目录
417. 太平洋大西洋水流问题
827.最大人工岛
127. 单词接龙
417. 太平洋大西洋水流问题
题目链接(opens new window)
有一个 m × n 的矩形岛屿,与 太平洋 和 大西洋 相邻。 “太平洋” 处于大陆的左边界和上边界,而 “大西洋” 处于大陆的右边界和下边界。
这个岛被分割成一个由若干方形单元格组成的网格。给定一个 m x n 的整数矩阵 heights , heights[r][c] 表示坐标 (r, c) 上单元格 高于海平面的高度 。
岛上雨水较多,如果相邻单元格的高度 小于或等于 当前单元格的高度,雨水可以直接向北、南、东、西流向相邻单元格。水可以从海洋附近的任何单元格流入海洋。
返回网格坐标 result 的 2D 列表 ,其中 result[i] = [ri, ci] 表示雨水从单元格 (ri, ci) 流动 既可流向太平洋也可流向大西洋 。
示例 1:
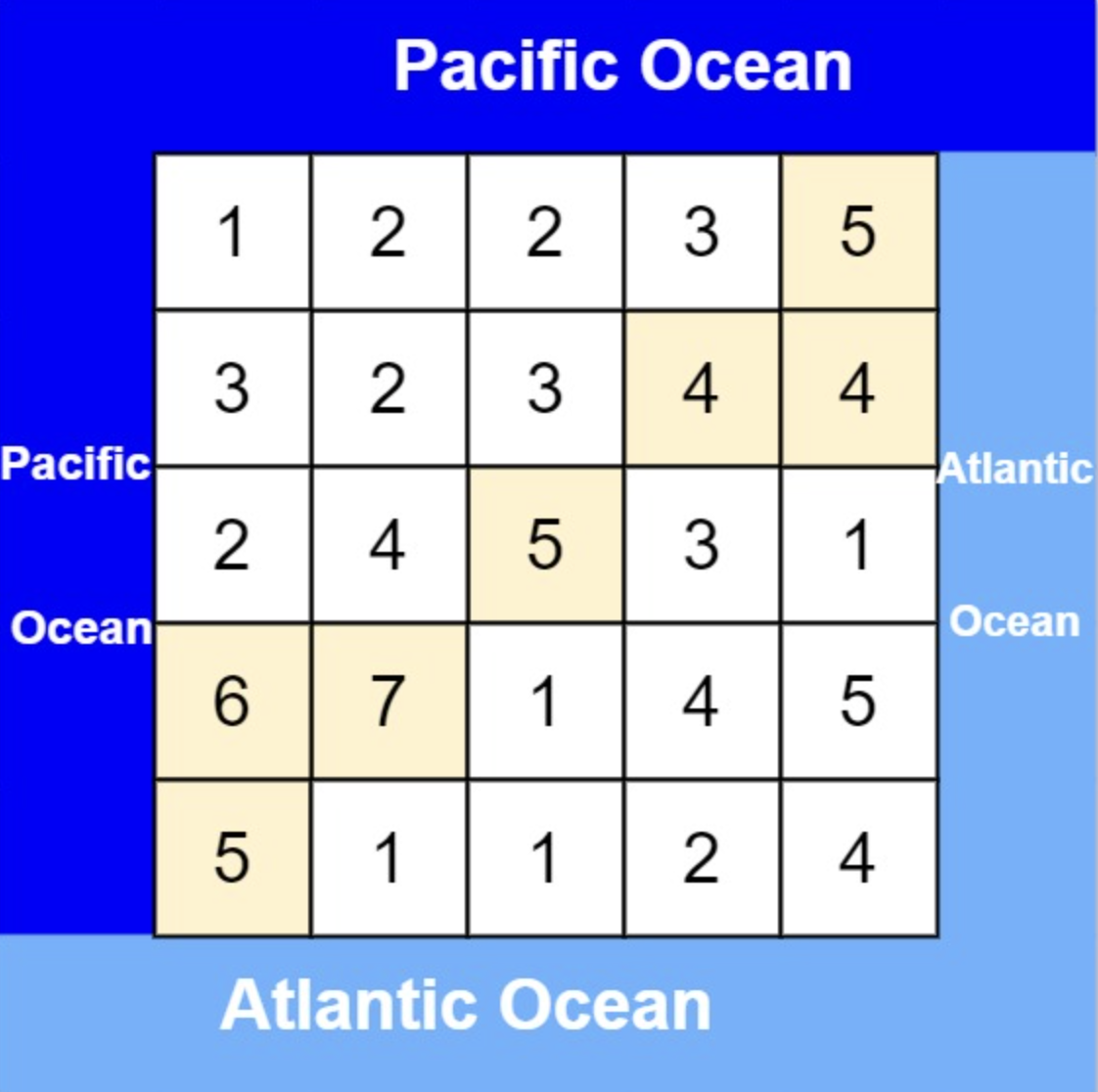
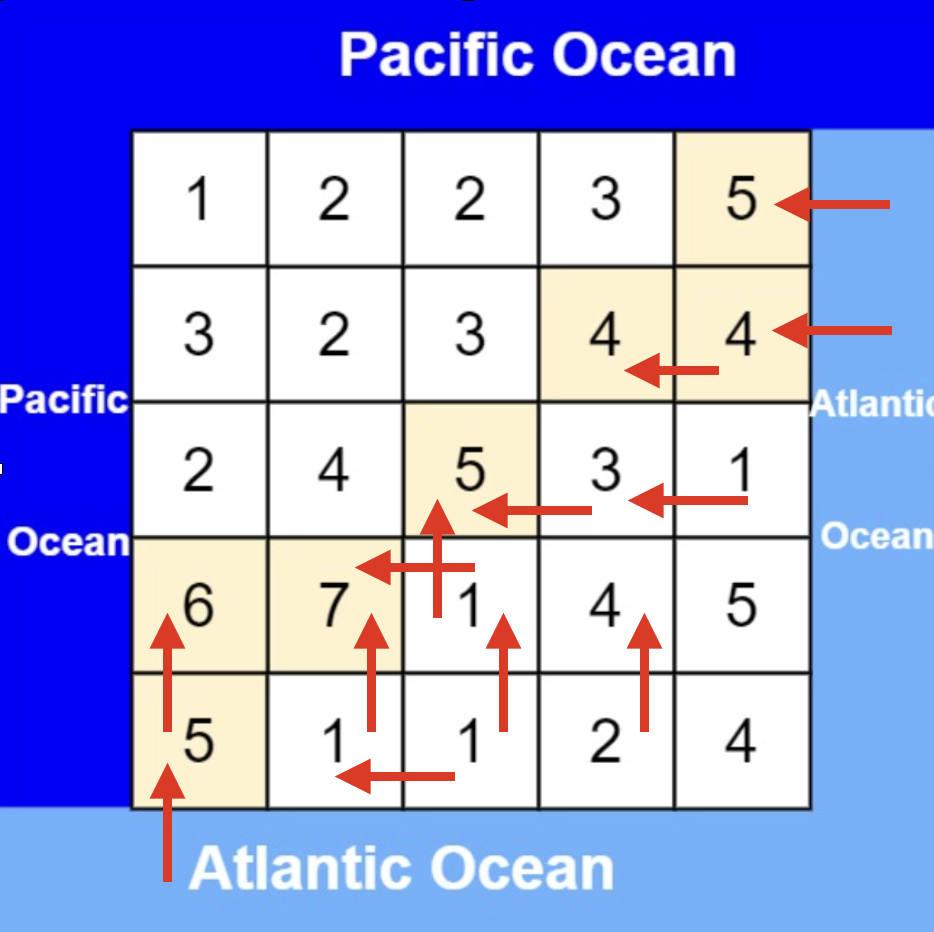
- 输入: heights = [[1,2,2,3,5],[3,2,3,4,4],[2,4,5,3,1],[6,7,1,4,5],[5,1,1,2,4]]
- 输出: [[0,4],[1,3],[1,4],[2,2],[3,0],[3,1],[4,0]]
示例 2:
- 输入: heights = [[2,1],[1,2]]
- 输出: [[0,0],[0,1],[1,0],[1,1]]
提示:
- m == heights.length
- n == heights[r].length
- 1 <= m, n <= 200
- 0 <= heights[r][c] <= 10^5
思路:
那么我们可以 反过来想,从太平洋边上的节点 逆流而上,将遍历过的节点都标记上。 从大西洋的边上节点 逆流而长,将遍历过的节点也标记上。 然后两方都标记过的节点就是既可以流太平洋也可以流大西洋的节点。
从太平洋边上节点出发,如图:
从大西洋边上节点出发,如图:

class Solution {
public://dfs版int dir[4][2]={1,0,0,1,-1,0,0,-1};//方向void dfs(vector<vector<int>>& heights, vector<vector<bool>>& visited, int x, int y){if(visited[x][y])return;visited[x][y]=true;for(int i=0;i<4;i++){int nextx = x+dir[i][0];int nexty = y+dir[i][1];if(nextx<0||nextx>=heights.size()||nexty<0||nexty>=heights[0].size())continue;if(heights[x][y]>heights[nextx][nexty])continue; //大于或等于当前才能流通,否则跳过dfs(heights, visited, nextx, nexty);// visited[nextx][nexty]=true;}return;}vector<vector<int>> pacificAtlantic(vector<vector<int>>& heights) {int n=heights.size();//列数int m=heights[0].size();//行数vector<vector<bool>>pacificVisited(n,vector<bool>(m,false));vector<vector<bool>>atlanticVisited(n,vector<bool>(m,false));//从边上分别遍历for(int i=0;i<n;i++){dfs(heights, pacificVisited, i,0);//遍历最顶上dfs(heights,atlanticVisited,i,m-1);//遍历最底下}for(int j=0;j<m;j++){dfs(heights, pacificVisited, 0, j);//遍历最左边dfs(heights, atlanticVisited, n-1,j); //遍历最右边}vector<vector<int>>result;//遍历整个地图for(int i=0;i<n;i++){for(int j=0; j<m;j++){if(pacificVisited[i][j]&&atlanticVisited[i][j]){result.push_back({i,j});}}}return result;}
};827.最大人工岛
力扣链接(opens new window)
给你一个大小为 n x n 二进制矩阵 grid 。最多 只能将一格 0 变成 1 。
返回执行此操作后,grid 中最大的岛屿面积是多少?
岛屿 由一组上、下、左、右四个方向相连的 1 形成。
示例 1:
- 输入: grid = [[1, 0], [0, 1]]
- 输出: 3
- 解释: 将一格0变成1,最终连通两个小岛得到面积为 3 的岛屿。
示例 2:
- 输入: grid = [[1, 1], [1, 0]]
- 输出: 4
- 解释: 将一格0变成1,岛屿的面积扩大为 4。
示例 3:
- 输入: grid = [[1, 1], [1, 1]]
- 输出: 4
- 解释: 没有0可以让我们变成1,面积依然为 4。
思路:
只要用一次深搜把每个岛屿的面积记录下来就好。
第一步:一次遍历地图,得出各个岛屿的面积,并做编号记录。可以使用map记录,key为岛屿编号,value为岛屿面积 第二步:在遍历地图,遍历0的方格(因为要将0变成1),并统计该1(由0变成的1)周边岛屿面积,将其相邻面积相加在一起,遍历所有 0 之后,就可以得出 选一个0变成1 之后的最大面积。
class Solution {
private:int count;int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y, int mark) {if (visited[x][y] || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水visited[x][y] = true; // 标记访问过grid[x][y] = mark; // 给陆地标记新标签count++;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过dfs(grid, visited, nextx, nexty, mark);}}public:int largestIsland(vector<vector<int>>& grid) {int n = grid.size(), m = grid[0].size();vector<vector<bool>> visited = vector<vector<bool>>(n, vector<bool>(m, false)); // 标记访问过的点unordered_map<int ,int> gridNum;int mark = 2; // 记录每个岛屿的编号bool isAllGrid = true; // 标记是否整个地图都是陆地for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 0) isAllGrid = false;if (!visited[i][j] && grid[i][j] == 1) {count = 0;dfs(grid, visited, i, j, mark); // 将与其链接的陆地都标记上 truegridNum[mark] = count; // 记录每一个岛屿的面积mark++; // 记录下一个岛屿编号}}}if (isAllGrid) return n * m; // 如果都是陆地,返回全面积// 以下逻辑是根据添加陆地的位置,计算周边岛屿面积之和int result = 0; // 记录最后结果unordered_set<int> visitedGrid; // 标记访问过的岛屿for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {int count = 1; // 记录连接之后的岛屿数量visitedGrid.clear(); // 每次使用时,清空if (grid[i][j] == 0) {for (int k = 0; k < 4; k++) {int neari = i + dir[k][1]; // 计算相邻坐标int nearj = j + dir[k][0];if (neari < 0 || neari >= grid.size() || nearj < 0 || nearj >= grid[0].size()) continue;if (visitedGrid.count(grid[neari][nearj])) continue; // 添加过的岛屿不要重复添加// 把相邻四面的岛屿数量加起来count += gridNum[grid[neari][nearj]];visitedGrid.insert(grid[neari][nearj]); // 标记该岛屿已经添加过}}result = max(result, count);}}return result;}
};127. 单词接龙
力扣题目链接(opens new window)
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
- 序列中第一个单词是 beginWord 。
- 序列中最后一个单词是 endWord 。
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典 wordList 中的单词。
- 给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
示例 1:
- 输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
- 输出:5
- 解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:
- 输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
- 输出:0
- 解释:endWord "cog" 不在字典中,所以无法进行转换
思路:最短路径,考虑广度优先搜索;为了提升查找效率,可以采用哈希结构,将单词列表转换到unodered_set,将路径与长度放到unodered_map<string, int>里;每次查找时,用两个for循环,一个for循环遍历beginword进行字母替换,另一个循环遍历26个字母,依次进行替换,再看看替换后字母有没有出现在单词集合unodered_set里,如果出现了:假如正好==endword,路径长度+1,返回结果;否则路径长度+1,继续进行搜索
class Solution {
public:int ladderLength(string beginWord, string endWord, vector<string>& wordList) {unordered_set<string>wordset(wordList.begin(), wordList.end());if(wordset.find(endWord)==wordset.end())return 0;unordered_map<string,int> visitedmap;//记录单词及对应路径长度queue<string>que;que.push(beginWord);visitedmap.insert(pair<string,int>(beginWord,1));//第一个单词,路径1while(!que.empty()){string word=que.front(); que.pop();int pathlen=visitedmap[word];for(int i=0;i<word.size();i++){string newword=word;for(int j=0;j<26;j++){newword[i]=j+'a';if(newword==endWord)return pathlen+1;//判断新字符串是否在单词集合里面,如果在,说明有效;//再看新单词是否在路径集合里出现过,如果有效且未出现在路径里,那么加入路径,路径长度+1,继续2迭代if(wordset.find(newword)!=wordset.end()&&visitedmap.find(newword)==visitedmap.end()){visitedmap.insert(pair<string,int>(newword,pathlen+1));que.push(newword);}}}}return 0;}
};参考:代码随想录