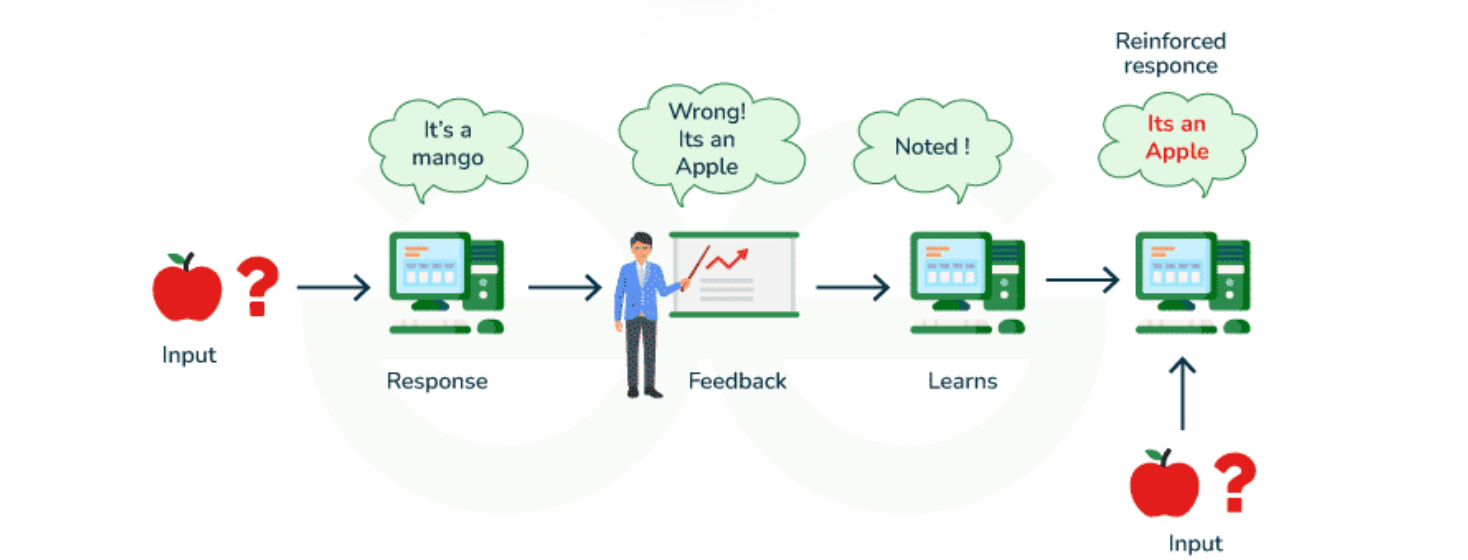
目标记录
["你好,我的爱人","你好,我的爱妻","你好,我的病人","世界真美丽"]
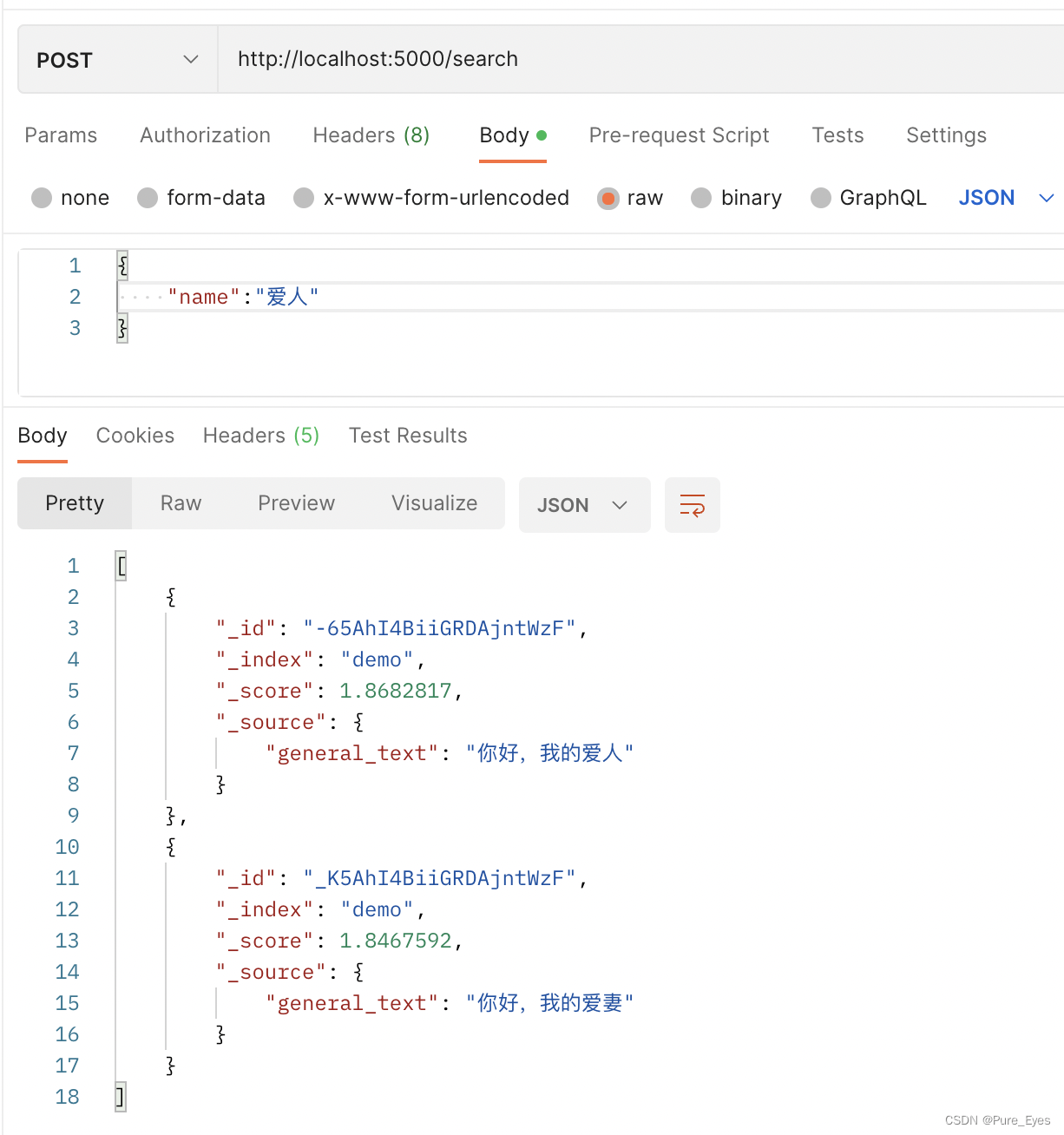
搜索词
爱人
预期返回
["你好,我的爱人","你好,我的爱妻"]
示例代码:
代码连接 es8以及bge-large-zh模型,
bge-large-zh用来将文本转换为向量数据
es用来存储向量数据,并根据向量来搜索相似度最高的文本(相似度可以用阈值调整)
from flask import Flask, request # 导入Flask类
from FlagEmbedding import FlagModel
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulkapp = Flask(__name__) # 实例化并命名为app实例
model = FlagModel('./models/bge/bge-large-zh', query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:")
# 创建Elasticsearch客户端对象
es = Elasticsearch(hosts="http://localhost:9200")
es.ping()@app.route('/ins', methods=['POST'])
def index(): data = request.get_json()print(data)strs = data["strs"]documents = []for str in strs: print(str)tmp = model.encode(str)documents.append({"general_text": str,"general_text_vector": tmp,# "domain":"001"})documentsbulk(es, documents, index="demo")return success(1)@app.route('/search', methods=['POST'])
def search():data = request.get_json()doc_vector = model.encode(data["name"])results = es.search(index="demo",source=["general_text", ],min_score= 1.83,query={"script_score": {"query": { "match_all": {} },"script": {"source": "cosineSimilarity(params.queryVector, 'general_text_vector') + 1.0","params": {"queryVector": doc_vector.tolist()}}}},size=1000)# return resultsreturn results['hits']['hits']def success(data):return {"status": "success","result": data}def fail(data):return {"status": "fail","result": data}if __name__ == "__main__":# Runport = 5000app.run(host='127.0.0.1', port=port, debug=False, use_reloader=False)es存储数据

搜索结果