LPL比赛数据可视化
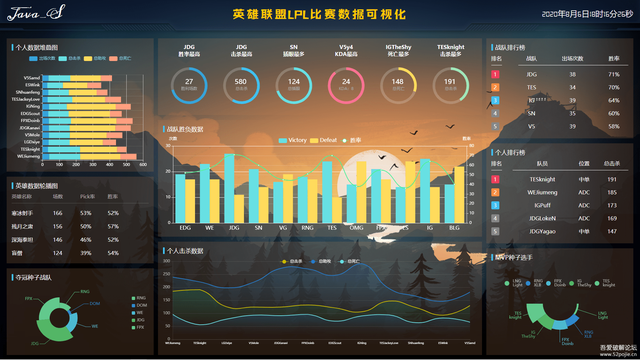
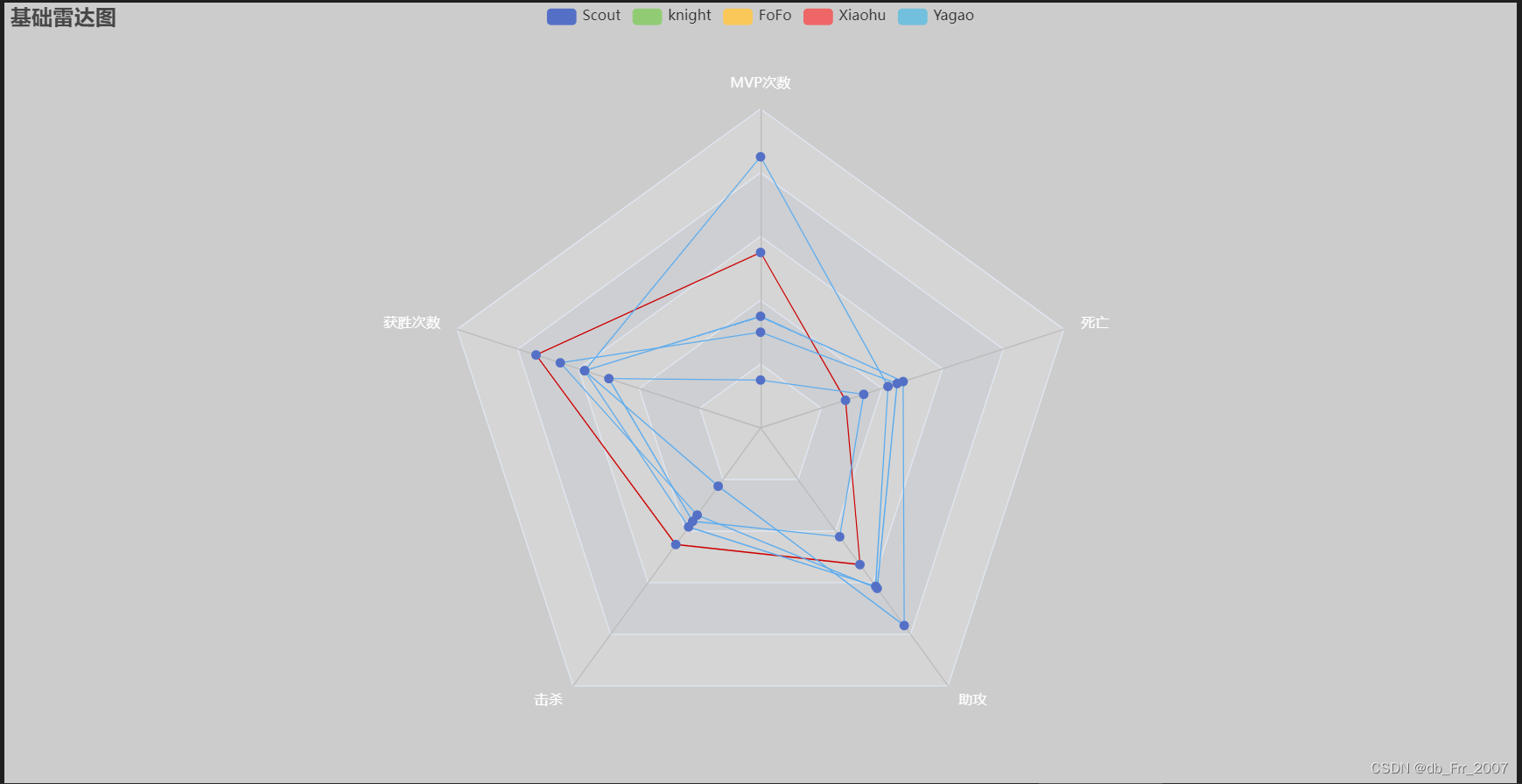
效果图
完成这个项目,我感觉我已经被掏空了,我几乎用尽了我会的所有知识
html+css+javascript+jQuery+python+requests+numpy+mysql+pymysql+json+ajax+flask+echarts
在这个过程中,并不是那么顺利,遇到了很多坑,好在全部都已经解决
在整个页面全部功能运行成功的那一刻,我感觉幸福极了

""" 当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢? 学习Python中有不明白推荐加入交流Q群号:928946953 群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF! 还有大牛解答! """

下面我就带领大家实践一下,怎么从无到有
如果觉得涉及的知识太多,实践起来困难的同学.不要怕,我专门做了一期视频一分钟上手此项目点我观看视频
需要用到的Python第三方库:flask,requests,pymysql,numpy
听说看着源码读python教程文章绝配哦Github

点我直达可视化页面
绘制前端页面
整个页面可划分为10个盒子,使用HTML和CSS就可以把最基础的框架搭建出来,大家都是pink老师的学生,怎么在页面中写盒子我就不多说了,我主要讲解一下如何将echarts的图表插入到页面中来
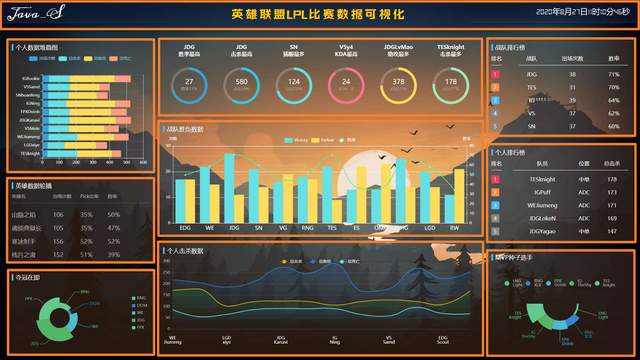
图1
什么是Echarts
Echarts官方网站
ECharts 是一个使用 JavaScript 实现的开源可视化库,涵盖各行业图表,满足各种需求
ECharts 遵循 Apache-2.0 开源协议,免费商用
ECharts 兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari等)及兼容多种设备,可随时随地任性展示
第一个 ECharts 实例
第一个 ECharts 实例源码
!!!!!!
使用Echarts的前提是你需要掌握HTML和Javascript的知识,毕竟Echarts是基于JS开发
观察源码不难发现,引入了外部文件[echarts.js] 如果不引入,程序将无法正常运行
基于准备好的div,绑定事件,初始化echarts实例
指定图表的配置项和数据,即可显示图表
大致流程:引入所需文件,在HTML定义好div盒子,在JS中绑定事件,初始化echarts实例,指定图表的配置项和数据
项目中的Echarts
1.引入所需文件

图2
说明:上面第一个实例将echarts的代码写在了HTML文件中,而我为了后期维护起来方便,就分开写了,所以需要引入[js.js]文件,也就是我把关于echarts的代码都写在了[js.js]文件中
2.在HTML定义好div盒子

图3
3.在JS中绑定事件,初始化echarts实例
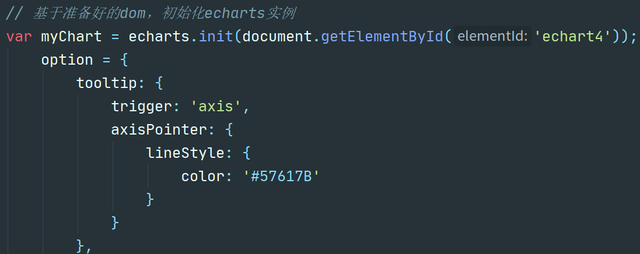
图4
4.指定图表的配置项和数据
代码过多,请到源码中查看
Echarts部分小总结
Echarts部分不是很难,直接到Echarts官网实例中找你想要的图表,然后复制代码,修改图表的配置和数据即可。我知道你肯定要问“代码中的一些属性我根本就不知道怎么去使用,怎么办嘛” 不要方,请到Echarts官网文档查看
项目中一共用了5种Echarts图表,使用的方法大同小异,我相信你可以举一反三

前端的页面绘制完毕后,你会发现一个问题。数据都写死的,而比赛数据几乎每天都在更新。每天去源码中修改对应的数据部分,过不了几天我想你肯定会厌倦。解决的方法肯定是有的,不光只是爬虫,还要向Echarts中插入数据(肯定不是手动插,而是机器插)。欲知后事如何,请往下看
爬取比赛数据
在讲解爬取数据之前,我还是想简单介绍一下什么是爬虫,回答大家对于爬虫的一些误解;假定大家都有一定的爬虫基础
什么是爬虫,爬虫违法吗?
数据从何而来
点我查看官网比赛数据
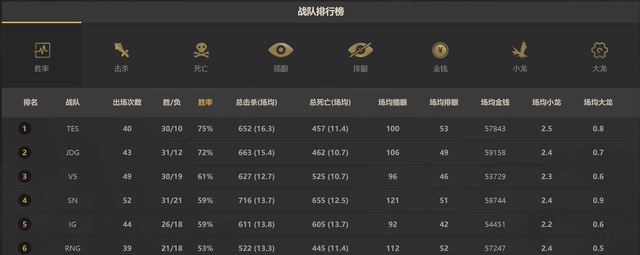
图5
这个网站很特别,是一个动态的网站。如果说只是简单的使用requests获取页面的源码;虽然可以获取到数据,但是数据只有当前显示的一页。我最开始的想法是使用selenium这个可以操控浏览器的第三方库,进行数据的获取。代码写完后,获取数据没什么问题,就是速度太慢了,我也利用requests重新写了爬虫程序,速度提升非常明显(selenium用时20s,requests用时2s;两个程序还包括了将数据写入数据库的代码)
所有,selenium版本的爬虫我不会讲,主要还是讲解requests的版本
现在,我们来到官网,右键点击检查(如果是谷歌浏览器,按F12也可以),点击【Network】
图6
按CTRL+R 刷新一下
在【name】下方找到【
LOL_MATCH2_MATCH_TEAMRANK_LIST_134_7_8.js】,接着点击【Preview】,你就会看到这么一个界面
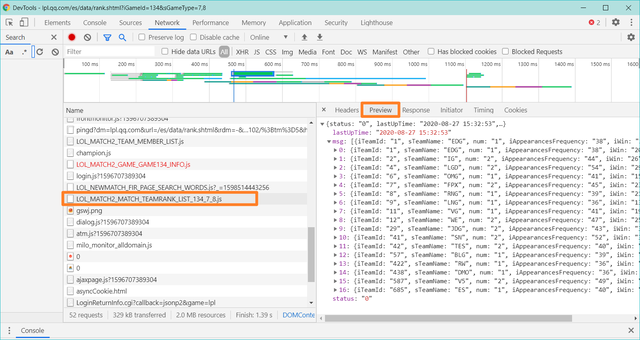
图7
观察右边的数据,是不是就是战队的信息,只不过就是用json包装起来了而已,利用Python简单处理一下就能获取到你想要的数据。这些数据是用接口形式传输的,我们就可以直接爬取接口
点击旁边的【Headers】,复制【Request URL】后面的网址,我们来到Pycharm
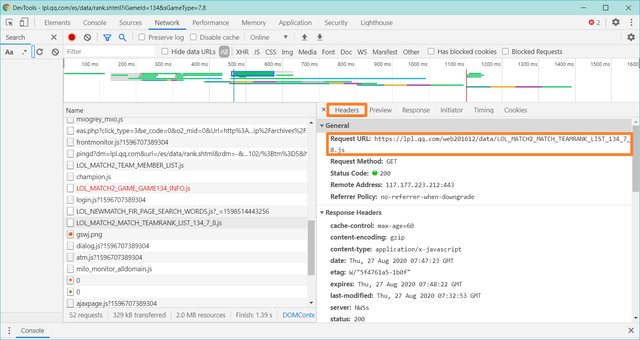
图8
我们打印一下请求的网址
import requestsdef get_info(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'}response = requests.get(url=url,headers=headers)return response.text
info = get_info('https://lpl.qq.com/web201612/data/LOL_MATCH2_MATCH_TEAMRANK_LIST_134_7_8.js')
print(info)Python
输出结果:
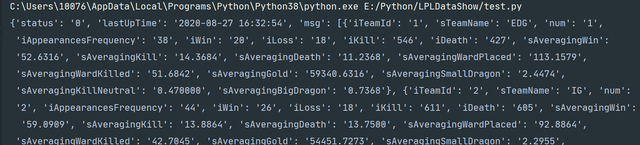
图9
可以看出所有的战队信息已经获取成功,可是输出的内容是一个str(字符串)对象,我们需要使用json.loads()函数将str对象转换为dict(字典)对象。再使用字典和列表的方法就可以将想要的数据提取出来,并且存放到另外一个字典里面
import requests
import jsondef get_info(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'}response = requests.get(url=url,headers=headers)return response.text
info = get_info('https://lpl.qq.com/web201612/data/LOL_MATCH2_MATCH_TEAMRANK_LIST_134_7_8.js')info = json.loads(info) #将str对象转换为dict(字典)对象
info_msg = info['msg'] #使用字典里面的键获取对于的值#队名
teamName = [data['sTeamName'] for data in info_msg]
#出场次数
out_count = [data['iAppearancesFrequency'] for data in info_msg]
#胜场
win = [data['iWin'] for data in info_msg]
#败场
loss = [data['iLoss'] for data in info_msg]
#胜率
win_rate = [int(str((int(data['iWin'])/(int(data['iWin'])+int(data['iLoss'])))*100)[:2]) for data in info_msg]
#总击杀
kill_sum = [data['iKill'] for data in info_msg]
#总死亡
death_sum = [data['iDeath'] for data in info_msg]
#插眼
placed_eye = [int(float(data['sAveragingWardPlaced']))for data in info_msg]
#排眼
killed_eye = [int(float(data['sAveragingWardKilled']))for data in info_msg]infos_list = [('队名',teamName),('出场次数',out_count),('胜场',win),('败场',loss),('胜率',win_rate),('总击杀',kill_sum),('总死亡',death_sum),('插眼',placed_eye),('排眼',killed_eye)]
info_dict = {key:value for key,value in infos_list}
print(info_dict)Python
输出结果:
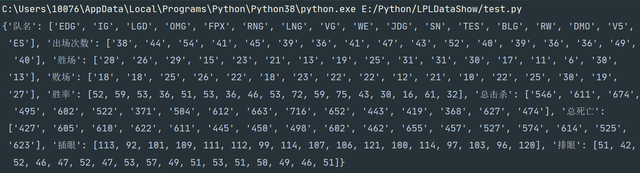
图10
在上面的程序当中,我运用列表推导式,字典推导式,很轻松的就拿到了想要数据。如果你还看不懂推导式,你可以到我这篇文章看看Python高级编程之列表推导式、字典推导式、集合推导式
其实,列表推导式还有更简单的写法,你可以去源码当中的【spider_api.py】文件中,第125行代码查看,117-122行注释的代码就是未优化的代码,留个小小的彩蛋,期待你去发现
聪明的你肯定已经发现了,这只是LPL战队的数据,那么队员和英雄的数据接口在哪里呢,刚才检查网页的时候,也没有发现.不要方,接着往下看

动态网站,其他数据接口在哪里
我们回到官方网站,点击【个人数据】
图11
接着右键检查,找到【
LOL_MATCH2_MATCH_PERSONALRANK_LIST_134_7_8.js】
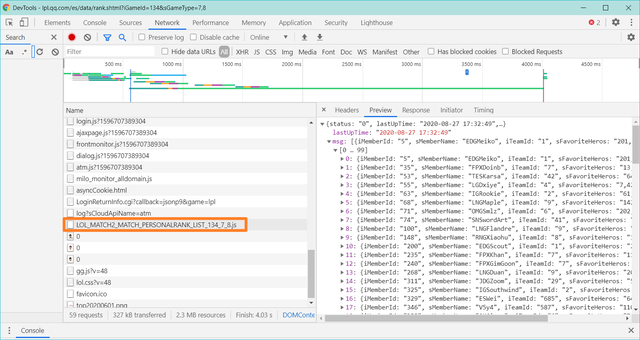
图12
获取数据的方法就和上面的类似了,我相信你可以举一反三
然而,获取英雄数据就不是那么顺利了
还是回到官网,点击【英雄数据】
还是右键检查,找到【
LOL_MATCH2_MATCH_HERORANK_LIST_134_7_8.js】
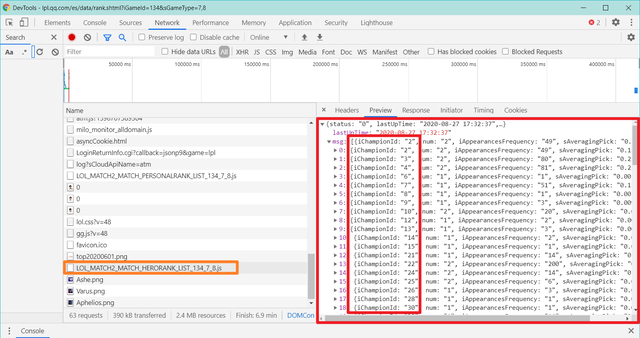
图13
你会惊奇的发现,为什么没有英雄的名字,而只有【iChampionId】和其他数据
于是,我们大胆的猜测,这些【iChampionId】会不会是英雄对应的ID呢?
寻找英雄名称
想查看英雄的名称,我脑袋里面第一个蹦出了的想法就是英雄联盟官网
老规矩,右键检查,找到【hero_list.js】,Amazing呀!
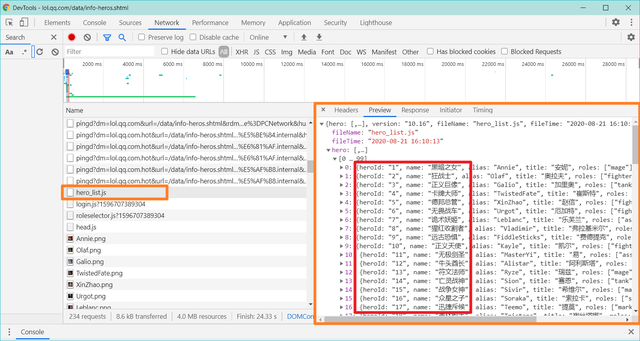
图14
你仔细看,发现英雄名称前面有个【heroId】,会不会就和我们刚才看到的【iChampionId】相对应呢?
你不用去对比啦,我已经对比过了,就是相对应的,嘿嘿

虽然已经找到英雄名称,但是新的问题又来了
从两个接口获取到的数据,怎么保证【iChampionId】的英雄匹配到正确的名称
如何获取数据,我就不多嘴了,详细代码请查看源码.我这里主要讲解一下如何匹配正确的英雄名称
name = []for i in hero_key_id_top60:for j in hero_name_id_list:if i == j :#由于从lpl数据页面无法获取到英雄名称,只能获取到对应的id#一层循环是pick率前60的英雄id,二层是所有英雄的的id#通过if判断,将pick率前60的英雄写入到指定列表中name.append(hero_name_list[hero_name_id_list.index(j)])Python
【hero_key_id_top60】中的内容:

图15
【hero_name_id_list】中的内容:
图16
【hero_name_list】中的内容:

图17
【name 】中的内容:

图18
数据已到位,下一步导入数据库
数据库交互
首先,请在你的电脑上面创建一个名为【lpl】的数据库,不需要建表,后面我会讲解如何用pymysql建表
导入数据
我们需要连接自己的数据库
代码如下,值得注意的是,passwd='你自己数据库的密码'
如果说看不懂代码,可以先去了解一下MySQL和pyMySQL
import pymysqldef mysql():db = pymysql.connect(host='localhost', user='root',passwd='123456', db='lpl', charset='utf8')cur = db.cursor()return db,curPython
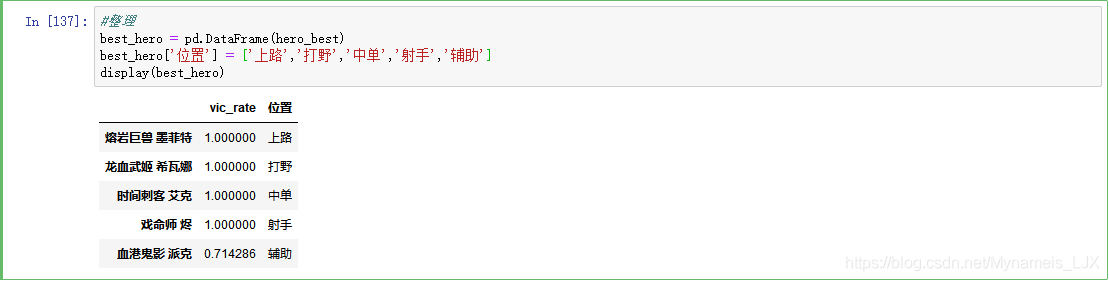
数据库连接成功后,我们以【战队排行榜】为例
db, cur = mysql()try:# 是否存在这个表,若存在就删除,【战队排行榜前五】为表的名称cur.execute("DROP TABLE IF EXISTS 战队排行榜前五")# 创建表sql语句set_sql_top5 = """ create table 战队排行榜前五(战队名称 varchar(20),出场次数 varchar(10),胜率 varchar(10))"""# 执行sql语句cur.execute(set_sql_top5)db.commit() # 保存# 准备写入数据的sql语句save_sql_top5 = "INSERT INTO 战队排行榜前五 values(%s,%s,%s);"# 写入数据库,参数一:写入的sql语句 参数二:数据,类型为列表,里面的元素类型是元组cur.executemany(save_sql_top5,info_list)db.commit()print("写入数据库成功")except Exception as e:print("创建数据库失败:case%s" % e)Python
【info_list】当中的数据

图19
数据库中的数据
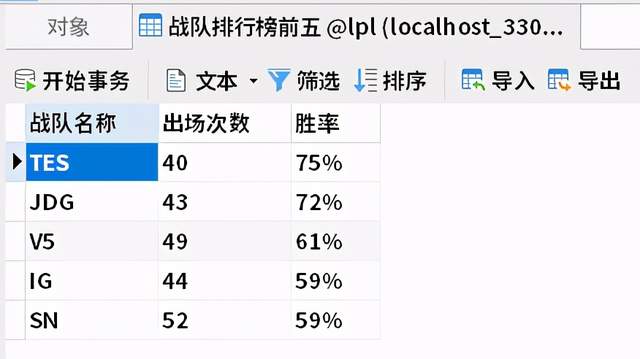
图20
取出数据
数据库还是需要连接的,我们任然以【战队排行榜】为例
import pymysqldef mysql():db = pymysql.connect(host='localhost', user='root',passwd='123456', db='lpl', charset='utf8')cur = db.cursor()return db,cur
def query(sql):db,cur = mysql()cur.execute(sql) #执行传入的sql语句res =cur.fetchall() #获取sql语句字段中的所有数据return res#sql语句,从【战队排行榜前五】这张表中,选择战队名称,出场次数,胜率
sql_wings = 'SELECT 战队名称,出场次数,胜率 FROM 战队排行榜前五'infos_wings = query(sql_wings) #取出数据
#print(infos_wings) : (('TES', '40', '75%'), ('JDG', '43', '72%'), ('V5', '49', '61%'), ('IG', '44', '59%'), ('SN', '52', '59%'))name = [info[0] for info in infos_wings]
out_count = [info[1] for info in infos_wings]
win_rate = [info[2] for info in infos_wings]
infos_list = [('name', name), ('outcount', out_count), ('winRate', win_rate)]#为什么最后要转换成字典的形式,我会在后面向前端传输数据的时候讲解
infos_dict = {key: value for key, value in infos_list}
#print(infos_dict)
#{'name': ['TES', 'JDG', 'V5', 'IG', 'SN'], 'outcount': ['40', '43', '49', '44', '52'], 'winRate': ['75%', '72%', '61%', '59%', '59%']}Python
Web程序开发
什么是Web程序
Web应用程序是一种可以通过Web访问的应用程序。Web应用程序的一个最大好处是用户很容易访问应用程序。用户只需要有浏览器即可,不需要再安装其他软件
能够开发web程序的编程语言有很多,比如Java,Php,Python等
而我们选择用Python进行开发,使用Falsk框架进行快速开发
什么是Falsk
Flask是一个使用 Python编写的轻量级Web应用框架。其WSGl( Python Web Server Gateway Interface)工具包采用 Werkzeug,模板引擎则使用 Jinja2,是目前十分流行的Web框架
这里给大家推荐一期视频,Flask快速入门.由于我的能力有限,还请大家花点时间将视频看完,再接着往后看文章
使用Flask连接前端页面
假定大家已经看完了视频,嘿嘿
使用pycharm创建一个flask项目,会自动帮我们生成两个文件夹【templates】【static】和一个python文件【app.py】
我们需要将写好的HTML文件放在【templates】目录下,CSS、JS和所用到的图片放在【static】目录下,如下图所示
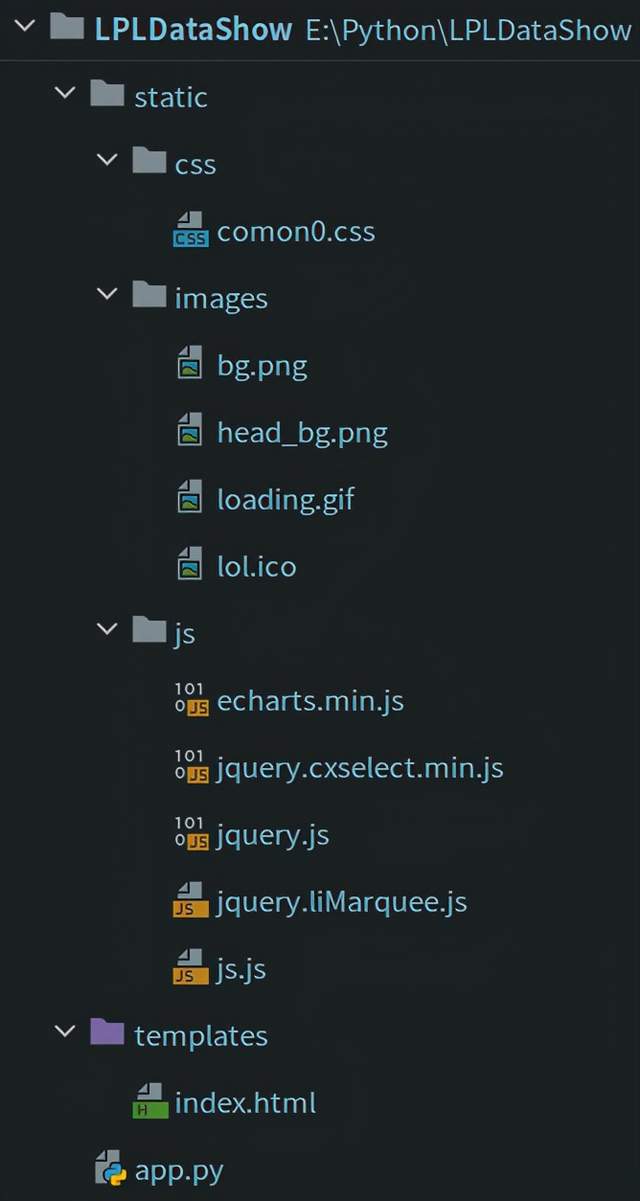
图21
值得注意的是,也是一个坑,HTML文件当中,引用的外部文件,文件地址一定要去修改。因为我们是先写好的前端页面,而flask当中需要我们将外部文件都放在【static】当中
注意事项
引入模板
这里所说的模板,就是我们写好的HTMl文件,只不过需要使用render_template()将其引入
import lpldata
from flask import Flask,render_templateapp = Flask(__name__)
LPL = lpldata.Lpl_Data()#从数据库获取数据@app.route('/')#默认路由
def hello_world():return render_template("index.html")#引入模板Python
使用Ajax传输数据
什么是Ajax
Ajax是Asynchronous Javascript and XML的简称,通过Ajax向服务器发送请求,接收服务器返回的json数据,然后使用 Javascript修改网页,来实现页面局部数据更新。使用 Jquery框架可方便的编写Ajax代码,需要 Jquery.js文件
基本格式
$.ajax({type:"post", //请求类型url:"/目标路由", //请求地址data:{}, //数据datatype:"json",success:function (data) {//请求成功的回调函数,data是返回的数据},error:function () {//请求失败时执行}
})JavaScript
我们先到app.py文件中,定义好一个路由(/wingsvd),methods添加一个'post',这里以【战队胜负图表】为例
@app.route('/wingsvd',methods=['GET','POST'])
def wings_vd():return LPL.get_wings_vd()Python
LPL.get_wings_vd(),你可以到lpldata.py文件查看相关的代码。主要功能就是从数据获取数据,并且将数据整理好后,存到字典里面,最后使用json.dumps()将dict(字典)对象转换为json对象,最为函数的返回值返回
现在回到Ajax的部分,你可以到【js.js】文件中359行查看
function echarts_4() {// 基于准备好的dom,初始化echarts实例var myChart = echarts.init(document.getElementById('echart4'));var lpl = {};$.ajax({url:'/wingsvd', //这里的地址是不是很眼熟,没错就是刚才定义的路由地址data: {},type: 'POST',async: false,dataType:'json',success: function (data) {lpl.name = data.name; // 使用json的方法,提取刚才LPL.get_wings_vd()返回的数据lpl.victory = data.victory;lpl.defeat = data.defeat;lpl.winRate = data.winRate;
......JavaScript
数据提取成功后,就可以在后面的echarts代码中修改对应的配置,图表就可以显示出数据啦
这里以图表的X轴为例
xAxis: [{type: "category",data: lpl.name, //上面的代码是不是也有它呀,有就对啦axisLine: { lineStyle: {color: "rgba(255,255,255,.1)"}},axisLabel: { textStyle: {color: "rgb(255,255,255)", fontSize: '16', }},},],JavaScript
所有的图表传输数据的操作方法都是一样的,先在【app.py】中创建路由,返回你需要的数据,再到【js.js】当中写Ajax和Echarts的代码
最后的胜利
所有的准备工作完成后,我们就只剩最后一步啦!
if __name__ == '__main__':app.run(debug=True)Python
右键,运行,点击下方的地址,可视化的页面就呈现在了你的眼前

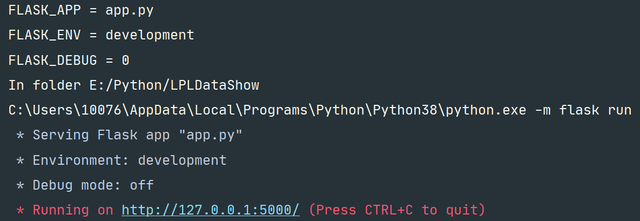
图24