文章目录
- 2. 两数相加
- 23. 合并 K 个升序链表
- 25. K 个一组翻转链表
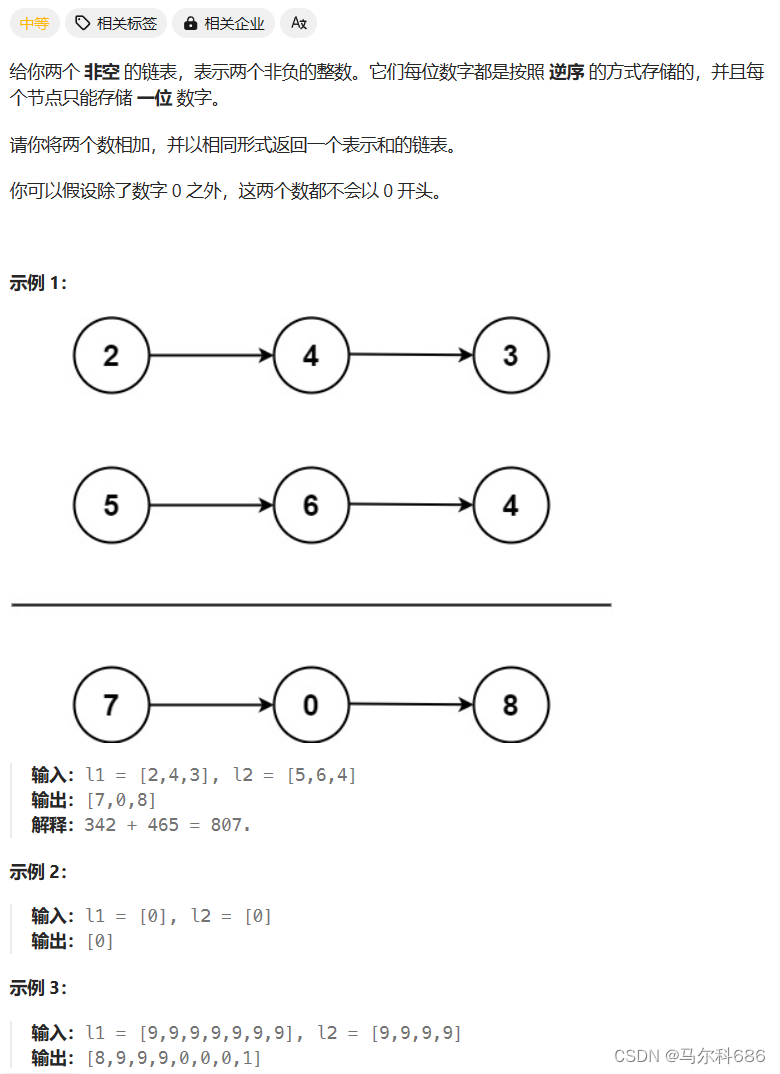
2. 两数相加
题目链接: leetcode2. 两数相加
class Solution {public ListNode addTwoNumbers(ListNode l1, ListNode l2) {ListNode cur1 = l1,cur2 = l2;ListNode newHead = new ListNode(0);ListNode prev = newHead;int t = 0;while(cur1 != null || cur2 != null || t != 0){if(cur1 != null){t += cur1.val;cur1 = cur1.next;}if(cur2 != null){t += cur2.val;cur2 = cur2.next;}prev.next = new ListNode(t%10);prev = prev.next;t /= 10;}return newHead.next;}
}
addTwoNumbers该方法接收两个ListNode类型的参数l1和l2,表示两个非负整数的链表表示。方法的目的是将这两个链表表示的整数相加,并返回一个新的链表表示结果。
代码逻辑如下:
- 创建两个指针cur1和cur2,分别指向l1和l2的头部。
- 创建一个新的链表newHead,用于存储结果。
- 创建一个指针prev,指向newHead。
- 初始化一个变量t为0,用于存储进位值。
- 使用while循环,当cur1、cur2不为空或者t不等于0时,执行以下操作:
- 如果cur1不为空,将cur1的值加到t上,并将cur1指向下一个节点。
- 如果cur2不为空,将cur2的值加到t上,并将cur2指向下一个节点。
- 创建一个新的节点,值为t对10取模的结果,并将其添加到prev后面。
- 更新prev为新添加的节点。
- 将t除以10,得到新的进位值。
- 返回newHead的下一个节点,即结果链表的头节点。
23. 合并 K 个升序链表
题目链接: leetcode23. 合并 K 个升序链表

解法一:优先级队列
题解代码:
class Solution {public ListNode mergeKLists(ListNode[] lists) {// 1.创建一个小根堆PriorityQueue<ListNode> heap = new PriorityQueue<>((v1,v2) -> v1.val - v2.val);// 2.把所有的头结点放进小根堆中for(ListNode head : lists){if(head != null){heap.offer(head);}}// 3.合并链表ListNode ret = new ListNode(0);ListNode prev = ret;while(!heap.isEmpty()){ListNode t = heap.poll();prev.next = t;prev = t;if(t.next != null) heap.offer(t.next);}return ret.next;}
}
下面这个代码创建了一个优先级队列(PriorityQueue),用于存储ListNode类型的对象。优先级队列的排序规则是按照ListNode对象的val属性值进行升序排列。
PriorityQueue<ListNode> heap = new PriorityQueue<>((v1,v2) -> v1.val - v2.val);
如果优先级队列的排序规则是按照ListNode对象的val属性值进行降序排列,代码如下:
PriorityQueue<ListNode> heap = new PriorityQueue<>((v1, v2) -> v2.val - v1.val);
下面这段代码它遍历一个名为lists的ListNode类型的列表。对于列表中的每个元素(这里称为head),如果该元素不为null,就将其添加到一个名为heap的优先级队列中。
解析:
for(ListNode head : lists):这是一个增强型for循环,用于遍历名为lists的ListNode类型的列表。每次循环,都会将列表中的一个元素赋值给变量head。if(head != null):这是一个条件判断语句,用于检查变量head是否为null。如果head不为null,则执行大括号内的代码。heap.offer(head):这是将变量head添加到名为heap的优先级队列中。offer()方法是Java的Queue接口中的方法,用于在队列的尾部插入一个元素。
代码:
for(ListNode head : lists){if(head != null){heap.offer(head);}
}
下面这段代码的主要功能是将一个链表(由ListNode节点组成)从堆中取出并重新组合。
首先,创建一个新的ListNode节点ret,并将其值设为0。然后,创建一个prev指针,指向ret。
然后,进入一个while循环,条件是堆不为空。在循环中,首先从堆中取出一个元素(即链表的一个节点),然后将prev的下一个节点设置为这个取出的元素。然后,将prev移动到这个新添加的节点上。
如果取出的节点的下一个节点不为空,那么将这个下一个节点添加到堆中。这样,就可以保证链表的顺序不变。
这个过程会一直进行,直到堆为空。最后,返回ret.next,即重新组合后的链表的头节点。
// 3.合并链表ListNode ret = new ListNode(0);ListNode prev = ret;while(!heap.isEmpty()){ListNode t = heap.poll();prev.next = t;prev = t;if(t.next != null) heap.offer(t.next);}
解法二:分治 - 递归
class Solution {public ListNode mergeKLists(ListNode[] lists) {return merge(lists, 0, lists.length - 1);}public ListNode merge(ListNode[] lists, int left, int right) {if (left > right) return null;if (left == right) return lists[left];// 1. 先平分数组int mid = (left + right) / 2;// [left, mid] [mid + 1, right]// 2. 递归处理左右两部分ListNode l1 = merge(lists, left, mid);ListNode l2 = merge(lists, mid + 1, right);// 3. 合并两个有序链表return mergeTwoList(l1, l2);}public ListNode mergeTwoList(ListNode l1, ListNode l2) {if (l1 == null) return l2;if (l2 == null) return l1;// 合并两个有序链表ListNode head = new ListNode(0);ListNode cur1 = l1, cur2 = l2, prev = head;while (cur1 != null && cur2 != null) {if (cur1.val <= cur2.val) {prev.next = cur1;prev = cur1;cur1 = cur1.next;} else {prev.next = cur2;prev = cur2;cur2 = cur2.next;}}if (cur1 != null) {prev.next = cur1;}if (cur2 != null) {prev.next = cur2;}return head.next;}
}
这段代码实现了一个名为Solution的类,其中包含了三个方法:mergeKLists、merge和mergeTwoList。
-
mergeKLists方法是整个算法的入口点,它接受一个ListNode数组作为输入,表示要合并的K个有序链表。该方法调用了merge方法来执行合并操作,并返回合并后的链表头节点。 -
merge方法是一个递归方法,用于将给定范围内的链表进行合并。它首先判断左边界是否大于右边界,如果是,则返回空值(表示没有需要合并的链表)。如果左边界等于右边界,则直接返回该链表。否则,它将范围分为两半,分别递归地调用merge方法来合并左右两部分,并将结果传递给mergeTwoList方法进行最终的合并操作。 -
mergeTwoList方法用于合并两个有序链表。它首先判断其中一个链表是否为空,如果是,则直接返回另一个链表。然后,它创建一个新的头节点head和一个指针prev,用于构建合并后的链表。通过比较两个链表当前节点的值,选择较小的节点连接到新链表中,并更新指针位置。最后,如果有一个链表还有剩余节点,将其连接到新链表的末尾。最终返回新链表的头节点。
这段代码使用了分治的思想,通过递归地将问题划分为更小的子问题来解决。在每一步中,它将链表数组分成两半,并递归地合并这两部分。最后,通过mergeTwoList方法将两个有序链表合并成一个有序链表。
25. K 个一组翻转链表
题目链接: leetcode25. K 个一组翻转链表

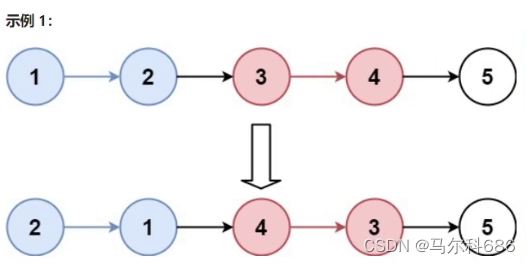
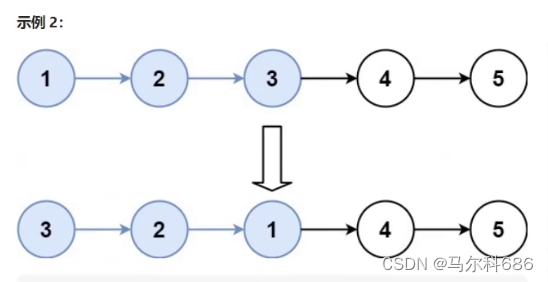
解法:模拟
- 先求出需要逆序多少组:n
- 重复n次,长度为k的链表的逆序即可(头插法)
class Solution {public ListNode reverseKGroup(ListNode head, int k) {// 1.先求出需要逆序多少组int n = 0;ListNode cur = head;while(cur != null){cur = cur.next;n++;}n /= k;// 2.重复n次 :长度为k的链表的逆序ListNode newHead = new ListNode(0);ListNode prev = newHead;cur = head;for(int i = 0; i < n; i++){ListNode tmp = cur;for(int j = 0; j < k; j++){// 头插ListNode next = cur.next;cur.next = prev.next;prev.next = cur;cur = next;}prev = tmp;}// 把后面不需要逆序的连接上prev.next = cur;return newHead.next;}
}
reverseKGroup该方法接收两个参数:一个ListNode类型的head和一个整数k。这个方法的目的是将链表中的节点按照k个一组进行逆序排列。
- 首先,通过遍历链表,计算出需要逆序的组数n。
- 然后,重复n次以下操作:长度为k的链表的逆序。在这个过程中,使用头插法将当前节点插入到新链表的头部。
- 最后,将剩余不需要逆序的节点连接到新链表的尾部,并返回新链表的头节点。
// 2.重复n次 :长度为k的链表的逆序ListNode newHead = new ListNode(0);ListNode prev = newHead;cur = head;for(int i = 0; i < n; i++){ListNode tmp = cur;for(int j = 0; j < k; j++){// 头插ListNode next = cur.next;cur.next = prev.next;prev.next = cur;cur = next;}prev = tmp;}
这段代码的功能是将一个链表按照长度为k的子链表进行逆序排列。具体实现如下:
- 创建一个新链表newHead,用于存储逆序后的结果。
- 使用两个指针prev和cur,分别指向新链表的尾部和原链表的头部。
- 使用一个外层循环,重复n次,其中n为需要逆序的组数。
- 在外层循环中,使用一个内层循环,重复k次,将当前子链表逆序插入到新链表中。
- 在内层循环中,首先记录当前节点的下一个节点next。
- 然后,将当前节点的next指针指向prev的下一个节点,即将当前节点插入到新链表的头部。
- 更新prev的next指针为当前节点,即prev指向当前节点。
- 更新cur指针为next,即移动到下一个节点。
- 在外层循环结束后,将剩余不需要逆序的节点连接到新链表的尾部。
- 最后,返回新链表的头节点newHead.next。
在这段代码中,"把不需要逆序的连接上"的步骤没有使用循环的原因是因为在之前的步骤中已经完成了所有需要逆序的分组操作。具体来说,由于我们已经按照每k个节点为一组进行了逆序排列,当我们执行到最后一组的时候,这组后面的节点都是不需要再逆序的。
在for循环中,我们重复n次逆序长度为k的链表的操作。每次循环,都会处理一个长度为k的子链表,然后将其逆序连接到之前已经逆序好的链表后面。变量prev在这里扮演了一个指针的角色,它始终指向当前逆序列表的尾部(即已逆序部分的最后一个节点)。
当for循环结束时,cur指针将会指向最后一个逆序好的子链表的下一个节点,也就是第一个不需要逆序的节点。因此,我们可以直接通过赋值prev.next = cur;将不需要逆序的部分连接到已逆序的链表后面。这一步不需要循环,因为剩下的节点已经是正确顺序的,并且只需要一次性地将它们全部连在一起。
总结一下,不使用循环的原因是因为:
- 在逆序的for循环中,我们处理了所有需要逆序的分组。
- 最后剩下的所有节点都不需要逆序,它们已经在正确的顺序中。
- 只需一步就能将这些剩余节点链接到已逆序的链表尾部。
所以,这里的设计是先通过循环处理所有需要特殊处理的节点,然后通过一次简单的赋值操作完成剩余节点的连接,从而避免了不必要的循环。