经典定义:
利用经验改善系统自身的性能。
经典的机器学习过程:

基本术语:
数据集:训练集、测试集
示例、样例、样本
属性、特征:属性值
属性空间、样本空间、输入空间
特征向量
标记空间、输出空间
归纳偏好(偏置):
任何一个有效的机器学习算法必有其偏好
学习算法的归纳偏好是否与问题本身匹配,大多数直接决定了算法能否取得好的性能
泛化能力:对新的未见过的处理能力强。
一、到底要什么
二、给的是不是想要的
泛化误差:在“未来”样本上的误差
经验误差:在训练集上的误差,亦称“训练误差”
过拟合 VS 欠拟合

三大问题:
一、如何获得测试结果 (评估方法)
关键:怎么获得“测试集”
测试集应该与训练接“互斥”
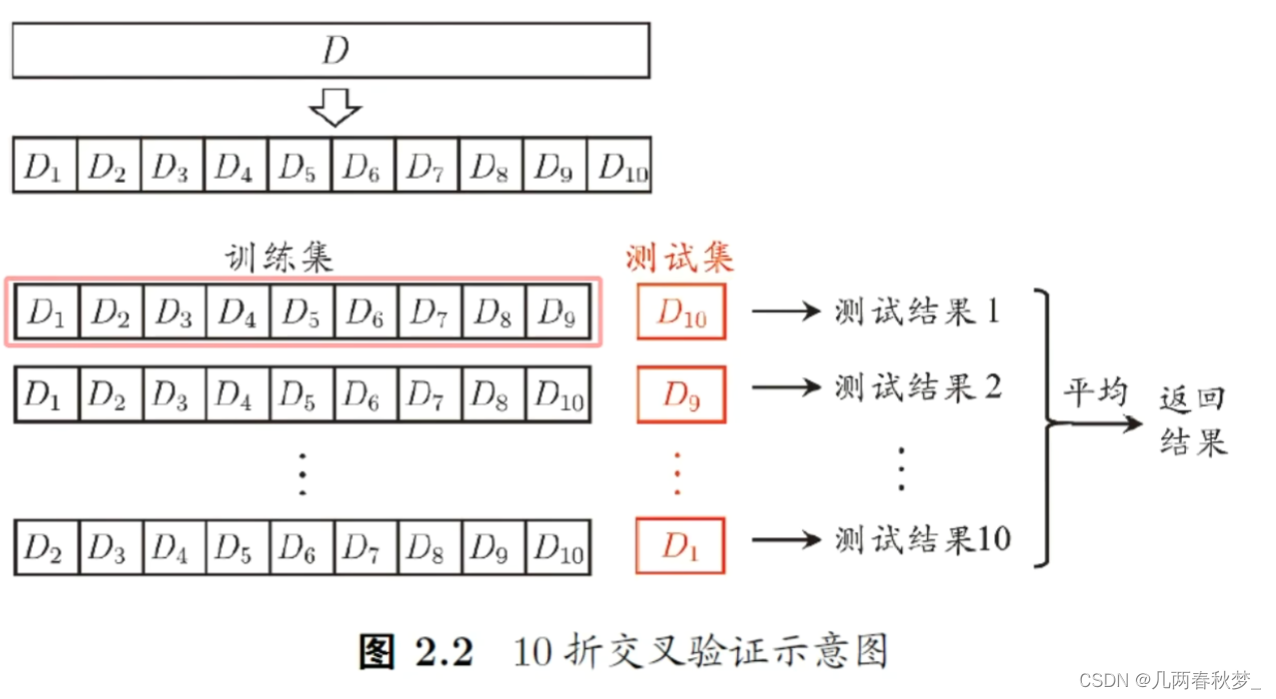
常见方法有:留出法、交叉验证法、自助法
k-折交叉验证法
调参与最终模型:
算法的参数:一般由人工设定,亦称“超参数”
模型的参数:一般由学习确定
调参本身就是一种对模型的选择,
二、如何评估性能优劣 (性能度量)
性能度量是衡量模型泛化能力的评价标准,反映了任务需求。
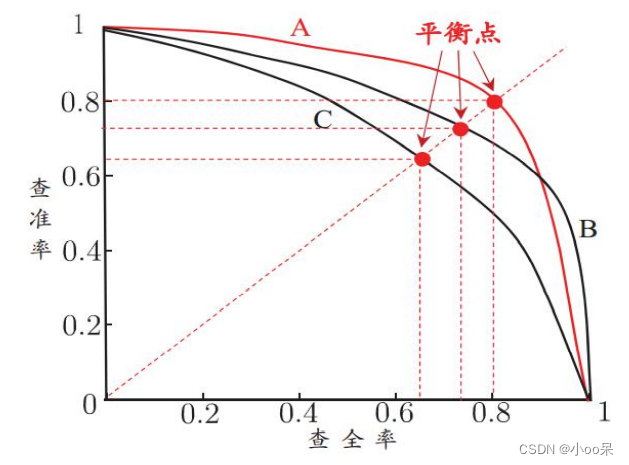
错误率、精度、查准率、查全率、F1度量
三、如何判断实质差别 (比较检验)
统计解设检验为学习器性能比较提供了重要依据。