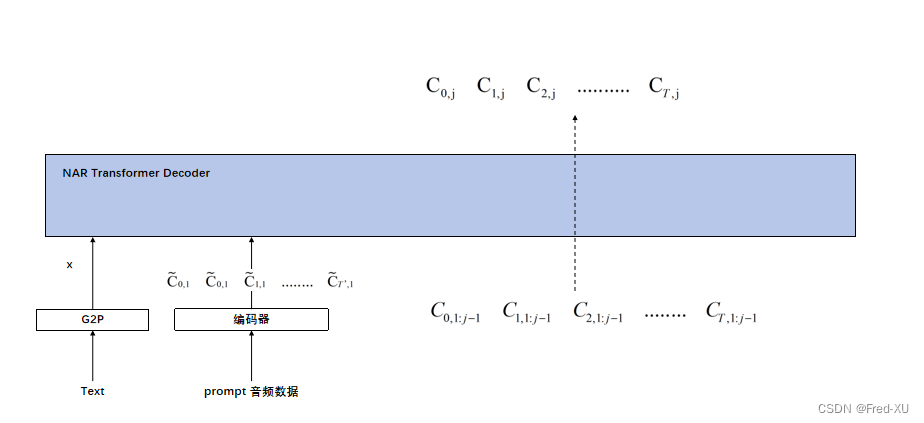
自回归模型使用特征中除第一个之外的维度
模型是非自回归的,对于整个编码序列,用之前的全部特征维度 C , 1 : j − 1 C_{,1:j-1} C,1:j−1 推导 C : j C_{:j} C:j