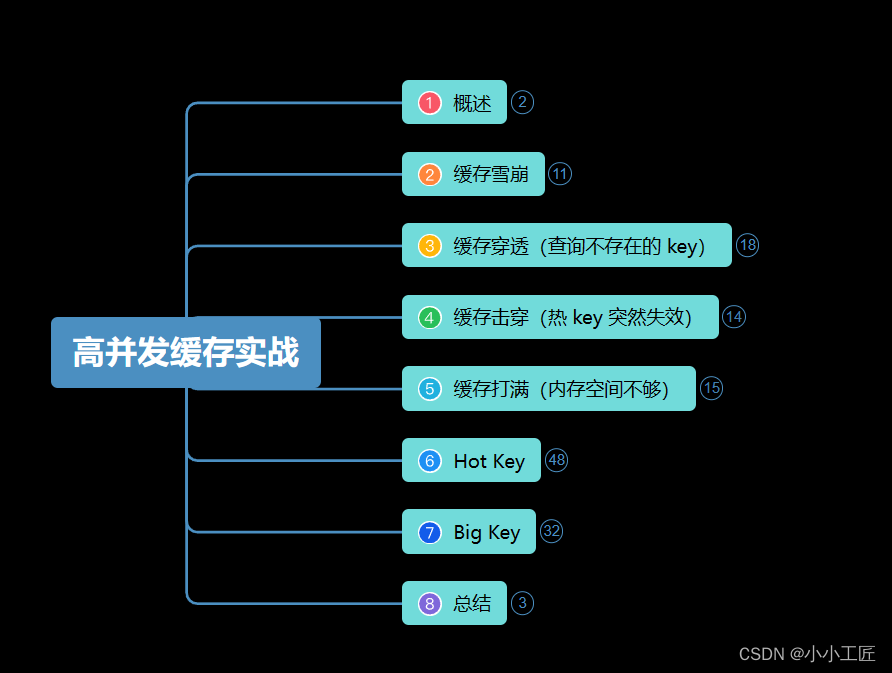
文章目录
- 概述
- 6座大山之_缓存雪崩 (缓存全部失效)
- 缓存雪崩的两种常见场景
- 如何应对缓存雪崩?
- 6座大山之_缓存穿透(查询不存在的 key)
- 缓存穿透的原因
- 解决方案
- 1. 数据校验
- 2. 缓存空值
- 3. 频控
- 4. 使用布隆过滤器
- 6座大山之_缓存击穿(热 key 突然失效)
- 解决思路1:永不过期
- 解决思路2:逻辑过期
- 解决思路3:互斥锁
- 6座大山之_缓存打满(内存空间不够)
- Redis的淘汰策略
- 发生场景
- 解决方案
- 6座大山之_Hot Key
- 发现热 Key
- 处理热 Key
- 6座大山之_Big Key
- 问题:
- 可能发生的场景:
- 发现大 Key的方法:
- 删除大 Key的方法:
- 避免产生大 Key的方法:

概述
在高并发系统中,Redis缓存通常被视为数据在存入数据库之前的重要中间层,其设计专注于缓存功能,性能往往比传统数据库高出一个数量级以上。以Redis单实例而言,其读取并发能力可达到10万QPS(官方理论值)。
然而,正因为Redis的高并发处理能力,它在系统链路中扮演着至关重要的角色。一旦系统遭遇高峰期,若我们在Redis处理方面稍有疏忽,可能会导致整个系统瘫痪。
因此,我们接下来将探讨在复杂、高并发的互联网系统中,缓存可能面临的一系列挑战,以及我们可以采取的措施来应对这些挑战。
6座大山之_缓存雪崩 (缓存全部失效)
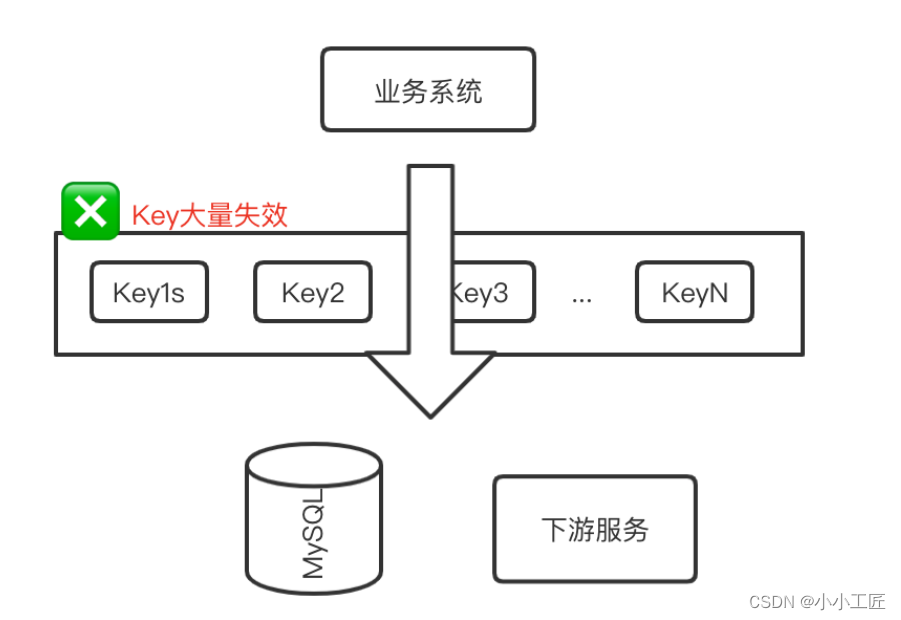
在高并发系统中,缓存(通常是Redis)扮演着重要的角色,它被视为数据库的保护伞,能够有效减轻数据库负载。然而,有时候我们可能会面临一个令人头疼的问题:缓存竟然完全失效了,而流量却突然间涌向了数据库,最终可能导致整个系统的不可用。这种情况被称为缓存雪崩。
缓存雪崩的两种常见场景
-
Redis集群不可用: 即使Redis是以集群模式部署,但当集群中的某个节点不可用时(如重启),如果没有合理的容错机制,可能会导致大量缓存同时失效,从而压垮数据库。
-
大量缓存集中失效: 在缓存预热过程中,如果将大量缓存集中预热或更新,那么这些缓存可能在同一时间突然失效,导致系统出现雪崩效应。
如何应对缓存雪崩?
-
合理部署Redis集群: 将Redis部署为集群模式,确保数据在多个节点上存在,即使某个节点不可用,也不至于导致所有缓存失效。跨机房部署可以进一步提高容灾能力。
-
持久化数据并预热缓存: 在重启Redis等操作前,通过SAVE指令将数据持久化,或者在重启后人工触发缓存预热,确保缓存不会因为重启而全部失效。
-
随机设置过期时间: 对于集中预热的缓存数据,设置过期时间时增加一定的随机性,使得缓存失效时间分散,避免集中失效导致的雪崩效应。


6座大山之_缓存穿透(查询不存在的 key)
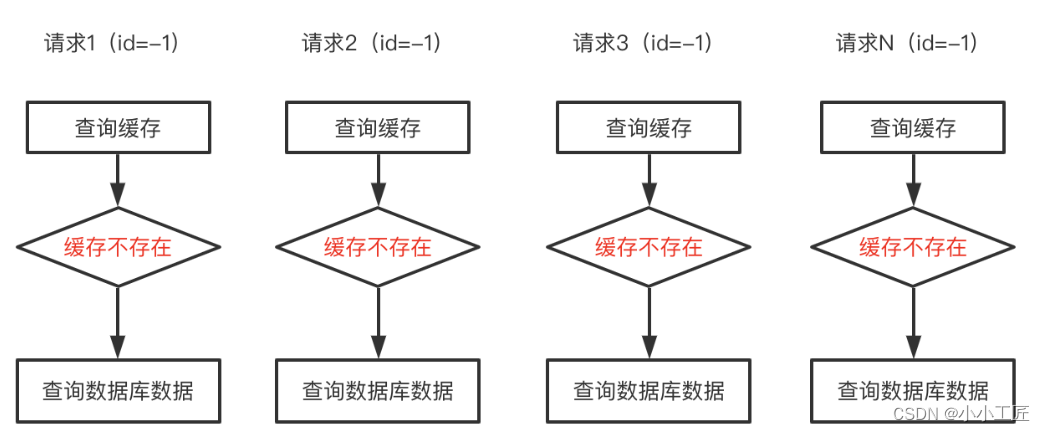
在缓存系统中,缓存穿透是一种常见而又令人头疼的问题。当用户请求查询缓存中不存在的数据时,这些请求会直接穿透缓存打到数据库,可能导致数据库负载过大,甚至引发系统崩溃。特别是在攻击者持续发起此类请求的情况下,这种攻击行为会对系统造成严重影响。
缓存穿透的原因
缓存穿透通常发生在以下情况下:
-
查询不存在的数据: 当用户请求查询缓存中不存在的数据时,如果缓存未命中,请求就会直接打到数据库,导致缓存穿透现象的发生。
-
恶意攻击: 攻击者可能会利用此漏洞,不断发起查询不存在数据的请求,造成数据库压力过大,甚至拖垮整个系统。
解决方案
1. 数据校验
在接入层对请求数据进行严格的校验,例如检查ID是否为正整数、参数范围是否合法等,以过滤掉非法请求,避免其穿透缓存直接访问数据库。
2. 缓存空值
对于查询不到的数据,可以在缓存中存储一个特殊的“null”值,下次请求命中缓存时直接返回。但需注意设置空值缓存的过期时间,避免缓存空间被占满。
3. 频控
针对恶意攻击者,可实施频率限制策略,例如基于IP地址进行频控,及时拒绝异常请求,以保护数据库不受攻击。
4. 使用布隆过滤器
布隆过滤器是一种高效的数据结构,可用于判断元素是否存在,但有一定的误判率。可以将所有数据存储在布隆过滤器中,查询缓存前先检查布隆过滤器,如果不存在则直接返回,从而避免不必要的缓存/数据库查询。
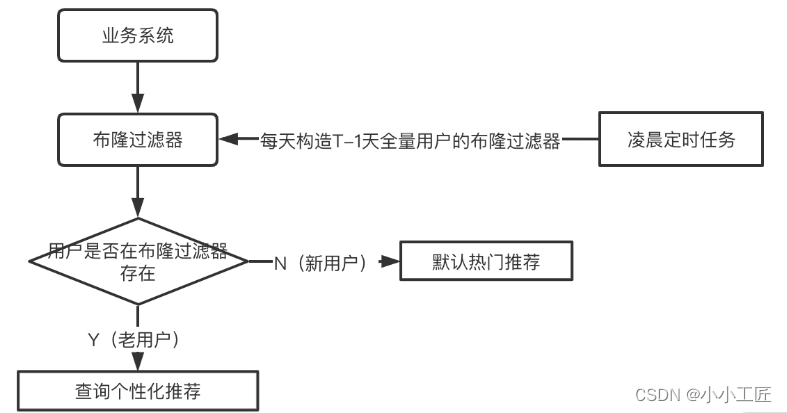
–
缓存穿透是高并发系统中常见的问题,但通过合理的预防措施和技术手段,我们可以有效地减轻其影响。在设计和开发过程中,应注重数据校验、缓存空值设置、频率限制以及布隆过滤器等措施的应用,以确保系统的稳定和安全运行。
6座大山之_缓存击穿(热 key 突然失效)
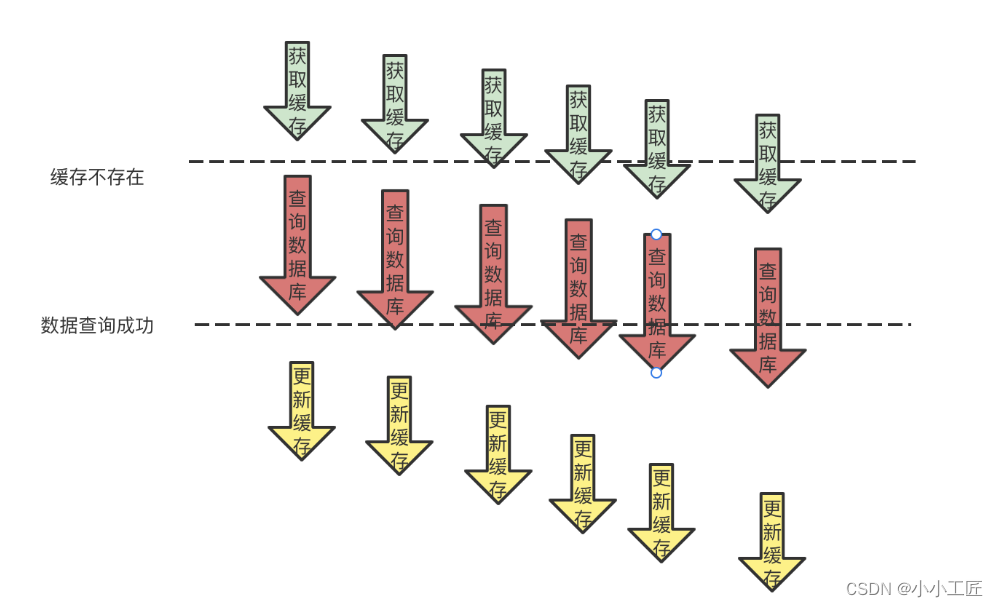
在缓存系统中,缓存击穿是一种常见但十分危险的现象。当一个热门的缓存 key 在失效瞬间,大量请求同时打到数据库,可能会导致数据库压力过大,甚至引发系统崩溃。
为应对这一挑战,我们可以采取以下解决方案:
解决思路1:永不过期
针对某些热门的 key,可以选择不设置过期时间,而是采用定时任务或定时更新的方式,以避免 key 失效的情况。
解决思路2:逻辑过期
对于不适合永不过期的全量 key,可以设置一个逻辑过期时间。即在缓存中存储数据的同时,记录数据的逻辑过期时间,定时任务异步地重新刷新缓存,并重新设置其物理过期时间和逻辑过期时间。
例如 Key1=Value1 这样的缓存,过期时间是 2024.10.01.00:00,那么物理过期时间可能设置在 2024.10.01.01:00,但是我们将 value 这样存储
{v:"Value1",t:1727715600}当读取到这个数据过期的时候,我们让任务异步地去重新刷新这个缓存,并重新设置其物理过期时间和逻辑过期时间,这样击穿到数据库的线程就可控为一条异步线程了。
这里的原则是物理过期时间一定要比逻辑过期时间久
解决思路3:互斥锁
使用互斥锁,在发现缓存不存在时加锁,只允许一条线程去数据库查询真实数据,其他线程等待。通过双重检查机制,确保数据在锁被释放前已被写入缓存,从而避免多次数据库访问。

public String query(String key) {String data = stringRedisTemplate.opsForValue().get(key);if (StringUtils.isEmpty(data)) {RLock locker = redissonClient.getLock("locker_" + key);if (locker.tryLock()) {try {data = stringRedisTemplate.opsForValue().get(key);if (StringUtils.isEmpty(data)) {data = getDataFromDB(key);stringRedisTemplate.opsForValue().set(key, data, 5, TimeUnit.SECONDS);}} finally {locker.unlock();}} else {Thread.sleep(100);return query(key);}}return data;
}
以上是利用 Redisson 实现的分布式锁示例,确保只有一条线程去数据库查询数据,其他线程等待或递归查询缓存,以防止缓存击穿。
之所以使用 1 个分布式锁,这样才能放 1 条线程去数据库访问,但是真实使用的时候并不需要做得这么重,只需要进程级别的加锁即可,因为我们服务的数量通常是有限且不大的,那么有限的并发打到数据库,做一些重复的工作也并不会太影响。

缓存击穿是高并发系统中常见的问题,但通过合理的策略和技术手段,我们可以有效地预防和应对这一挑战。重视缓存设计和管理,结合适当的方案,可以有效地保护数据库并确保系统的稳定运行。
6座大山之_缓存打满(内存空间不够)

在Redis中,内存是有限的,当内存使用达到上限时,需要采取一些策略来淘汰一定不使用的key,以释放空间存储新的key。这个上限由配置的maxmemory参数决定,无论是否开启持久化,都会触发淘汰策略。
maxmemory 100mb
Redis的淘汰策略
-
noeviction(默认): 不删除任意数据,但根据引用计数器进行释放,当内存不足时直接返回错误。
-
volatile-lru: 选择最近最少使用的带过期时间的数据进行淘汰。
-
allkeys-lru: 选择最近最少使用的数据进行淘汰,包括带过期时间和不带过期时间的数据。
-
volatile-lfu: 选择使用频率最低的带过期时间的数据进行淘汰。
-
allkeys-lfu: 选择使用频率最低的数据进行淘汰,包括带过期时间和不带过期时间的数据。
-
volatile-random: 随机选择一个带过期时间的数据进行淘汰。
-
allkeys-random: 随机选择一个数据进行淘汰,包括带过期时间和不带过期时间的数据。
-
volatile-ttl: 选择最接近过期的数据进行释放操作,只从带过期时间的数据集中选择。
发生场景
-
把Redis当存储使用: 部分场景下,将Redis用作数据存储,不设置过期时间,可能导致内存持续增长,触发淘汰策略,不正确的淘汰策略可能导致数据丢失。
-
Bug数据逐步污染缓存: 开发人员忘记设置过期时间,或设置过期时间过长,导致缓存内存被占满。
解决方案
-
存储隔离: 对于永不过期的数据,要与正常的缓存数据做集群的分离,以便设置不同的淘汰策略。
-
容量监控:
- 预估使用容量,给予足够的冗余应对业务发展。
- 实时监控使用量变化,一旦超过阈值,立即扩容并排查原因。
- 监控key的过期时间,定期扫描,发现未设置过期时间或设置不合理的key,并及时修复。
在实际应用中,结合合适的淘汰策略和监控手段,能够更好地管理Redis缓存,保障系统的稳定性和可靠性。
6座大山之_Hot Key
热 Key 是指在Redis中频繁访问的某些特定key,可能导致单个实例的性能问题。即使对Redis进行扩容,也无法完全解决热 Key 问题,因为对于同一个key的访问通常会集中在同一个实例上。
热 Key 问题可能导致接口超时、网络负载过大、连接数达到上限等一系列问题,严重影响系统稳定性和性能。
发现热 Key
-
按业务场景预估热点 key: 根据业务特点预估一些热门key,如促销商品、秒杀商品等。这种方法简单但依赖于人工经验,无法发现意外的热点。
-
客户端收集: 封装代码统计Redis的所有访问命令,对命令进行统计分析。简单方便但需要代码修改。
-
代理层收集: 在访问Redis之前添加访问代理层,代理层收敛请求并进行统计。无代码侵入但架构复杂。
-
Redis监控命令: 使用Redis提供的监控命令,如
hotkeys命令,实时监控热 Key。无代码侵入但对大集群扫描较慢。
# 统计间隔0.1秒输出一次hotkeysredis-cli --hotkeys -i 0.1root@root:~# redis-cli --hotkeys -i 0.1# Scanning the entire keyspace to find hot keys as well as# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec# per 100 SCAN commands (not usually needed).[00.00%] Hot key 'aaa' found so far with counter 1-------- summary -------Sampled 4 keys in the keyspace!hot key found with counter: 1 keyname: aaa- 网络抓包分析: 抓取Redis服务器侧的包进行分析,发现流量倾斜和热 Key。无代码侵入但可能恶化现有问题。
处理热 Key
-
本地缓存: 在访问Redis之前加一层本地缓存,将部分热 Key 存储在本地。需要合理设计淘汰策略和热 Key 发现机制。
-
本机Redis备机: 将Redis备机部署在本地,充当本地缓存的角色。需要考虑一致性和维护成本。
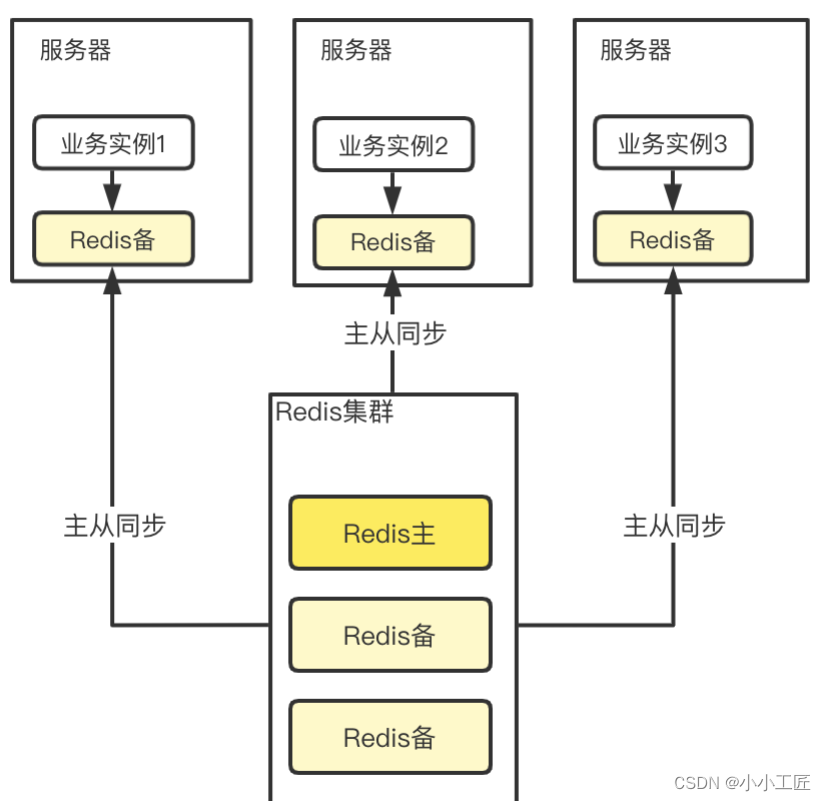
-
备份存储: 将热 Key 备份成多份,分布在不同实例上,分散流量。需要设计合适的备份策略。
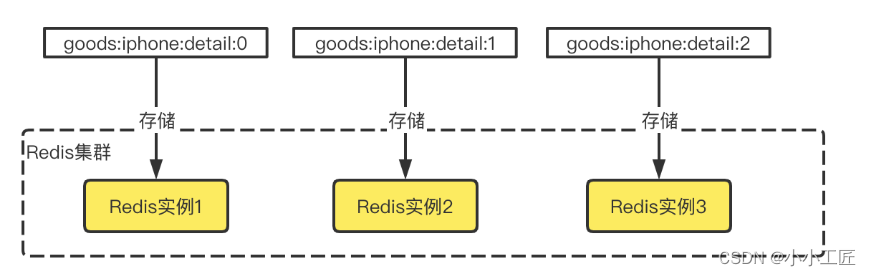
Cluster 模式下某个 key 是存储在固定的某个实例上的,所以热 key 才如此棘手,因为所有流量都打到同一个实例上。那么有没有可能打散这些流量呢?
答案是有可能的。如果我们把热 key 备份成 N 份,例如,原 key 是 goods📱detail,那么这 N 份的 key 就分为 goods:iphone:detail:0,goods:iphone:detail:1,goods:iphone:detail:2,……,goods:iphone:detail:N-1,分散在集群的多个节点,查询的时候可以按照一定的散列规则分散去访问不同的 key 副本,规则可以选择随机散列、按用户散列等。
随机散列的示意 Java 代码如下:
int N = M * 2//M是集群里的节点数,得到备份数量//生成随机数int random = new Random().nextInt(N);//构造备份新keyString bakHotKey = hotKey + “_” + random;String data = getFromRedis(bakHotKey);if (data == null) {//查询不到缓存,从数据库查询出来放到对应的备份Keydata = getFromDB();saveToRedis(bakHotKey, expireTime);}注:以上代码中 N 取了节点数 2 倍的原因是,由于 Redis 的散列存储算法是内置固定的,我们无法 100% 保证不同的备份 key 肯定落在不同副本上,所以 N 的取值上取了一点冗余。
-
读写分离: 开启读写分离,利用备节点扛住读流量。适用于热 Key 主要是读场景的情况。
-
京东hotkeys框架: 京东开源的hotkeys框架可用于实时侦测热 Key,并自动推送到本地缓存。适用于电商等场景的热 Key 发现和处理。
6座大山之_Big Key
大 Key在Redis中是一项棘手的问题,因为它会导致多种性能和稳定性问题,包括内存倾斜、网络阻塞和阻塞查询。以下是关于大 Key的问题以及解决方案的详细说明:
问题:
-
内存倾斜: 大 Key存在于集群的某个实例上,导致该实例的内存占用和CPU负载过大,成为系统的隐患点。
-
网络阻塞: 大 Key的操作可能导致网络I/O成为瓶颈,尤其是涉及到hgetall、get、hmget等操作时。
-
阻塞查询: Redis内部处理大 Key时是单线程处理的,大 Key的操作耗时,会阻塞其他语句的执行,影响整个集群的服务能力。
可能发生的场景:
-
部分列表类存储: 例如,存储粉丝列表或商品列表的大型数据结构。
-
统计类的集合: 需要按天统计某类用户的集合,随着用户数量的增加,该Key的大小也会增加。
-
大数据缓存类: Redis作为数据库缓存,若缓存的数据量过大,例如将几万行的数据存储为一个JSON,就会产生大Key。
发现大 Key的方法:
-
分析RDB文件: 对RDB文件进行分析,找出其中的大Key。
-
scan+debug: 结合scan命令和debug object命令,筛选出当前实例所有Key的大小,找到大Key。
-
redis-cli --bigkeys: 使用redis-cli的bigkeys命令,找到实例中各种数据类型的最大Key。
删除大 Key的方法:
-
Lazy Free: Redis 4.0提供了异步延时释放Key内存的功能,将释放操作放在后台线程处理,减少对主线程的阻塞。
-
UNLINK命令: Redis 4.0.0引入了UNLINK命令,其时间复杂度是O(1),能够快速删除大Key。
-
集合scan命令: 对于低版本的Redis,可以使用集合配套的scan命令分批删除大Key的元素。
避免产生大 Key的方法:
拆分: 在设计阶段,针对可能成为大 Key的数据结构,采取拆分策略,将大数据集拆分成多个子集,避免单个Key过大。
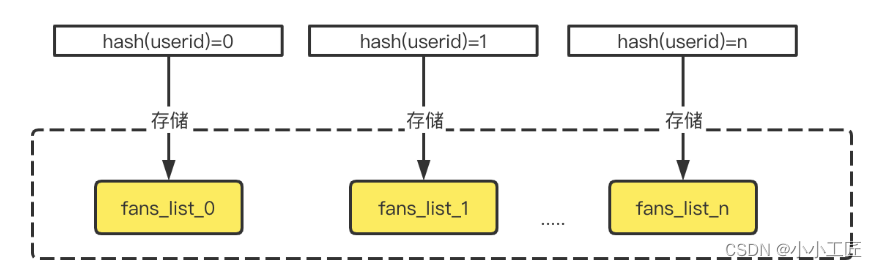
例如一个粉丝列表 list。针对一些大 V 博主,我们可以按照粉丝的 userid 决定其存在于哪个 list,拆分成 list0、list1、list2、list3 等。针对一个大的 hash,我们也可以将不同的 field 分散成多个子 hash,并且要先计算在哪个子 hash 中进行获取.
解决大 Key问题需要综合考虑系统设计、数据存储和操作方式等多个方面,以确保系统的性能和稳定性。